
Pandas를 사용한 일련의 데이터 처리

- coldplay.xixi앞으로
- 2020-09-15 16:10:372446검색

관련 학습 권장사항: python 튜토리얼
오늘 우리는 Python에서 일반적으로 사용되는 새로운 계산 도구 라이브러리인 유명한 Pandas를 소개하기 시작합니다.
Pandas의 전체 이름은 Python 데이터 분석 라이브러리로, Numpy를 기반으로 한 과학 컴퓨팅 도구입니다. 가장 큰 특징은 구조화된 데이터를 데이터베이스의 연산 테이블처럼 연산할 수 있어 복잡하고 고급 연산을 많이 지원하며 Numpy의 향상된 버전이라고 볼 수 있습니다. csv 또는 Excel 테이블에서 완전한 데이터를 쉽게 구성할 수 있으며 다양한 테이블 수준 배치 데이터 계산 인터페이스를 지원합니다.
거의 모든 Python 패키지와 마찬가지로 pandas도 pip를 통해 설치할 수 있습니다. Anaconda 제품군을 설치한 경우 numpy 및 pandas와 같은 라이브러리가 자동으로 설치됩니다. 설치하지 않은 경우 한 줄의 명령으로 설치를 완료할 수 있습니다.
pip install pandas复制代码
Numpy와 마찬가지로 pandas를 사용할 때 일반적으로 별칭을 지정합니다. pd. 따라서 pandas 사용 규칙은 다음과 같습니다.
import pandas as pd复制代码
이 줄을 오류 없이 실행하면 pandas가 설치된 것입니다. 일반적으로 pandas와 함께 사용되는 두 가지 패키지가 있는데 그 중 하나는 Scipy라는 과학 컴퓨팅 패키지이고 다른 하나는 Matplotlib라는 데이터 시각화 도구 패키지입니다. pip를 사용하여 이 두 패키지를 함께 설치할 수도 있습니다. 다음 기사에서는 이 두 패키지를 사용할 때 사용법을 간략하게 소개하겠습니다.
pip install scipy matplotlib复制代码
Pandas에는 가장 일반적으로 사용되는 두 가지 데이터 구조가 있습니다. 하나는 Series이고 다른 하나는 DataFrame입니다. 그 중
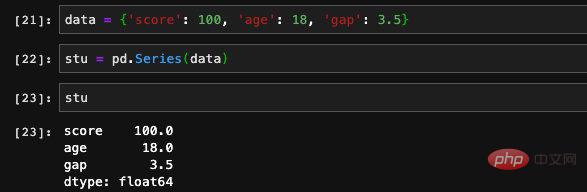
series는 1차원 데이터 구조로 간단히 1차원 배열 또는 1차원 벡터로 이해될 수 있습니다. DataFrame은 기본적으로 테이블이나 2차원 배열로 이해될 수 있는 2차원 데이터 구조입니다. 먼저 시리즈를 살펴보겠습니다. 시리즈에는 두 가지 주요 유형의 데이터가 저장되어 있습니다. 하나는 데이터 세트로 구성된 배열이고, 다른 하나는 이 데이터 세트의 인덱스 또는 레이블입니다. 우리는 단순히 시리즈를 만들고 인쇄하여 이해합니다.
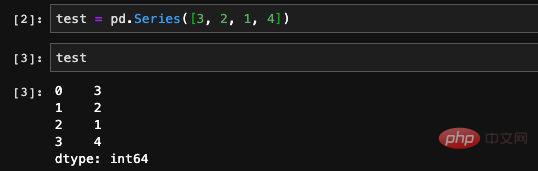 여기에서는 네 가지 요소가 포함된 시리즈를 무작위로 만든 다음 인쇄했습니다. 인쇄된 데이터에 두 개의 열이 있는 것을 볼 수 있습니다. 두 번째 열은 방금 생성했을 때 입력한 데이터입니다. 인덱스를 생성할 때 인덱스를 지정하지 않았기 때문에 pandas는 자동으로 행 번호 인덱스를 생성합니다. Series 유형의 값과 인덱스 속성을 통해 Series에 저장된 데이터와 인덱스를 볼 수 있습니다.
