
JS 정규식의 원리와 구문 분석
- php中世界最好的语言원래의
- 2018-03-29 16:17:431824검색
이번에는 JS 정규식 파싱의 원리와 구문에 대해 알려드리고, JS 정규식 파싱의 원리와 구문을 파싱할 때 주의 사항은 무엇인지 살펴보겠습니다.
Zhengze는 끈의 바다에서 헤매는 것과 같습니다. Zhengze는 제출된 지폐의 진위 여부를 알 수 없는 지폐 탐지기와 같습니다. 사용자, 가짜일 때는 항상 식별하는 데 도움이 될 수 있고, 정상일 때는 손전등과 같으며, 무언가를 찾아야 할 때 항상 원하는 것을 얻는 데 도움이 될 수 있습니다...
——Stinson's에서 발췌 중국어 병행문장 연습 "Regular"
문학 발췌문을 감상한 후 JS에서 정규식을 정식으로 정리하겠습니다. 이 글의 주된 목적은 정규식의 사용법을 잊어버리지 않도록 하는 것이므로 정리하여 작성했습니다. 참고로, 실수가 있으면 알려주시면 감사하겠습니다.
이 글의 제목이 "원스톱"이므로 "용"에 걸맞은 내용이어야 하므로 규칙성 원칙, 구문 개요, JS(ES5)의 규칙성, ES6 규칙성의 확장 및 규칙성을 실천하기 위한 아이디어를 포함합니다. . 가능한 한 깊이 들어가도록 최선을 다하겠습니다. 이 내용을 간단한 방법으로 설명하십시오(심오한 내용을 실제로 간단한 방법으로 설명할 수 있는 것처럼). , 그런 다음 기본적으로 귀하의 요구에 맞는 두 번째, 세 번째 및 다섯 번째 부분을 읽으십시오. JS를 마스터하고 싶다면 정규이므로 미안하다고 생각하고 내 아이디어를 따르는 것이 좋습니다.
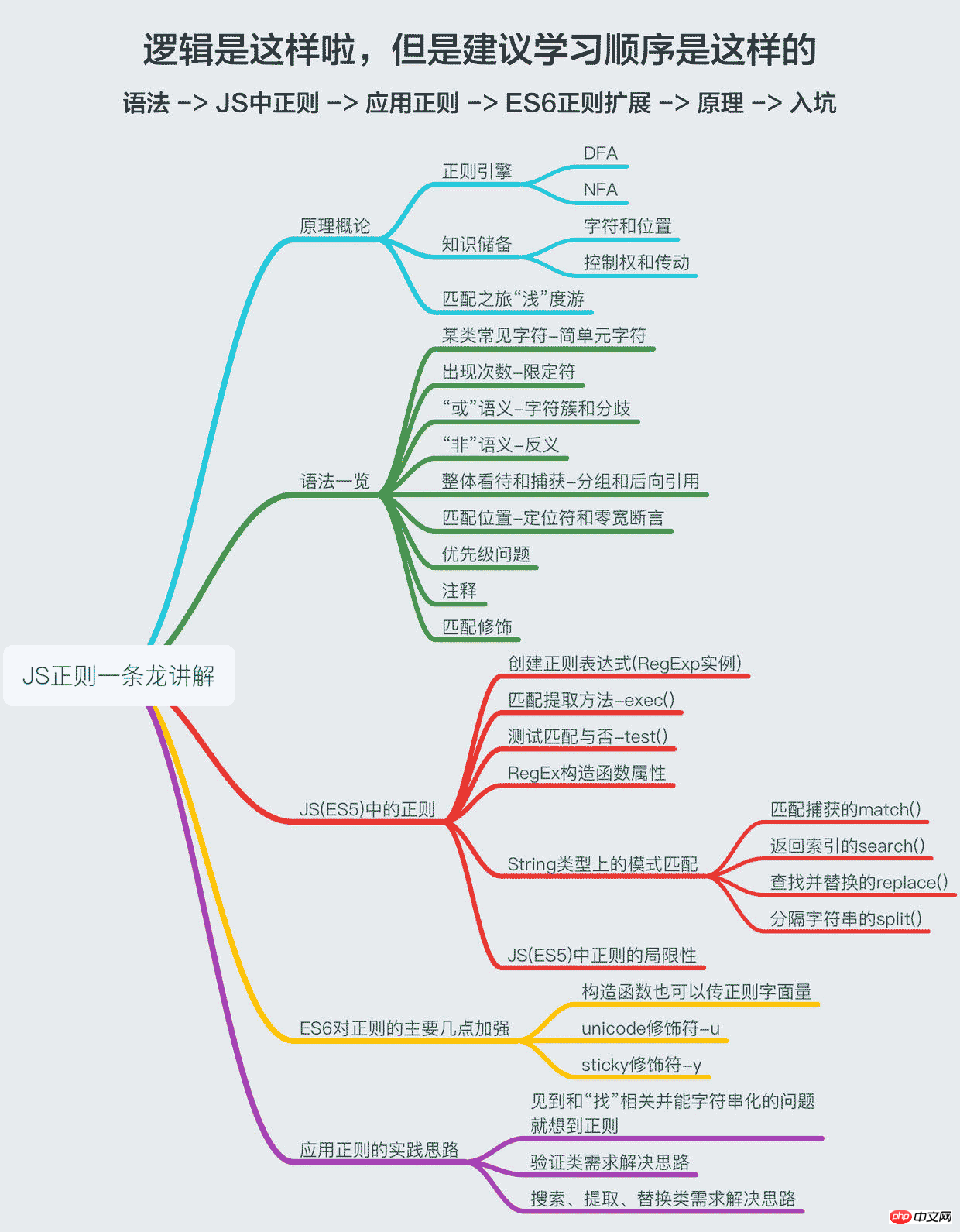
1. 원리 개요
처음 정규 표현식을 사용하기 시작했을 때 컴퓨터가 도대체 어떻게 정규 표현식을 기반으로 문자열을 일치시키는지 정말 대단하다고 생각했습니다. 나중에서야 "계산 이론"이라는 책을 접하고 규칙성, DFA, NFA 간의 개념과 연관성을 보고 깨달음을 얻었습니다.
하지만 정규식을 원리적으로 이해하고 싶다면 가장 좋은 방법은 다음과 같습니다.
1. 먼저 O'REILLY의 "Animal Story" 시리즈와 같이 정규식에 관한 책을 찾아보세요.
2. 일반 엔진을 직접 구현해 보세요.
