
크롤러 기술을 구현하기 위해 Jsoup을 사용하는 방법 소개

- 不言앞으로
- 2019-03-08 15:37:543501검색
이 글은 크롤러 기술을 구현하기 위해 Jsoup을 사용하는 방법을 소개합니다. 도움이 필요한 친구들이 참고할 수 있기를 바랍니다.
1. Jsoup에 대한 간략한 소개
WebMagic, Spider, Jsoup 등 Java에서 지원되는 다양한 크롤러 프레임워크가 있습니다. 오늘 우리는 Jsoup를 사용하여 간단한 크롤러 프로그램을 구현합니다.
Jsoup에는 DOM 객체의 문서 순회 방법 참조, CSS 선택기 사용법 참조 등 HTML 문서를 처리하는 데 매우 편리한 API가 있으므로 Jsoup을 사용하여 페이지 데이터 크롤링 기술을 빠르게 익힐 수 있습니다.
2.빠른 시작
1) HTML 페이지 작성

페이지의 표에 있는 제품 정보는 크롤링하려는 데이터입니다. 그 중 속성은 pname 클래스의 제품 이름과 pig 클래스에 속하는 제품 사진입니다.
2) HttpClient를 사용하여 HTML 페이지 읽기
HttpClient는 Http 프로토콜 데이터를 처리하는 도구로 HTML 페이지를 입력 스트림으로 Java 프로그램으로 읽는 데 사용할 수 있습니다. http://hc.apache.org/에서 HttpClient jar 패키지를 다운로드할 수 있습니다.

3) Jsoup을 사용하여 html 문자열 구문 분석
Jsoup 도구를 도입하면 직접 구문 분석 메서드를 호출하여 html 페이지의 내용을 설명하는 문자열을 구문 분석하여 Document 객체를 얻을 수 있습니다. Document 객체는 DOM 트리를 작동하여 html 페이지에 지정된 내용을 얻습니다. 관련 API에 대해서는 Jsoup 공식 문서를 참조하세요: https://jsoup.org/cookbook/
아래에서는 Jsoup을 사용하여 위 HTML에 지정된 제품 이름과 가격 정보를 얻습니다.
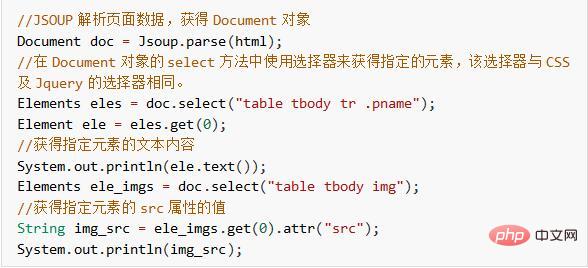
지금까지 HttpClient+Jsoup을 사용하여 HTML 페이지 데이터를 크롤링하는 기능을 구현했습니다. 다음으로 크롤링된 데이터를 데이터베이스에 저장하고 이미지를 서버에 저장하는 등 효과를 보다 직관적으로 만듭니다.
3. 크롤링된 페이지 데이터 저장
1) 일반 데이터를 데이터베이스에 저장
크롤링된 데이터를 엔터티 빈으로 캡슐화하여 데이터베이스에 저장합니다.
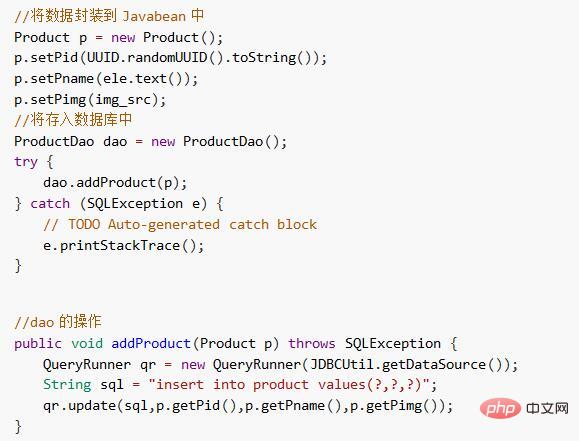
2) 사진을 서버에 저장
사진을 직접 다운로드하여 로컬로 서버에 저장하세요.

4. 요약
이 사례는 단순히 HttpClient+Jsoup을 사용하여 네트워크 데이터를 크롤링하는 방법을 구현한 것입니다. 크롤러 기술 자체에 관해서는 아직 살펴볼 만한 부분이 많이 있는데 이에 대해서는 나중에 설명하겠습니다.
위 내용은 크롤러 기술을 구현하기 위해 Jsoup을 사용하는 방법 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!