
Scrapy는 Sina Weibo 크롤러를 구현합니다.

- little bottle앞으로
- 2019-04-28 16:08:504758검색
이 글에서는 주로 scrapy를 사용하여 Sina Weibo 크롤러를 구현하는 방법에 대해 설명하고 있으며 이에 대한 관심이 있습니다. . 친구들이 이에 대해 자세히 알아볼 수 있으며, 읽은 후 직접 시도해 볼 수도 있습니다!
최근 졸업 프로젝트로 인해 대량의 데이터를 수집해야 합니다. DIY를 원칙으로 시나웨이보에서 14~18년차 유명 연예인 100여명의 웨이보 콘텐츠를 모았습니다. 덩치 큰 놈들이 웨이보에 주로 올리는 글 좀 보세요~
1 우선 이 프로젝트는 스크래피를 사용하여 작성되므로 사용하는 사람은 알 것입니다.
수집되는 웹사이트는 웨이보의 웹페이지인 weibo.com 입니다. 조금 더 번거롭기는 하지만 콘텐츠는 모바일 세그먼트 및 wap 사이트에 비해 약간 더 포괄적입니다.
2. 수집에 앞서 웨이보가 우리에게 어떤 장애물을 설치했는지 살펴보겠습니다.
- Login
- Page js 렌더링
Weibo는 Go에 로그인하지 않은 사용자에 대해 기본적으로 302 점프를 사용하므로 따라서 Weibo 돈을 모으는 것은 Weibo가 이 수집이 너무 게으르다고 생각하게 만들 것입니다. 먼저 수동으로 로그인한 다음 쿠키를 스크래피에 저장하여 요청할 때 수집량이 많지 않기 때문에 액세스할 수 있는 쿠키를 가져오십시오. 큰데 아마 100,000개 정도밖에 안 될 거예요. 여기에서 scrapy를 처음 접하는 사람들에게 scrapy의 쿠키는 json과 유사한 형태라는 점을 상기시켜야 합니다. 이는 요청에 직접 붙여넣고 사용하는 것과는 다릅니다. 
아마 이렇기 때문에 로그인 후 쿠키를 붙여넣고 코드로 변환해야 합니다. 코드는 다음과 같습니다.
class transCookie:
def __init__(self, cookie):
self.cookie = cookie
def stringToDict(self):
itemDict = {}
items = self.cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict
if __name__ == "__main__":
cookie = "你的cookie"
trans = transCookie(cookie)
print(trans.stringToDict()) 쿠키 1개면 거의 충분하다고 생각합니다. 쿠키 3개를 저장하고 있습니다. 여러 쿠키를 사용하는 간단한 방법은 여러 쿠키를 배열에 직접 넣고 요청이 있을 때마다 무작위 기능을 사용하여 하나를 선택하는 것입니다. , 이는 쿠키를 일괄적으로 수집하기 위한 용도로만 사용되며, 데이터가 철회되는 경우 대규모 계정 풀을 유지해야 합니다. 요청할 때 ua와 쿠키를 가져오세요. 
Weibo는 oid를 기준으로 각 사용자를 구분합니다. Daniel Wu의 Weibo를 예로 들어 Weibo 검색 인터페이스에서 Daniel Wu를 검색하고 홈페이지를 마우스 오른쪽 버튼으로 클릭하면 됩니다. 웹페이지 소스 코드는 다음과 같습니다. 