이 글의 초점은 JS의 정규 표현식 적용에 맞춰져 있으므로 원리는 간략하게만 소개합니다(저는 일반 엔진을 작성한 적이 없고 깊이 들어가지도 않을 것이기 때문에). 호기심 많은 아기를 대략 "바보"로 만들 것입니다. 저처럼 정규식에 대해 궁금하다면, 둘째, 원리에 대한 기본 지식을 아는 것이 문법을 이해하고 정규 규칙을 작성하는 데 큰 도움이 됩니다.
1. 정규식이 효과적인 이유는 JS가 실행될 수 있는 이유와 동일합니다. 정규식을 기반으로 기계를 시뮬레이션하는 알고리즘입니다. 이 기계에는 테스트할 문자열을 읽어서 이러한 상태 사이를 이동합니다. 최종적으로 "해피 엔딩" 상태에 도달하면 그렇지 않으면 당신이 좋은 사람이라고 말해주세요. 정규식을 제한된 수의 단계로 결과를 계산할 수 있는 기계로 변환하여 엔진을 구현합니다.
일반 엔진은 크게 DFA와 NFA 두 가지 범주로 나눌 수 있습니다.
1. DFA(Deterministic Finite Automaton) 결정론적 유한 오토마톤 2 NFA(Non-Deterministic Finite Automaton) 비결정론적 유한 오토마톤, 대부분은 다음과 같습니다. NFA
여기서 "결정론적"은 특정 문자 입력에 대해 기계 상태가 확실히 a에서 b로 이동한다는 것을 의미하고 "비결정론적"은 특정 문자 입력에 대해 이 기계가 입력됨을 의미합니다. 여러 가지 상태 점프 방법이 있을 수 있습니다. 여기서 "유한"은 상태가 제한되어 있음을 의미하며 특정 문자열이 허용되는지 또는 좋은 사람 카드가 발급되는지 여부가 제한된 수의 단계 내에서 결정될 수 있습니다. 이 기계의 규칙이 정해지면 누구도 보지 않고도 스스로 판단을 내릴 수 있다는 의미로 이해됩니다.
2. 지식 보유
이 섹션은 정규 표현식, 특히 문자가 무엇인지, 위치가 무엇인지 이해하는 데 매우 유용합니다.
2.1 정규 표현식의 문자열 - n 문자, n+1 위치
위의 "웃음" 문자열에는 총 8개의 글자가 보이는데, 똑똑한 사람만 볼 수 있는 9개의 자리가 있습니다. 왜 캐릭터와 포지션이 필요한가요? 위치가 일치할 수 있기 때문입니다.
그런 다음 "점유 문자"와 "너비 0"을 이해하기 위해 한 단계 더 나아가겠습니다.