여기에서는 네 가지 요소가 포함된 시리즈를 무작위로 만든 다음 인쇄했습니다. 인쇄된 데이터에 두 개의 열이 있는 것을 볼 수 있습니다. 두 번째 열은 방금 생성했을 때 입력한 데이터입니다. 인덱스를 생성할 때 인덱스를 지정하지 않았기 때문에 pandas는 자동으로 행 번호 인덱스를 생성합니다. Series 유형의 값과 인덱스 속성을 통해 Series에 저장된 데이터와 인덱스를 볼 수 있습니다.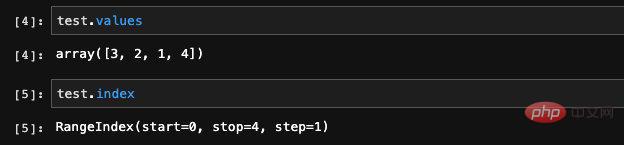
여기서 출력되는 값은 Numpy 배열입니다 이는 놀라운 일이 아닙니다. 앞서 말했듯이 pandas는 Numpy를 기반으로 개발된 과학 컴퓨팅 라이브러리이고 Numpy는 그 하위 계층이기 때문입니다. 인쇄된 인덱스 정보에서 이것이 Range 유형 인덱스, 범위 및 단계 크기임을 알 수 있습니다.
Index는 시리즈 구성 함수의 기본 매개변수입니다. 이를 채우지 않으면 기본적으로 data의 행 번호인 Range 인덱스가 생성됩니다. 데이터의 인덱스를 직접 지정할 수도 있습니다. 예를 들어 지금 코드에 index 매개변수를 추가하면 인덱스를 직접 지정할 수도 있습니다.

문자 유형의 인덱스를 지정하면 인덱스가 반환하는 결과는 더 이상 RangeIndex가 아니라 Index입니다. pandas는 내부적으로 숫자 인덱스와 문자 인덱스를 구별합니다.
색인을 사용하면 자연스럽게 요소를 찾는 데 사용됩니다. 인덱스를 배열의 첨자로 직접 사용할 수 있으며 둘의 효과는 동일합니다. 뿐만 아니라 인덱스 배열도 허용되며 여러 인덱스의 값을 직접 쿼리할 수 있습니다.
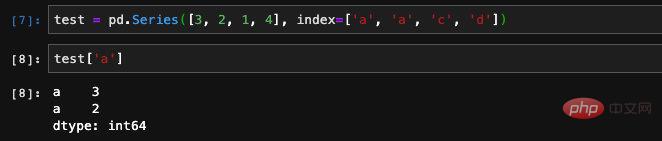
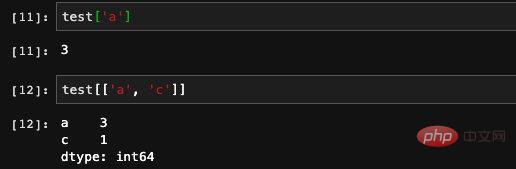 또한 시리즈 생성 시
또한 시리즈 생성 시 . 마찬가지로 인덱스 쿼리를 사용하면 여러 결과도 얻을 수 있습니다.
 그뿐만 아니라 Numpy와 같은 부울 인덱스도 계속 지원됩니다.
그뿐만 아니라 Numpy와 같은 부울 인덱스도 계속 지원됩니다. 
시리즈는 다양한 유형의 계산을 직접 지원합니다.
