
집 >운영 및 유지보수 >리눅스 운영 및 유지 관리 >리눅스 프로세스와 신호
리눅스 프로세스와 신호
- 巴扎黑원래의
- 2017-06-23 13:49:162215검색
이 문서의 디렉토리:
9.1 프로세스에 대한 간략한 설명
9.11 프로세스와 프로그램의 차이점
9.12 멀티태스킹 및 CPU 시간 슬라이싱
9.13 상위-하위 프로세스 및 프로세스 생성 방법
9.14 프로세스 상태
9.15 예를 들어 분석해 보세요. 프로세스 상태 전환 프로세스
9.16 프로세스 구조 및 서브쉘
9.2 작업
9.3 터미널과 터미널의 관계 프로세스
9.4 신호
9.41 알아야 할 신호
9.42 SIGHUP
9. 43 좀비 프로세스 및 SIGCHLD
9.4 4 수동으로 보내기 신호(kill 명령)
9.45 pkill 및 killall
9.5 퓨저 및 lsof
9.1 프로세스에 대한 간략한 설명
프로세스는 다음과 같습니다. 매우 복잡한 개념이고 많은 내용이 포함됩니다. 이 섹션에 나열된 내용은 명령을 사용하여 상태를 확인하는 방법보다 이러한 이론을 최대한 이해해야 한다고 생각합니다. 상태 정보는 나중에 확인해 보세요. 기본적으로 해당 상태가 무엇을 의미하는지 모르겠습니다.
그러나 프로그래머가 아닌 경우 프로세스 세부 사항을 자세히 알아볼 필요는 없습니다.
9.1.1 프로세스와 프로그램의 차이점
프로그램은 바이너리 파일로 디스크에 정적으로 저장되며 시스템 실행 리소스(CPU/메모리)를 차지하지 않습니다.
프로세스는 사용자가 프로그램을 실행하거나 프로그램을 트리거한 결과입니다. 프로세스는 프로그램의 실행 중인 인스턴스라고 간주할 수 있습니다. 프로세스는 동적이며 시스템 리소스를 적용 및 사용하고 운영 체제 커널과 상호 작용합니다. 다음 기사에서는 많은 상태 통계 도구의 결과가 시스템 클래스의 상태를 보여줍니다. 실제로 시스템 상태의 동의어는 커널 상태입니다.
9.1.2 멀티태스킹 및 CPU 시간 슬라이싱
이제 모든 운영 체제는 멀티태스킹 또는 병렬 실행인 여러 프로세스를 "동시에" 실행할 수 있습니다. 그러나 실제로 이것은 인간의 착각입니다. 물리적 CPU는 동시에 하나의 프로세스만 실행할 수 있습니다.
인간은 운영 체제가 여러 작업을 병렬로 수행할 수 있다는 환상을 갖게 됩니다. 이는 매우 짧은 시간에 프로세스 간 전환을 통해 이루어집니다. 프로세스 A는 한 순간에 실행되고 프로세스 A는 실행됩니다. B. 여러 프로세스 사이를 끊임없이 전환하면 인간은 동시에 여러 작업을 처리하고 있다고 생각하게 됩니다. 그러나 CPU가 실행할 다음 프로세스를 선택하는 방법은 매우 복잡한 문제입니다.Linux에서는 다음에 실행할 프로세스를 결정하는 것이 "스케줄링 클래스"(스케줄러)를 통해 이루어집니다. 프로그램 실행 여부는 프로세스의 우선순위에 따라 결정되지만, 우선순위 값이 낮을수록 우선순위가 높아지고 스케줄링 클래스에서 더 빨리 선택됩니다. Linux에서는 프로세스의 nice 값을 변경하면 특정 프로세스 유형의 우선 순위 값에 영향을 미칠 수 있습니다.
