
Redis 버전 6.0의 새로운 기능 소개

- 王林앞으로
- 2021-01-08 09:08:502975검색

Redis 6.0 안정 버전
Redis 6.0.0 안정 버전은 새로운 네트워크 프로토콜 RESP3, 새로운 클러스터 프록시, ACL 등과 같은 많은 새로운 기능과 기능적 개선 사항을 제공합니다. 아직은 모두가 가장 우려하는 부분이 "멀티스레딩"이 아닐까 생각합니다. 이제 Redis 6.0 버전의 새로운 기능을 살펴보겠습니다.
(학습 동영상 공유: redis 동영상 튜토리얼)
1. Redis 6.0 이전 버전은 정말 단일 스레드인가요?
Redis가 획득(소켓 읽기), 구문 분석, 실행, 콘텐츠 반환(소켓 쓰기) 등을 포함한 클라이언트 요청을 처리할 때 모두 순차 및 직렬 메인 스레드로 처리됩니다. 실". 그러나 엄밀히 말하면 Redis 4.0부터는 단일 스레드가 아닙니다. 기본 스레드 외에도 더티 데이터 정리, 쓸모 없는 연결 해제, 큰 키 삭제 등과 같은 일부 느린 작업을 처리하는 백그라운드 스레드도 있습니다.
2. Redis6.0 이전에는 왜 멀티스레딩을 사용하지 않았나요?
비슷한 질문에 대해 공식 답변을 주셨습니다: Redis를 사용할 때 Redis는 주로 메모리와 네트워크의 제한으로 인해 CPU가 병목 현상이 발생하는 상황이 거의 없습니다. 예를 들어 일반적인 Linux 시스템에서 Redis는 파이프라이닝을 사용하여 초당 100만 개의 요청을 처리할 수 있으므로 애플리케이션이 주로 O(N) 또는 O(log(N)) 명령을 사용하는 경우 CPU를 거의 차지하지 않습니다.
단일 스레드 사용 후 유지 관리성이 높습니다. 멀티스레딩 모델은 일부 측면에서 잘 작동하지만 프로그램 실행 순서에 불확실성이 발생하고 동시 읽기 및 쓰기에 일련의 문제가 발생하며 시스템 복잡성이 증가하고 스레드 전환 또는 심지어 잠금이 발생할 수 있습니다. 잠금 해제 및 교착 상태를 통해. Redis는 AE 이벤트 모델, IO 다중화 및 기타 기술을 통해 매우 높은 처리 성능을 제공하므로 멀티 스레딩을 사용할 필요가 없습니다. 단일 스레드 메커니즘은 Redis 내부 구현의 복잡성을 크게 줄여주며, Rehash, Lpush 및 기타 "스레드 안전하지 않은" 명령은 잠금 없이 실행될 수 있습니다.
3. Redis6.0이 멀티스레딩을 도입하는 이유는 무엇인가요?
Redis는 모든 데이터를 메모리에 저장합니다. 작은 데이터 패킷의 경우 Redis 서버는 80,000~100,000 QPS를 처리할 수 있습니다. 이는 Redis 처리의 한계이기도 합니다. 단일 스레드 Redis이면 충분합니다.
그러나 비즈니스 시나리오가 점점 더 복잡해지면서 일부 회사는 수억 건의 거래에 쉽게 도달할 수 있으므로 더 큰 QPS가 필요합니다. 일반적인 솔루션은 분산 아키텍처에서 데이터를 분할하고 여러 서버를 사용하는 것이지만 이 솔루션은 관리할 Redis 서버가 너무 많고 유지 관리 비용이 높다는 등 매우 큰 단점이 있으며 일부 솔루션은 단일 Redis 서버에 적합합니다. 데이터 파티션에서는 작동하지 않습니다. 데이터 파티션은 핫스팟 읽기/쓰기 문제를 해결할 수 없으며, 재할당 및 확장/축소가 더 복잡해집니다.
