
Python의 DataFrame은 Excel 병합된ell_python을 구현합니다.

- 不言원래의
- 2018-04-02 16:19:2110017검색
이 글에서는 Excel 병합 셀을 구현하기 위해 Python에서 DataFrame을 주로 소개합니다. 여기에는 특정 참조 값이 있습니다. 관심 있는 친구들이 참고할 수 있습니다.
저는 직장에서 엑셀을 수행하기 위해 데이터를 출력해야 하는 경우가 종종 있는데, 일부 셀에는 예를 들어 아래 표에서 A 열의 값을 기준으로 B 열과 C 열의 해당 셀을 병합해야 합니다. pandas의 to_excel 메서드는 인덱스만 병합할 수 있지만 xlsxwriter에서는 merge_range 메서드를 사용할 수 있습니다. 제공되지만 최종적으로 조정하려면 매번 지루한 테스트를 작성해야 하고 재사용도 잘 되지 않습니다. 그래서 데이터프레임과 merge_range를 결합하여 직접 메서드를 작성하고 싶습니다. 일반적인 아이디어는 다음과 같습니다.
 1. MY_DataFrame 클래스를 정의하고 DataFrame 클래스를 상속하면 데이터 구조를 직접 재구성하지 않고도 팬더의 많은 기능을 효과적으로 활용할 수 있습니다.
1. MY_DataFrame 클래스를 정의하고 DataFrame 클래스를 상속하면 데이터 구조를 직접 재구성하지 않고도 팬더의 많은 기능을 효과적으로 활용할 수 있습니다.
병합 알고리즘은 다음과 같습니다.
1. 주어진 매개변수의 [키 열]에 따라 그룹 계산 및 정렬을 수행하고 CN과 RN 두 개의 보조 열을 추가합니다
2. 그렇지 않으면 그룹(행)을 병합할 필요가 없습니다. (CN=1은 그룹 데이터 행이 고유하고 병합할 필요가 없음을 의미합니다.)
4. 병합해야 할 열에서 RN=1이면 merge_range를 호출하고 CN 셀을 한 번에 씁니다. RN>1이면 셀을 건너뜁니다. RN=1이면 셀이 병합되어 쓰여졌기 때문입니다. erge_range를 반복적으로 호출하면 Excel 문서를 열 때 오류가 보고됩니다.
사진과 함께 설명은 다음과 같습니다.
# -*- coding: utf-8 -*-
"""
Created on 20170301
@author: ARK-Z
"""
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self,path,key_cols=[],merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy=My_DataFrame(self,copy=True)
line_cn=self_copy.index.size
cols=list(self_copy.columns.values)
if all([v in cols for i,v in enumerate(key_cols)])==False: #校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i,v in enumerate(merge_cols)])==False: #校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({'border':1,'bold':True,'text_wrap':True})
format_other = wb2007.add_format({'border':1,'valign':'vcenter'})
for i,value in enumerate(cols): #写表头
#print(value)
worksheet2007.write(0,i,value,format_top)
#merge_cols=['B','A','C']
#key_cols=['A','B']
if key_cols ==[]: #如果key_cols 参数不传值,则无需合并
self_copy['RN']=1
self_copy['CN']=1
else:
self_copy['RN']=self_copy.groupby(key_cols,as_index=False).rank(method='first').ix[:,0] #以key_cols作为是否合并的依据
self_copy['CN']=self_copy.groupby(key_cols,as_index=False).rank(method='max').ix[:,0]
#print(self)
for i in range(line_cn):
if self_copy.ix[i,'CN']>1:
#print('该行有需要合并的单元格')
for j,col in enumerate(cols):
#print(self_copy.ix[i,col])
if col in (merge_cols): #哪些列需要合并
if self_copy.ix[i,'RN']==1: #合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i+1,j,i+int(self_copy.ix[i,'CN']),j, self_copy.ix[i,col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
#worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
#worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
#print(',')
else:
#print('该行无需要合并的单元格')
for j,col in enumerate(cols):
#print(df.ix[i,col])
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)
통화 코드:
import My_Module
DF=My_DataFrame({'A':[1,2,2,2,3,3],'B':[1,1,1,1,1,1],'C':[1,1,1,1,1,1],'D':[1,1,1,1,1,1]})
DF
Out[120]:
A B C D
0 1 1 1 1
1 2 1 1 1
2 2 1 1 1
3 2 1 1 1
4 3 1 1 1
5 3 1 1 1
DF.my_mergewr_excel('000_2.xlsx',['A'],['B','C'])
효과는 다음과 같습니다.
A와 B 열을 병합하도록 설정할 수도 있습니다.
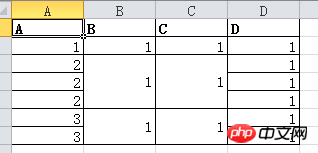
DF.my_mergewr_excel('000_2.xlsx',['A'],['A','B'])
효과는 다음과 같습니다.
위 내용은 Python의 DataFrame은 Excel 병합된ell_python을 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!