일부 프로세스는 더 중요하므로 가능한 한 빨리 완료해야 하지만 일부 프로세스는 덜 중요하므로 더 일찍 또는 나중에 완료해도 큰 영향을 미치지 않습니다. 따라서 운영 체제는 어떤 프로세스가 더 중요하고 어떤 프로세스가 더 중요한지 알 수 있어야 합니다. 프로세스는 덜 중요합니다. 더 중요한 프로세스의 경우 가능한 한 빨리 완료될 수 있도록 더 많은 CPU 실행 시간을 할당해야 합니다. 아래 그림은 CPU 타임슬라이스의 개념이다.

이를 통해 모든 프로세스가 실행될 기회가 있지만 중요한 프로세스는 항상 더 많은 CPU 시간을 확보한다는 것을 알 수 있습니다. 이 방법은 "선점형 멀티태스킹"입니다. 커널은 CPU를 동시에 실행하도록 할 수 있습니다. .CPU 칩이 소진되면 CPU 사용 권한이 복구되고 스케줄링 클래스에서 선택한 프로세스에 CPU가 할당됩니다. 또한 경우에 따라 현재 실행 중인 프로세스도 직접 선점될 수 있습니다. 시간이 지남에 따라 프로세스에 할당된 시간은 점차 소모됩니다. 할당된 시간이 소모되면 커널은 프로세스에 대한 제어권을 되찾고 다음 프로세스를 실행하게 됩니다. 그러나 이전 프로세스가 아직 완료되지 않았기 때문에 스케줄링 클래스는 앞으로도 이를 계속 선택할 것이므로 각 프로세스가 일시적으로 중지될 때 커널은 런타임 환경(레지스터 및 페이지 테이블의 내용)을 저장해야 합니다. 위치는 커널이 차지하는 메모리입니다. 이를 보호 사이트라고 합니다. 다음에 프로세스가 다시 실행될 때 원래 런타임 환경이 CPU에 로드되어 CPU가 계속 실행될 수 있습니다. 원래 런타임 환경에서.
리딩에서는 Linux 스케줄러가 CPU 타임 슬라이스의 경과에 따라 실행할 다음 프로세스를 선택하는 것이 아니라 프로세스의 대기 시간, 즉 준비 대기열에서 대기한 시간과 그 프로세스를 고려한다고 말했습니다. 가장 엄격한 시간 요구 사항이 있는 프로세스는 가능한 한 빨리 실행을 예약해야 합니다. 또한 중요한 프로세스에는 자연스럽게 더 많은 CPU 실행 시간이 할당됩니다.
스케줄링 클래스는 실행할 다음 프로세스를 선택한 후 기본 작업 전환, 즉 컨텍스트 전환을 수행해야 합니다. 이 프로세스에는 CPU 프로세스와의 긴밀한 상호 작용이 필요합니다. 프로세스 전환은 너무 빈번해도 안 되고, 너무 느려도 안 됩니다. 너무 자주 전환하면 보호 및 복구 장면에서 CPU가 너무 오랫동안 유휴 상태가 되어 사람이나 프로세스에 생산적이지 않습니다(프로그램을 실행하지 않기 때문에). 너무 느리게 전환하면 프로세스 예약 전환이 느려질 수 있습니다. 직설적으로 말하면 ls 명령을 실행하면 다음 프로세스가 오랫동안 기다려야 할 가능성이 높습니다. 반나절을 기다려야 하는데 이는 분명히 허용되지 않습니다.
이 시점에서 우리는 메모리의 측정 단위가 공간 크기인 것처럼 cpu의 측정 단위가 시간이라는 것을 알고 있습니다. 프로세스가 차지하는 CPU 시간이 길다는 것은 CPU가 해당 프로세스에서 실행되는 데 오랜 시간을 보낸다는 의미입니다. CPU의 백분율 값은 작업 강도나 빈도가 아니라 "프로세스가 차지하는 CPU 시간/총 CPU 시간"이라는 점에 유의하세요.
9.1.3 상위-하위 프로세스 및 프로세스 생성 방법
각 프로세스에는 프로그램을 실행하는 사용자의 UID 및 기타 기준에 따라 고유한 PID가 할당됩니다.
