
Python--BeautifulSoup 라이브러리 소개

- 零下一度원래의
- 2017-06-23 11:14:513148검색
BeautifulSoup은 사용자가 제공하는 모든 것을 구문 분석하고 트리 순회 작업을 수행합니다.
BeautifulSoup 라이브러리는 "태그 트리"를 구문 분석, 순회 및 유지 관리하기 위한 함수 라이브러리입니다(순회는 특정 검색 경로를 따르는 것을 의미합니다. 순서 트리의 각 노드를 한 번만 방문하십시오.
우리는 종종 BeautifulSoup 라이브러리를 bs4라고 부릅니다. 라이브러리를 가져오려면 bs4에서 BeautifulSoup을 가져오세요. 그 중 import BeautifulSoup은 bs4의 BeautifulSoup 클래스를 주로 사용합니다.
bs4 라이브러리 파서
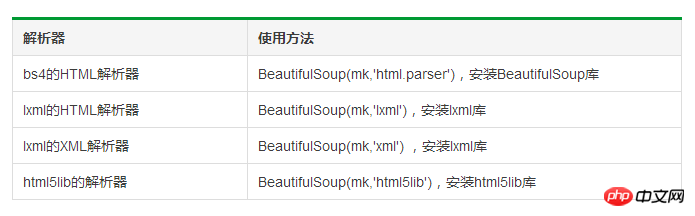
BeautifulSoup 클래스의 기본 요소
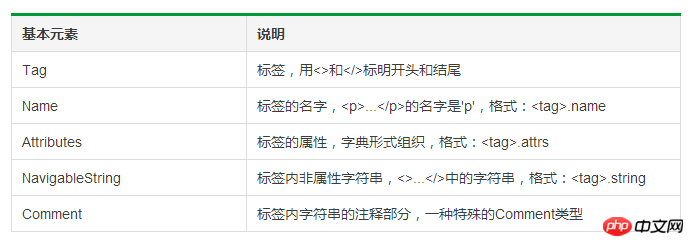
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到실행 결과:
a
{'href': '', 'class': ['no-login']} ['no-login']
로그인
댓글은 다음과 같습니다
bs4 라이브러리용 HTML의 기본 구조
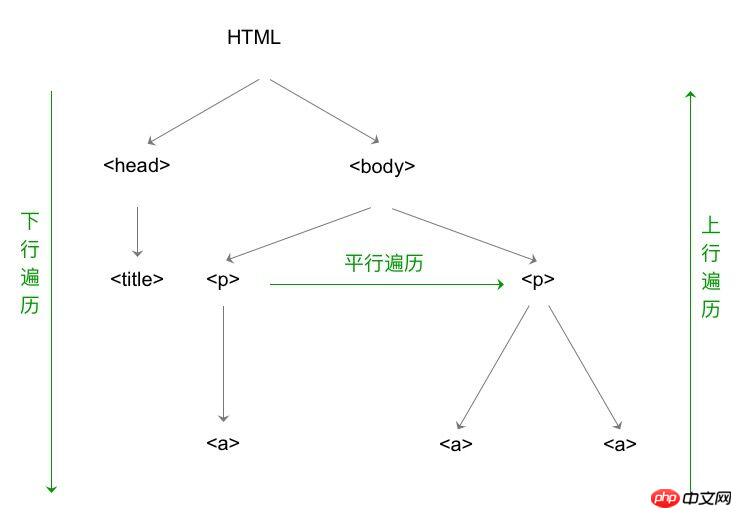 태그 트리의 하향 순회
태그 트리의 하향 순회
그 중 BeautifulSoup 유형은 태그 트리의 루트 노드입니다.
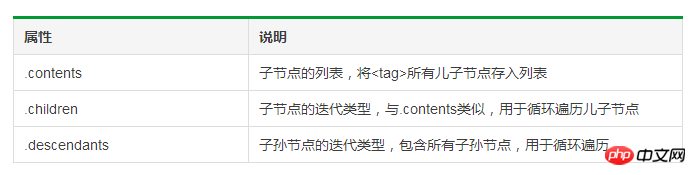
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)
1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)

div
몸
html
[문서]
태그 트리의 병렬 순회
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
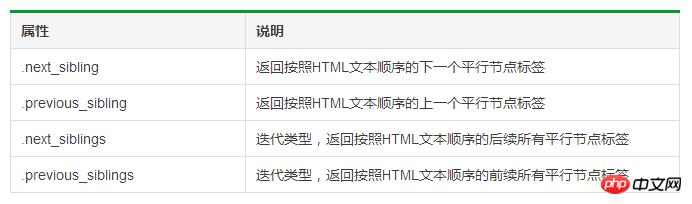
운영 환경: Mac, Python 3.6, PyCharm 2016.2
참고: 중국 대학교 MOOC 과정 "Python 웹 크롤러 및 정보 추출"위 내용은 Python--BeautifulSoup 라이브러리 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!