
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에 대한 나의 이해 2부: 인덱스
MySQL에 대한 나의 이해 2부: 인덱스

- coldplay.xixi앞으로
- 2020-10-21 17:05:352386검색
오늘의
mysql tutorial 칼럼에서는 관련 인덱스 지식을 소개합니다.

MySQL 시리즈의 두 번째 기사에서는 인덱스 유형, 데이터 모델, 인덱스 실행 프로세스, 가장 왼쪽 접두사 원칙, 인덱스 실패 상황, 인덱스 푸시다운 등을 포함하여 MySQL의 인덱스에 관한 몇 가지 문제를 주로 논의합니다.
인덱스에 대해 처음 배운 것은 2학년 때 데이터베이스 원리 과정에서 쿼리문이 매우 느릴 때 특정 필드에 인덱스를 추가하여 쿼리 효율성을 향상할 수 있습니다.
아주 고전적인 예도 있습니다. 데이터베이스를 사전으로, 색인을 디렉토리로 생각하면 사전의 디렉토리를 사용하여 단어를 쿼리할 때 색인의 역할이 반영될 수 있습니다.
1. 인덱스 유형
MySQL에서는 인덱스의 로직이나 필드 특성에 따라 인덱스를 크게 일반 인덱스, 고유 인덱스, 기본 키 인덱스, 조인트 인덱스, 접두사 인덱스로 구분합니다.
- 일반 인덱스: 어떠한 제한도 없는 가장 기본적인 인덱스입니다.
- 고유 인덱스: 인덱스 열의 값은 고유해야 합니다.
- 기본 키 인덱스: 특수 고유 인덱스로, 기본 키 값은 비워 둘 수 없습니다.
- 조인트 인덱스: 조인트 인덱스는 인덱스 열에 여러 필드가 있는 일반 인덱스입니다. 가장 왼쪽 접두사 원칙을 고려해야 합니다.
- 접두사 색인: 문자 유형의 처음 몇 문자 또는 바이너리 유형의 처음 몇 바이트를 색인화합니다.
물리적 저장소와 구별되는 또 다른 인덱스 분류로는 클러스터형 인덱스와 비클러스터형 인덱스가 있습니다.
- 클러스터형 인덱스: 인덱스 순서는 데이터 저장 순서와 일치하며 리프 노드는 데이터 행을 저장합니다.
- 비클러스터형 인덱스: 비클러스터형 인덱스의 리프 노드에는 클러스터형 인덱스의 값이 저장되며, 클러스터형 인덱스를 기반으로 생성됩니다.
간단히 말하면, 소위 클러스터형 인덱스는 인덱스 키와 데이터 행이 함께 있는 것을 의미하며, 논클러스터형 인덱스의 인덱스 키에 해당하는 값이 클러스터형 인덱스의 값이 됩니다.
2. 인덱스 데이터 구조
인덱스를 구현하는 데 사용되는 일반적인 데이터 구조에는 해시 테이블, 순서 배열 및 검색 트리가 포함됩니다.
2.1 Hash Index
해시 테이블은 HashMap과 마찬가지로 특정 해시 함수를 통해 키의 인덱스 값을 계산한 후 이를 추가하는 컨테이너입니다. 키에 해당하는 값은 해당 위치에 저장됩니다. 해시 함수에 의해 계산된 동일한 인덱스 값을 가진 두 개의 키가 있는 경우(해시 충돌이 발생함) 배열의 이 위치는 연결 목록이 됩니다. 모든 값을 동일한 해시 값으로 저장합니다.
그래서 일반적인 상황에서는 해시 테이블의 등가 쿼리의 시간 복잡도가 O(1)에 도달할 수 있지만, 해시 충돌이 발생하는 경우 연결 목록의 모든 값을 추가로 순회해야 합니다. 일치하는 조건부 데이터를 찾으려면
그리고 해시 함수로 계산한 인덱스가 불규칙하다는 점을 고려하면, 해시 테이블은 모든 키가 완전히 해시되어 공간 낭비 없이 키가 균등하게 분산될 수 있기를 바라고 있습니다. 즉, 해시 테이블의 핵심은 비순차적이므로 해시 테이블을 사용하여 범위 쿼리를 수행하는 것은 정렬에서도 마찬가지입니다.
