
Python 데이터 분석 실용 개요 데이터 분석

- coldplay.xixi앞으로
- 2021-01-06 09:48:392248검색
Python Tutorial이 칼럼에서는 개요 데이터를 소개합니다.

추천(무료): Python tutorial
문서 디렉토리
- 1. 데이터 분석 입문
- 1. 2. 데이터 분석가 취업 전망
- 3. 데이터 분석가가 되는 길
2. Python 설치 및 환경 구성- 2. Python 버전
- 3. 환경 변수 구성
- 4. pip 설치
- 5. 통합 개발 환경 선택
- 3. Anaconda 소개 및 설치
- 1. Anaconda란
- 2. conda 소개 및 패키지 관리. tools
- 4. Jupyter Notebook
1.Jupyter Notebook 기본 소개- 2.Jupyter Notebook 사용
- 3.Jupyter에서 Python 사용하기
- 4.데이터 상호 작용 사례
- csv 데이터 로드 및 처리 MongoDB 데이터베이스에 데이터 저장
- Jupyter를 사용하여 매장 데이터 처리
1. 빅데이터 시대의 기본
빅데이터 현황 데이터 산업 발전:현재 데이터는 폭발적인 성장을 보여주고 있으며 매 순간 다음과 같은 상황이 발생할 수 있습니다.
13,000건 이상의 iPhone 앱 다운로드 98,000건 이상의 Twitter에 새로운 Weibo 게시물
- 1억 6,800만 건 이상의 이메일 전송
- Taobao Double Eleven 10680+ 신규 주문
- 12306 1840+ 티켓 발행
- 빅 데이터 시대에 세 가지 주요 변화가 발생했습니다.
- 무작위 샘플에서 전체 데이터로
정확성에서 혼란으로
- 원인과 결과 관련 관련 관계
- 전형적인 예를 들어보세요: 남성은 기저귀를 사러 슈퍼마켓에 갈 때 맥주를 사게 됩니다. 빅데이터 분석 결과 슈퍼마켓에서는 기저귀 선반 근처에 맥주를 두게 되어 매출이 증가하고 기저귀를 구매하게 됩니다. .맥주 구매와는 인과관계는 없으나 어느 정도 상관관계가 있습니다.
- 국내 빅데이터 적용 현황은 다음과 같습니다(CSDN 기준).
인재 요구 사항은 주로 다음과 같습니다. 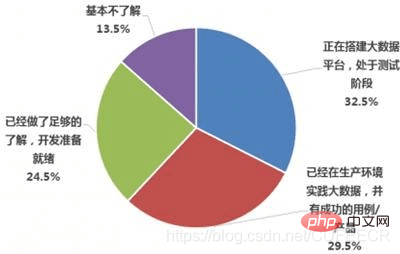
데이터 분석가
통계 분석
- 예측 분석
- 프로세스 최적화
- 빅 데이터 엔지니어
- 플랫폼 개발
애플리케이션 개발 - 기술 니컬 지원
- 데이터 설계자
- 비즈니스 이해
애플리케이션 배포-
- 건축 디자인
- 데이터 분석을 배워야 하는 이유는 데이터가 점점 더 일반화되고 저렴해지고 있으며, 분석은 희소하면서도 추가 가치가 있는 데이터를 제공할 수 있기 때문입니다.
2. 데이터 분석가의 직업 전망
데이터 분석가가 해결해야 할 문제:수요 예측, 생산 능력 할당
빅데이터 시대에는 데이터를 해석하는 능력이 더욱 필요합니다.
Q: 오븐의 용량이 제한되어 있는데 어떤 종류의 빵을 생산해야 하나요?- A: 가장 인기 있는 빵을 나열하고
- 스타 제품
을 우선적으로 생산합니다.
사업 계획
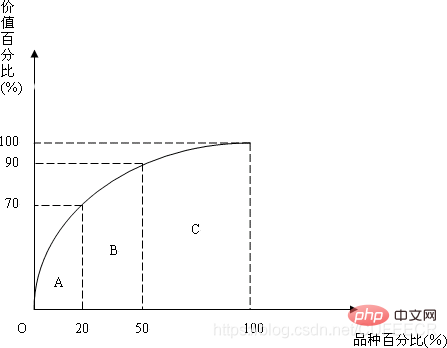
핵심은 스타 제품을 찾는 것입니다. 이를 위해서는 빵의 전체 매출을 계산한 다음, 전체 매출에서 각 유형의 빵이 차지하는 상대적인 비율을 계산하고, 70%를 차지할 수 있는 제품 조합의 생산을 우선시해야 합니다. 매출액의. 이 분석 방법은 다음과 같이 ABC 분석 방법이라고도 합니다.
마케팅 계획의 효율성을 평가합니다. 통계는 단순히 데이터를 분석하는 것이 아니라 결과를 통해 이루어집니다. 분석의 핵심은 고객 행동에 어떻게 영향을 미칠지 추측하고 이를 구체적인 으로 공식화하고 그에 따라 행동하는 것입니다.
통계는 단순히 데이터를 분석하는 것이 아니라 결과를 통해 이루어집니다. 분석의 핵심은 고객 행동에 어떻게 영향을 미칠지 추측하고 이를 구체적인 으로 공식화하고 그에 따라 행동하는 것입니다. - Q: 온라인으로 빵을 팔고 싶다면 어떤 광고가 더 효과적인가요?
A: 두 가지 유형의 카피라이팅을 작성하고 일정 기간 동안 실행하여 얼마나 효과적인지 확인하세요.
Q: 빵집이 모서리를 잘랐는지 어떻게 빵에서 알 수 있나요?
광고 효과를 비교하는 가장 좋은 방법은 통계적인 무작위 제어 실험을 사용하여 두 가지 유형의 광고를 무작위로 게재하는 것입니다. 일정 시간이 지난 후 어떤 광고 효과가 더 좋은지 관찰한 다음 실적이 더 좋은 광고를 사용하는 것입니다. 대판.
제품 품질 관리 결과와 결과의 원인 사이의 관계를 찾아내는 것이 매우 중요합니다. A: 무작위로 빵 몇 개를 확인하고 무게 차이가 너무 큰지 확인해보세요. - 먼저 빵의 평균 무게를 알아야 하고, 그런 다음 빵의 무게가 정규 분포를 따르는 종 모양의 곡선을 나타내는지 확인하기 위해 빵을 샘플링해야 합니까? 곡선에서 벗어나면 빵의 품질에 문제가 있을 수 있습니다. 다음과 같습니다:
 통계는 단순히 데이터를 분석하는 것이 아니라 결과를 통해 이루어집니다. 분석의 핵심은 고객 행동에 어떻게 영향을 미칠지 추측하고 이를 구체적인
통계는 단순히 데이터를 분석하는 것이 아니라 결과를 통해 이루어집니다. 분석의 핵심은 고객 행동에 어떻게 영향을 미칠지 추측하고 이를 구체적인 좋은 데이터 분석가는 좋은 제품 기획자이자 업계 리더;
IT 기업에서 우수한 데이터 분석가는 회사의 고위 임원이 될 가능성이 높습니다.
데이터 분석가의 작업 흐름은 다음과 같습니다. 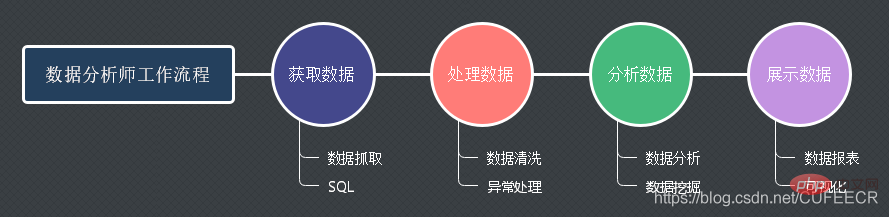
데이터 분석가의 세 가지 주요 작업:
- 이력 분석
- 미래 예측
- 선택 최적화
데이터 분석가에게 필요한 8가지 기술:
- 통계
- 통계 테스트, P-값, 분포, 추정
- 기본 도구
- Python
- SQL
- 다변수 미적분학 및 선형 대수
- 데이터 랭글링
- 데이터 시각화
- 소프트웨어 엔지니어링
- 머신러닝
- 데이터 과학자 사고
- 데이터 중심
- 문제 해결
데이터 분석가에게 필요한 세 가지 주요 능력은
- 기본 통계 및 분석 도구의 응용
- 컴퓨터 코딩 능력
- 특정 응용 분야 또는 업계 지식
전형적인 데이터 분석가의 성장 과정: 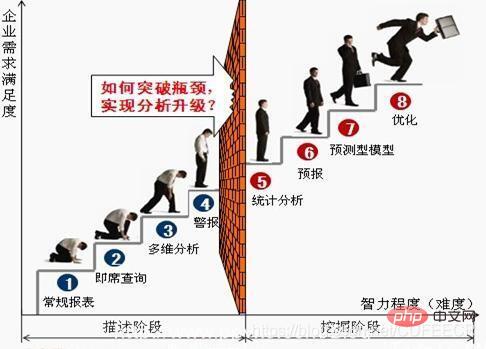
3. 데이터 분석가가 되는 길
데이터 분석가가 되기 위한 자기 수양:
- Sensitive
- Exploring
- 꼼꼼
- 실용적
데이터 분석가가 갖추어야 할 역량은 다음과 같습니다.
