
NodeJS 백과사전 크롤러 예제 튜토리얼

- 小云云원래의
- 2017-12-18 09:21:261655검색
이 글은 주로 NodeJS를 사용하여 크롤러를 배우는 방법을 설명하고, 창피한 것들의 백과사전을 크롤링하여 사용법과 효과를 설명합니다. 모두에게 도움이 되기를 바랍니다.
1. 서문 분석
크롤러를 구현하기 위해 보통 Python/.NET 언어를 사용하지만, 이제 프론트엔드 개발자로서 당연히 NodeJS에 능숙해야 합니다. 다음으로 우리는 NodeJS 언어를 사용하여 Encyclopedia of Embarrassing Things에 대한 크롤러를 구현합니다. 또한, 이 글에서 사용된 코드 중 일부는 es6 구문입니다.
이 크롤러를 구현하는 데 필요한 종속 라이브러리는 다음과 같습니다.
request: get 또는 post 메소드를 사용하여 웹페이지의 소스 코드를 얻습니다. Cherio: 웹페이지 소스 코드를 구문 분석하고 필요한 데이터를 얻습니다.
이 문서에서는 먼저 크롤러에 필요한 종속성 라이브러리와 그 사용을 소개한 다음 이러한 종속성 라이브러리를 사용하여 Encyclopedia of Embarrassing Things용 웹 크롤러를 구현합니다.
2. 요청 라이브러리
request는 매우 강력하고 사용하기 쉬운 경량 http 라이브러리입니다. 이를 사용하여 Http 요청을 구현할 수 있으며 HTTP 인증, 사용자 정의 요청 헤더 등을 지원합니다. 다음은 요청 라이브러리의 일부 기능에 대한 소개입니다.
다음과 같이 요청 모듈을 설치하세요.
npm install request
request가 설치되면 이제 request를 사용하여 Baidu 웹 페이지를 요청할 수 있습니다.
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
옵션 매개변수가 설정되지 않은 경우 요청 방법은 기본적으로 요청 가져오기로 설정됩니다. 요청 객체를 즐겨 사용하는 구체적인 방법은 다음과 같습니다.
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
그러나 URL에서 얻은 html 소스 코드를 직접 요청하여 필요한 정보를 얻지 못하는 경우가 많습니다. 일반적으로 요청 헤더와 웹페이지 인코딩을 고려해야 합니다.
웹 페이지 요청 헤더 및 웹 페이지 인코딩
다음은 웹 페이지 요청 헤더를 추가하고 요청할 때 올바른 인코딩을 설정하는 방법을 설명합니다.
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
옵션 매개변수를 설정하고 헤더 속성을 추가하여 요청 헤더를 설정하세요. 인코딩 속성을 추가하여 웹페이지의 인코딩을 설정하세요. 인코딩이 null 인 경우 get 요청으로 얻은 콘텐츠는 Buffer 개체입니다. 즉, 본문은 Buffer 개체입니다.
위에 소개된 기능은 다음 요구 사항을 충족하기에 충분합니다.
3.cheerio 라이브러리
cheerio는 가볍고 빠르며 배우기 쉬운 특성으로 개발자들에게 사랑받는 서버 측 Jquery입니다. Jquery에 대한 기본 지식이 있으면 Cherio 라이브러리를 배우는 것은 매우 쉽습니다. 웹 페이지에서 요소를 빠르게 찾을 수 있으며 규칙은 Jquery의 요소 찾기 방법과 동일합니다. 또한 html의 요소 내용을 수정하고 매우 편리한 형식으로 해당 데이터를 얻을 수도 있습니다. 다음은 주로 웹 페이지에서 요소를 빠르게 찾고 해당 내용을 얻기 위한 Cherio를 소개합니다.
먼저 체리오 라이브러리를 설치하세요
npm install cheerio
다음은 코드 일부와, 체리오 라이브러리의 사용법을 설명합니다. 블로그파크 홈페이지를 분석한 후, 각 페이지의 기사 제목을 추출합니다.