Redis 자체의 관점에서 보면 읽기 및 쓰기 네트워크의 읽기/쓰기 시스템 호출이 Redis 실행 중 CPU 시간의 대부분을 차지하기 때문에 병목 현상은 주로 네트워크의 IO 소비에서 발생합니다. 최적화를 위한 두 가지 주요 방향이 있습니다. :
• 네트워크 IO 성능 향상, DPDK를 사용하여 커널 네트워크 스택 교체와 같은 일반적인 구현
• 멀티 스레딩을 사용하여 멀티 코어를 완전히 활용, Memcached와 같은 일반적인 구현.
이 프로토콜 스택 최적화 방법은 Redis와 관련이 거의 없습니다. 멀티 스레딩을 지원하는 것이 가장 효과적이고 편리한 작업 방법입니다. 요약하면 Redis는 두 가지 주요 이유로 멀티스레딩을 지원합니다.
• 서버 CPU 리소스를 최대한 활용할 수 있습니다. 현재 메인 스레드는 하나의 코어만 사용할 수 있습니다
• 멀티스레드 작업은 Redis 동기 IO 읽기를 공유할 수 있습니다. 그리고 load
4를 작성하세요. Redis6.0은 기본적으로 멀티스레딩을 활성화하나요?
Redis 6.0의 멀티스레딩은 기본적으로 비활성화되어 있으며 기본 스레드만 사용됩니다. 이를 활성화하려면 redis.conf 구성 파일을 수정해야 합니다: io-threads-do-reads yes
5 Redis6.0 멀티 스레딩이 활성화되면 스레드 수를 설정하는 방법입니다. ?
멀티스레딩을 켠 후에는 스레드 수를 설정해야 합니다. 그렇지 않으면 적용되지 않습니다. 또한 redis.conf 구성 파일을 수정하세요
스레드 수 설정과 관련하여 공식적인 제안이 있습니다: 4코어 컴퓨터는 2개 또는 3개 스레드로 설정하는 것이 좋습니다. 8코어 컴퓨터는 2개 또는 3개 스레드로 설정하는 것이 좋습니다. 스레드 수는 6개 스레드로 설정됩니다. 스레드 수는 머신 코어 수보다 작아야 합니다. 또한 스레드 수가 많을수록 8개 이상의 스레드는 기본적으로 의미가 없다고 관계자들은 믿고 있습니다.
6. Redis6.0에 멀티스레딩을 적용한 후 성능 개선 효과는 무엇인가요?
Redis 작성자 antirez가 RedisConf 2019에서 공유할 때 언급한 내용: Redis 6에 도입된 멀티 스레드 IO 기능은 성능 향상을 최소한 두 배 이상 향상시킬 수 있습니다. 국내 전문가들도 불안정한 버전을 사용해 알리바바 클라우드 esc에서 테스트를 진행한 바 있다. 4스레드 IO에서 GET/SET 명령의 성능은 싱글스레드에 비해 거의 2배 정도 향상됐다.
테스트 환경:
Redis 서버: Alibaba Cloud Ubuntu 18.04, 8 CPU 2.5 GHZ, 8G 메모리, 호스트 모델 ecs.ic5.2xlarge
Redis 벤치마크 클라이언트: Alibaba Cloud Ubuntu 18.04, 8 2.5 GHZ CPU, 8G 메모리, 호스트 모델 ecs.ic5.2xlarge
테스트 결과: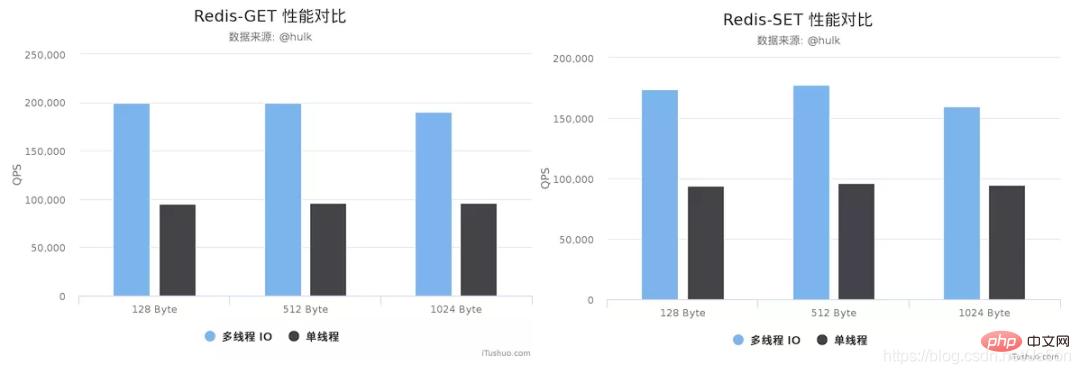
자세한 내용은 https://zhuanlan.zhihu.com/p/76788470
참고 1: 이러한 성능 검증 테스트는 엄격한 지연 제어 및 다양한 동시성 시나리오를 대상으로 하지 않습니다. 스트레스 테스트. 해당 데이터는 검증 참고용일 뿐이며 온라인 지표로 사용할 수 없습니다.