따라서 해시 테이블은 동등 쿼리에만 적합합니다.
2.2 순서 배열
이름에서 알 수 있듯이 순서 배열은 동일한 쿼리에 대한 시간 복잡도가 해시 테이블보다 열등한 O(logN)에 도달할 수 있습니다. 약간의.
그러나 순서 배열을 통한 범위 쿼리가 더 효율적입니다. 먼저 이진 쿼리를 통해 최소값(또는 최대값)을 찾은 다음 다른 경계까지 반대 방향으로 탐색합니다.
정렬에 관해서는 순서 배열은 본질적으로 정렬되어 자연스럽게 정렬됩니다. 물론 정렬 필드는 인덱스 필드가 아니므로 별도로 이야기하겠습니다.
그러나 정렬된 배열에는 단점이 있습니다. 배열 요소는 연속적이고 정렬되어 있기 때문에 이때 새로운 데이터 행이 삽입되면 정렬된 배열의 질서를 유지하기 위해 이 요소의 키보다 큰 요소가 삽입됩니다. 그런 다음 장치를 이동하여 삽입할 위치를 만듭니다. 그리고 이러한 방식으로 인덱스를 유지하는 데 드는 비용은 매우 높습니다.
그래서 순서 배열은 옷이 초기화된 후에는 더 이상 업데이트되지 않는 데이터를 저장하는 데 적합합니다.
2.3 검색 트리
데이터 구조를 아는 사람은 검색 트리가 쿼리 시간 복잡도가 O(logN)이고 업데이트 시간 복잡도가 O(logN)인 데이터 구조라는 것을 알아야 합니다. 따라서 해시 테이블 및 정렬된 배열과 비교하여 검색 트리는 쿼리 및 업데이트 측면을 모두 고려합니다. 이것이 MySQL에서 가장 일반적으로 사용되는 데이터 모델이 검색 트리인 이유입니다.
인덱스가 디스크에 저장된다는 점을 고려하면 검색 트리가 이진 트리인 경우 왼쪽 및 오른쪽 자식 노드가 2개만 있을 수 있습니다. 데이터가 많은 경우 이 이진 트리의 높이가 매우 커질 수 있습니다. 높음. MySQL이 쿼리를 수행할 때 트리 높이로 인해 디스크 I/O 시간이 너무 길어지고 쿼리 효율성이 저하될 수 있습니다.
2.4 전체 텍스트 색인
또한 역 색인을 설정하여 필드 포함 여부를 결정하는 문제를 해결하는 전체 텍스트 색인도 있습니다.
역색인은 전체 텍스트 검색 시 문서 또는 문서 그룹의 단어 저장 위치 매핑을 저장하는 데 사용됩니다. 역색인을 통해 해당 단어를 기반으로 해당 단어가 포함된 문서 목록을 빠르게 얻을 수 있습니다. 단어.
키워드로 검색할 때 전체 텍스트 색인이 유용합니다.
3. InnoDB의 BTree 인덱스
3.1 B+ 트리
이것은 비교적 간단한 B+ 트리입니다.
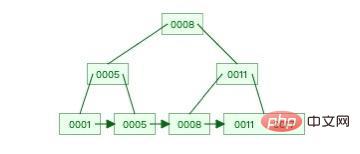
이미지 출처: Data Structure Visualizations
또한 위의 예시 그림에서 볼 수 있듯이 이 B+ 트리의 가장 낮은 리프 노드는 모든 요소를 저장하며 리프 노드는 요소만 저장하는 것이 아니라 순서대로 저장됩니다. 인덱스 열의 값입니다.
3.2 BTree 인덱스 예시
InnoDB에서는 BTree를 기반으로 한 인덱스 모델이 가장 일반적으로 사용됩니다. 다음은 InnoDB의 BTree 인덱스 구조를 설명하는 실제적인 예입니다.
