
동일한 PHP 문자열이지만 길이가 다른 문제를 해결하세요.

- 藏色散人원래의
- 2020-07-18 09:06:242950검색
PHP 문자열의 길이가 다른 문제를 해결하는 방법: 먼저 "mb_Detect_encoding()" 함수를 통해 두 문자열의 인코딩 방법을 확인한 다음 특정 문자 길이를 확인하고 마지막으로 중국어가 아닌 문자를 제거합니다.

질문:
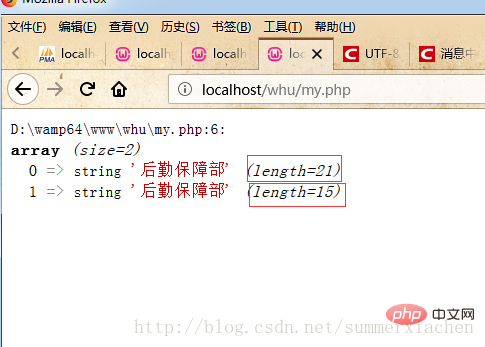
사진에서 보면 얼핏 보면 "물류지원부서"라는 똑같은 중국어 문자열이 2개 있는데 하나는 길이가 21이고 다른 하나는 15입니다.
우선 인코딩 방법이 다르기 때문에 발생한다고 직관적으로 생각하실 수도 있습니다.
두 문자열의 인코딩 방법을 mb_detect_encoding()함수를 통해 보면 다음과 같습니다
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));echo "str1='".$str1."'"." 编码:".$encode1."</br>";echo "str2='".$str2."'"." 编码:".$encode2."</br>";?>하지만 출력 결과는 모두 UTF-8입니다.
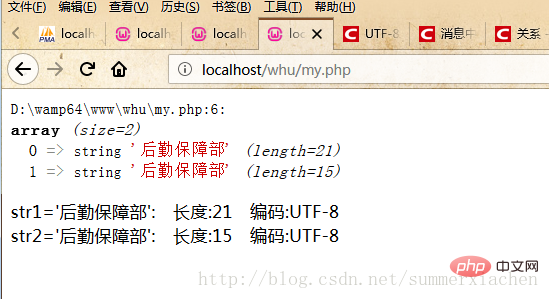
이유는 무엇입니까? 출력에서 구체적인 문자 길이를 살펴보겠습니다
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";?>출력 결과는 다음과 같습니다.
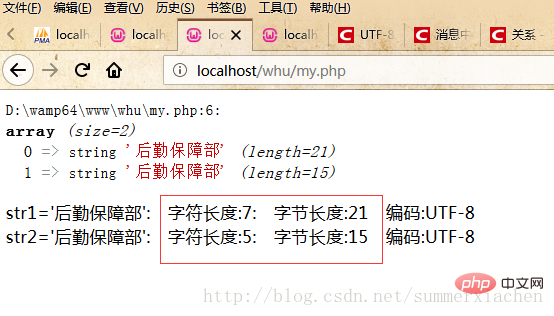
문자열 str1에 한자가 7개 포함되어 있는 것으로 확인되었지만 실제로는 "물류지원부서" 5개만 표시됩니다
차단하여 str1의 마지막 두 글자를 봅니다.
//截取str1后面两个未显示字符$res=mb_substr($str1, 5,2);echo "最后两字符:".$res."</br>";echo mb_strlen($res);
는 에코로 표시할 수 없지만 두 글자를 차지합니다.
똑같이 보이는 문자열이 다음과 같은 경우 실제로 동일해야 하기 때문에 처리해야 하는 것은 중국어가 아닌 문자를 제거하는 것입니다:
//剔除str1字串中未显示的字符(非中文字符)preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);마지막으로 코드는 다음과 같습니다
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";//截取str1后面两个未显示字符echo "</br>------------------截取str1后面两个未显示字符---------------------</br>";$res=mb_substr($str1, 5,2);echo "str1最后两字符: ".$res."</br>";echo "str1长度: ".mb_strlen($res)."</br>";//比较echo "</br>--------------------------相等比较----------------------------------</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";echo "str2 与 str2比较: ";echo strcomp($str2,$str2)."</br>";//剔除str1字串中非中文preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);echo "</br>---------------------剔除str1字串中非中文后----------------------</br>";echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";function strcomp($str1,$str2){
if($str1 == $str2){
return "相等";
}else{
return "不等";
}
}
?>실행 결과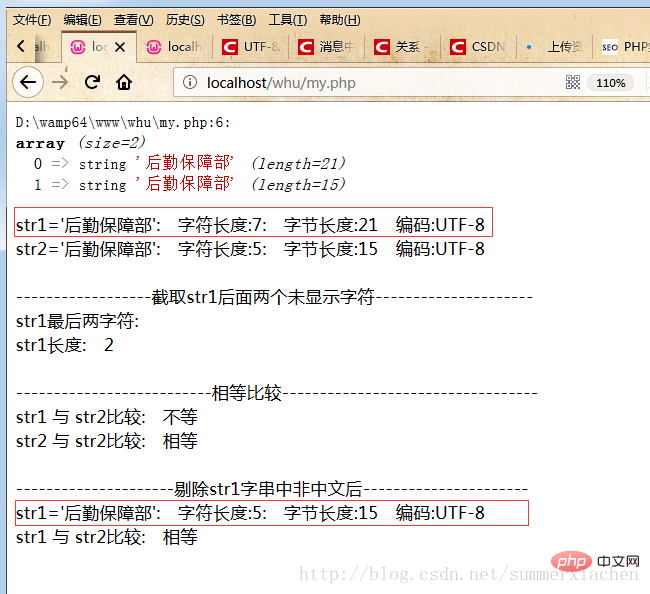
참고:
21- phpmyadmin의 SQL 입력 상자에 str1 바이트를 입력하면 다음과 같이 표시됩니다
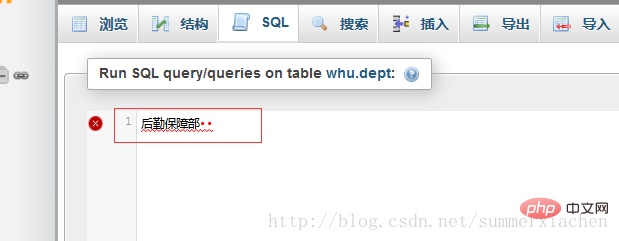
글쎄, 두 글자만 추가되었을 뿐입니다
더 보기 관련 지식은 PHP 중국어 웹사이트를 방문하세요!
위 내용은 동일한 PHP 문자열이지만 길이가 다른 문제를 해결하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!