부모-자식 프로세스의 개념을 간단히 말하면 특정 프로세스(부모 프로세스)의 컨텍스트에서 프로그램이 실행되거나 호출될 때 이 프로그램에 의해 트리거되는 프로세스가 자식 프로세스이고 프로세스의 PPID가 이를 나타냅니다. 프로세스의 상위 프로세스의 PID입니다. 이를 통해 우리는 하위 프로세스가 항상 상위 프로세스에 의해 생성됨을 알 수 있습니다.
Linux에서는 부모-자식 프로세스가 트리 구조로 존재하며, 부모 프로세스에 의해 생성된 여러 자식 프로세스를 형제 프로세스라고 합니다. CentOS 6에서는 init 프로세스가 모든 프로세스의 상위 프로세스이고 CentOS 7에서는 systemd입니다.
Linux에서 하위 프로세스를 생성하는 세 가지 방법이 있습니다(매우 중요한 개념): 하나는 포크로 생성된 프로세스, 하나는 exec로 생성된 프로세스, 또 하나는 클론으로 생성된 프로세스입니다.
(1).fork는 현재 프로세스의 복사본을 복사하고(기록 중 복사 모드에 관계없이) 이러한 리소스를 적절한 방식으로 하위 프로세스에 전달하는 복사 프로세스입니다. 따라서 하위 프로세스가 제어하는 리소스는 메모리 내용을 포함하여 상위 프로세스의 리소스와 동일하므로 환경 변수 및 변수도 포함됩니다. 그러나 상위 프로세스와 하위 프로세스는 완전히 독립적입니다. 동일한 프로그램의 두 인스턴스입니다.
(2).exec는 현재 실행 중인 프로세스를 대체하기 위해 다른 응용 프로그램을 로드하는 것입니다. 이는 새 프로세스를 만들지 않고 새 프로그램을 로드하는 것을 의미합니다. exec에는 다른 작업도 있습니다. 프로세스가 실행된 후 exec가 있는 쉘을 종료합니다. 따라서 프로세스 보안을 보장하기 위해 새롭고 독립적인 자식 프로세스를 형성하려면 먼저 현재 프로세스의 복사본을 포크한 다음 포크된 자식 프로세스에 대해 exec를 호출하여 자식을 대체할 새 프로그램을 로드해야 합니다. 프로세스. 예를 들어, bash에서 cp 명령을 실행하면 bash가 먼저 분기되고 exec는 cp 프로그램을 로드하여 하위 bash 프로세스를 덮어쓰고 cp 프로세스가 됩니다.
(3).clone은 스레드를 구현하는 데 사용됩니다. 클론은 포크와 동일하게 작동하지만 복제된 새 프로세스는 상위 프로세스와 독립적이지 않습니다. 프로세스를 복제할 때 공유할 리소스를 지정할 수 있습니다.
일반적으로 형제 프로세스는 독립적이고 서로 보이지 않지만 때로는 특별한 수단을 통해 프로세스 간 통신을 달성할 수 있습니다. 예를 들어, 파이프는 양쪽의 프로세스를 조정하며 양쪽의 프로세스는 동일한 프로세스 그룹에 속하며 해당 PPID는 동일합니다. 파이프를 사용하면 "파이프라인" 방식으로 데이터를 전송할 수 있습니다.
프로세스에는 소유자, 즉 개시자가 있습니다. 사용자가 프로세스 개시자, 상위 프로세스 개시자 또는 루트 사용자가 아닌 경우 프로세스를 종료할 수 없습니다. 그리고 상위 프로세스(비터미널 프로세스)를 종료하면 하위 프로세스가 고아 프로세스가 됩니다. 고아 프로세스의 상위 프로세스는 항상 init/systemd입니다.
9.1.4 프로세스 상태
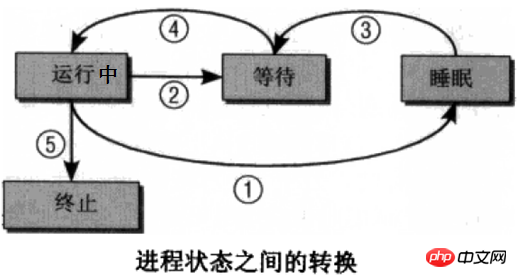
프로세스가 항상 실행되는 것은 아닙니다. 적어도 CPU가 실행되고 있지 않을 때는 실행되지 않습니다. 프로세스에는 여러 상태가 있으며 상태 전환은 여러 상태 간에 이루어질 수 있습니다. 아래 그림은 매우 고전적인 프로세스 상태 설명 다이어그램입니다. 개인적으로는 오른쪽 그림이 더 이해하기 쉽다고 생각합니다.
