
간단한 Biquge 크롤러를 작성하기 위한 60줄의 Python 코드 소개

- coldplay.xixi앞으로
- 2021-01-13 09:51:072842검색

推荐(免费):Python视频教程
文章目录
- 系列文章目录
- 前言
- 一、网页解析
- 二、代码填写
- 1.获取Html及写入方法
- 2.其余代码
- 总结
前言
利用python写一个简单的笔趣阁爬虫,根据输入的小说网址爬取整个小说并保存到txt文件。爬虫用到了BeautifulSoup库的select方法
结果如图所示: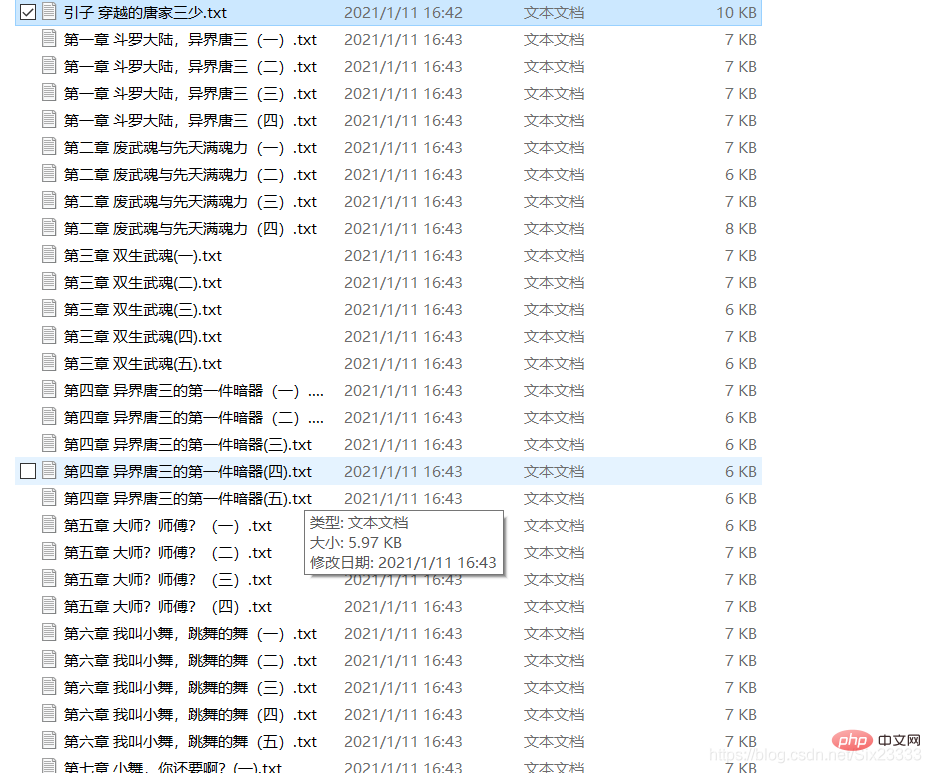
本文只用于学习爬虫
一、网页解析
这里以斗罗大陆小说为例 网址:
http://www.biquge001.com/Book/2/2486/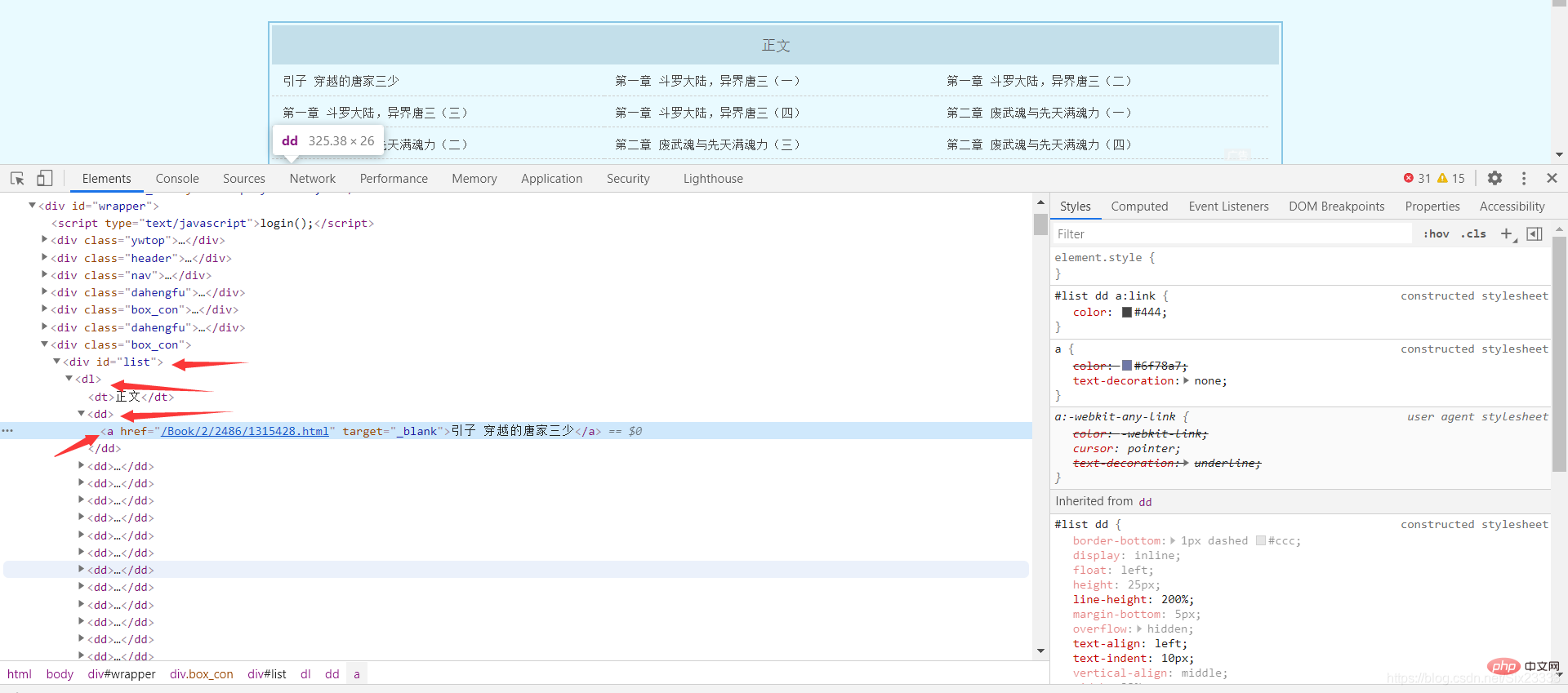
可以发现每章的网页地址和章节名都放在了 中的a标签中,所以利用BeautfulSoup中的select方法可以得到网址和章节名
Tag = BeautifulSoup(getHtmlText(url), "html.parser") #这里的getHtmlText是自己写的获取html的方法urls = Tag.select("p #list dl dd a")
然后遍历列表
for url in urls: href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址 pageName = url.text # 每章的章名
然后每章小说的内容都存放在
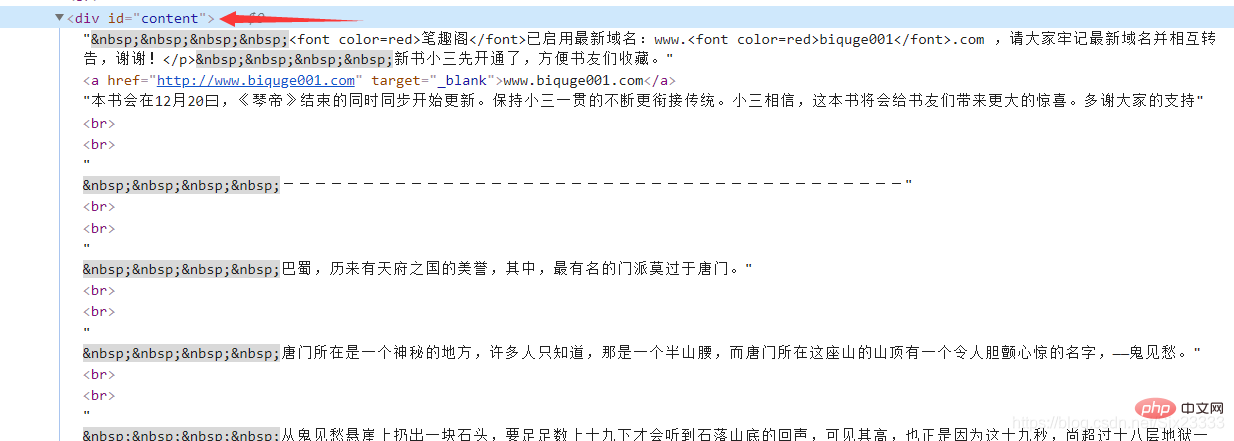
substance = Tag.select("p #content") # 文章的内容
最后同理在首页获取小说的名称
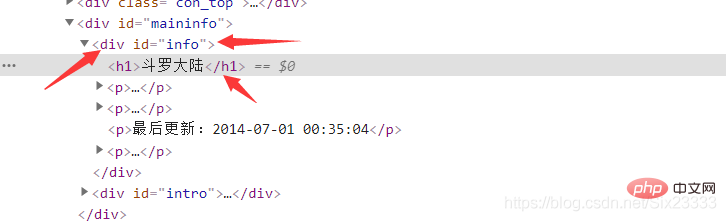
bookName = Tag.select("p #info h1")
二、代码填写
1.获取Html及写入方法
def getHtmlText(url): r = requests.get(url, headers=headers) r.encoding = r.apparent_encoding # 编码转换 r.raise_for_status() return r.textdef writeIntoTxt(filename, content): with open(filename, "w", encoding="utf-8") as f: f.write(content) f.close() print(filename + "已完成")
