
Node.js+Chrome+Puppeteer를 사용하여 웹사이트 크롤링

- 青灯夜游앞으로
- 2020-09-16 09:53:183147검색

동영상 튜토리얼 추천: nodejs 튜토리얼
무엇을 배울까요?
이 튜토리얼에서는 JavaScript를 사용하여 웹을 자동화하고 정리하는 방법을 배웁니다. 이를 위해 Puppeteer를 사용하겠습니다. Puppeteer는 헤드리스 Chrome을 제어할 수 있는 노드 라이브러리 API입니다. Headless Chrome은 실제로 Chrome을 실행하지 않고 Chrome 브라우저를 실행하는 방법입니다.
이 중 어느 것도 말이 되지 않는다면, 실제로 알아야 할 것은 Google Chrome을 자동화하기 위해 JavaScript 코드를 작성한다는 것입니다.
시작하기 전에
시작하기 전에 컴퓨터에 Node 8 이상이 설치되어 있어야 합니다. 여기에서 설치할 수 있습니다. "현재" 버전 8+를 선택하세요.
이전에 Node를 사용해 본 적이 없고 배우고 싶다면 다음을 확인하세요. Node JS 알아보기 3 최고의 온라인 Node JS 코스.
Node 설치 후 새 프로젝트 폴더를 생성하고 Puppeteer를 설치하세요. Puppeteer에는 API와 함께 사용할 수 있는 최신 버전의 Chromium이 함께 제공됩니다.
npm install --save puppeteer
예제 #1 — 스크린샷
Puppeteer를 설치한 후 간단한 예부터 시작하겠습니다. 이 예는 Puppeteer 문서에서 가져온 것입니다(사소한 변경 포함). 귀하가 방문하는 웹사이트의 스크린샷을 찍는 방법을 코드를 통해 단계별로 안내해 드리겠습니다.
먼저 test.js라는 파일을 만들고 다음 코드를 복사하세요. test.js的文件,然后复制以下代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
让我们逐行浏览这个例子。
- 第1行: 我们需要我们先前安装的 Puppeteer 依赖项
-
第3-10行:这是我们的主函数
getPic()。该函数将保存我们所有的自动化代码。 -
第12行:在第12行上,我们调用
getPic()函数。
需要注意的是,getPic()函数是一个异步函数,并利用了新的ES 2017async/await功能。由于这个函数是异步的,所以当调用时它返回一个Promise。当Async函数最终返回值时,Promise将被解析(如果存在错误,则Reject)。
由于我们使用的是async函数,因此我们可以使用await表达式,该表达式将暂停函数执行并等待Promise解析后再继续。 如果现在所有这些都没有意义,那也没关系。随着我们继续学习教程,它将变得更加清晰。
现在,我们概述了主函数,让我们深入了解其内部功能:
- 第4行:
const browser = await puppeteer.launch();
这是我们实际启动 puppeteer 的地方。实际上,我们正在启动 Chrome 实例,并将其设置为等于我们新创建的browser变量。由于我们使用了await关键字,因此该函数将在此处暂停,直到Promise解析(直到我们成功创建 Chrome 实例或出错)为止。
- 第5行:
const page = await browser.newPage();
在这里,我们在自动浏览器中创建一个新页面。我们等待新页面打开并将其保存到我们的page变量中。
- 第6行:
await page.goto('https://google.com');
使用我们在代码的最后一行中创建的page,现在可以告诉page导航到URL。在此示例中,导航到 google。我们的代码将暂停,直到页面加载完毕。