하위 정규 표현식이 위치 대신 문자와 일치하고 최종 결과에 저장될 경우 이 하위 표현식은 예를 들어, /ha/(ha와 일치)는 문자를 차지합니다.
하위정규어가 문자 대신 위치와 일치하거나 일치하는 내용이 결과에 저장되지 않는 경우 위치로 간주됨), 이 하위 표현식은 /read(?=ing)/와 같이 너비가 0입니다(읽기와 일치하지만 읽은 내용만 결과에 넣습니다. 구문은 아래에 자세히 설명되어 있습니다. 이는 단지 예일 뿐입니다.) , 그 중 (?=ing)은 너비가 0이며 본질적으로 위치를 나타냅니다.
소유된 문자는 상호 배타적이며 너비가 0이면 상호 배타적이지 않습니다. 즉, 한 문자는 동시에 하나의 하위 표현식과만 일치할 수 있지만, 한 위치는 너비가 0인 여러 하위 표현식과 동시에 일치할 수 있습니다. 예를 들어, /aa/는 a와 일치할 수 없습니다. 이 문자열의 a는 정규식의 첫 번째 문자와만 일치할 수 있으며 두 번째 a와 동시에 일치할 수는 없습니다(말도 안되는 소리). 예를 들어 /bba/는 a와 일치할 수 있습니다. 정규식에 단어의 시작을 나타내는 두 개의 b 메타 문자가 있지만 이 두 b는 위치 0(이 예에서는)과 동시에 일치할 수 있습니다.
참고: 문자열의 문자와 위치에 대해 이야기하고, 정규 표현식에 대해 사용된 문자와 너비가 0인 것에 대해 이야기합니다.
2.2 제어 및 전송
일부 블로그 게시물이나 정보를 검색할 때 이 두 단어를 만날 수 있습니다. 설명은 다음과 같습니다. 메타 문자)이 문자열과 일치하면 제어가 이루어집니다.
Transmission은 정규식 엔진의 메커니즘을 나타냅니다. 전송 장치는 문자열에서 정규식이 일치하기 시작하는 위치를 찾습니다.
정규 표현식이 일치하기 시작하면 일반적으로 하위 표현식이 문자열의 특정 위치에서 일치를 시도합니다. 하위 표현식이 일치를 시도하기 시작하는 위치는 이전 하위 표현식에서 시작됩니다. 예를 들어, read(?=ing)ingsbook은 reading book과 일치합니다. 우리는 이 정규 표현식을 read, (?=ing), ing, s, book으로 간주합니다. 4 단일 문자의 하위 표현이므로 여기서는 편의상 이렇게 처리합니다. 읽기는 위치 0에서 시작하여 위치 4와 일치합니다. 다음 (?=ing)은 위치 4부터 계속 일치합니다. 위치 4 뒤에 실제로 ing가 오는 것으로 확인되므로 일치가 성공했다고 주장됩니다. 전체(?=ing)는 위치와 일치합니다. 4는 단지 위치(여기서 너비가 0인 것이 무엇인지 더 잘 이해할 수 있음)이고, 다음 ing은 위치 4에서 위치 7까지 일치하고, s는 위치 7에서 위치 8까지 일치합니다. , 마지막 책은 위치 8부터 일치합니다. 위치 12에서 전체 일치가 완료됩니다.
3. "얕은" 매칭 여정 (생략 가능) 이렇게까지 말했지만 우리는 우리 자신을 정규 엔진이라고 생각하며 가장 작은 단위인 "캐릭터"와 "위치"부터 단계별로 살펴보겠습니다. 정규 매칭 과정에서 몇 가지 예를 들어보겠습니다.3.1 기본 일치정규식: easy
소스 문자열: 매우 쉬움
3.2 너비가 0인 일치
正则:^(?=[aeiou])[a-z]+$ 源字符串:apple
우선 이 정규식은 처음부터 끝까지 완전한 문자열과 일치합니다. 이 전체 문자열은 소문자로만 구성되고 a, e, i, o 5자로 시작합니다. , 그리고 u로 시작합니다.