참고 2: 멀티스레딩을 활성화하는 경우 최소 4코어 머신을 사용하는 것이 좋으며 Redis 인스턴스는 상당한 양의 CPU 시간을 차지합니다. 그렇지 않으면 멀티스레딩을 사용할 필요가 없습니다. 그래서 회사 개발자의 80%가 그냥 살펴볼 것으로 추정됩니다.
7.Redis6.0 멀티스레딩 구현 메커니즘?
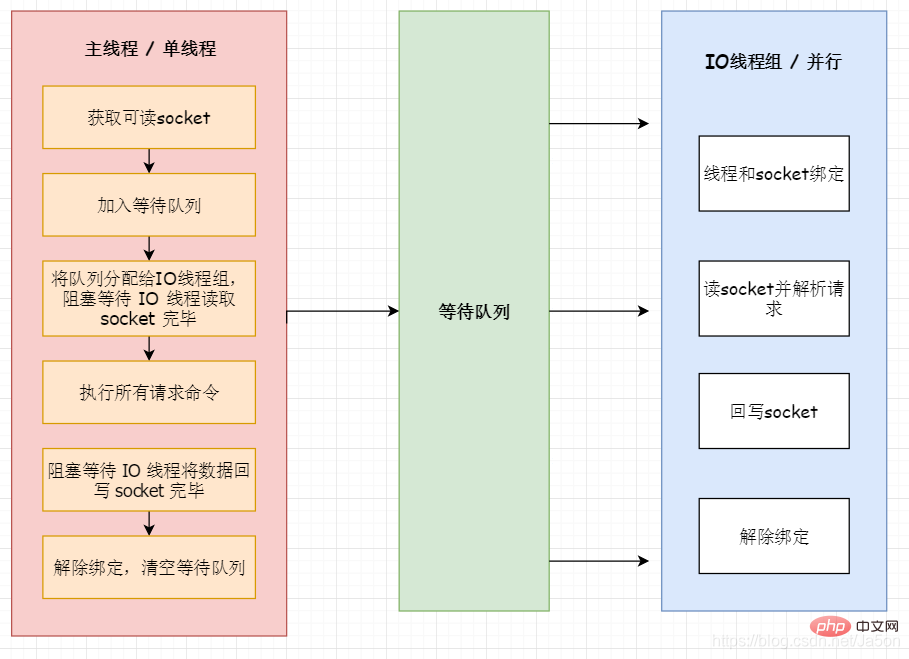
이 프로세스는 다음과 같이 간략하게 설명됩니다:
1. 메인 스레드는 연결 설정 요청을 수신하고 소켓을 가져와 전역 대기 읽기 처리 대기열에 넣는 역할을 담당합니다. 2. 메인 스레드는 읽기 이벤트를 처리하고 RR(Round Robin)을 전달합니다. 이러한 연결을 이러한 IO 스레드에 할당합니다.
3. 메인 스레드는 차단하고 IO 스레드가 소켓 읽기를 완료할 때까지 기다립니다.
4. 메인 스레드는 요청 명령을 실행합니다. 단일 스레드 방식으로 요청된 데이터를 읽고 구문 분석하지만 실행되지 않습니다.
5, 메인 스레드는 IO 스레드가 데이터를 소켓에 다시 쓸 때까지 차단하고 기다립니다.
