
데이터 처리를 위해 팬더를 사용하는 DataFrame

- coldplay.xixi앞으로
- 2020-09-15 16:20:054430검색

관련 학습 권장 사항: python 튜토리얼
이 글은 pandas 데이터 처리 주제의 두 번째 글입니다. Pandas에서 가장 중요한 데이터 구조인 DataFrame에 대해 이야기해 보겠습니다.
이전 글에서 Series의 사용법을 소개했고 Series가 1차원 배열과 동일하지만 Pandas에는 편리하고 사용하기 쉬운 많은 API가 캡슐화되어 있다고 언급했습니다. DataFrame은 간단히 Series로 구성된 사전으로 이해하여 데이터를 2차원 테이블로 접합할 수 있습니다. 또한 테이블 수준 데이터 처리 및 일괄 데이터 처리를 위한 많은 인터페이스를 제공하므로 데이터 처리의 어려움이 크게 줄어듭니다.
Create DataFrame
DataFrame에는행 인덱스와 열 인덱스라는 두 개의 인덱스가 있어 해당 행과 열을 쉽게 얻을 수 있습니다. 이를 통해 데이터 처리를 위한 데이터를 찾는 어려움이 크게 줄어듭니다.
먼저 가장 간단한 것인 DataFrame을 만드는 방법부터 시작해 보겠습니다.사전에서 생성됨
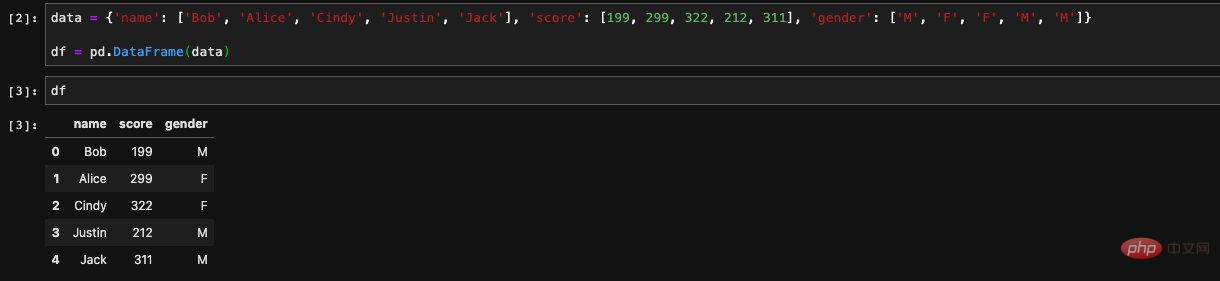
키를 열 이름으로, 값을 해당 값으로 사용 DataFrame을 생성합니다.
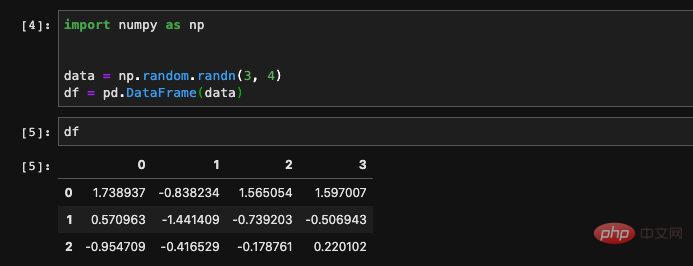
jupyter로 출력하면 자동으로 DataFrame의 내용이 테이블 형식으로 표시됩니다.numpy 데이터에서 생성
열 이름을 지정하지 않고 numpy 배열을 전달하면 pandas는 Numbers가 제공하는 numpy 2차원 배열에서 DataFrame을 생성할 수도 있습니다. :
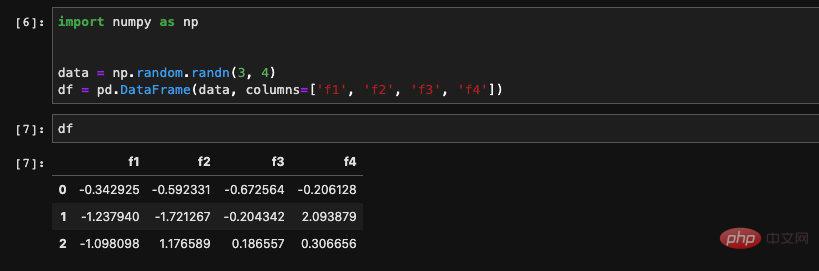
파일에서 읽기
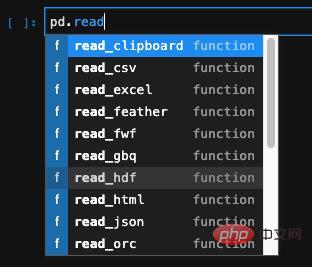
pandas의 또 다른 매우 강력한 기능은 다양한 형식의 파일에서 데이터를 읽어 DataFrame을 생성할 수 있다는 것입니다. 데이터베이스이기도 합니다.
excel, csv, json 등과 같은 구조화된 데이터의 경우 pandas는 해당 API를 찾아서 사용할 수 있는 특별한 API를 제공합니다.