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
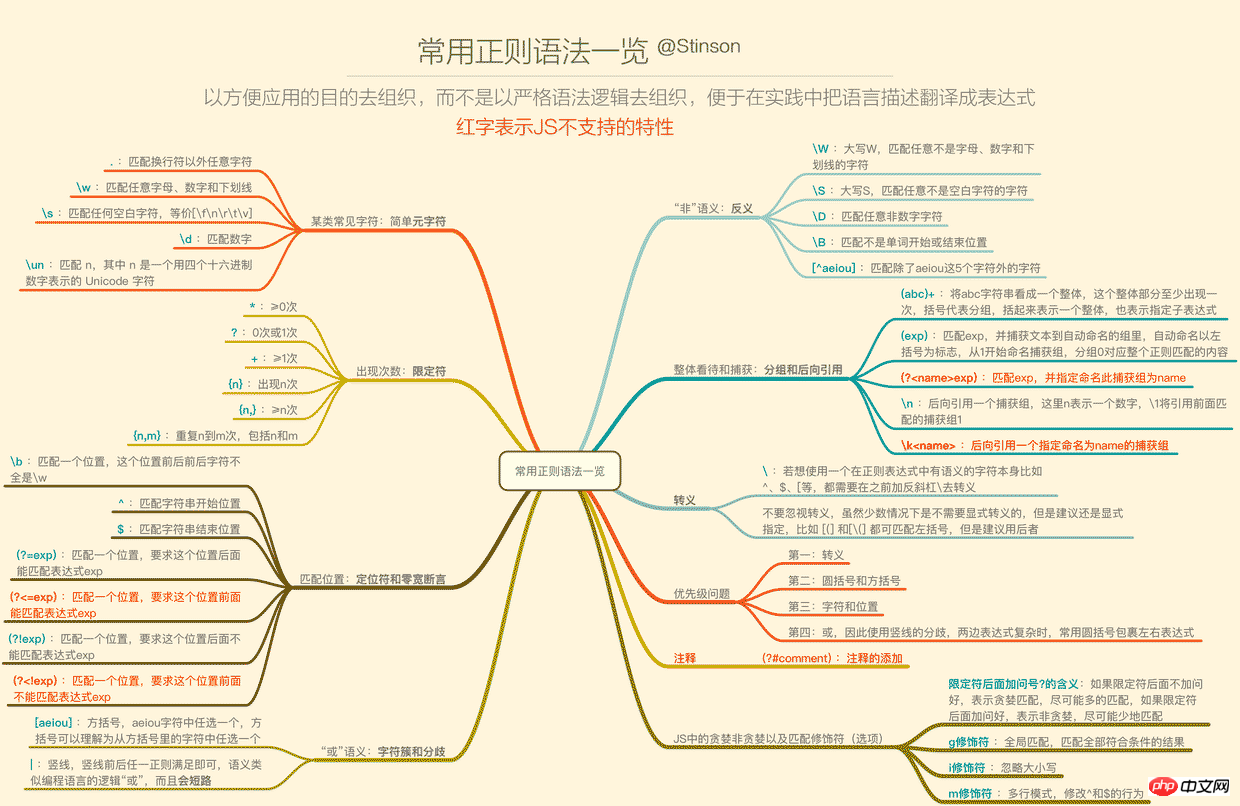
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a?는 문자 a의 발생 횟수를 0 또는 1회 나타냅니다.
a{5}는 문자 a의 연속 발생 횟수를 5회 나타냅니다.
a{5,}는 연속된 문자 a의 횟수를 나타냅니다. 문자 a >= 5회
a{5,10}는 문자 a의 연속 발생 횟수가 5와 10
3을 포함하여 5~10회임을 의미합니다. 일치 위치 - 로케이터 및 0 -width 어설션
특정 위치의 표현식과 일치합니다. 표현식은 모두 너비가 0이며 주로 두 부분으로 구성됩니다. 하나는 특정 위치와 일치하는 로케이터이고 다른 하나는 일치하는 너비가 0인 어설션입니다. 특정 요구 사항을 충족해야 하는 위치입니다.
다음 로케이터가 일반적으로 사용됩니다.
b는 단어 경계 위치와 일치합니다. 정확한 설명은 이 위치 앞과 뒤의 모든 문자가 w로 설명될 수 없으므로 u597dbabc와 일치할 수 있다는 것입니다. 좋은 abc" "의.
^은 문자열의 시작 위치인 위치 0과 일치합니다. RegExp 개체의 Multiline 속성이 설정된 경우 ^는 'n' 또는 'r' 다음의 위치도 일치합니다.
$는 끝과 일치합니다. RegExp 개체의 Multiline 속성이 설정된 경우 $는 'n' 또는 'r' 앞의 위치와도 일치하는 경우 문자열의 위치
제로 너비 어설션(JS에서 지원)에는 다음 두 가지가 있습니다.