- Excel 데이터 처리에 익숙함
- 강력한 데이터 민감도
- 회사 비즈니스 및 업계 지식에 익숙함
- 데이터 분석 방법 마스터
-
기본 분석 방법
- 대조 분석 방법
- 그룹 분석 방법
- 교차 분석 방법
- 구조 분석 방법
- 깔때기형 분석 방법
- 종합 평가 분석 방법
- 요인 분석 방법
- 행렬 상관 분석
- 고급 분석 방법
- 상관분석 방법
- 회귀분석 방법
- 클러스터 분석 방법
- 판별 분석 방법
- 주성분 분석 방법
- 요인 분석 방법
- 대응 분석 방법
- 시계열
-
기본 분석 방법
다양한 상황에서 업계 데이터 분석 실무자의 업무 내용 및 책임:
- 데이터 분석에 참여
- 일일 보고서 작성 방법 배우기
- 일일 매출 및 재고 테이블
- 제품 매출 예측
- 재고 계산 및 조기 경고
- 트래픽 분석 관련 테이블
- 검토
- 데이터 분석 및 마이닝 인력
- 제품 최적화를 위한 데이터 지원 제공
- 제품 개선 효과 검증
- 상위 경영진에게 이메일 및 보고서 제공
- 인터넷 + 분석
- KPI 지표 모니터링
- 각 A 일종의 정기 보고서
- 특정 비즈니스 문제에 대한 분석 보고서 작성
- 비즈니스를 위한 오프라인 모델링 및 분석
데이터 분석에서 매우 중요한 주제 기초는 수학이지만, 그렇지 않아도 상관없습니다. 수학에 능숙하다면 Python을 사용하여 학습할 수 있습니다.
Python은 프로그래밍 언어일 뿐만 아니라 데이터 마이닝, 기계 학습 및 기타 기술의 기초로서 자동화된 작업 흐름 구축을 용이하게 합니다.
시작하기; Python을 사용하는 것은 어렵지 않으며 수학적 요구 사항이 너무 높지 않습니다. 이는 중요합니다. 당신이 해야 할 일은 알고리즘 논리를 언어로 표현하는 방법을 아는 것입니다.
Python에는 많은 패키지 도구 라이브러리와 명령이 있습니다. 문제를 해결하고 구축하기 위해 어떤 수학적 방법을 사용하는 것입니다.
Python 데이터 분석을 빠르게 시작하려면 Python 관련 툴킷을 잘 활용해야 합니다.
(1) Python의 가장 큰 특징은 거대하고 활동적인 과학 컴퓨팅 커뮤니티가 있다는 것입니다. 과학 컴퓨팅에 Python을 사용하는 추세도 점점 더 분명해지고 있습니다.
(2) Python은 지속적으로 라이브러리를 개선했기 때문에 데이터 처리 작업의 주요 대안이 되었습니다. 일반 프로그래밍의 강력한 강점과 결합하여 Python 응용 프로그램만 사용하여 다음을 포함하는 데이터 중심 응용 프로그램을 구축하는 것이 완전히 가능합니다.
- 자주 사용하는 데이터 분석 라이브러리
- Numpy
- Scipy
- Pandas
- matplotlib
자주 사용하는 고급 데이터 분석 라이브러리- nltk
- igraph
- scikit-learn
- 데이터 이해
- 데이터 정리 및 예비 분석
- 그리기 및 시각화
- 데이터 집계 및 그룹화 처리
- 데이터 마이닝
- 선형 회귀
- 시계열 분석
- 분류 알고리즘
- 클러스터링 알고리즘
- 차원 축소 알고리즘
- 생각하기
- 더 많이 하세요
- 요약 더보기
2. Python 설치 및 환경 구성
1.Python 버전
Python은 3.X와 2.X의 두 가지 주요 버전으로 나뉩니다.
Python 버전 3.0은 종종 Python 3000 또는 줄여서 Py3k라고 합니다. 이는 이전 버전의 Python에 비해 주요 업그레이드입니다.
Python 3.X는 너무 많은 부담을 주지 않기 위해 하위 호환성을 염두에 두고 설계되지 않았습니다. 이전 Python 버전용으로 설계된 많은 프로그램은 Python 3에서 제대로 실행되지 않습니다.
대부분의 타사 라이브러리는 Python 3.X 버전과 호환되도록 열심히 노력하고 있습니다.
2. 다른 시스템에 Python 설치
(1) Unix 및 Linux 시스템
- http://www.python.org/download/
- Unix/Linux에 적합한 소스 코드 압축 패키지 선택
- 압축된 패키지 다운로드 및 압축 해제
- 일부 옵션을 맞춤 설정해야 하는 경우 모듈/설정을 수정하세요
-
./configure스크립트 실행./configure脚本 makemake install
make
make install
- (2) Window system
-
http://www.python.org/download/방문하기 다운로드 목록에서 Window 플랫폼 설치 패키지를 선택하세요 공식 홈페이지에서 다운로드한 이후 웹사이트가 매우 느립니다. Python을 설치했습니다. 각 버전의 설치 패키지를 다운로드하여 정리했습니다. QQ 그룹을 직접 클릭하여 추가할 수 있습니다.
963624318 그룹 폴더 - Python 관련 설치 패키지에 다운로드하시면 됩니다. 다운로드 후 다운로드 패키지를 두 번 클릭하여 Python 설치 마법사로 들어갑니다. 설치는 매우 간단합니다. 기본 설정을 사용하고 설치가 완료될 때까지
을 계속 클릭하세요. brew install python安装新版本。
3.环境变量配置
Windows系统需要配置环境变量。
如果在安装Python时没有选择添加环境变量,则需要手动添加,需要将安装Python的路径XXXPythonXXX和XXXPythonXXXScripts添加到环境变量,有两种方式:
- 命令行添加
CMD中分别执行path=%path%;XXXPythonXXX和path=%path%;XXXPythonXXXScripts即可。 - 在系统设置中添加
右键计算机 → 属性 → 高级系统设置 → 系统属性 → 环境变量 → 双击path → 添加XXXPythonXXX和XXXPythonXXXScripts安装路径,如下:
最后依次点击确认退出即可。
4.安装pip
pip是Python中的包安装和管理工具,在安装Python时可以选择安装pip,在Python 2 >=2.7.9或Python 3 >=3.4中自带。
如果没有安装pip,可以通过命令安装:
- Linux或者Mac
pip install -U pip - Windows(cmd输入)
python -m pip install -U pip(3) Mac 시스템
brew install python을 실행하여 새 버전을 설치할 수 있습니다. 3. 환경 변수 구성
Windows 시스템에서는 환경 변수를 구성해야 합니다.
Python 설치 시 환경 변수 추가를 선택하지 않은 경우 Python XXXPythonXXX 및 XXXPythonXXXScripts를 설치할 경로를 수동으로 추가해야 합니다. 환경 변수에는 두 가지 방법이 있습니다. 명령줄 추가 CMD에서 path=%path%;XXXPythonXXX와 path=%path%;XXXPythonXXXScripts를 각각 실행합니다. 시스템 설정에서
컴퓨터를 마우스 오른쪽 버튼으로 클릭 → 속성 → 고급 시스템 설정 → 시스템 속성 → 환경 변수 → 경로 두 번 클릭 → XXXPythonXXX 및 XXXPythonXXXScripts 추가 code> 설치 경로는 다음과 같습니다.

마지막으로 확인을 클릭하여 종료하세요.
4. pip 설치
pip는 Python 설치 시 pip 설치를 선택할 수 있습니다. Python 2 >=2.7.9 또는 Python 3 >=3.4입니다. pip가 설치되지 않은 경우 다음 명령을 통해 설치할 수 있습니다:
Linux 또는 Mac
pip install -U pipWindows(cmd 입력)python -m pip install -U pip
5. 통합 개발 환경 선택 Python에는 PyCharm 등 다양한 편집기가 있습니다. 여기서 PyCharm을 선택하세요. PyCharm은 JetBrains에서 만든 Python IDE로, Mac OS를 지원합니다. 윈도우, 리눅스 시스템.
Python에는 PyCharm 등 다양한 편집기가 있습니다. 여기서 PyCharm을 선택하세요. PyCharm은 JetBrains에서 만든 Python IDE로, Mac OS를 지원합니다. 윈도우, 리눅스 시스템.
, 구문 강조, 프로젝트 관리,
코드 점프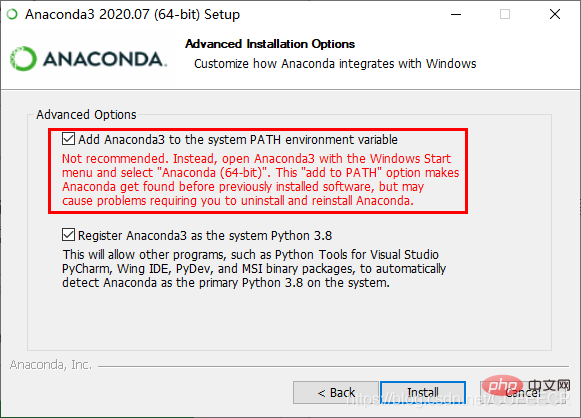 ,
,
마지막으로 다음을 클릭하세요. 설치가 완료된 후 Win 키(Windows 시스템 아래)를 클릭하면 아래와 같이 최근에 추가된 응용 프로그램 목록 A를 볼 수 있습니다. 