특수 형식인 경우에는 그렇지 않습니다. 우리는 다양한 텍스트 파일에서 데이터를 읽고 구분 기호 와 같은 매개변수를 전달하여 생성을 완료할 수 있는 read_table을 사용합니다. 예를 들어 PCA의 차원 감소 효과를 검증한 이전 기사에서는 .data 형식 파일에서 데이터를 읽었습니다. 이 파일의 열 사이 구분 기호는 csv의 쉼표나 테이블 문자가 아닌 공백입니다. sep 매개변수를 전달하고 구분 기호를 지정하여 데이터 읽기를 완료합니다.
 이 헤더 매개변수는 파일의 어느 줄이 데이터의 열 이름으로 사용되는지 나타냅니다.
이 헤더 매개변수는 파일의 어느 줄이 데이터의 열 이름으로 사용되는지 나타냅니다. 은 첫 번째 줄이 열 이름으로 사용됨을 의미합니다. 데이터에 컬럼 이름이 없으면 header=None을 지정해야 하며, 그렇지 않으면 문제가 발생합니다. 다중 레벨 열 이름을 사용할 필요가 거의 없으므로 일반적으로 가장 일반적으로 사용되는 방법은 기본값을 사용하거나 None으로 설정하는 것입니다. DataFrame을 생성하는 모든
방법 중에서 가장 일반적으로 사용되는 방법은 파일에서 읽는 마지막 방법입니다. Kaggle에서는 머신러닝을 하거나 일부 대회에 참가할 때 데이터가 이미 만들어져 파일 형태로 제공되는 경우가 많기 때문에 직접 데이터를 생성해야 하는 경우가 거의 없습니다. 실제 작업 시나리오에서는 데이터가 파일에 저장되지 않더라도 일반적으로 일부 빅 데이터 플랫폼에 저장되는 소스가 있으며 모델은 이러한 플랫폼에서 훈련 데이터를 얻습니다. 그래서 우리는 일반적으로 DataFrame을 생성하는 다른 방법을 거의 사용하지 않습니다. 파일에서 읽는 방법을 익히는 데 어느 정도 이해하고 집중합니다.
공통 작업
다음은 팬더를 체계적으로 사용하는 방법을 배우기 전에 이미 알고 있던 팬더의 몇 가지 일반적인 작업을 소개합니다. 이해하는 이유도 아주 간단합니다. 너무나 흔히 쓰이는 내용이기 때문에 꼭 알고 이해해야 할 상식적인 내용이라고 할 수 있습니다.
데이터 보기
Jupyter에서 DataFrame 인스턴스를 실행하면 DataFrame의 모든 데이터가 인쇄됩니다. 데이터 행이 너무 많으면 중간 부분이 생략됩니다. 타원의 형태. 데이터의 양이 많은 DataFrame의 경우 일반적으로 이렇게 직접 출력하여 표시하지 않고, 처음 몇 개 또는 마지막 몇 개만 표시하도록 선택합니다. 여기에는 두 개의 API가 필요합니다.
처음 여러 데이터를 표시하는 방법을 head라고 합니다. 매개변수를 받아 처음부터 지정한 데이터 수만큼 표시하도록 지정할 수 있습니다.
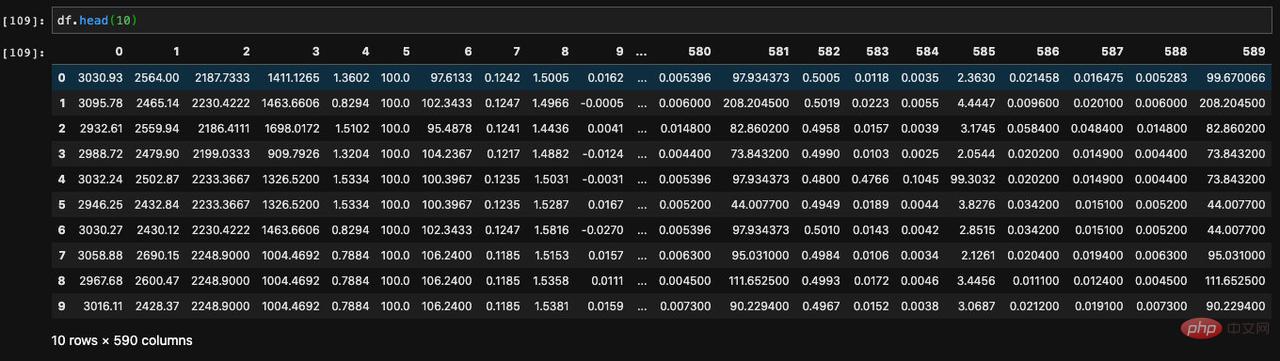
처음 몇 개의 항목을 표시하는 API가 있으므로 마지막 몇 개의 항목을 표시하는 API도 있습니다. 이러한 API를 tail이라고 합니다. 이를 통해 DataFrame에서 마지막으로 지정된 수의 데이터를 볼 수 있습니다.

