
집 >데이터 베이스 >MySQL 튜토리얼 >SQL Server의 Partition By 및 row_number 함수 사용에 대한 자세한 설명
SQL Server의 Partition By 및 row_number 함수 사용에 대한 자세한 설명

- coldplay.xixi앞으로
- 2020-07-24 17:39:544491검색

키워드별 파티션은 분석 함수의 일부로, 그룹 내 여러 레코드를 반환할 수 있다는 점에서 집계 함수와 다릅니다. 반면 집계 함수에는 일반적으로 파티션별 통계 값을 반영하는 레코드가 하나만 있습니다. 결과 집합을 그룹화합니다. 지정하지 않으면 전체 결과 집합을 그룹으로 처리합니다.
오늘 그룹에서 질문을 봤는데 여기에 요약하겠습니다. 다양한 카테고리에서 최신 기록을 쿼리하세요. 얼핏 보기에는 매우 간단하지 않나요? 분류를 원할 경우 Group By를 사용하고, 최신 기록을 원할 경우 Order By를 사용하세요. 그런 다음 자신의 테이블에 만들어 보세요:
관련 학습 권장 사항: mysql 비디오 튜토리얼
우선 제출 시간에 따라 데이터를 역순으로 테이블에 배치합니다.
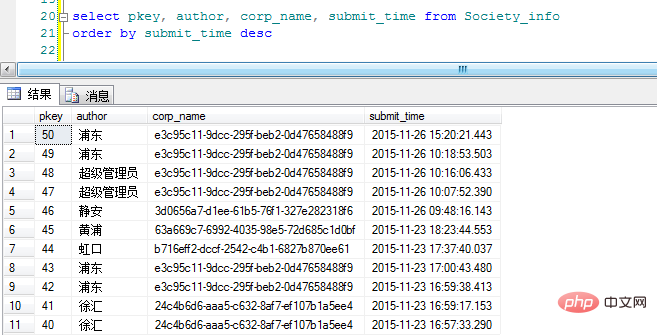
"corp_name"은 분류 GUID입니다(제 이름이 임의로 지정되었음을 양해해 주시기 바랍니다). 좋습니다. 표시 효과를 보기 위해 Group By를 추가하는 원래 아이디어는 다음과 같습니다.
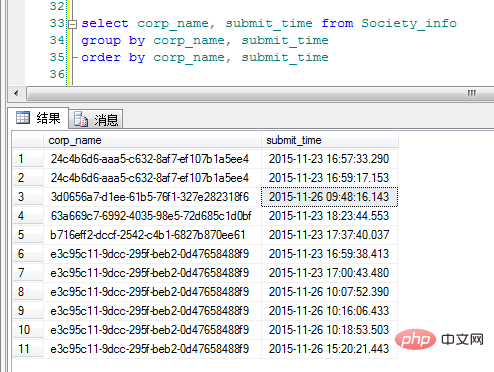
어, 음. 이 결과는 제가 상상했던 것과 다릅니다. 코드를 작성할 때 여전히 문제를 합리적으로 분석해야 하는 것 같습니다. 마음이 결과를 제어할 수는 없습니다.
요구사항이 데이터 카테고리가 다르기 때문에 Group By 외에 다른 기능을 사용할 수 있나요? 조사를 해보니 실제로 over(partition by) 기능이 있다는 것을 알았습니다. 그러면 일반적으로 사용되는 Group By 기능과의 차이점은 무엇입니까? Group By는 단순히 결과를 그룹화하는 것 외에도 일반적으로 집계 기능과 함께 사용됩니다. Partition By에는 그룹화 기능도 있으며 여기서는 자세히 설명하지 않겠습니다.
코드를 보세요:
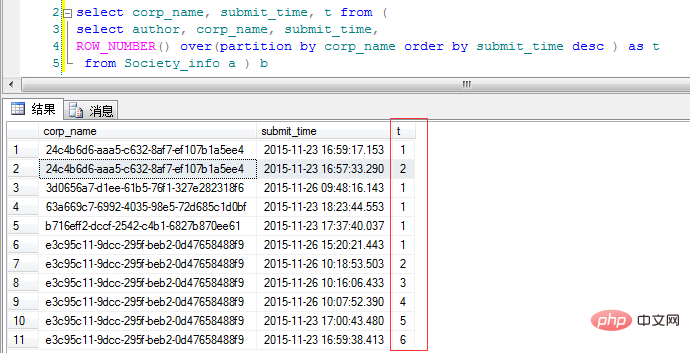
over(partition by corp_name order by submit_time desc ) as t . corp_name에 따라 분류되고 시간의 역순으로 정렬됩니다. "t" 여기의 열은 다양한 corp_name 클래스의 발생 횟수입니다. 요구 사항은 다양한 카테고리의 최신 제출 데이터만 쿼리하면 됩니다. "t"로 다시 필터링하세요.
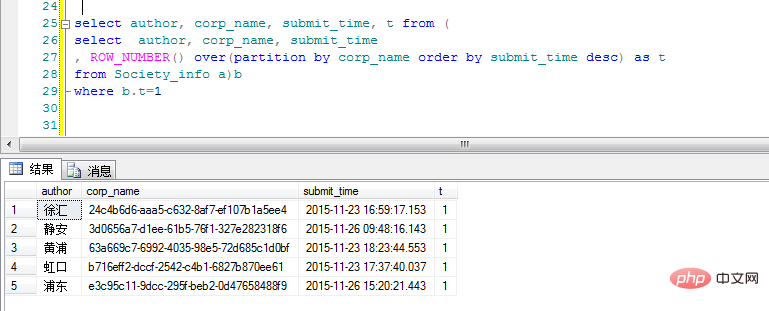
좋아요, 결과가 나왔습니다. 좋아요를 눌러달라는 게 아니라 제 아바타의 가슴을 좋아해 주시길 바랍니다. ! ! !
ps: SQL Server 데이터베이스 파티션별 및 ROW_NUMBER() 함수 사용에 대한 자세한 설명
필드별 SQL 파티션 사용 경험
먼저 예제를 살펴보세요.
if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
-- 모든 정보
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