이때 Anaconda Navigator를 클릭할 수 있습니다. , 아래와 같이 :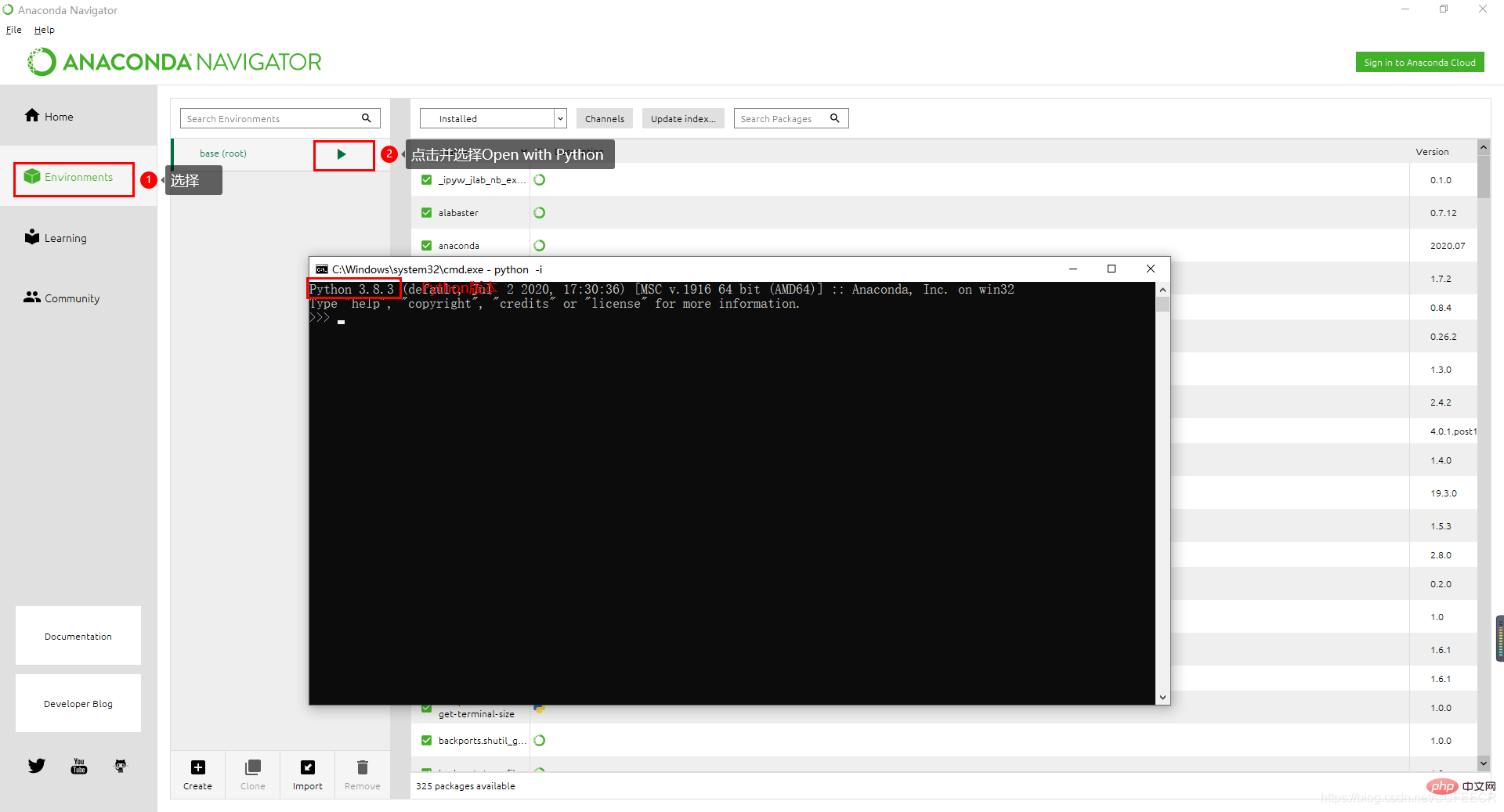
환경이 Python 3.8.3임을 알 수 있습니다. Anaconda에서 만든 기본 환경은 base라고 하며 기본 환경이기도 합니다.
Anaconda 명령줄 도구 Anaconda Powershell Prompt를 열고 python -V를 입력한 다음 Python 3.8.3도 인쇄하세요. python -V,也打印Python 3.8.3。
还可以通过命令创建新的conda环境,如conda create --name py27 python=2.7执行后即创建了一个名为py27的Python版本为2.7的conda环境。
激活环境执行命令conda activate py27,停用使用命令conda deactivate。
可以在命令行中执行conda list查看已经安装的库,如下:
# packages in environment at E:\Anaconda3: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py38_0 alabaster 0.7.12 py_0 anaconda 2020.07 py38_0 anaconda-client 1.7.2 py38_0 anaconda-navigator 1.9.12 py38_0 ... zlib 1.2.11 h62dcd97_4 zope 1.0 py38_1 zope.event 4.4 py38_0 zope.interface 4.7.1 py38he774522_0 zstd 1.4.5 ha9fde0e_0
3.conda工具的介绍和包管理
conda是Anaconda下用于包管理和环境管理的工具,功能上类似pip和virtualenv的组合,conda的环境管理与virtualenv是基本上是类似的操作。
安装成功后conda会默认加入到环境变量中,因此可直接在命令行窗口运行conda命令。
常见的conda命令和含义如下:
| 命令含义 | conda命令 |
|---|---|
| conda –h | 查看帮助 |
| 基于python3.6版本创建名为python36的环境 | conda create --name python36 python=3.6 |
| 激活此环境 | activate python36(Windows)、source activate python36(linux/mac) |
| 查看python版本 | python -V |
| 退出当前环境 | deactivate python36 |
| 删除环境 | conda remove -n py27 --all |