열의 추가, 삭제 및 수정을 확인하세요.
DataFrame에 대해 앞서 언급했지만 실제로는 Series dict의 조합과 동일합니다. dict이기 때문에 키 값을 기준으로 자연스럽게 지정된 Series를 얻을 수 있습니다.
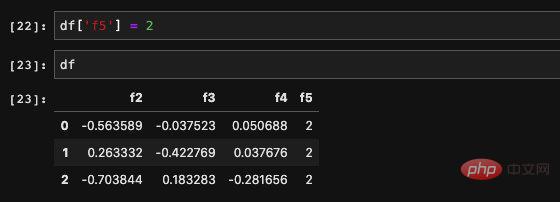
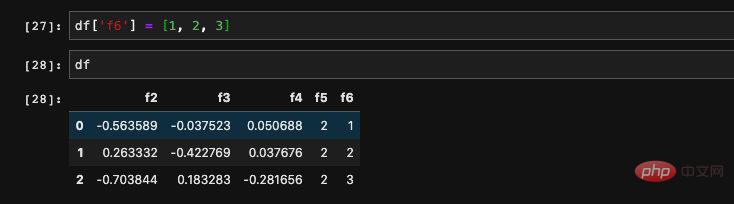
DataFrame에서 지정된 열을 가져오는 두 가지 방법이 있습니다. 열 이름을 추가하거나 dict 를 통해 요소를 찾아 쿼리할 수 있습니다.
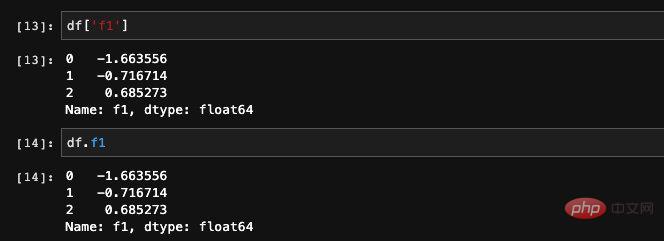
동시에 읽을 수도 있습니다. , 열이 여러 개인 경우 dict를 통해 요소를 쿼리하는 한 가지 방법만 지원됩니다. 들어오는 목록을 수신하고 목록의 열에 해당하는 데이터를 찾을 수 있습니다. 반환된 결과는 이러한 새 열로 구성된 새 DataFrame입니다. 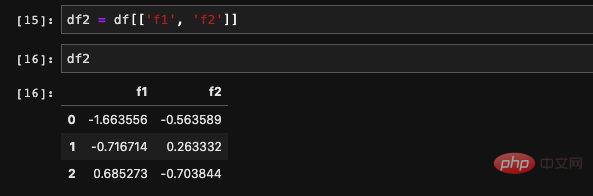
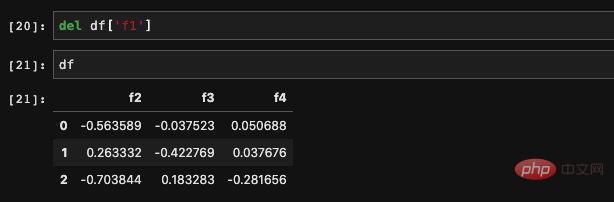
del을 사용하여 필요하지 않은 열을 삭제할 수 있습니다:
 배열도 가능합니다
배열도 가능합니다
numpy 배열로 변환사용하여 numpy 배열을 얻을 수 있습니다.
DataFrame에 해당:
 DataFrame의 각 열은 별도의 유형
DataFrame의 각 열은 별도의 유형
요약오늘 글에서는 DataFrame과 Series의 관계에 대해 배웠고, DataFrame의 기본 사용법과 일반적인 사용법도 배웠습니다. DataFrame은 대략적으로 Series로 구성된 사전으로 간주될 수 있지만 실제로는 별도의 데이터 구조로 자체 API도 많고 많은 고급 작업을 지원하며 데이터를 처리하는 강력한 도구입니다.
일부 전문 기관에서는 통계를 작성했는데, 알고리즘 엔지니어의 경우 약 70%의 시간이 데이터 처리에 투자됩니다. 실제로 모델을 작성하고 매개변수를 조정하는 데 소요되는 시간은 20% 미만일 수 있습니다. 이를 통해 데이터 처리의 필요성과 중요성을 알 수 있습니다. Python 분야에서 pandas는 데이터 처리를 위한 최고의 메스이자 도구 상자입니다.
프로그래밍에 대해 더 자세히 알고 싶다면 php training 칼럼을 주목해주세요!
위 내용은 데이터 처리를 위해 팬더를 사용하는 DataFrame의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!