- 第7行:
await page.screenshot({path: 'google.png'});
现在,我们告诉 Puppeteer 截取当前页面的屏幕。screenshot()方法将自定义的.png屏幕截图的保存位置的对象作为参数。同样,我们使用了await关键字,因此在执行操作时我们的代码会暂停。
- 第9行:
await browser.close();
最后,我们到了getPic()函数的结尾,并且关闭了browser。
运行示例
您可以使用 Node 运行上面的示例代码:
node test.js
这是生成的屏幕截图:
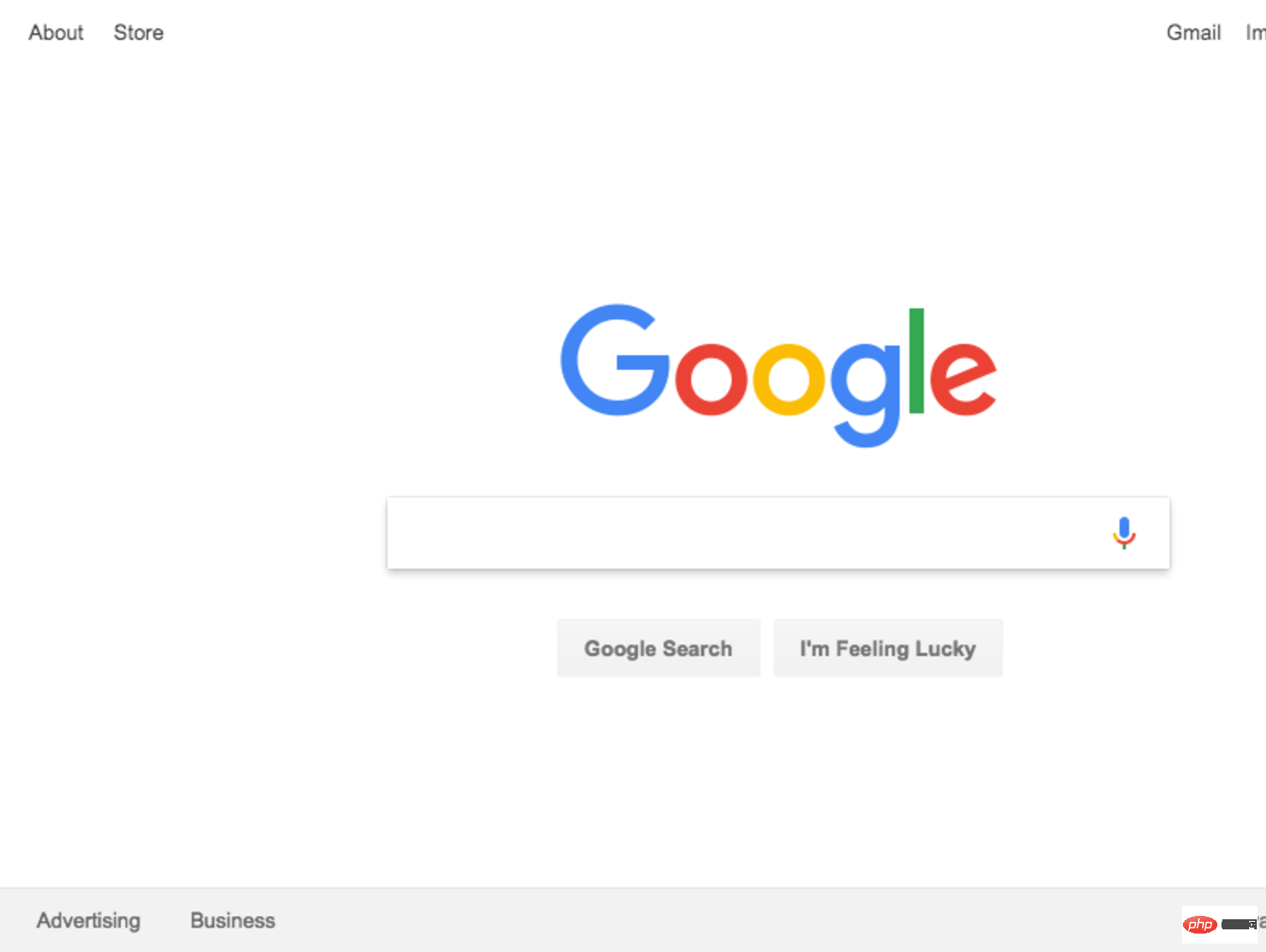
太棒了!为了增加乐趣(并简化调试),我们可以不以无头方式运行代码。
这到底是什么意思?自己尝试一下,看看吧。更改代码的第4行从:
const browser = await puppeteer.launch();
改为:
const browser = await puppeteer.launch({headless: false});
然后使用 Node 再次运行:
node test.js
太酷了吧?当我们使用{headless:false}
await page.setViewport({width: 1000, height: 500})이 예제를 한 줄씩 살펴보겠습니다. 🎜- 🎜Line 1: 🎜 앞서 설치한 Puppeteer 종속성이 필요합니다.
- 🎜Line 3-10: 🎜이것이 주요 함수
getPic()입니다. 이 함수는 모든 자동화 코드를 보유합니다. - 🎜12행: 🎜12행에서는
getPic()함수를 호출합니다.
getPic() 함수는 비동기 함수이며 새로운 ES 2017 async/를 활용한다는 점에 유의해야 합니다. 함수를 기다리세요. 이 함수는 비동기식이므로 호출 시 Promise를 반환합니다. Async 함수가 최종적으로 값을 반환하면 Promise가 해결됩니다(또는 오류가 있는 경우 Reject). 🎜🎜 async 함수를 사용하고 있으므로 함수 실행을 일시 중지하고 Promise가 실행될 때까지 기다리는 await 표현식을 사용할 수 있습니다. 해결하고 계속하세요. 🎜이 중 어느 것도 지금 이해가 되지 않더라도 괜찮습니다🎜. 튜토리얼을 계속 진행하면 더 명확해질 것입니다. 🎜🎜이제 주요 기능에 대한 개요를 살펴봤으니 내부 기능을 살펴보겠습니다. 🎜- 🎜4행: 🎜
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();🎜여기서 실제로 인형극을 시작합니다. 기본적으로 Chrome 인스턴스를 시작하고 새로 생성된 browser 변수와 동일하게 설정합니다. await 키워드를 사용했기 때문에 함수는 Promise가 해결될 때까지(Chrome 인스턴스를 성공적으로 생성하거나 오류가 발생할 때까지) 여기에서 일시 중지됩니다. 🎜- 🎜5번째 줄: 🎜
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});🎜여기서 자동 브라우저에 새 페이지를 만듭니다. 새 페이지가 열릴 때까지 기다렸다가 page 변수에 저장합니다. 🎜- 🎜6번째 줄: 🎜
let scrape = async () => {
return 'test';
};🎜코드의 마지막 줄에서 생성한 페이지를 사용하여 이제 페이지 해당 URL로 이동합니다. 이 예에서는 Google로 이동합니다. 페이지가 로드될 때까지 코드가 일시 중지됩니다. 🎜<ul><li>🎜7행: 🎜</li></ul>