| 查看所有安装的环境 | conda info -e |
conda的包管理常见命令如下:
| 包管理命令意义 | 包管理命令 |
|---|---|
| 安装matplotlib | conda install matplotlib |
| 查看已安装的包 | conda list |
| 包更新 | conda update matplotlib |
| 删除包 | conda remove matplotlib |
在conda中,anything is a package一切皆是包
conda create --name py27 python=2.7과 같은 명령을 통해 새 conda 환경을 생성할 수도 있습니다. 실행 후 py27이라는 Python 버전 2.7이 포함된 conda 환경이 생성됩니다. 명령줄에서 conda list를 실행하면 다음과 같이 설치된 라이브러리를 볼 수 있습니다. |
3. Conda 도구 소개 및 패키지 관리 |
|---|---|
| 및 | Environment Management도구는 기능적으로 pip와 virtualenv의 조합과 유사합니다. Conda의 환경 관리와 virtualenv는 기본적으로 유사한 작업입니다. | 성공적으로 설치되면 기본적으로 conda가 환경 변수에 추가되므로 명령줄 창에서 직접 conda 명령을 실행할 수 있습니다.
| conda 명령 |
모든 것이 패키지이고 모든 것이 패키지입니다, conda 자체도 패키지로 간주할 수 있습니다. python 환경 패키지로서 anaconda도 패키지로 간주될 수 있으므로 업데이트를 지원하는 일반 타사 패키지 외에도 이 세 가지 패키지는 다음 명령도 지원합니다. 🎜 Conda 자체 업데이트🎜🎜conda update conda🎜🎜🎜🎜Update anaconda application🎜🎜conda update anaconda🎜🎜🎜🎜Update Python, 현재 Python 환경이 3.8.1이고 최신 버전이 3.8.2라고 가정하면 다음과 같습니다. 3.8로 업그레이드 .2🎜🎜conda 업데이트 python🎜🎜🎜🎜四、Jupyter Notebook
1.Jupyter Notebook基本介绍
Jupyter Notebook(此前被称为IPython notebook)是一个交互式笔记本,支持运行40多种编程语言。
在开始使用notebook之前,需要先安装该库:
(1)在命令行中执行pip install jupyter来安装;
(2)安装Anaconda后自带Jupyter Notebook。
在命令行中执行jupyter notebook,就会在当前目录下启动Jupyter服务并使用默认浏览器打开页面,还可以复制链接到其他浏览器中打开,如下:
可以看到,notebook界面由以下部分组成:
(1)notebook名称;
(2)主工具栏,提供了保存、导出、重载notebook,以及重启内核等选项;
(3)notebook主要区域,包含了notebook的内容编辑区。
2.Jupyter Notebook的使用
在Jupyter页面下方的主要区域,由被称为单元格的部分组成。每个notebook由多个单元格构成,而每个单元格又可以有不同的用途。
上图中看到的是一个代码单元格(code cell),以[ ]开头,在这种类型的单元格中,可以输入任意代码并执行。
例如,输入1 + 2并按下Shift + Enter,单元格中的代码就会被计算,光标也会被移动到一个新的单元格中。
如果想新建一个notebook,只需要点击New,选择希望启动的notebook类型即可。
简单使用示意如下: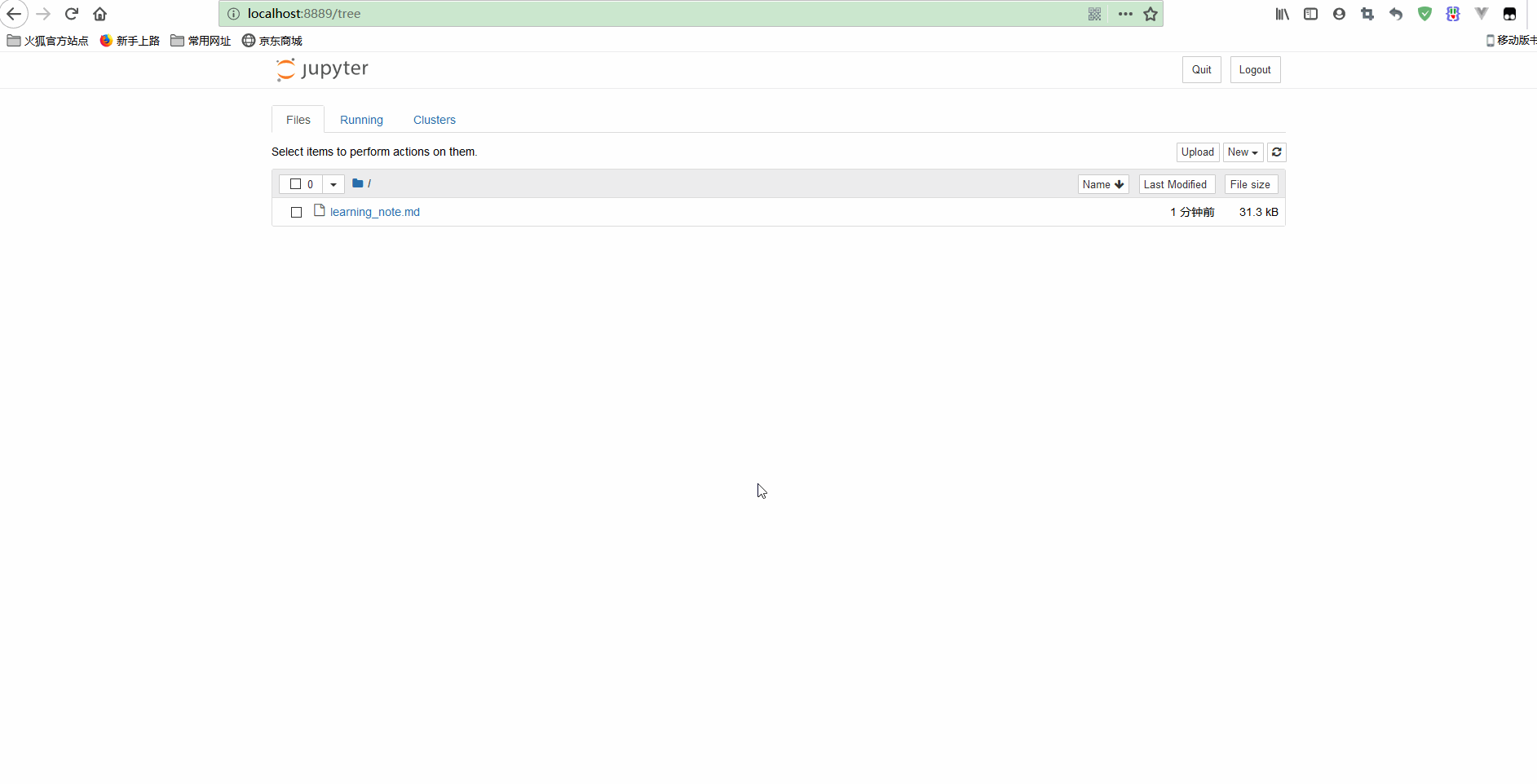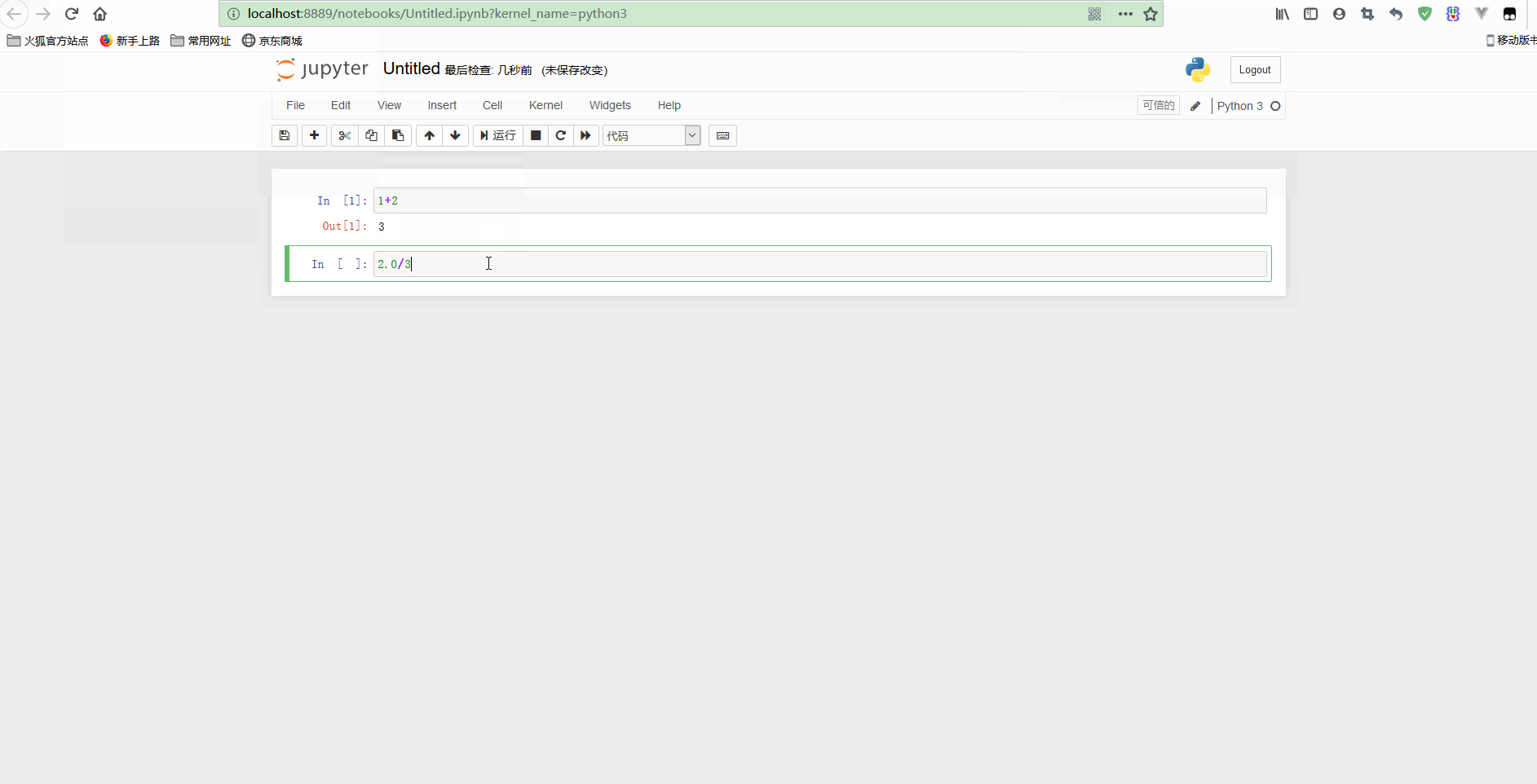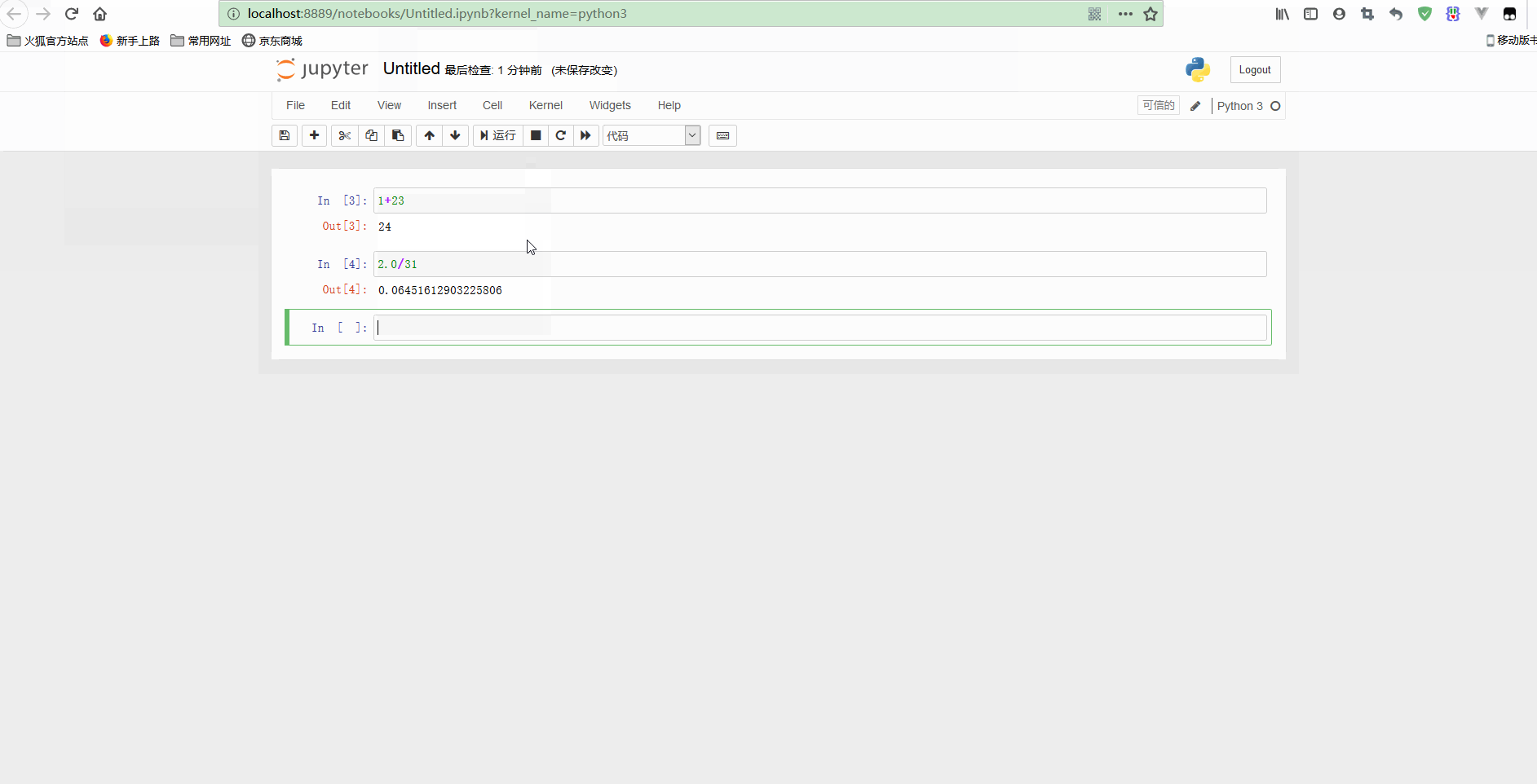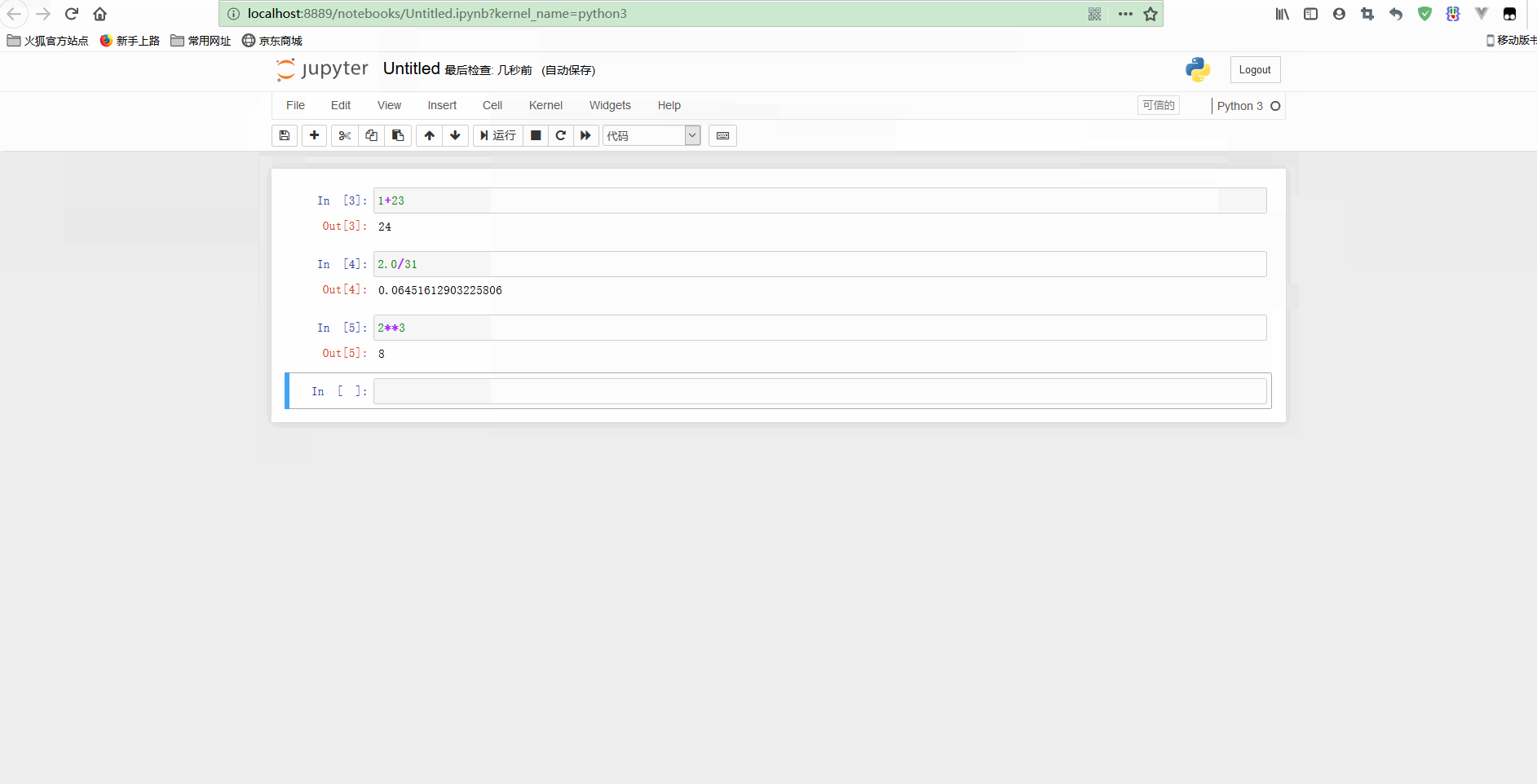
可以看到,notebook可以修改之前的单元格,对其重新计算,这样就可以更新整个文档了。如果你不想重新运行整个脚本,只想用不同的参数测试某个程式的话,这个特性显得尤其强大。
不过,也可以重新计算整个notebook,只要点击Cell -> Run all即可。
再测试标题和其他代码如下: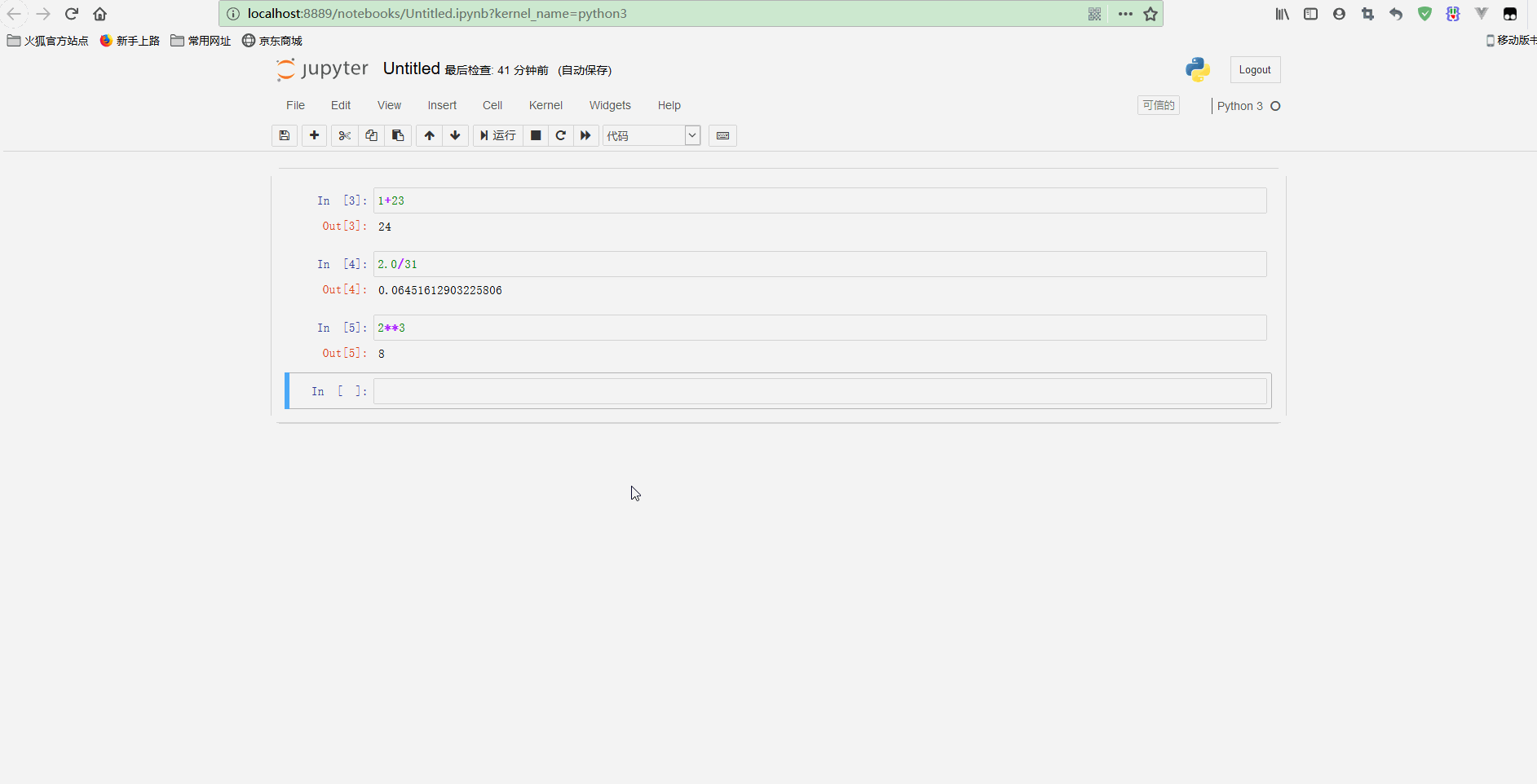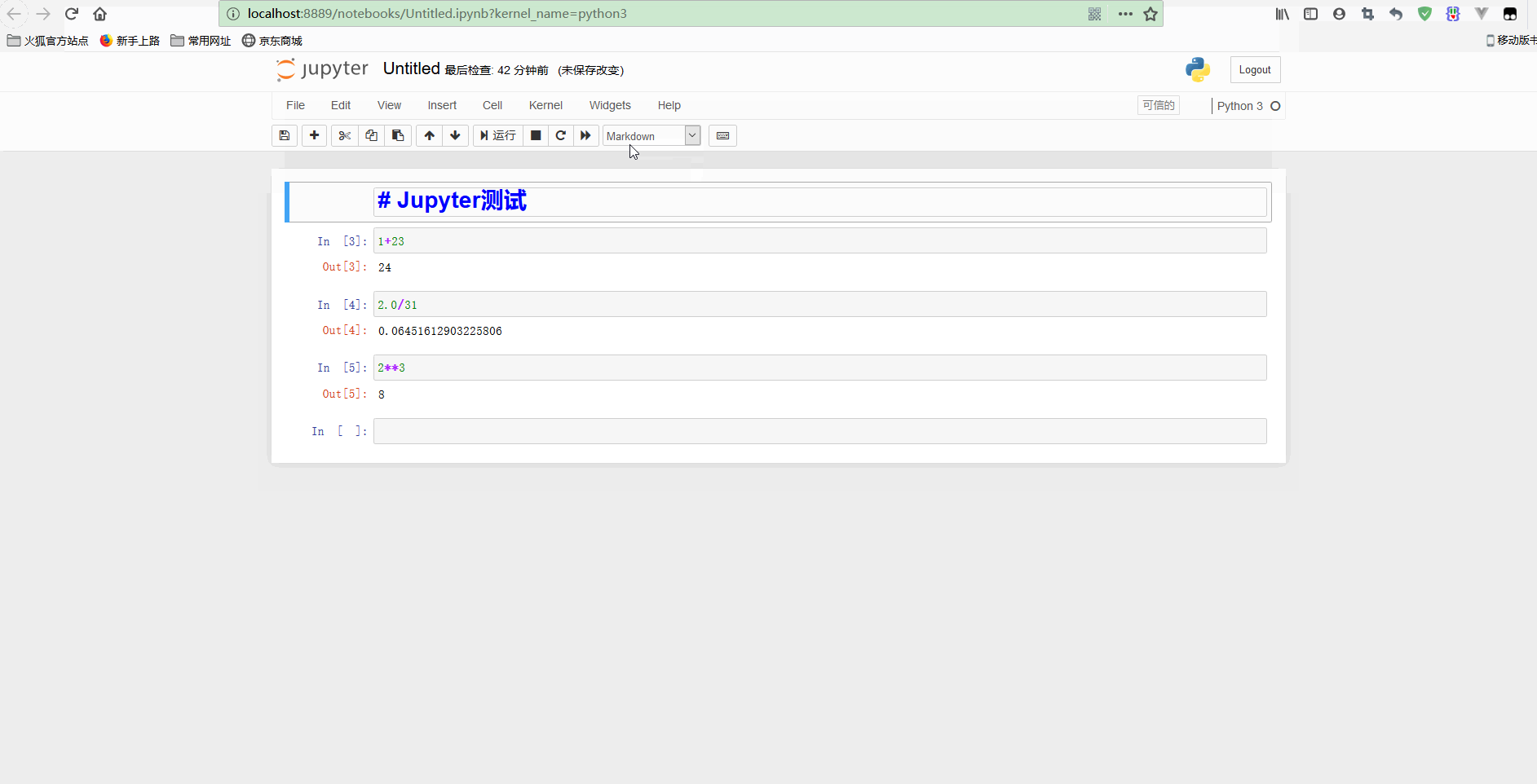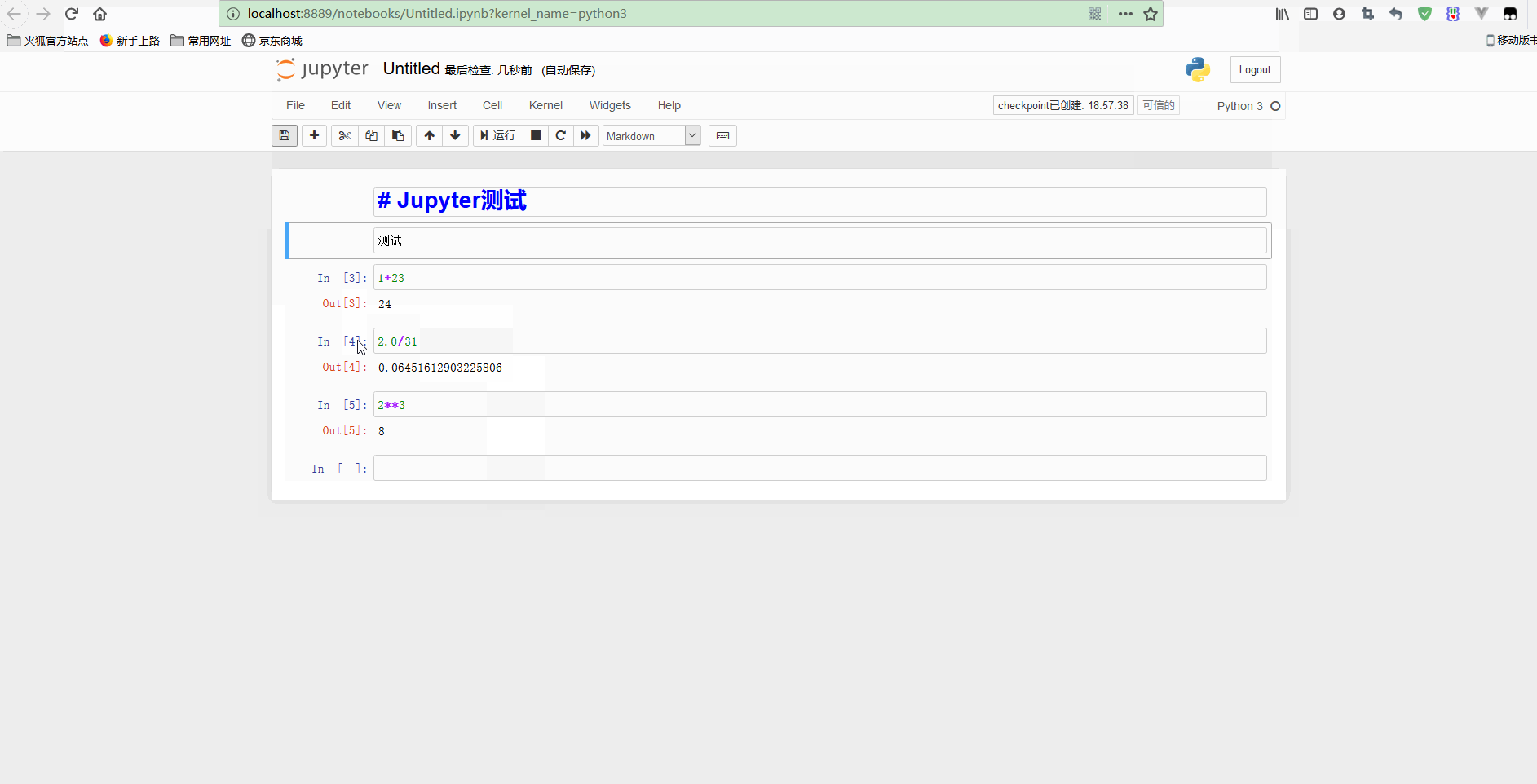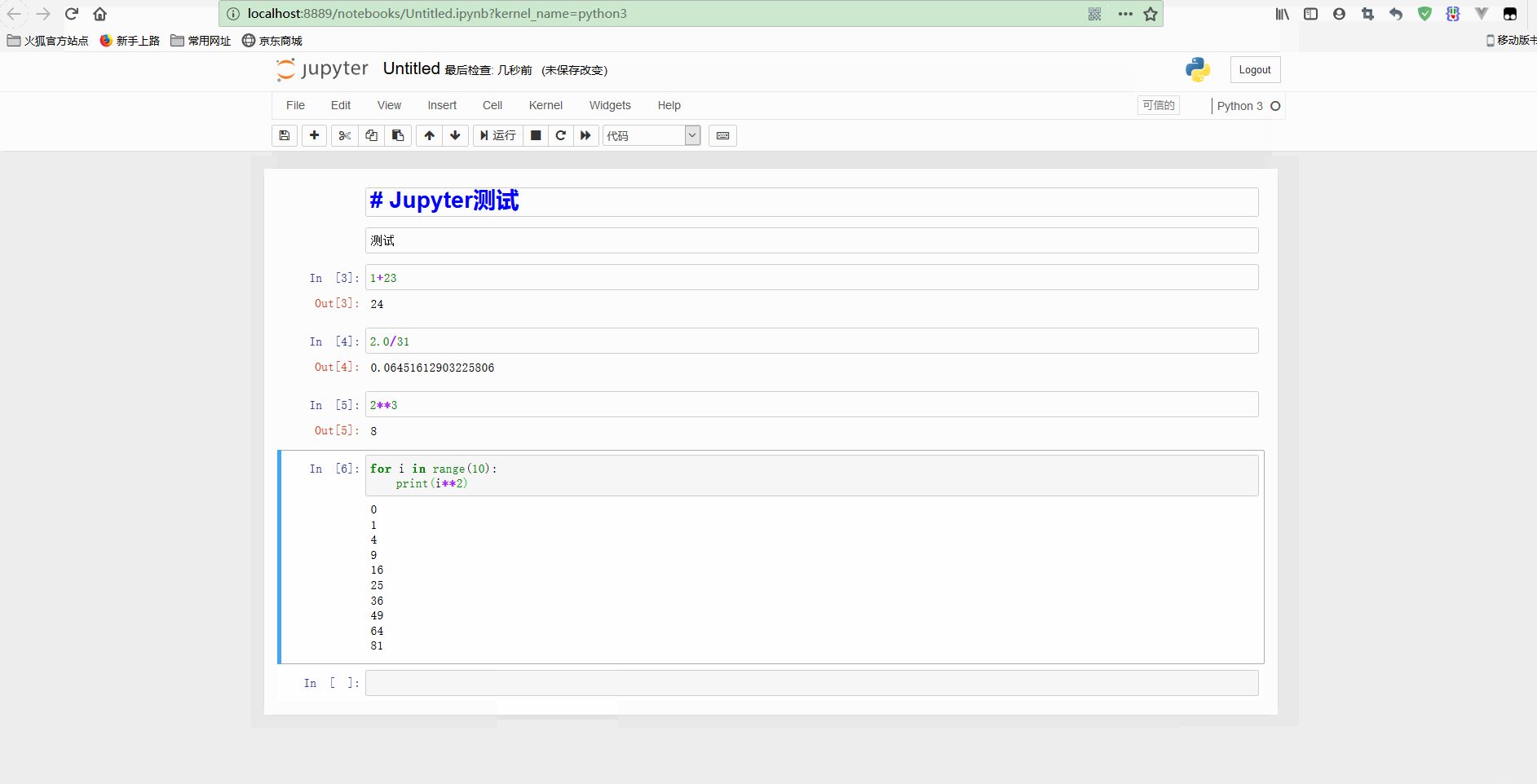
可以看到,在顶部添加了一个notebook的标题,还可以执行for循环等语句。
3.Jupyter中使用Python
Jupyter测试Python变量和数据类型如下:
测试Python函数如下:
测试Python模块如下:
可以看到,在执行出错时,也会抛出异常。
测试数据读写如下:
数据读写很重要,因为进行数据分析时必须先读取数据,进行数据处理后也要进行保存。
4.数据交互案例
加载csv数据,处理数据,保存到MongoDB数据库
有csv文件Python 데이터 분석 실용 개요 데이터 분석.csv和Python 데이터 분석 실용 개요 데이터 분석.csv,分别是商品数据和用户评分数据,如下:
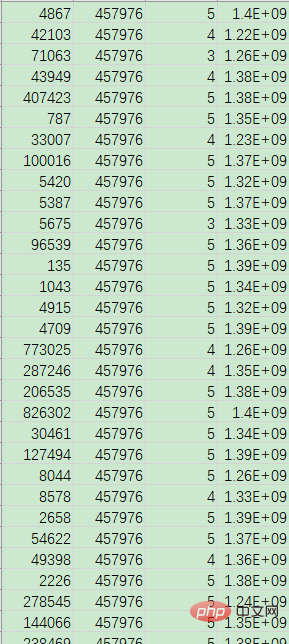