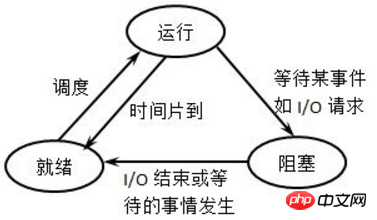
실행 상태: 프로세스가 실행 중입니다. 즉, CPU가 실행 중입니다.
Ready(대기) 상태: 프로세스가 실행될 수 있고 이미 대기 대기열에 있습니다. 즉, 예약 클래스가 다음에 이를 선택할 수 있음을 의미합니다.
Sleep(차단) 상태: 프로세스가 절전 모드이므로 실행할 수 없습니다.
각 상태 간의 변환 방법은 다음과 같습니다. (이해하기 쉽지 않을 수 있으므로 나중에 예제와 결합할 수 있습니다.)
(1) 새 상태 -> 준비 상태: 대기 큐가 새 프로세스를 수락할 수 있는 경우 , 커널은 새 프로세스를 대기 대기열로 이동합니다.
(2) 준비 상태 -> 실행 상태: 스케줄링 클래스가 대기 큐에 있는 프로세스를 선택하고 프로세스가 실행 상태로 들어갑니다.
(3) 실행 상태 -> 절전 상태: 실행 중인 프로세스는 특정 이벤트(IO 대기, 신호 대기 등) 발생을 기다려야 하고 절전 상태에 들어가기 때문에 실행할 수 없습니다.
(4) Sleep 상태 -> Ready 상태: 프로세스가 기다리고 있는 이벤트가 발생하면 프로세스는 Sleep 상태에서 대기 큐로 큐에 들어가 다음 번 실행을 위해 선택되기를 기다립니다.
(5) 실행 상태 -> 준비 상태: 타임 슬라이스 부족으로 인해 실행 프로세스가 일시 중지되거나 선점형 스케줄링 모드에서는 우선 순위가 높은 프로세스가 우선 순위가 낮은 프로세스를 강제로 선점합니다.
(6) 실행 중 상태 -> 종료 상태: 프로세스가 완료되거나 특별한 이벤트가 발생하면 프로세스가 종료 상태가 됩니다. 명령의 경우 일반적으로 종료 상태 코드가 반환됩니다.
위 그림에는 "Ready-->Sleep"과 "Sleep-->Run" 사이를 전환하는 상태가 없습니다. 이해하기 쉽습니다. "Ready-->Sleep"의 경우 대기 프로세스가 이미 대기 대기열에 진입하여 실행될 수 있음을 나타내며, 절전 상태로 진입한다는 것은 일시적으로 실행할 수 없음을 의미하며 이는 "Sleep--"에 대한 충돌입니다. >Run" 예약 클래스가 대기 대기열에서 실행할 다음 프로세스를 선택하기 때문에 이 방법도 작동하지 않습니다.
실행 상태-->수면 상태에 대해 이야기해 보겠습니다. Running 상태에서 Sleep 상태까지 일반적으로 신호 알림을 기다리거나 IO가 완료되기를 기다리는 등 이벤트 발생을 기다리는 것입니다. 신호 알림은 이해하기 쉽지만 IO 대기, 프로그램 실행을 위해 CPU는 프로그램의 명령을 실행해야 하며 동시에 변수 데이터, 키보드 입력 데이터 또는 데이터일 수 있는 데이터를 입력해야 합니다. 디스크 파일에서 후자의 두 가지 데이터 유형은 CPU에 비해 매우 느립니다. 그러나 무슨 일이 있어도 CPU가 데이터가 필요한 순간에 데이터를 얻을 수 없다면 CPU는 유휴 상태로만 있을 수 있습니다. CPU는 매우 귀중한 리소스이기 때문에 커널은 이를 허용해야 합니다. CPU가 실행되고 데이터가 필요합니다. 프로세스는 일시적으로 대기 상태가 되어 데이터가 준비될 때까지 기다린 후 대기 큐로 돌아가서 예약 클래스에 의해 선택되기를 기다립니다. IO 대기 중입니다.