<pre class="brush:php;toolbar:false">let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};</pre>🎜이제 Puppeteer에게 현재 <code>페이지의 스크린샷을 찍으라고 지시합니다. screenshot() 메서드는 스크린샷 저장 위치의 사용자 정의 .png 개체를 매개변수로 사용합니다. 이번에도 await 키워드를 사용하여 작업이 수행되는 동안 코드를 일시 중지했습니다. 🎜- 🎜라인 9: 🎜
const browser = await puppeteer.launch({headless: false});🎜마지막으로 getPic() 함수의 끝에 도달하고 브라우저를 닫습니다. 코드>. 🎜🎜🎜예제 실행🎜🎜🎜Node를 사용하여 위의 예 코드를 실행할 수 있습니다. 🎜<pre class="brush:php;toolbar:false">const page = await browser.newPage();</pre>🎜생성된 스크린샷은 다음과 같습니다. 🎜🎜<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/2d6f574ea6b652f9047628a160ebac6c-2.png" class="lazy" alt=""><br>멋지네요! 재미를 더하고 디버깅을 더 쉽게 하기 위해 헤드리스 실행 없이 코드를 실행할 수 있습니다. 🎜🎜이게 정확히 무슨 뜻인가요? 직접 해보고 확인해 보세요. 코드의 4행을 🎜<pre class="brush:php;toolbar:false">await page.goto('http://books.toscrape.com/');</pre>🎜에서 🎜<pre class="brush:php;toolbar:false">await page.waitFor(1000);</pre>🎜로 변경한 다음 Node: 🎜<pre class="brush:php;toolbar:false">browser.close();
return result;</pre>🎜를 사용하여 다시 실행하세요. 그렇죠? <code>{headless: false}로 실행하면 Google Chrome이 코드에 따라 작동하는 것을 실제로 볼 수 있습니다. 🎜在继续之前,我们将对这段代码做最后一件事。还记得我们的屏幕截图有点偏离中心吗?那是因为我们的页面有点小。我们可以通过添加以下代码行来更改页面的大小:
await page.setViewport({width: 1000, height: 500})
这个屏幕截图更好看点:
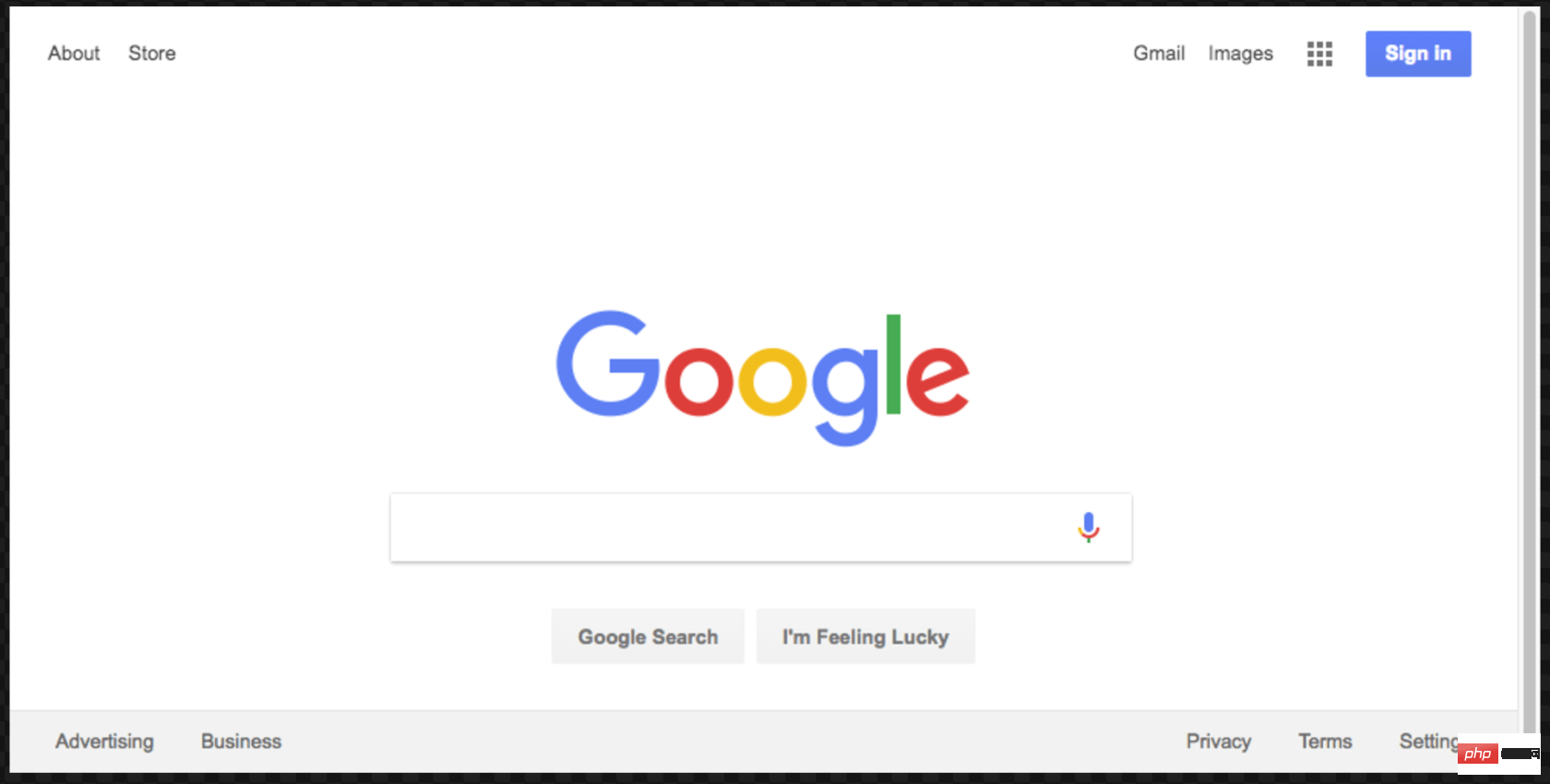
这是本示例的最终代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
示例 #2-让我们抓取一些数据
既然您已经了解了 Headless Chrome 和 Puppeteer 的工作原理,那么让我们看一个更复杂的示例,在该示例中我们事实上可以抓取一些数据。
首先, 在此处查看 Puppeteer 的 API 文档。 如您所见,我们有很多方法可以使用, 不仅可以点击网站,还可以填写表格,输入内容和读取数据。
在本教程中,我们将抓取 Books To Scrape ,这是一家专门设置的假书店,旨在帮助人们练习抓取。
在同一目录中,创建一个名为scrape.js的文件,并插入以下样板代码:
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});
理想情况下,在看完第一个示例之后,上面的代码对您有意义。如果没有,那没关系!