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
现在需要通过Python将其读取出来,并将指定的字段保存到MongoDB中,需要在Anaconda中执行命令conda install pymongo安装pymongo。
Python代码如下:
import pymongoclass Product:
def __init__(self,productId:int ,name, imageUrl, categories, tags):
self.productId = productId
self.name = name
self.imageUrl = imageUrl
self.categories = categories
self.tags = tags def __str__(self) -> str:
return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating:
def __init__(self, userId:int, productId:int, score:float, timestamp:int):
self.userId = userId
self.productId = productId
self.score = score
self.timestamp = timestamp def __str__(self) -> str:
return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__':
myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
mydb = myclient["goods-users"]
# val attr = item.split("\\^")
# // 转换成Product
# Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim)
Python 데이터 분석 실용 개요 데이터 분석 = mydb['Python 데이터 분석 실용 개요 데이터 분석']
with open('Python 데이터 분석 실용 개요 데이터 분석.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split('^')
product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip())
Python 데이터 분석 실용 개요 데이터 분석.insert_one(product.__dict__)
# print(product)
# print(json.dumps(obj=product.__dict__,ensure_ascii=False))
item = f.readline()
# val attr = item.split(",")
# Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
Python 데이터 분석 실용 개요 데이터 분석 = mydb['Python 데이터 분석 실용 개요 데이터 분석']
with open('Python 데이터 분석 실용 개요 데이터 분석.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split(',')
rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip()))
Python 데이터 분석 실용 개요 데이터 분석.insert_one(rating.__dict__)
# print(rating)
item = f.readline()
在启动MongoDB服务后,运行Python代码,运行完成后,再通过Robo 3T查看数据库如下: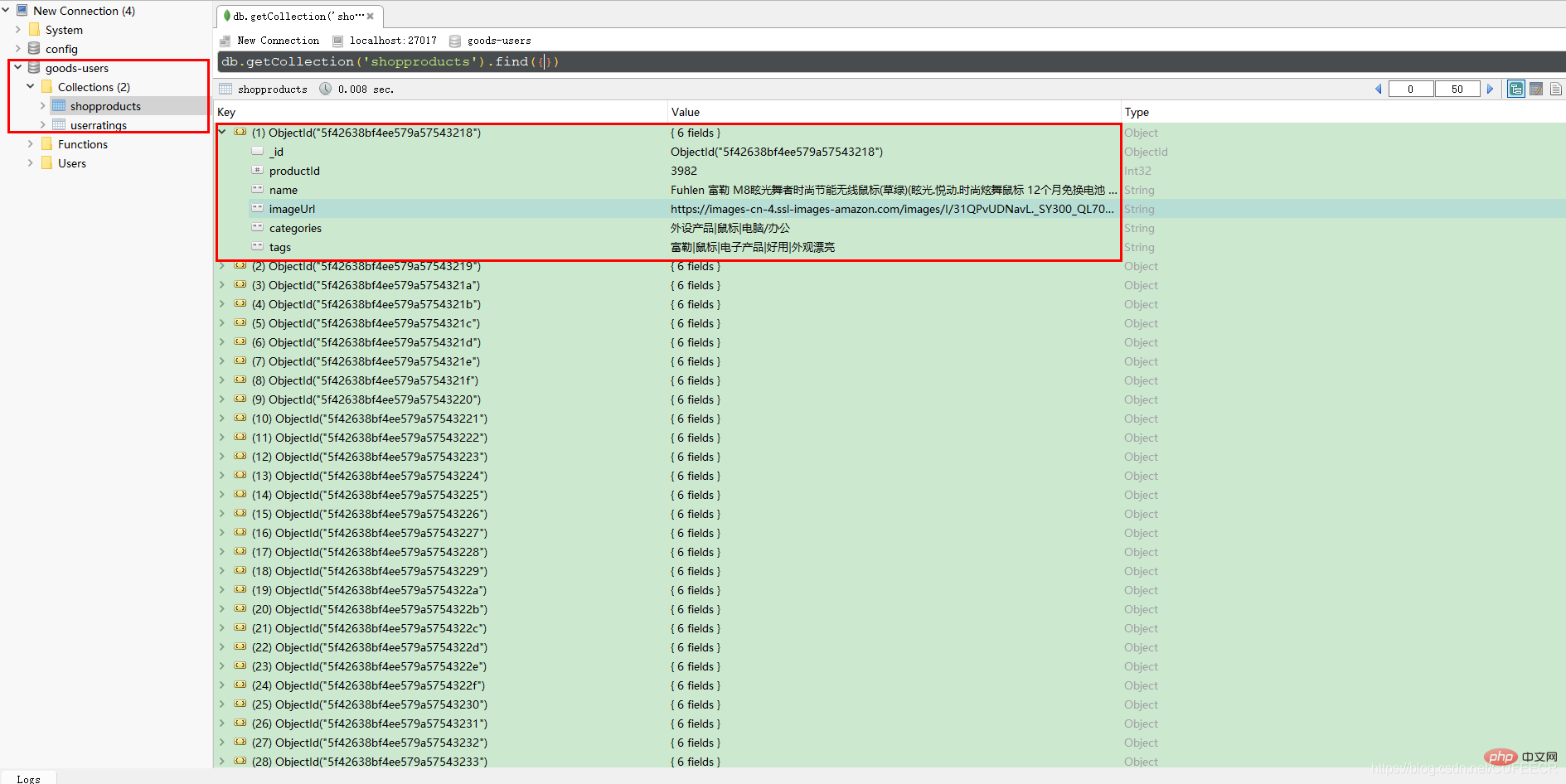
显然,保存数据成功。
使用Jupyter处理商铺数据
待处理的数据是商铺数据,如下: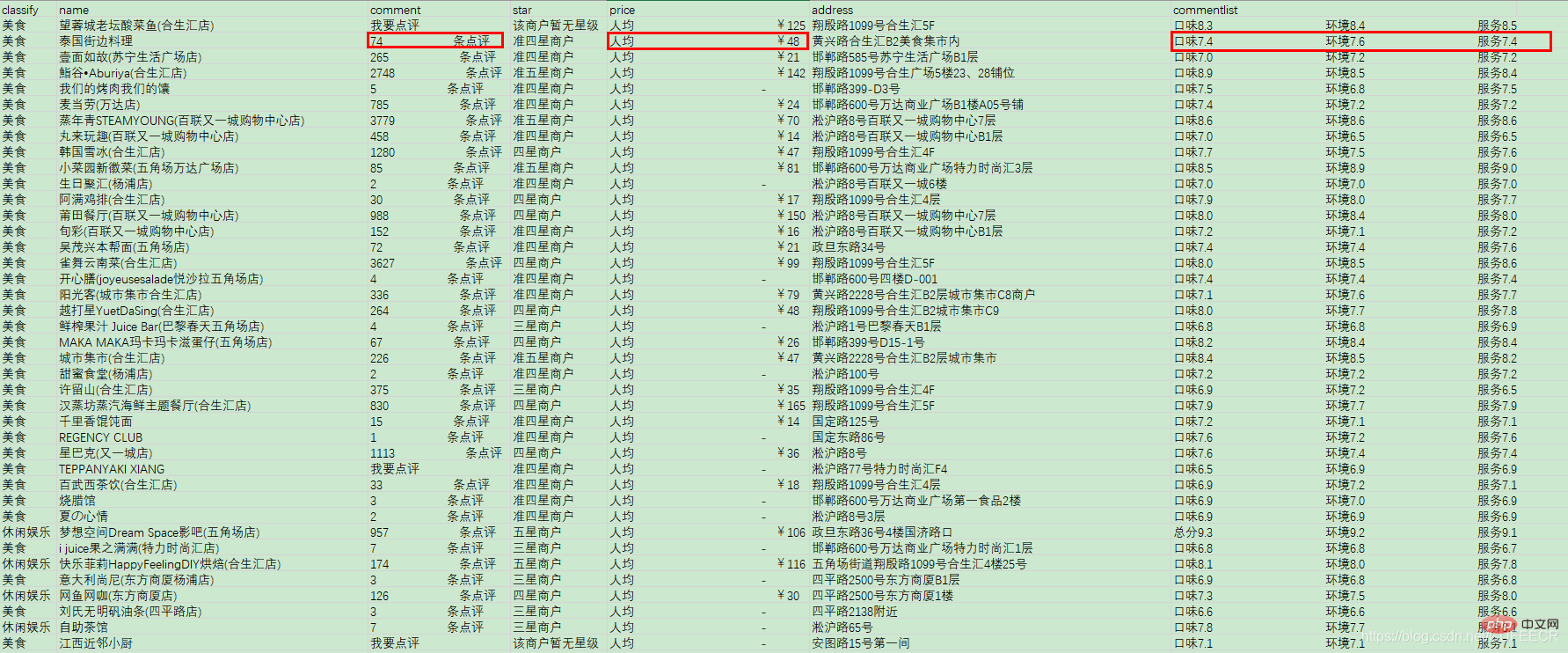
包括名称、评论数、价格、地址、评分列表等,其中评论数、价格和评分均不规则、需要进行数据清洗。
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
Jupyter中处理如下: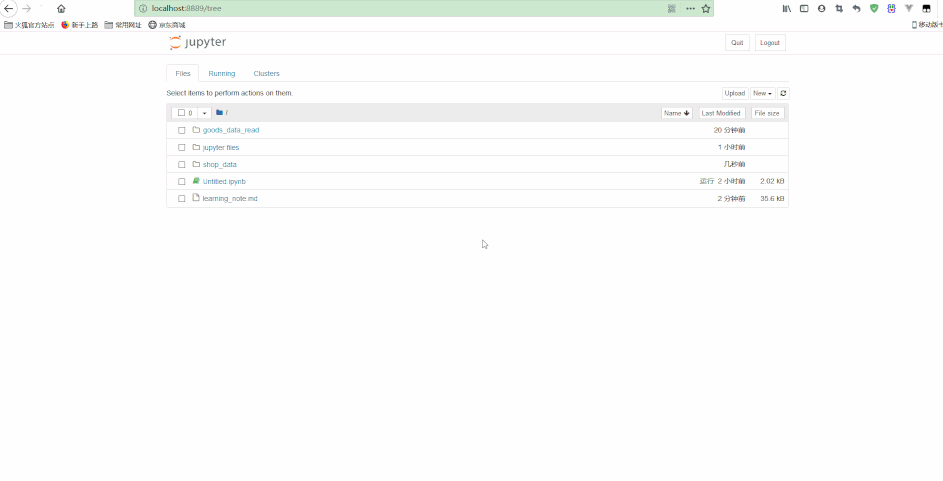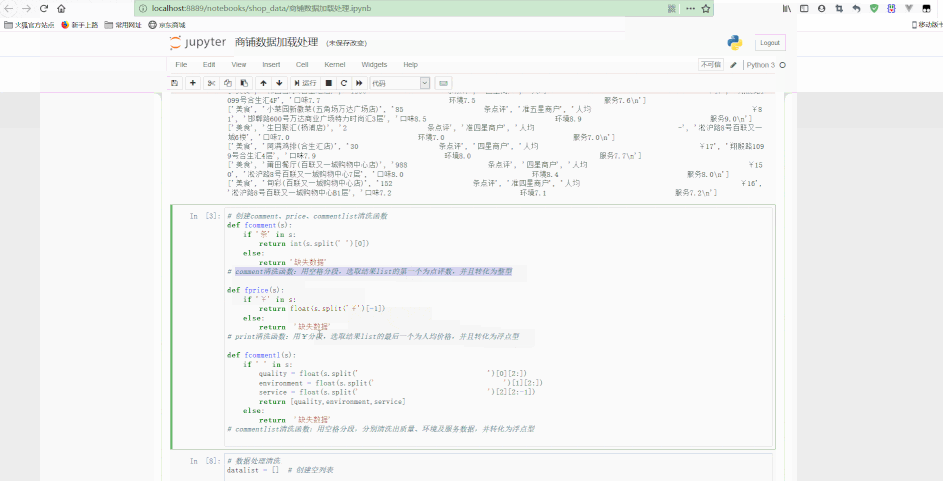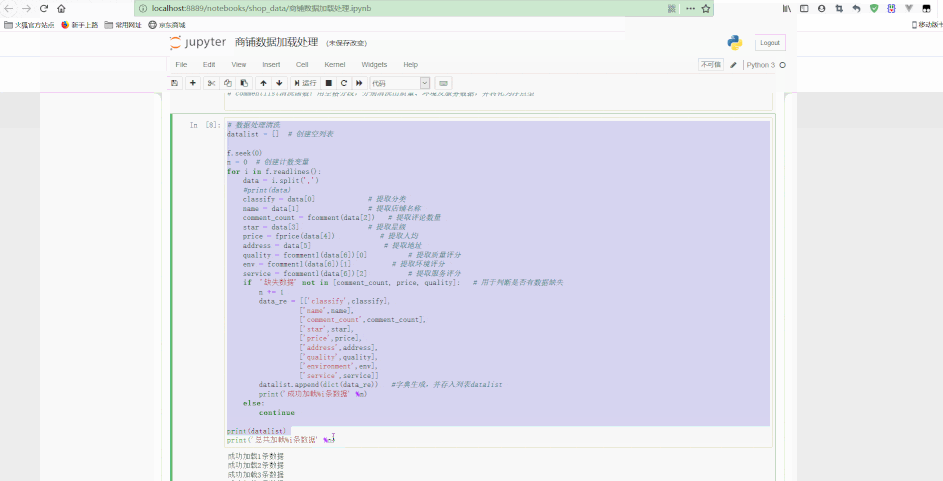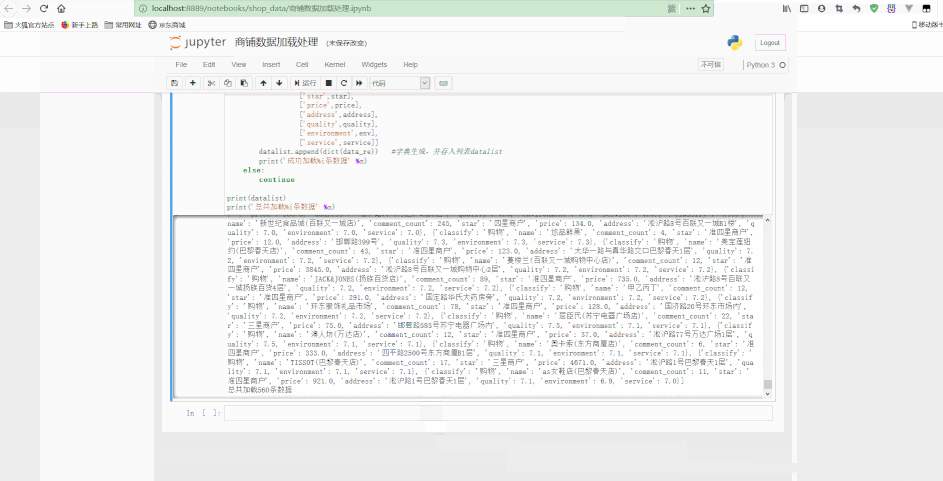
可以看到,最后得到了经过清洗后的规则数据。
完整Python代码如下:
# 数据读取f = open('商铺数据.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]:
print(i.split(','))# 创建comment、price、commentlist清洗函数def fcomment(s):
'''comment清洗函数:用空格分段,选取结果list的第一个为点评数,并且转化为整型'''
if '条' in s:
return int(s.split(' ')[0])
else:
return '缺失数据'def fprice(s):
'''price清洗函数:用¥分段,选取结果list的最后一个为人均价格,并且转化为浮点型'''