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码
이 테이블에는 기본 키 id와 이름 필드 두 개의 필드만 있고, 이름 필드를 인덱스 열로 하는 BTree 인덱스가 설정됩니다.
기본 키 ID 필드를 기반으로 하는 인덱스는 기본 키 인덱스라고도 합니다. 인덱스 트리 구조는 인덱스 트리의 리프가 아닌 단계에 기본 키 ID 값이 저장되고, 리프에 값이 저장됩니다. 노드는 기본 키 ID가 해당 전체 데이터 행 에 해당하며 아래 그림과 같습니다.
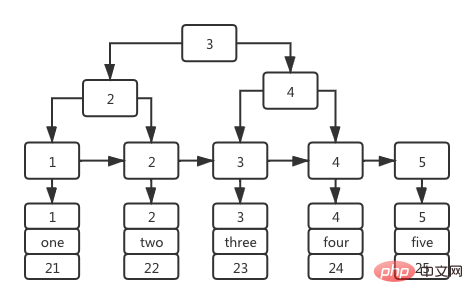
또한 기본 키 인덱스의 리프 노드에는 기본 키 ID에 해당하는 전체 데이터 행이 저장되므로 기본 키 인덱스는 클러스터형 인덱스라고도 합니다.
name 필드를 열로 하는 인덱스 트리에서 리프가 아닌 노드도 인덱스 열의 값을 저장하며, 리프 단계에 저장된 값은 그림과 같이 기본 키 id의 값입니다. 아래 그림.
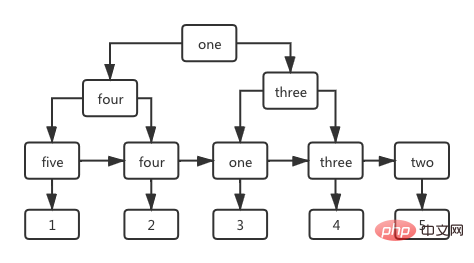
3.3 인덱스 실행 과정
먼저 사용자 테이블에서 id=1인 데이터 행을 쿼리하려면 다음 SQL 문장을 살펴보세요.
select * from user where id=1;复制代码
이 SQL의 실행 프로세스는 매우 간단합니다. 스토리지 엔진은 기본 키 ID의 인덱스 트리를 통해 id=1을 찾으면 인덱스 트리에서 id=1인 데이터 행을 반환합니다. 기본 키 값은 고유하기 때문에 적중 대상이 발견되면 검색이 중지되고 결과 집합이 직접 반환됩니다.
3.3.1 테이블로 돌아가기
다음으로 일반 인덱스를 사용한 쿼리를 살펴보겠습니다. 기본 키 인덱스와는 약간 다른 상황입니다.
select * from user where name='one';复制代码
위 SQL 쿼리 문의 프로세스는 다음과 같습니다. 먼저 스토리지 엔진은 일반 인덱스 이름 열의 인덱스 트리를 검색합니다. 매우 중요한 단계: 테이블로 돌아가기 .
일반 인덱스의 인덱스 트리 하위 노드에는 기본 키 값이 저장되므로 쿼리 문에서 기본 키 id와 인덱스 열을 제외한 다른 필드를 쿼리해야 하는 경우 쿼리 기반 쿼리를 위해 기본 키 인덱스 트리로 돌아가야 합니다. 기본 키 id 값에서 기본 키 id에 해당하는 전체 데이터 행을 가져온 다음 이 행을 결과 집합에 추가하기 전에 클라이언트가 요구하는 필드를 가져옵니다.