사실 위 사진에는 프로세스-좀비 상태의 특수한 상태가 빠져있습니다. 좀비 프로세스는 프로세스가 종료된 상태로 전환되어 임무를 완료하고 사라졌지만 커널이 프로세스 목록에서 해당 항목을 삭제할 시간이 없었음을 의미합니다. 이는 커널이 처리하지 않았음을 의미합니다. 이는 프로세스가 죽었으면서도 살아 있다는 착각을 불러일으킵니다. 프로세스가 더 이상 리소스를 소비하지 않기 때문에 죽었다고 합니다. 스케줄링 클래스가 이를 선택하여 실행하도록 하는 것은 불가능합니다. 아직 프로세스 목록에 캡처할 수 있는 해당 항목이 있기 때문입니다. 좀비 프로세스는 많은 리소스를 차지하지 않으며 프로세스 목록에서 약간의 메모리만 차지합니다. 대부분의 좀비 프로세스는 프로세스가 정상적으로 종료(kill -9 포함)되어 나타나는데, 부모 프로세스에서는 프로세스가 종료되었음을 확인하지 않아 커널에 알리지 않으며, 커널은 프로세스가 종료된 사실을 알지 못한다. 좀비 프로세스에 대한 자세한 설명은 later를 참조하세요.
또한, 수면 상태는 중단 가능한 수면과 중단 없는 수면으로 나누어지는 매우 광범위한 개념입니다. 인터럽트 가능한 수면은 외부 신호 및 커널 신호를 수신하여 깨울 수 있는 수면입니다. 대부분의 수면은 ps 또는 top에 의해 포착될 수 있는 수면은 거의 항상 중단 불가능한 수면에 의해서만 제어될 수 있습니다. 커널을 깨우기 위한 신호를 시작합니다. 외부 세계는 주로 하드웨어와 상호 작용할 때 신호를 통해 깨어날 수 없습니다. 예를 들어 파일을 가져올 때 하드 디스크에서 메모리로 데이터를 로드하는 것은 하드웨어와 상호 작용하는 짧은 시간 동안 중단되지 않아야 합니다. 그렇지 않으면 데이터를 로드할 때 인공 신호에 의해 갑자기 수동으로 깨어나게 됩니다. 하드웨어 상호 작용 프로세스가 아직 완료되지 않았으므로 깨어나더라도 CPU에 실행을 줄 수 없으므로 캣팅할 때 콘텐츠의 일부만 표시하는 것은 불가능합니다. 파일. 더욱이, 중단 없는 절전 모드를 인위적으로 깨울 수 있다면 더 심각한 결과는 하드웨어 충돌이 될 것입니다. 무정전 수면은 특정 중요한 프로세스를 보호하고 CPU가 낭비되는 것을 방지하기 위한 것임을 알 수 있습니다. 일반적으로 중단할 수 없는 수면은 수명이 매우 짧고 프로그래밍 방식이 아닌 방식으로 포착하기가 매우 어렵습니다. 실제로 프로세스가 존재하는 것으로 확인되고 좀비 프로세스가 아니며 CPU 리소스를 점유하지 않는 한 해당 프로세스는 휴면 상태입니다. 기사 뒷부분에 나오는 일시 정지 상태와 추적 상태를 포함하면 이 역시 절전 상태입니다.9.1.6 프로세스 구조 및 하위 셸
포그라운드 프로세스: 일반 명령(예: cp 명령)은 실행을 위해 하위 프로세스를 분기합니다. 하위 프로세스가 실행되는 동안 상위 프로세스는 절전 모드로 전환됩니다. 이러한 유형의 프로세스가 포그라운드 프로세스입니다. 포그라운드 프로세스가 실행되면 상위 프로세스는 절전 모드로 전환됩니다. CPU가 하나뿐이므로 CPU가 여러 개 있어도 실행 흐름(프로세스 대기)으로 인해 하나의 프로세스만 실행될 수 있습니다. , 여러 실행 스트림은 프로세스 내 멀티스레딩을 사용하여 구현되어야 합니다.