我们上面所做的需要以前安装的puppeteer依赖关系。然后我们有scraping()函数,我们将在其中填入抓取代码。此函数将返回值。最后,我们调用scraping函数并处理返回值(将其记录到控制台)。
我们可以通过在scrape函数中添加一行代码来测试以上代码。试试看:
let scrape = async () => {
return 'test';
};
现在,在控制台中运行node scrape.js。您应该返回test!完美,我们返回的值正在记录到控制台。现在我们可以开始补充我们的scrape函数。
步骤1:设置
我们需要做的第一件事是创建浏览器实例,打开一个新页面,然后导航到URL。我们的操作方法如下:
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};
太棒了!让我们逐行学习它:
首先,我们创建浏览器,并将headless模式设置为false。这使我们可以准确地观察发生了什么:
const browser = await puppeteer.launch({headless: false});
然后,我们在浏览器中创建一个新页面:
const page = await browser.newPage();
接下来,我们转到books.toscrape.com URL:
await page.goto('http://books.toscrape.com/');
我选择性地添加了1000毫秒的延迟。尽管通常没有必要,但这将确保页面上的所有内容都加载:
await page.waitFor(1000);
最后,完成所有操作后,我们将关闭浏览器并返回结果。
browser.close(); return result;
步骤2:抓取