2.其余代码
代码如下(示例):
url = "http://www.biquge001.com/Book/2/2486/"substanceStr = ""bookName1 = ""html = getHtmlText(url)# 判断是否存在这个文件Tag = BeautifulSoup(getHtmlText(url), "html.parser")urls = Tag.select("p #list dl dd a")bookName = Tag.select("p #info h1")for i in bookName:
bookName1 = i.textif not os.path.exists(bookName1):
os.mkdir(bookName1)
print(bookName1 + "创建完成")else:
print("文件已创建")for url in urls:
href = "http://www.biquge001.com/" + url['href'] # 字符串的拼接 拼接成正确的网址
pageName = url.text # 每章的章名
path = bookName1 + "\\" # 路径
fileName = path + url.text + ".txt" # 文件名 = 路径 + 章节名 + ".txt"
Tag = BeautifulSoup(getHtmlText(href), "html.parser") # 解析每张的网页
substance = Tag.select("p #content") # 文章的内容
for i in substance:
substanceStr = i.text
writeIntoTxt(fileName, substanceStr)
time.sleep(1)
总结
简单利用了BeautfulSoup的select方法对笔趣阁的网页进行了爬取
更多相关学习敬请关注Python教程栏目!
위 내용은 간단한 Biquge 크롤러를 작성하기 위한 60줄의 Python 코드 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
이 기사는 csdn.net에서 복제됩니다. 침해가 있는 경우 admin@php.cn으로 문의하시기 바랍니다. 삭제
이전 기사:Python2와 3의 차이점을 설명하세요.다음 기사:Python2와 3의 차이점을 설명하세요.