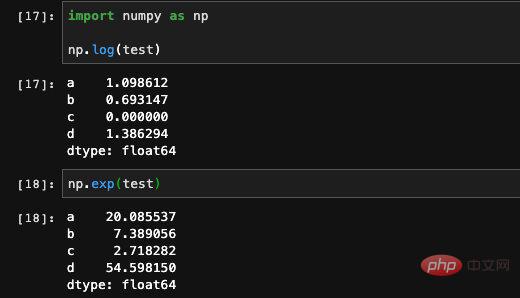
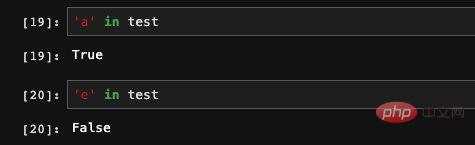
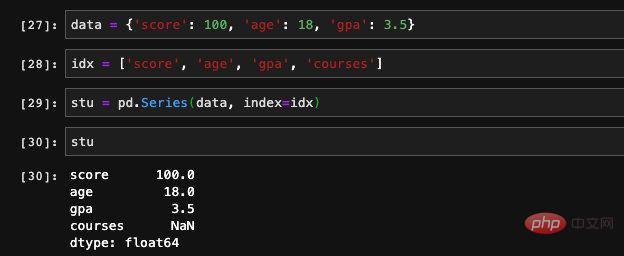
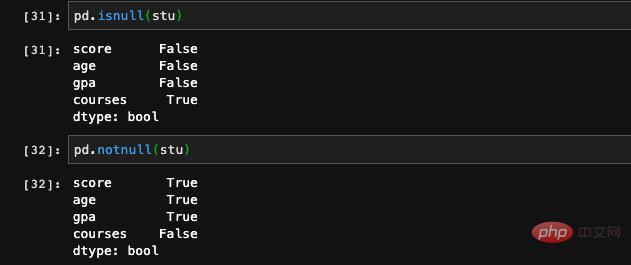
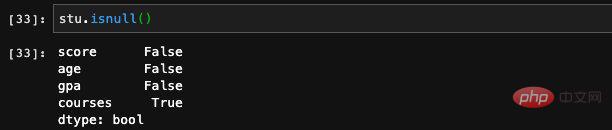
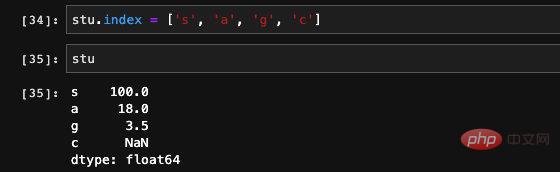
: 또한 Numpy의 연산 함수를 사용하여 일부 복잡한 수학 연산을 수행할 수 있지만 이 계산의 결과는 Numpy 배열이 됩니다. 시리즈에 인덱스가 있으므로 dict 메서드를 사용하여 인덱스가 시리즈에 있는지 여부를 확인할 수도 있습니다: 시리즈에는 실제로 인덱스와 값이 있습니다. of dict는 동일하므로 Seires는 dict를 통한 초기화도 지원합니다. 이런 방식으로 생성된 순서는 키가 dict에 저장되는 순서와 같으므로 생성 시 인덱스를 지정할 수 있습니다. 우리는 그 순서를 제어할 수 있습니다. 잘못된 값 또는 null 값으로 이해될 수 있습니다. 기능이나 학습 데이터를 처리할 때 일부 항목이 있는 데이터의 특정 기능이 비어 있는 상황이 종종 발생합니다. pandas에서는 isnull 및 notnull 함수를 사용할 수 있습니다. 공석이 있는지 확인하세요. 인덱스도 수정될 수 있습니다. 여기에 새 값을 직접 할당할 수 있습니다. 기본적으로 pandas의 Series는 Numpy 1차원 배열의 캡슐화 레이어와 인덱싱과 같은 일부 관련 기능입니다. 따라서 DataFrame은 실제로 더 많은 데이터 처리 관련 기능이 추가된 시리즈 배열의 캡슐화라고 상상할 수 있습니다. 핵심 구조를 파악한 후에는 이러한 API를 하나씩 외우는 것보다 팬더의 전체 기능을 이해하는 것이 훨씬 더 유용합니다. pandas는 Python 데이터 처리를 위한 훌륭한 도구입니다. 자격을 갖춘 알고리즘 엔지니어로서 우리가 기계 학습과 딥 러닝을 위해 Python을 사용하는 데 있어 거의 알아야 할 것입니다. 설문조사 데이터에 따르면, 알고리즘 엔지니어의 일상 업무 중 70%가 데이터 처리에 투자되고, 실제로 모델을 구현하고 훈련하는 데 사용되는 비율은 30% 미만입니다. 따라서 업계에서 발전하려면 데이터 처리의 중요성을 알 수 있습니다. 모델을 배우는 것만으로는 충분하지 않습니다. 이 글은 조판을 위해 mdnice를 사용합니다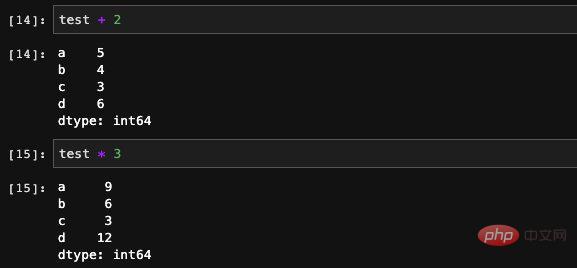
요약
php training
위 내용은 Pandas를 사용한 일련의 데이터 처리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!