if '¥' in s:
return float(s.split('¥')[-1])
else:
return '缺失数据'def fcommentl(s):
'''commentlist清洗函数:用空格分段,分别清洗出质量、环境及服务数据,并转化为浮点型'''
if ' ' in s:
quality = float(s.split(' ')[0][2:])
environment = float(s.split(' ')[1][2:])
service = float(s.split(' ')[2][2:-1])
return [quality, environment, service]
else:
return '缺失数据'# 数据处理清洗datalist = [] # 创建空列表f.seek(0)n = 0 # 创建计数变量for i in f.readlines():
data = i.split(',')
# print(data)
classify = data[0] # 提取分类
name = data[1] # 提取店铺名称
comment_count = fcomment(data[2]) # 提取评论数量
star = data[3] # 提取星级
price = fprice(data[4]) # 提取人均
address = data[5] # 提取地址
quality = fcommentl(data[6])[0] # 提取质量评分
env = fcommentl(data[6])[1] # 提取环境评分
service = fcommentl(data[6])[2] # 提取服务评分
if '缺失数据' not in [comment_count, price, quality]: # 用于判断是否有数据缺失
n += 1
data_re = [['classify', classify],
['name', name],
['comment_count', comment_count],
['star', star],
['price', price],
['address', address],
['quality', quality],
['environment', env],
['service', service]]
datalist.append(dict(data_re)) # 字典生成,并存入列表datalist
print('成功加载%i条数据' % n)
else:
continueprint(datalist)print('总共加载%i条数据' % n)f.close()
更多编程相关知识,请访问:编程教学!!
위 내용은 Python 데이터 분석 실용 개요 데이터 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!