여기서 oid는 각 사용자의 고유 식별자입니다. 해당 사용자의 홈페이지 주소는 https://weibo.com + oid,
주소를 사용하여 Weibo 인터페이스에 직접 입력하여 수집하고 URL 주소를 조합할 수 있습니다. 예:
https :/ /weibo.com/wuyanzu?is_all=1&stat_date=201712#feedtop
2017년 12월 Wu Yanzu의 웨이보입니다. stat_date 뒤의 숫자만 바꿔도 해당 웨이보 주소임을 알아내는 것은 어렵지 않습니다. 웨이보의 양이 많은 일부 사용자의 경우 월간 웨이보에 JS를 다시 로드해야 할 수도 있습니다. 물론 우리의 멋진 남성 신인 우옌즈 씨는 확실히 다른 웨이보를 찾아 비교하지 않을 것입니다. 예: 
, 나머지 Weibo는 js 비동기 로딩을 통해 사용자에게 표시되어야 함을 알 수 있습니다. 브라우저 개발자 모드를 열고, 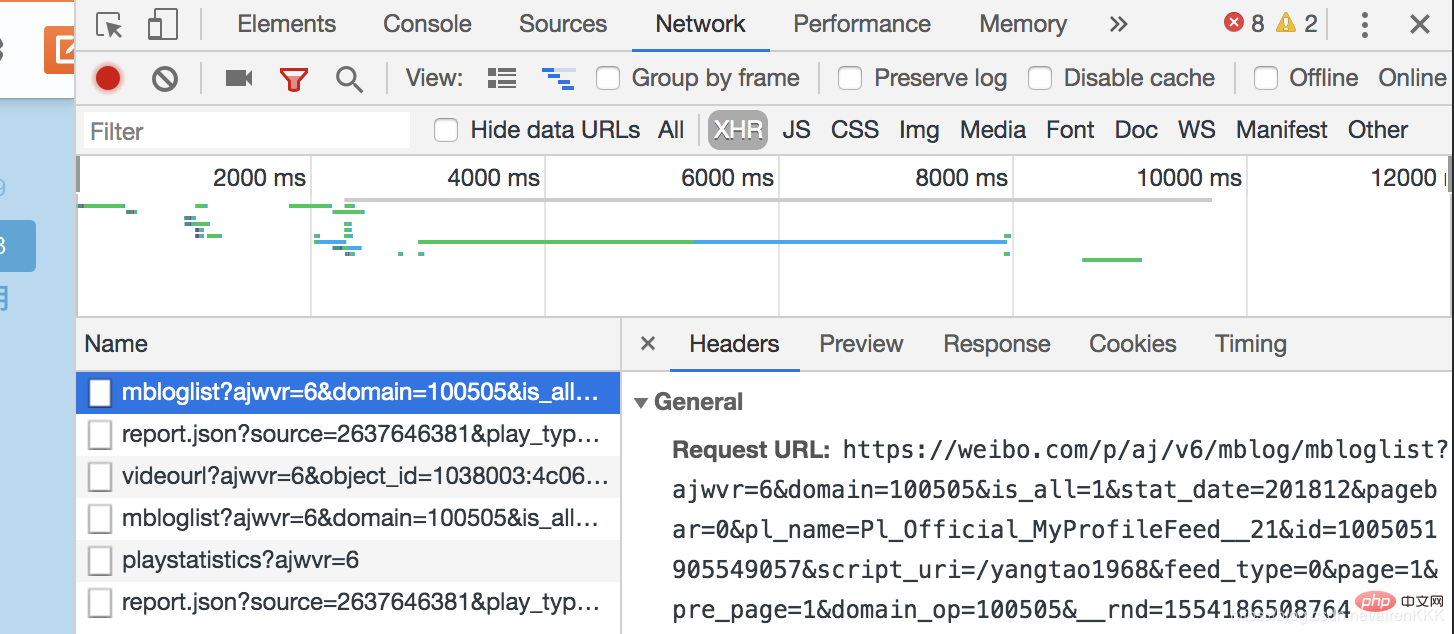
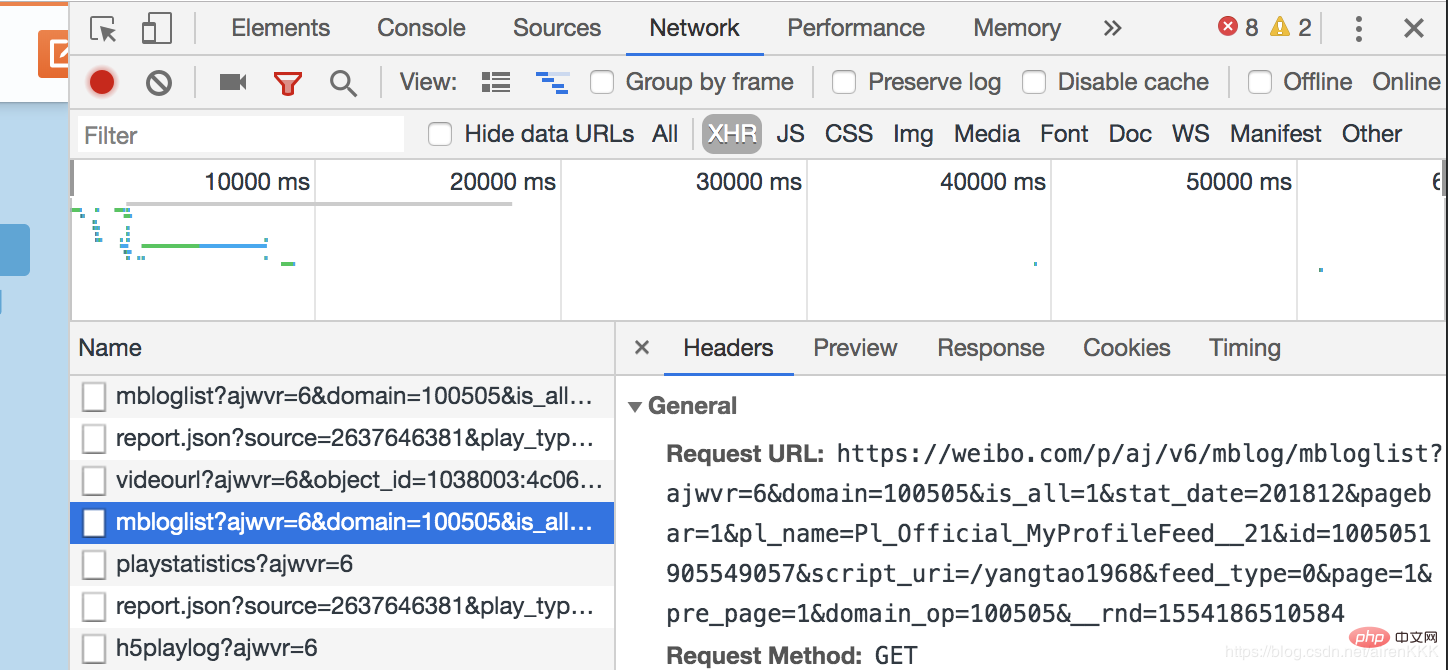
js로 로드된 페이지를 두 번 비교해 보면 Request_URL의 차이점을 찾는 것은 어렵지 않습니다. 단지 두 매개변수인 pagebar와 _rnd에 대해 첫 번째는 페이지 수를 나타내고 두 번째는 시간의 암호화이므로(테스트에 사용하지 않아도 상관없습니다) 숫자만 구성하면 됩니다. 페이지 수. 규모가 큰 일부 웨이보 게시물은 여전히 뒤집어야 할 수도 있습니다. 이유는 같습니다.
class SpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nickname = scrapy.Field()
follow = scrapy.Field()
fan = scrapy.Field()
weibo_count = scrapy.Field()
authentication = scrapy.Field()
address = scrapy.Field()
graduated = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
oid = scrapy.Field()设置需要爬取的字段nickname昵称,follow关注,fan粉丝,weibo_count微博数量,authentication认证信息,address地址,graduated毕业院校,有些微博不显示的默认设置为空,以及oid和博文内容及发布时间。
这里说一下内容的解析,还是吴彦祖微博,如果我们还是像之前一样直接用scrapy的解析规则去用xpath或者css选择器解析会发现明明结构找的正确却匹配不出数据,这就是微博坑的地方,点开源代码。我们发现:
微博的主题内容全是用script包裹起来的!!!这个问题当初也是困扰了博主很久,反复换着法子用css和xpath解析始终不出数据。
解决办法:正则匹配(无奈但有效)
至此,就可以愉快的进行采集了,附上运行截图:
输入导入mongodb:
相关教程:Python视频教程
위 내용은 Scrapy는 Sina Weibo 크롤러를 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!