6. 대기를 바인딩 해제하고 지웁니다. queue 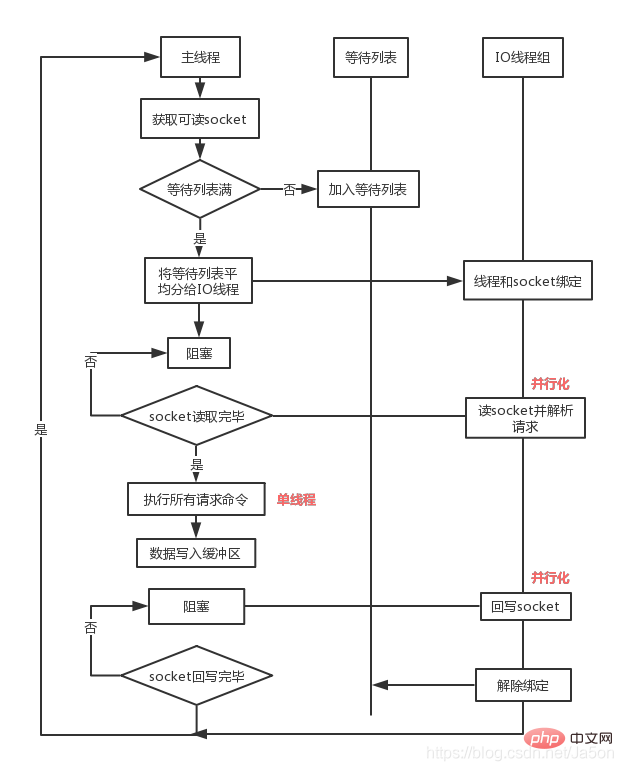 (사진출처: https://ruby-china.org/topics/38957)
(사진출처: https://ruby-china.org/topics/38957)
1. IO 스레드는 동시에 소켓을 읽거나, 2. IO 스레드는 소켓 구문 분석 명령을 읽고 쓰는 역할만 담당하며 명령 처리는 담당하지 않습니다.
위 구현 메커니즘에서 볼 수 있듯이 Redis의 멀티 스레드 부분은 네트워크 데이터 읽기 및 쓰기와 프로토콜 분석을 처리하는 데만 사용되며 명령 실행은 여전히 단일 스레드에서 순차적으로 실행됩니다. 따라서 키, Lua, 트랜잭션, LPUSH/LPOP 등을 제어하는 동시성 및 스레드 안전성 문제를 고려할 필요가 없습니다.
9. Linux 환경에 Redis6.0.1(6.0의 공식 버전은 6.0.1)을 설치하는 방법은 무엇입니까?이는 다른 Redis 버전을 설치하는 것과 별반 차이가 없으므로 여기서는 설명하지 않겠습니다. 주의할 점은 구성된 멀티 스레드 수가 CPU의 코어 수보다 작아야 한다는 것입니다.
[root@centos7.5 ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-310 명령을 사용하여 코어 수를 확인하세요. Redis6의 멀티 스레드 모델을 비교하세요. 0과 Memcached의 멀티스레딩 모델
예전에는 Memcached가 주요 인터넷 기업에서 흔히 사용하는 캐싱 솔루션이었습니다. 따라서 Redis와 Memcached의 차이점은 기본적으로 캐싱과 관련해 면접관들이 꼭 물어봐야 할 면접 질문이 되었습니다. 최근에는 memcached의 사용이 줄어들고 redis가 기본적으로 사용됩니다. 그러나 Redis 6.0에 멀티스레딩 기능이 추가되면서 비슷한 문제가 여전히 발생할 수 있습니다. 다음으로 멀티스레딩 모델에 대해서만 간략하게 비교하겠습니다.