그러면 스토리지 엔진은 name='one'을 충족하지 않는 첫 번째 레코드를 발견할 때까지 인덱스 트리를 계속 검색합니다. 그런 다음 검색을 중지하고 마지막으로 모든 적중 레코드를 클라이언트에 반환합니다. . name='one' 的记录才会停止搜索,最后将所有命中的记录返回客户端。
我们把根据从普通索引查询到的主键 id 值,再在主键索引中查询整个数据行的过程称之为回表。
当数据量十分庞大时,回表是一个十分耗时的过程,所以我们应该尽量避免回表发生,这就引出了下一个问题:使用覆盖索引避免回表。
3.3.2 覆盖索引
不知道你有没有注意到,在上一个回表的问题中有这样一句描述:“当查询语句需要查询除主键 id 及索引列之外的其他字段时...”,在这种场景下需要通过回表来获取其他的查询字段。也就是说,如果查询语句需要查询的字段仅有主键 id 和索引列的字段时,是不是就不需要回表了?
下面来分析一波这个过程,首先建立一个联合索引。
alter table user add index name_age ('name','age');复制代码
那么这棵索引树的结构图应该是下面这样:

联合索引索引树的子节点顺序是按照声明索引时的字段来排序的,类似于 order by name, age
3.3.2 Covering index🎜🎜이전 테이블 반환 질문에 "쿼리 문이 쿼리해야 하는 경우"와 같은 설명이 있다는 것을 눈치채셨는지 모르겠습니다. 기본 키 ID 및 인덱스 열 이외의 다른 필드..." 이 시나리오에서는 테이블을 반환하여 다른 쿼리 필드를 가져와야 합니다. 즉, 쿼리문이 기본키 id와 인덱스 컬럼의 필드만 쿼리하면 되는 경우에는 테이블을 반환할 필요가 없는 걸까요? 🎜🎜 먼저 이 과정을 분석해 보겠습니다. 🎜select name,age from user where name='one';复制代码
🎜그러면 이 인덱스 트리의 구조 다이어그램은 다음과 같아야 합니다: 🎜🎜 🎜🎜공동 색인 색인 트리의 하위 노드 순서는 색인이 생성될 때 필드에 따라 정렬됩니다.
🎜🎜공동 색인 색인 트리의 하위 노드 순서는 색인이 생성될 때 필드에 따라 정렬됩니다. order by name, age와 유사하게 선언되며, 해당 인덱스에 해당하는 값은 일반 인덱스와 마찬가지로 기본 키 값입니다. 🎜select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
4. 最左前缀原则
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
5. 索引失效场景
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
5.1 全字段匹配
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
5.2 部分字段匹配
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
- 第一个数字 1 是该字段声明时的长度。
- 第二个数字 3 是该字段字符类型的长度:utf8=3, gbk=2, latin1=1。
- 第三个数字 1 是该字段的默认类型,若默认允许 NULL,第三个数字是 1,因为 NULL 需要一个字节的额外空间;若默认不允许 NULL,这里应该是0。
- 第四个数字 2 是 varchar 类型的变长字段需要附加的字节。
所以这两条查询语句使用索引的情况是:
- 使用联合索引,索引长度为 12 字节,使用到的索引字段是 a,b 字段;
- 使用联合索引,索引长度为 6 字节,使用到的索引字段是 a 字段;
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
5.3 范围查询
第三种情况是查询条件用的是范围查询(,!=,=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
- like 必须要求是左模糊匹配才能用到索引,因为字符类型字段的索引树也是有序的。
- between 并不一定是范围查询,它相当于使用 in 多值精确匹配,所以 between 并不会因为是范围查询就让联合索引后面的索引列失效。
5.4 查询条件为函数或表达式
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
5.5 其他索引失效的场景
- 查询影响行数大于全表的25%
- 查询条件使用 (!=), not in, is not null
- in 查询条件中值数据类型不一致,MySQL 会将所有值转化为与索引列一致的数据类型,从而无法使用索引
6. 索引下推
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
7. 温故知新
- 索引分类?聚簇索引结构?非聚簇索引结构?
- 常用的实现索引的数据模型?
- B+树索引的执行流程?
- 什么是回表?如何优化?
- 什么是覆盖索引?
- 什么是最左前缀原则?
- 索引在哪些情况下可能会失效?
- 什么是索引下推?
更多相关免费学习推荐:mysql教程(视频)
위 내용은 MySQL에 대한 나의 이해 2부: 인덱스의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!