백그라운드 프로세스: 명령어 실행 시 명령어 끝에 "&" 기호를 추가하면 백그라운드로 진입합니다. 명령을 백그라운드에 넣으면 즉시 상위 프로세스로 돌아가고 백그라운드 프로세스의 jobid 및 pid가 반환되므로 백그라운드 프로세스의 상위 프로세스는 절전 모드로 전환되지 않습니다. 백그라운드 프로세스에서 오류가 발생하거나 실행이 완료되어 백그라운드 프로세스가 종료되면 상위 프로세스가 신호를 받습니다. 따라서 명령 뒤에 "&"를 추가하고 "&" 뒤에 실행할 다른 명령을 제공하면 "cp /etc/fstab /tmp & cat /etc와 같은 "의사 병렬" 실행을 달성할 수 있습니다. /fstab".
bash 내장 명령: bash 내장 명령은 매우 특별합니다. 상위 프로세스는 이러한 명령을 실행하기 위해 하위 프로세스를 생성하지 않지만 현재 bash 프로세스에서 직접 실행됩니다. 그러나 내장 명령을 파이프 뒤에 배치하면 내장 명령은 파이프 왼쪽의 프로세스와 동일한 프로세스 그룹에 속하므로 하위 프로세스가 계속 생성됩니다.
이렇게 말했으니, 이 특별한 하위 프로세스인 서브쉘을 설명해야 합니다.
일반적으로 분기된 하위 프로세스의 내용은 변수를 포함하여 상위 프로세스의 내용과 동일합니다. 예를 들어 상위 프로세스의 변수는 cp 명령을 실행할 때도 얻을 수 있습니다. 그러나 cp 명령은 어디에서 실행됩니까? 서브쉘에서. cp 명령을 실행하고 Enter 키를 누른 후 현재 bash 프로세스는 하위 bash를 분기하고 하위 bash는 exec를 통해 cp 프로그램을 로드하여 하위 bash를 대체합니다. 여기서 sub-bash와 sub-shell에 얽매이지 마세요. 관계를 알 수 없다면 그냥 동일하게 취급하세요.
모든 명령의 실행 환경이 서브쉘에 있다는 것을 알 수 있나요? 분명히 위에서 언급한 bash 내장 명령은 하위 쉘에서 실행되지 않습니다. 다른 모든 방법은 서브쉘에서 수행되지만 방법은 다릅니다. 완전한 서브쉘에 대해서는 서브쉘이 여러 곳에서 언급되는 man bash를 참조하십시오. 다음은 몇 가지 일반적인 방법입니다.
(1) bash 명령을 직접 실행합니다. 이는 매우 우연적인 순서이다. bash 명령 자체는 내장된 bash 명령입니다. 현재 쉘 환경에서 내장된 명령을 실행하면 하위 쉘이 생성되지 않습니다. 즉, 실제 결과는 새 bash가 하위 프로세스라는 것입니다. . 그 이유 중 하나는 bash 명령을 실행하면 다양한 환경 구성 항목이 로드되기 때문입니다. 상위 bash 환경을 덮어쓰지 않으려면 하위 쉘로 존재해야 합니다. 포크에서 나오는 bash 하위 프로세스의 내용은 상위 셸을 완전히 상속하지만 환경 구성 항목을 다시 로드하므로 하위 셸은 일반 변수를 상속하지 않고 변수를 덮어씁니다. 상위 쉘에서 상속됩니다. /etc/bashrc 파일에서 변수를 정의한 다음 상위 셸에서 이름은 같지만 값이 다른 환경 변수를 내보낸 다음 하위 셸로 이동하여 변수 값이 무엇인지 확인할 수도 있습니다.