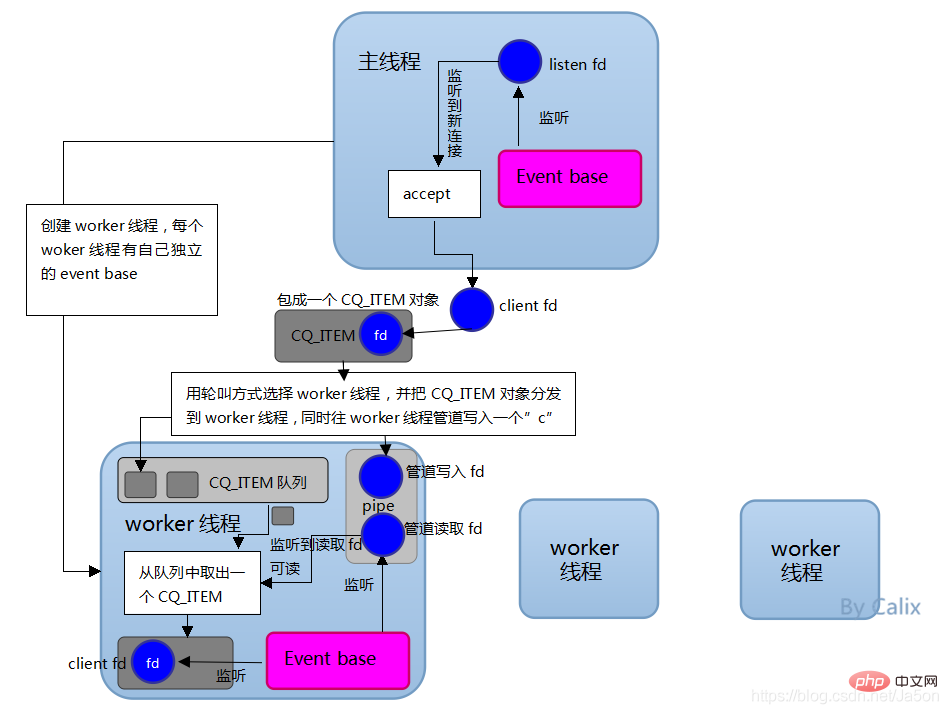 위 그림과 같이 Memcached 서버는 마스터-워커 모드로 작동하며 서버는 소켓을 사용하여 클라이언트와 통신합니다. 메인 스레드와 작업자 스레드는 파이프 파이프를 사용하여 통신합니다. 메인 스레드는 libevent를 사용하여 이벤트 응답 후 연결 정보의 데이터 구조를 캡슐화하고 알고리즘에 따라 적절한 작업 스레드를 선택하고 연결 정보를 전달하는 연결 작업을 배포합니다. 해당 스레드는 연결 설명자를 사용하여 설정하고 클라이언트의 소켓은 후속 데이터 액세스 작업을 연결하고 수행합니다.
위 그림과 같이 Memcached 서버는 마스터-워커 모드로 작동하며 서버는 소켓을 사용하여 클라이언트와 통신합니다. 메인 스레드와 작업자 스레드는 파이프 파이프를 사용하여 통신합니다. 메인 스레드는 libevent를 사용하여 이벤트 응답 후 연결 정보의 데이터 구조를 캡슐화하고 알고리즘에 따라 적절한 작업 스레드를 선택하고 연결 정보를 전달하는 연결 작업을 배포합니다. 해당 스레드는 연결 설명자를 사용하여 설정하고 클라이언트의 소켓은 후속 데이터 액세스 작업을 연결하고 수행합니다.
Redis6.0과 Memcached 멀티 스레딩 모델 비교:
유사성: 둘 다 마스터 스레드-작업자 스레드 모델을 채택합니다. 차이점: Memcached는 작업자 스레드에서 기본 논리도 실행하며 모델이 더 간단하여 진정한 스레드 격리를 달성합니다. , 스레드 격리에 대한 기존의 이해와 일치합니다. Redis는 처리 로직을 마스터 스레드에 반환하지만 어느 정도 모델의 복잡성을 증가시키지만 스레드 동시성 보안과 같은 문제도 해결합니다.
멀티 스레딩 기능과 관련하여 Antirez는 6.0 RC1에서 다음과 같이 설명했습니다.
Redis가 멀티 스레딩을 지원하는 두 가지 가능한 방법이 있습니다. 첫 번째는 "memcached"와 같으며, 하나의 Redis 인스턴스가 여러 스레드를 열어 스레드를 늘리는 것입니다. GET/SET과 같은 간단한 명령으로 초당 수행할 수 있는 작업입니다. 여기에는 I/O 및 명령 구문 분석과 같은 다중 스레드 처리가 포함되므로 "I/O 스레딩"이라고 합니다. 다른 하나는 다른 스레드에서 느린 명령을 실행하여 다른 클라이언트가 차단되지 않도록 하는 것입니다. 우리는 이 스레딩 모델을 "느린 명령 스레딩"이라고 부릅니다.