-- 사용 PARTITION BY 함수 뒤에
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
는 결과에 추가 열 NUM이 있음을 확인할 수 있습니다. 이 NUM은 동일한 행의 수를 나타냅니다. 예를 들어 A1이 3개 있는 경우 해당 행의 수를 표시합니다. 각 A1.
-- ROW_NUMBER() OVER
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
의 결과만 사용하면 행 번호만 표시하는 것을 볼 수 있습니다.
-- 애플리케이션에 대해 더 자세히 살펴보겠습니다
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
다음으로 몇 가지 예제를 통해 ROW_NUMBER() 함수의 사용법을 소개하겠습니다.
예는 다음과 같습니다.
1.
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
와 같이 번호 매기기에는 row_number() 함수를 사용합니다. 원칙: 먼저 psd로 정렬하고, 정렬한 후 각 데이터에 번호를 매깁니다.
2. 주문을 가격 오름차순으로 정렬하고, 각 레코드를 다음 코드로 정렬합니다.
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. 각 가구의 모든 주문을 계산하고 각 고객의 주문을 오름차순으로 정렬합니다. 금액별로 주문하고 동시에 각 고객의 주문에 번호를 매깁니다. 이렇게 하면 각 고객이 주문한 수를 알 수 있습니다.
그림에 표시된 대로:

코드는 다음과 같습니다.
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4. 각 고객이 최근에 주문한 수를 계산합니다.

코드는 다음과 같습니다.
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5. 각 고객의 모든 주문 중 최소 구매 금액을 계산하고, 해당 주문 중 고객이 구매한 횟수도 계산합니다.
如图:

上图:rows表示客户是第几次购买。
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order ) select * from tabs where totalPrice in ( select MIN(totalPrice)from tabs group by customerID )
6.筛选出客户第一次下的订单。

思路。利用rows=1来查询客户第一次下的订单记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order ) select * from tabs where rows = 1 select * from OP_Order
7.rows_number()可用于分页
思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。
8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
如下代码:
select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
위 내용은 SQL Server의 Partition By 및 row_number 함수 사용에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!