正如您现在可能已经确定的那样,Books to Scrape 拥有大量的真实书籍和这些书籍的伪造数据。我们要做的是选择页面上的第一本书,然后返回该书的标题和价格。这是要抓取的图书的主页。我有兴趣点第一本书(下面红色标记)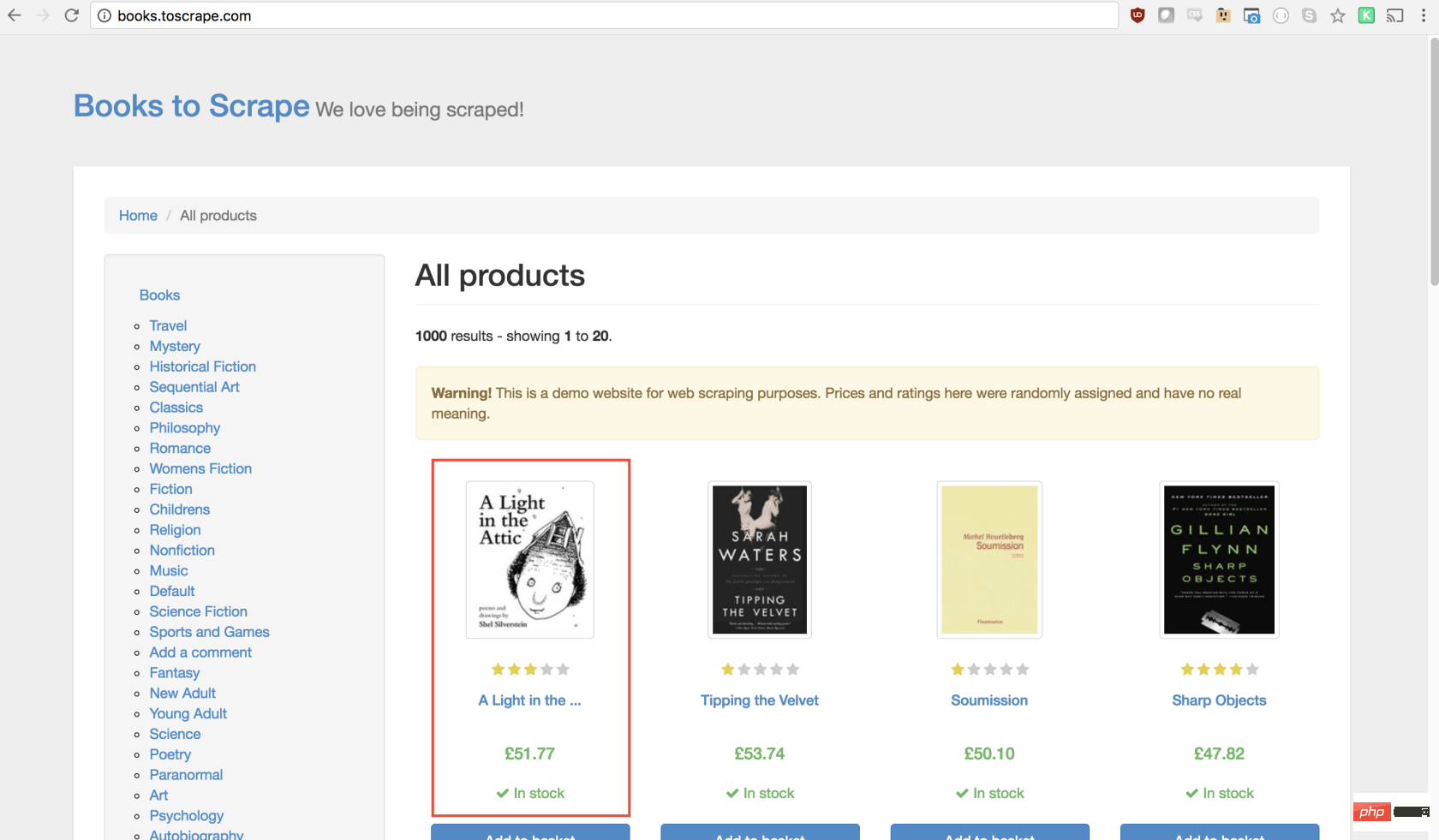
查看 Puppeteer API,我们可以找到单击页面的方法:
page.click(selector[, options])
-
selector用于选择要单击的元素的选择器,如果有多个满足选择器的元素,则将单击第一个。
幸运的是,使用 Google Chrome 开发者工具可以非常轻松地确定特定元素的选择器。只需右键单击图像并选择检查: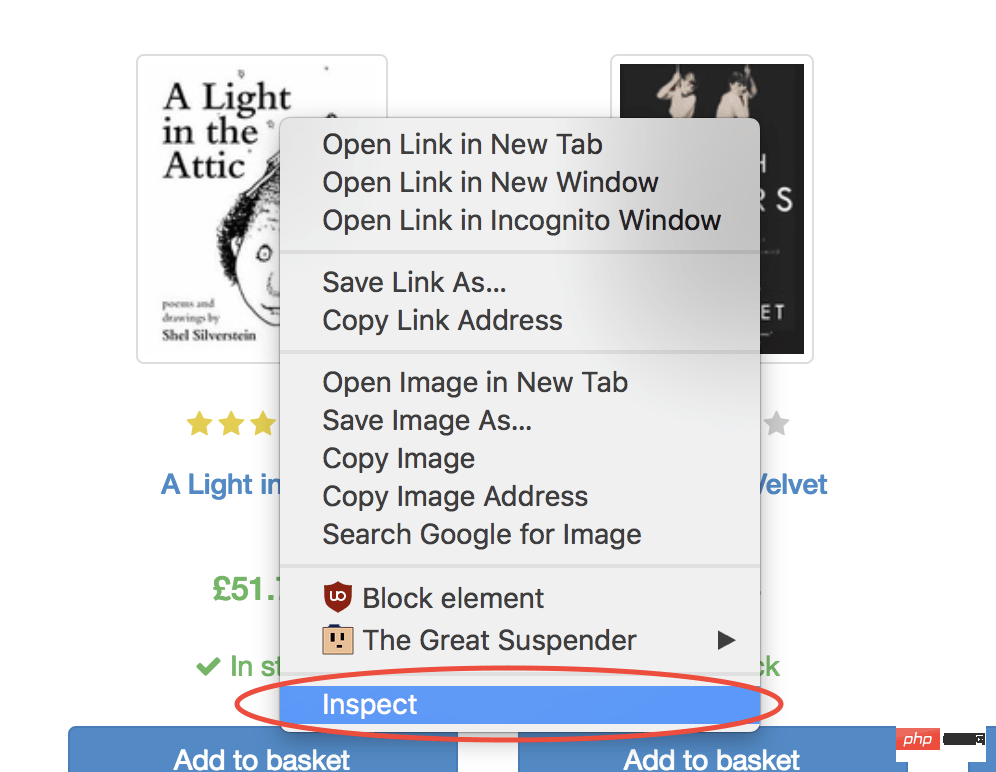
这将打开元素面板,突出显示该元素。现在,您可以单击左侧的三个点,选择复制,然后选择复制选择器:
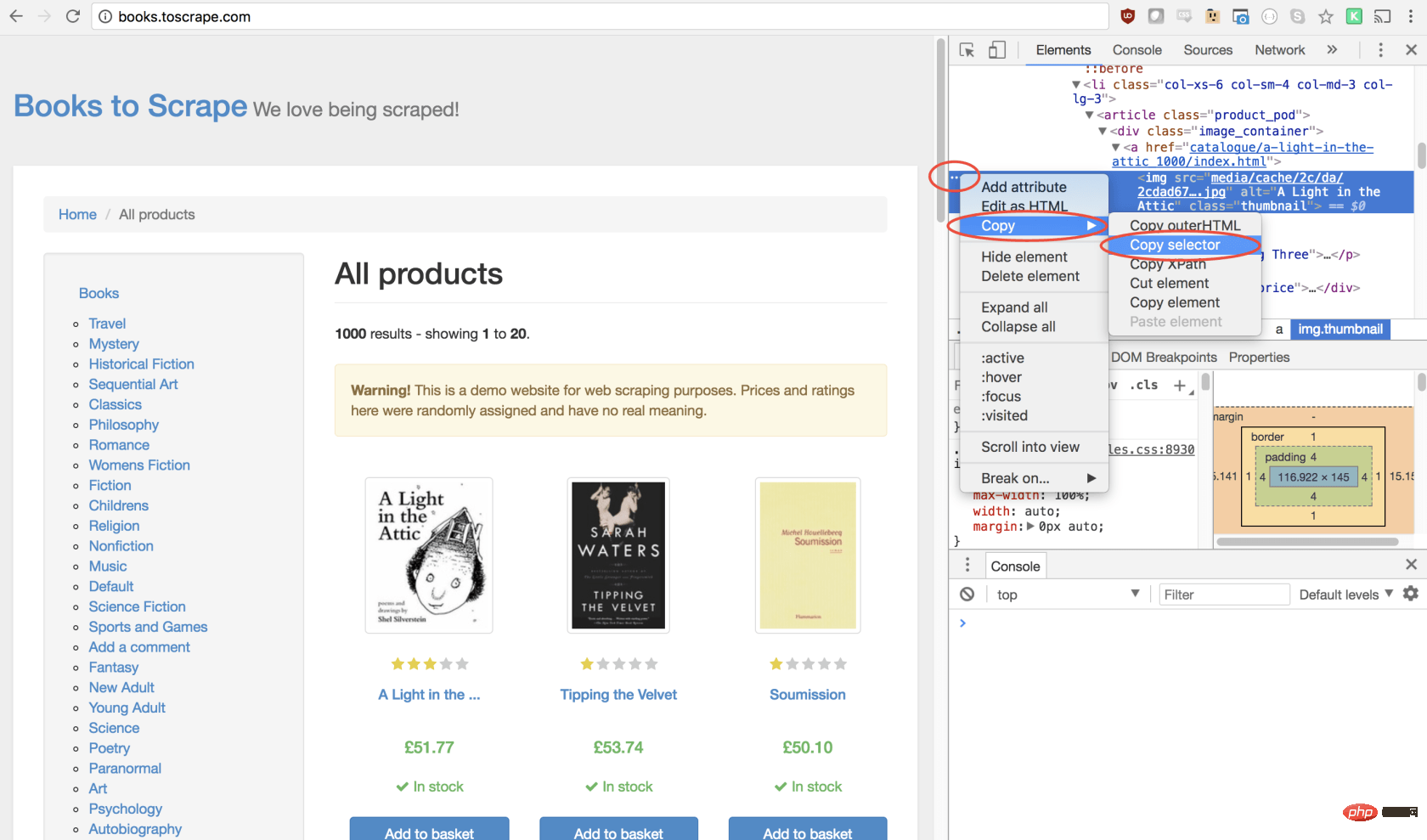
太棒了!现在,我们复制了选择器,并且可以将click方法插入程序。像这样:
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');
我们的窗口将单击第一个产品图像并导航到该产品页面!
在新页面上,我们对商品名称和商品价格均感兴趣(以下以红色概述)
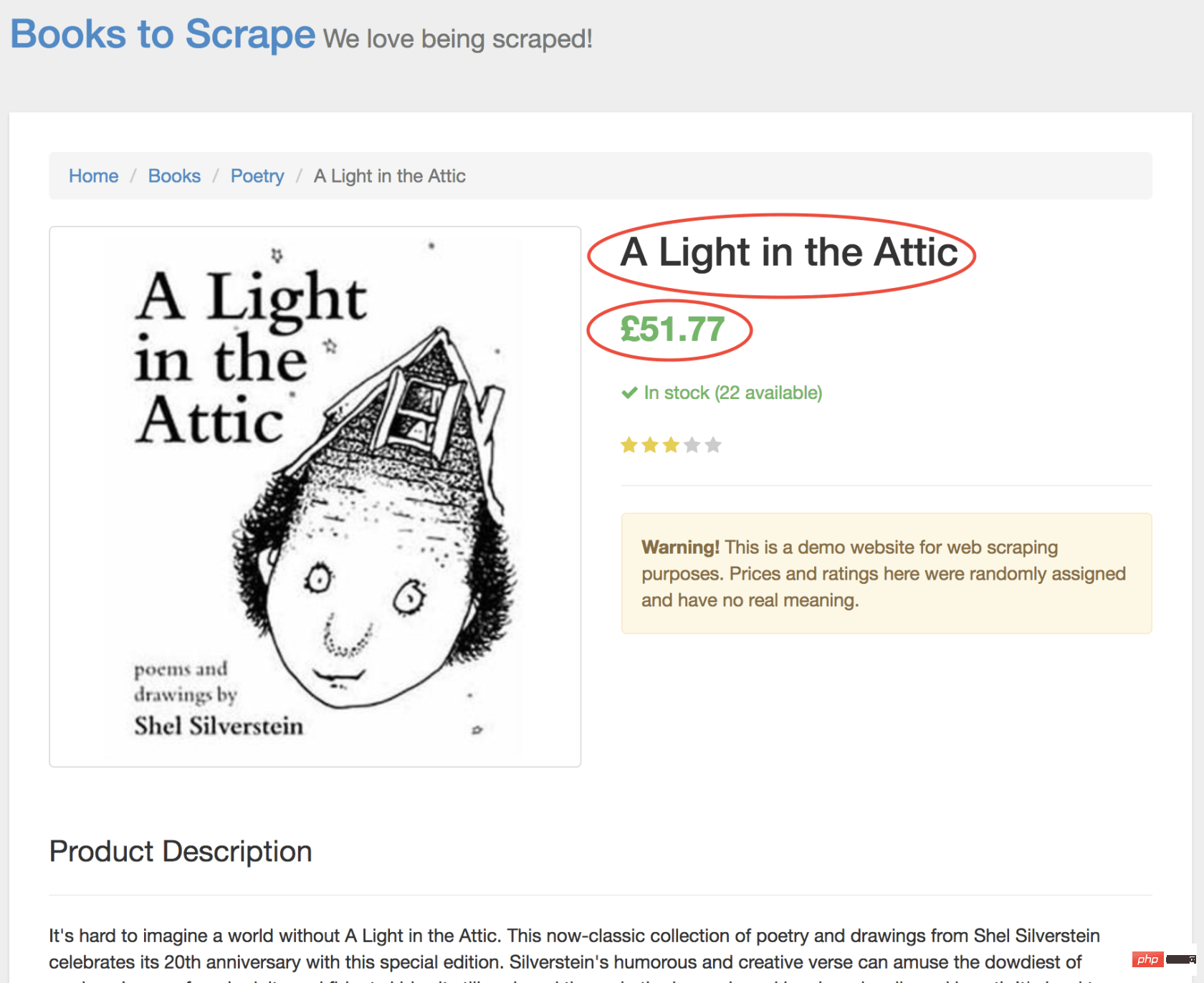
为了检索这些值,我们将使用page.evaluate()方法。此方法使我们可以使用内置的 DOM 选择器,例如querySelector()。
我们要做的第一件事是创建page.evaluate()函数,并将返回值保存到变量result中:
const result = await page.evaluate(() => {// return something});
在函数里,我们可以选择所需的元素。我们将使用 Google Developers 工具再次解决这一问题。右键单击标题,然后选择检查:
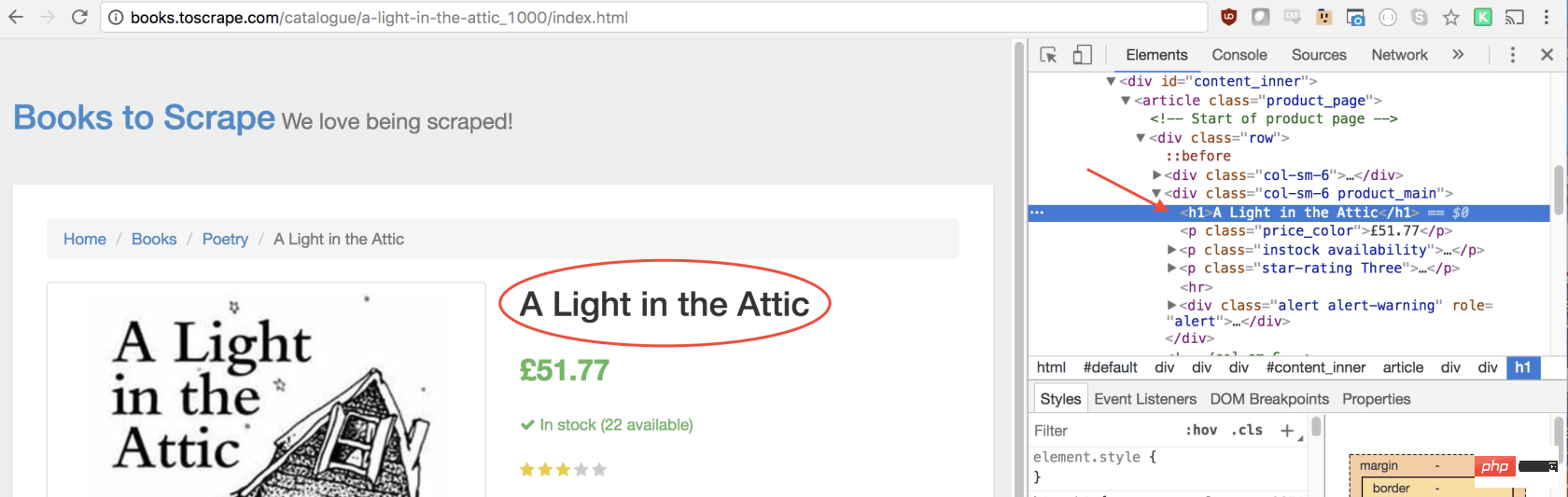
正如您将在 elements 面板中看到的那样,标题只是一个h1元素。我们可以使用以下代码选择此元素:
let title = document.querySelector('h1');
由于我们希望文本包含在此元素中,因此我们需要添加.innerText-最终代码如下所示:
let title = document.querySelector('h1').innerText;
同样,我们可以通过单击右键检查元素来选择价格:
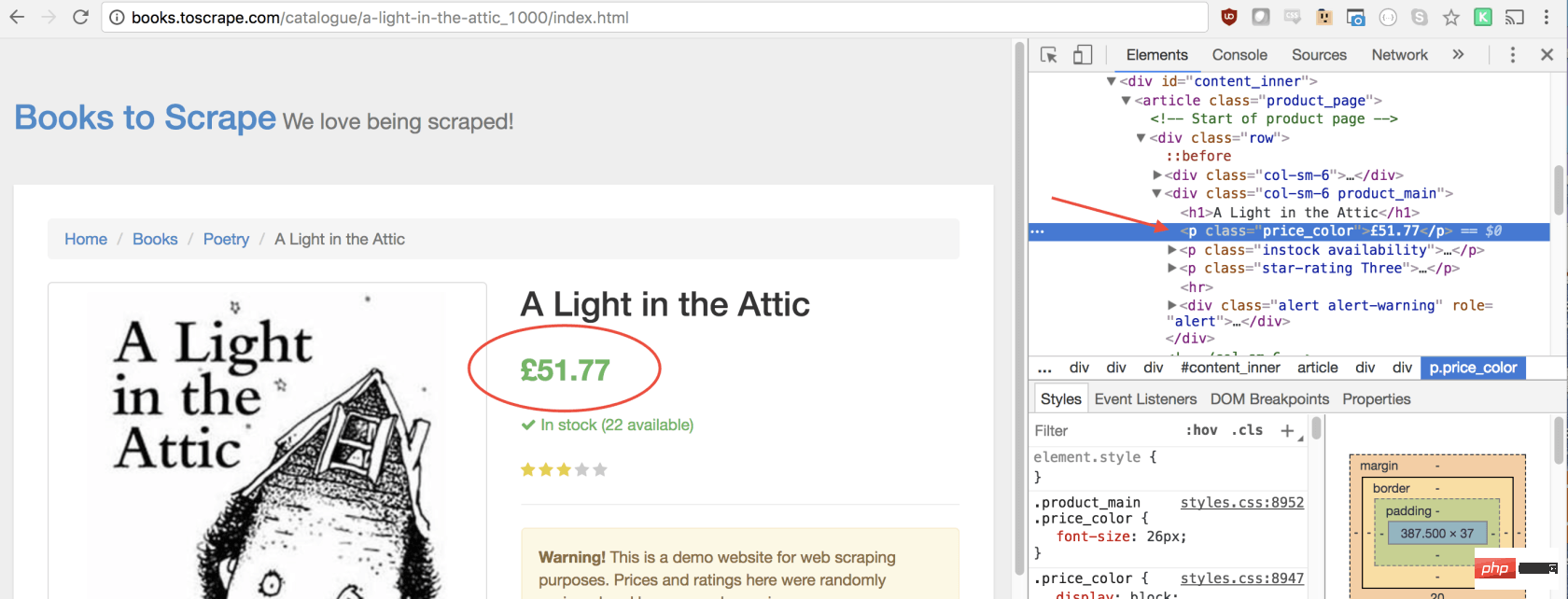
如您所见,我们的价格有price_color类,我们可以使用此类选择元素及其内部文本。这是代码:
let price = document.querySelector('.price_color').innerText;
现在我们有了所需的文本,可以将其返回到一个对象中:
return {
title,
price
}
太棒了!我们选择标题和价格,将其保存到一个对象中,然后将该对象的值返回给result变量。放在一起是这样的:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}});
剩下要做的唯一一件事就是返回result,以便可以将其记录到控制台:
return result;