(2). 쉘 스크립트를 실행합니다. 스크립트의 첫 번째 줄은 항상 "#!/bin/bash"이거나 직접 "bash xyz.sh"이기 때문에 이는 실제로 위의 bash를 실행하여 하위 쉘에 들어가는 것과 동일합니다. 둘 다 bash 명령을 사용합니다. 서브쉘을 입력하세요. 실행 스크립트에는 명령이 실행된 후 자동으로 서브셸을 종료하는 작업이 하나 더 있습니다. 따라서 스크립트가 실행될 때 상위 쉘의 환경 변수는 스크립트에 상속되지 않습니다. - (3) 내장되지 않은 명령에 대한 명령 대체. 명령에 명령 대체 부분이 포함된 경우 이 부분이 먼저 실행됩니다. 이 부분이 내장 명령이 아닌 경우 서브쉘에서 완료되고 실행 결과가 현재 명령으로 반환됩니다. 이 서브쉘은 bash 명령을 통해 입력된 서브쉘이 아니기 때문에 상위 쉘의 모든 변수 내용을 상속합니다. 이것은 또한 "$(echo $$)"에서 "$$"의 결과가 bash 명령을 사용하여 입력된 서브 쉘이 아니기 때문에 서브 쉘의 pid 번호가 아니라 현재 bash의 pid 번호임을 설명합니다.
- exec와 source라는 두 가지 특수 스크립트 호출 방법도 있습니다.
- exec: exec는 현재 프로세스를 대체하는 로더이므로 서브쉘을 열지 않고, 현재 쉘에 있는 명령이나 스크립트를 직접 실행한 후 exec가 위치한 쉘을 바로 종료한다. 이는 bash에서 cp 명령을 실행할 때 cp가 실행된 후 cp가 있는 하위 쉘이 자동으로 종료되는 이유를 설명합니다.
- source: 소스는 일반적으로 환경 구성 스크립트를 로드하는 데 사용되며 명령을 직접 로드할 수 없습니다. 또한 서브쉘을 열지 않고 현재 쉘에서 호출 스크립트를 직접 실행하며 스크립트 실행 후 현재 쉘을 종료하지 않으므로 스크립트는 현재 기존 변수를 상속하고 스크립트 실행 후 로드된 환경 변수는 현재 셸에 고정되어 현재 셸에 적용됩니다.
9.2 작업 작업
대부분의 프로세스는 백그라운드 작업이므로 작업이라고 하는 경우가 많습니다. , 각 직업은 직업 테이블의 직업 항목에 해당합니다.
백그라운드에서 명령이나 스크립트를 수동으로 실행하려면 명령줄 뒤에 "&" 기호를 추가하세요. 예:
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
프로세스를 백그라운드에 넣은 후 즉시 상위 프로세스로 돌아갑니다. 일반적으로 백그라운드에 수동으로 넣은 프로세스는 bash에서 수행되므로 bash 환경으로 돌아갑니다. 즉시. 상위 프로세스를 반환하는 동안 해당 jobid 및 pid도 상위 프로세스로 반환됩니다. 나중에 jobid를 인용하려면 jobid 앞에 백분율 기호 "%"를 추가해야 합니다. 여기서 "%%"는 현재 작업을 나타냅니다. 예를 들어 "kill -9 %1"은 jobid 1로 백그라운드 프로세스를 종료한다는 의미입니다. . 100개의 세미콜론을 추가하지 않으면 종료되며 Init 프로세스를 종료합니다.
jobs 명령을 통해 백그라운드 작업 정보를 볼 수 있습니다.
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs
"&"를 통해 백그라운드에 배치된 작업은 계속 백그라운드에서 실행됩니다. 물론 vim과 같은 대화형 명령의 경우 일시 중지된 실행 상태로 들어갑니다.
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
여기에 표시되는 것은 실행 및 ps 또는 top에 의해 표시되는 R 상태입니다. 이는 대기 대기열의 프로세스도 실행 중이라는 의미는 아닙니다. 이들은 모두 task_running 식별자에 속합니다.