신중하게 고려한 후에 Redis는 "I/O 스레딩"을 사용하지 않습니다. Redis는 주로 런타임 중 네트워크 및 메모리에 의해 제한되므로 Redis 성능 향상은 주로 여러 Redis 인스턴스, 특히 Redis 클러스터를 통해 이루어집니다. 다음으로 개선 사항의 두 가지 측면을 주로 고려하겠습니다.
1. Redis 클러스터의 여러 인스턴스는 동시에 AOF를 다시 작성하지 않도록 오케스트레이션을 통해 로컬 인스턴스의 디스크를 합리적으로 사용할 수 있습니다.
2. 더 나은 클러스터 프로토콜 클라이언트가 없을 때 사용자가 클러스터를 추상화할 수 있도록 Redis 클러스터 프록시를 제공합니다.
그리고 Redis는 Memcached와 같은 메모리 시스템이지만 Memcached와는 다릅니다. 멀티스레딩은 복잡하므로 LPUSH를 실행하는 스레드는 LPOP를 실행하는 다른 스레드를 서비스해야 합니다.
제가 정말로 기대하는 것은 실제로 "느린 작업 스레딩"입니다. redis6 또는 redis7에서는 스레드가 느린 작업을 처리하기 위해 키를 완전히 제어할 수 있도록 "키 수준 잠금"이 제공됩니다.
참조: http://antirez.com/news/126
12. IO 멀티플렉싱은 Redis 스레드에서 자주 언급됩니다.
이것은 비동기 차단 IO라고도 하는 고전적인 Reactor 디자인 패턴인 IO 모델의 한 유형입니다. 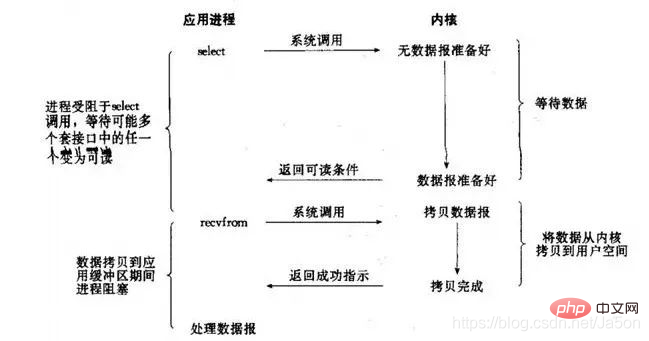
다중 채널은 여러 소켓 연결을 의미하고 재사용은 하나의 스레드를 재사용하는 것을 의미합니다. 다중화 기술에는 select, poll, epoll의 세 가지 주요 기술이 있습니다. epoll은 최신 및 최고의 다중화 기술입니다. 다중 채널 I/O 다중화 기술을 사용하면 단일 스레드가 여러 연결 요청을 효율적으로 처리할 수 있으며(네트워크 IO의 시간 소모 최소화) Redis는 메모리에서 데이터를 매우 빠르게 작동합니다(여기서 메모리 내 작업은 문제가 되지 않습니다). ). 성능 병목 현상), 위의 두 가지 점은 주로 Redis의 높은 처리량에 기여합니다.
13. 레디스의 이스터 에그 롤윗(LOLWUT)을 아시나요?
이 기능은 실제로 Redis 5.0부터 사용 가능했지만, 알고만 있었던 점 양해 부탁드립니다. 저자는 이 기능을 "LOLWUT: 데이터베이스 명령 내부의 예술 작품", "데이터베이스 명령 내부의 예술 작품"이라고 설명합니다. 감정이라고 부를 수도 있고, 부활절 달걀이라고 부를 수도 있습니다. 구체적으로 무엇인지는 밝히지 않겠습니다. 저 같은 게 뭔지 모르는 친구들은 http://antirez.com/news/123를 참고하시면 실행될 때마다 무작위로 생성됩니다. 
관련 권장 사항: redis 데이터베이스 튜토리얼
위 내용은 Redis 버전 6.0의 새로운 기능 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!