您的最终代码应如下所示:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // 成功!
});
您可以通过在控制台中键入以下内容来运行 Node 文件:
node scrape.js // { 书名: 'A Light in the Attic', 价格: '£51.77' }
您应该看到所选图书的标题和价格返回到屏幕上!您刚刚抓取了网页!
示例 #3 ——完善它
现在您可能会问自己,当标题和价格都显示在主页上时,为什么我们要点击书?为什么不从那里抓取呢?而在我们尝试时,为什么不抓紧所有书籍的标题和价格呢?
因为有很多方法可以抓取网站! (此外,如果我们留在首页上,我们的标题将被删掉)。但是,这为您提供了练习新的抓取技能的绝好机会!
挑战
目标 ——从首页抓取所有书名和价格,并以数组形式返回。这是我最终的输出结果:

开始!看看您是否可以自己完成此任务。与我们刚创建的上述程序非常相似,如果卡住,请向下滚动…
GO! See if you can accomplish this on your own. It’s very similar to the above program we just created. Scroll down if you get stuck…
提示:
此挑战与上一个示例之间的主要区别是需要遍历大量结果。您可以按照以下方法设置代码来做到这一点:
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择全部
// 遍历每一个产品
// 选择标题
// 选择价格
data.push({title, price}); // 将数据放到数组里, 返回数据;
// 返回数据数组
});
如果您不明白,没事!这是一个棘手的问题…… 这是一种可能的解决方案。在以后的文章中,我将深入研究此代码及其工作方式,我们还将介绍更高级的抓取技术。如果您想收到通知,请务必 在此处输入您的电子邮件 。
方案:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组, 用来存储数据
let elements = document.querySelectorAll('.product_pod'); // 选择所有产品
for (var element of elements){ // 遍历每个产品
let title = element.childNodes[5].innerText; // 选择标题
let price = element.childNodes[7].children[0].innerText; // 选择价格
data.push({title, price}); // 将对象放进数组 data
}
return data; // 返回数组 data
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 成功!
});
结束语:
感谢您的阅读!
英文原文地址:https://codeburst.io/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js-b18efb9e9921
更多编程相关知识,请访问:编程入门!!
위 내용은 Node.js+Chrome+Puppeteer를 사용하여 웹사이트 크롤링의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!