먼저 블로그파크 홈페이지를 분석해보세요. 아래와 같이
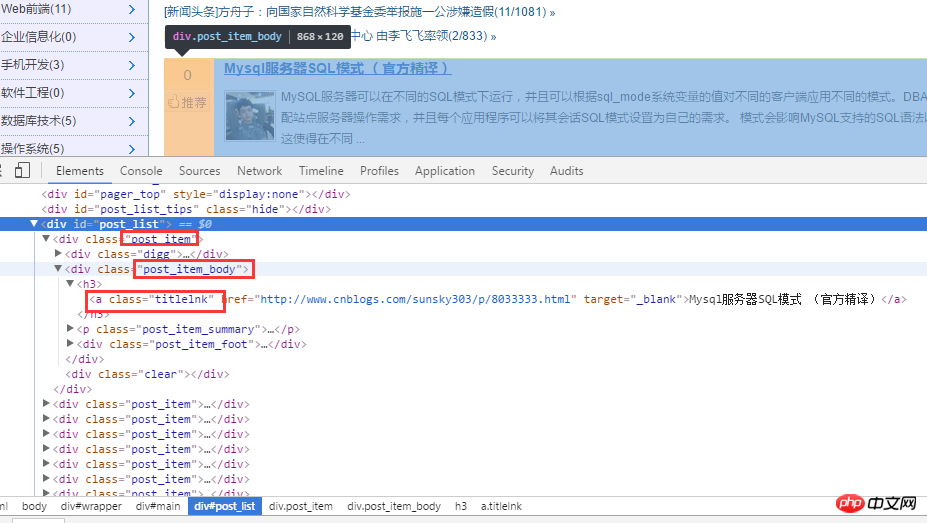
html 소스코드를 분석한 후, 먼저 .post_item을 통해 모든 제목을 얻은 후, 각 .post_item을 분석하고, a.titlelnk를 사용하여 각 제목의 a 태그를 일치시킵니다. 다음은 코드를 통해 구현됩니다.
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
물론, Cherio 라이브러리는 연쇄 호출도 지원하며 위 코드는 다음과 같이 다시 작성할 수도 있습니다.
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
위 코드는 매우 간단하므로 말로 설명하지는 않겠습니다. 아래에서는 제가 더 중요하다고 생각하는 몇 가지 사항을 요약해 보겠습니다.
find() 메서드를 사용하여 노드 세트 A를 얻습니다. A 세트의 요소를 다시 루트 노드로 사용하여 하위 노드를 찾고 하위 요소의 콘텐츠와 속성을 얻는 경우 $를 수행해야 합니다. (A 세트 [i]의 하위 요소에 대한 A) 위의 $(ele) 와 같은 래퍼입니다. 위 코드에서는 $(ele)를 사용하고 있는데 실제로 $(this)도 사용할 수 있는데, es6의 화살표 함수를 사용하고 있기 때문에 각각의 메소드에서 콜백 함수의 this 포인터가 변경되었습니다. 따라서 나는 $(ele); 를 사용합니다. Cherio 라이브러리는 위의 $('.post_item').find('a.titlelnk') 와 같은 체인 호출도 지원합니다. (). A가 컬렉션인 경우 A 컬렉션의 각 하위 요소에 대해 find() 메서드가 호출되고 결과 공용체가 다시 배치됩니다. A가 text()를 호출하면 A 컬렉션의 각 하위 요소는 text()를 호출하고 모든 하위 요소의 내용을 통합한 문자열을 반환합니다(직접 통합, 구분 기호 없음).
마지막으로 제가 자주 사용하는 몇 가지 방법을 요약하겠습니다.
first() last() children([selector]): 이 방법은 하위 노드만 검색하는 반면 find는 전체 하위 노드를 검색한다는 점을 제외하면 find와 유사합니다.
4. 당황스러운 백과사전 크롤러
위의 요청 및 치리오 클래스 라이브러리 소개를 통해 이 두 라이브러리를 사용하여 당황한 백과사전의 페이지를 크롤링해 보겠습니다.
1. 프로젝트 디렉토리에서 새로운 httpHelper.js 파일을 생성하고, URL을 통해 Encyclopedia of Embarrassing Things의 웹페이지 소스 코드를 얻으세요:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2. 새로운 Splider.js 파일을 생성하고 Encyclopedia of Embarrassing Things의 웹 코드를 분석하고, 필요한 정보를 추출하고, URL의 ID를 변경하여 다양한 페이지에서 데이터를 크롤링하는 로직을 구축합니다.
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
위 내용은 NodeJS 백과사전 크롤러 예제 튜토리얼의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!