(?=exp)는 위치와 일치합니다. 이 위치의 오른쪽은 표현식 exp와 일치할 수 있습니다. 이 표현식은 하나의 위치에만 일치하지만 이 위치의 오른쪽과 오른쪽에 있는 항목에 대한 요구 사항이 있습니다. "read"를 일치시키기 위해 read(?=ing )를 사용하는 것과 같이 side는 결과에 포함되지 않습니다. 결과는 "read"이고 "ing"은 결과에 포함되지 않습니다
(?!exp )가 위치와 일치하며, 이 위치의 오른쪽은 표현식 exp와 일치할 수 없습니다
4. "or"의 의미를 표현하고 싶습니다 - 문자 클러스터 및 차이점
예를 들어 우리는 종종 "or"의 의미를 표현합니다. , 이들 문자 중 하나가 일치하거나 5개의 숫자 또는 5개의 문자와 일치합니다.
문자 클러스터는 대괄호 안의 문자 중 하나를 나타내는 문자 수준의 "또는" 의미를 표현하는 데 사용할 수 있습니다.
[abc]는 a, b, c 세 문자 중 하나를 나타냅니다. 문자 또는 숫자가 연속적이면 -를 사용하여 나타낼 수 있습니다. [b-f]는 b에서 f까지의 여러 문자 중 하나를 나타냅니다. [(ab)(cd)]는 "ab" 또는 문자열과 일치하는 데 사용되지 않습니다. "cd"이지만 a, b, c, d, (,) 6개 문자 중 하나와 일치합니다. 즉, "ab 또는 cd 문자열 일치"라는 요구 사항을 표현하려면 이렇게 쓸 수 없습니다. ab|cd 이렇게요. 하지만 여기서는 괄호 자체를 논리적으로 이스케이프해야 합니다. 그러나 대괄호 안의 괄호는 여전히 명시적으로 이스케이프하는 것이 좋습니다. 차이점이 사용됨 표현식 수준에서 "or" 의미는 | 왼쪽 또는 오른쪽의 모든 표현식과 일치함을 의미합니다.
ab|cd는 문자열 "ab" 또는 "cd"와 일치합니다.
은 짧습니다. Circuited, 생각해 보세요
프로그래밍 언어의 논리 OR- 단락이므로 (ab | abc)를 사용하여 문자열 "abc"를 일치시키면 결과는 "ab"가 됩니다. 수직 막대의 왼쪽이 충족되었기 때문입니다. , 따라서 왼쪽의 일치 결과는 전체 일반 결과를 나타냅니다
- 5. "non"의 의미를 표현하고 싶습니다. - 반의어
- W , D, S, B를 사용해야 합니다. 대문자로 표시되는 메타 문자는 해당 소문자의 반의어입니다. 이러한 메타 문자는 "문자, 숫자, 밑줄을 제외한 문자", "숫자가 아닌 문자"와 일치합니다. 문자" 및 " "공백이 아닌 문자", "단어가 아닌 경계 위치"
[^aeiou]는 대괄호 안의 a, e, i, o, u를 제외한 모든 문자를 의미하며 시작 부분에 나타납니다. 제외를 의미합니다. ^가 대괄호 안에 표시되지 않으면 ^ 문자 자체를 나타냅니다.
-
6. 전체 보기 및 캡처 - 그룹화 및
역참조 -
실제로는 이미 본 내용입니다. 괄호 위의 일부 위치, 예, 괄호 한 쌍으로 묶인 것은 그룹화에 사용됩니다.
上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式 var exp = /pattern/flags; //比如 var pattern=/\b[aeiou][a-z]+\b/gi; //等价下面的构造函数创建 var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词 var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches; while(matches=pattern.exec(str)){ console.log(matches.index +' '+ matches[0] + ' ' + matches[1]); } //循环2次输出 //0 Reading Read //12 Writing Writ3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES61. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符 /^\uD83D/u.test('\uD83D\uDC2A') // false,加了u可以正确处理 /^\uD83D/.test('\uD83D\uDC2A') // true,不加u,当做两个unicode字符处理加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
드디어 JS 규칙성에 대한 설명을 10,000자 이상 작성했습니다. 쓰고 나니 규칙성에 대한 숙련도가 한 단계 더 발전한 것 같아서 자주 정리해 보시길 권합니다. 매우 유용합니다. , 그리고 기꺼이 그것을 여러분 자신과 공유하십시오. 그것은 모든 사람에게 큰 유익이 됩니다. 그것을 읽을 수 있는 모든 사람에게 감사드립니다.
이 기사의 사례를 읽은 후 방법을 마스터했다고 생각합니다. 더 흥미로운 정보를 보려면 PHP 중국어 웹사이트의 다른 관련 기사를 주목하세요!
추천 도서:
위 내용은 JS 정규식의 원리와 구문 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!