백그라운드에 수동으로 참여하는 또 다른 방법은 Ctrl+Z 키를 누르는 것입니다. 이렇게 하면 실행 중인 프로세스가 백그라운드에 추가될 수 있지만 백그라운드에 추가된 프로세스는 백그라운드에서 일시 중지됩니다.
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
작업 정보를 보면 각 작업 ID 뒤에 "+" 기호가 있고 "-" 또는 기호가 없는 것도 볼 수 있습니다.
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
vim 프로세스 뒤에 더하기 기호가 있는 것으로 나타났습니다. "+"는 작업이 실행 중임을 의미하며 "-"는 다음 작업을 의미합니다. 실행될 예약 클래스에 의해 선택된 작업은 더 이상 세 번째 작업부터 시작으로 표시되지 않습니다. 백그라운드 작업 테이블에서 실행 중 "+"가 없으면 대기 대기열에 있다는 의미이고, "+"가 있으면 실행 중이라는 의미이며, 중지되면 절전 모드에 있다는 의미로 작업 상태로 분석할 수 있습니다. 상태 . 그러나 각 작업에 할당된 시간 조각이 실제로 매우 짧기 때문에 작업 목록의 작업이 항상 이 상태에 있을 것이라고 생각할 수는 없습니다. 다음 작업으로 전환하고 실행하세요. 그러나 실제 프로세스에서는 각 작업의 전환 속도와 시간 조각이 매우 짧기 때문에 작업 목록이 작을 경우 표시되는 순서가 크게 변경되지 않을 수 있습니다.
위 예시에서 다음으로 실행할 작업은 vim인데, 첫 번째 프로세스가 멈춰서 다른 프로세스는 실행되지 않는 걸까요? 분명히 그렇지 않습니다. 실제로 머지않아 다른 두 가지 절전 작업이 완료되었지만 vim은 여전히 중지 상태에 있다는 것을 알게 될 것입니다.
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
이 작업 예제를 통해 커널 일정이 처리되는 방식에 대해 더 깊이 이해하셨나요?
주제로 돌아갑니다. 프로세스를 수동으로 백그라운드에 넣을 수 있으므로 반드시 다시 포그라운드로 가져올 수 있으며, 실행 진행 상황을 확인하기 위해 포그라운드로 이동한 후 백그라운드로 가져오고 싶은 경우에는 방법이 있을 것입니다. Backstage 모드에 추가하려면 CTRL+Z를 사용하지 마세요.
fg, bg 명령은 각각 foreground와 background의 약어입니다. 즉, 포그라운드에 넣는 것과 백그라운드에 넣는 것입니다. 엄밀히 말하면 실행 중인 상태에서 포그라운드와 백그라운드에 넣는 것입니다. 원래 작업이 중지된 상태입니다.
작업 방법도 매우 간단합니다. 명령 바로 뒤에 jobid를 추가하면 됩니다(예: [fg|bg] [%jobid]). jobid를 지정하지 않으면 현재 작업, 즉 "가 있는 작업이 실행됩니다. +' 항목입니다.
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
작업 테이블에서 작업을 직접 제거하려면 disown 명령을 사용하세요. 작업이 끝나는 것이 아니라 작업 테이블만 제거됩니다. 그리고작업 테이블을 제거한 후 작업은 init/systemd 프로세스에 중단되어 터미널과 독립적이 됩니다.
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
9.3 终端和进程的关系
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
9.4 信号
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
9.4.1 需知道的信号
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
9.4.2 SIGHUP
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
9.4.3 僵尸进程和SIGCHLD
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
9.4.4 手动发送信号(kill命令)
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
9.4.5 pkill和killall
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
9.5 fuser和lsof
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
9.5.1 fuser
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
9.5.2 lsof
例如:
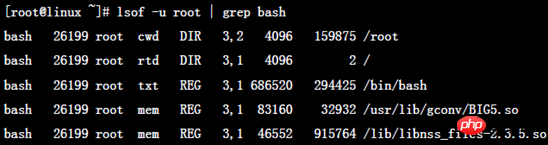
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
转载请注明出处:
위 내용은 리눅스 프로세스와 신호의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!