
집 >운영 및 유지보수 >리눅스 운영 및 유지 관리 >ext 파일 시스템 메커니즘
ext 파일 시스템 메커니즘
- 巴扎黑원래의
- 2017-06-23 14:19:292308검색
이 문서의 디렉터리:
4.1 파일 시스템의 구성 요소
4.2 파일 시스템의 전체 구조
4 .3 데이터 블록
4.4 inode 기본 지식
4.5 Inode 심층
4.6 단일 파일 시스템의 파일 작업 원리
4.7 다중 파일 시스템 연관
4.8 ext3 파일 시스템의 로깅 기능 4.9 ext4 파일 시스템 파티션은 디스크를 열로 나누는 것입니다. 파티션을 분할한 후에는 포맷한 후 마운트해야 사용할 수 있습니다. (다른 방법은 고려하지 않습니다.) 파티션을 포맷하는 과정은 실제로 파일 시스템을 생성하는 것입니다. CentOS 5 및 CentOS 6에서 기본적으로 사용되는 ext2/ext3/ext4, CentOS 7에서 기본적으로 사용되는 xfs, Windows에서는 NTFS, CD형 파일 시스템 ISO9660, MAC에서는 하이브리드 등 다양한 유형의 파일 시스템이 있습니다. 파일 시스템 HFS, 네트워크 파일 시스템 NFS, Oracle이 개발한 btrfs 및 구식 FAT/FAT32 등
이 글에서는 Ext Family 파일 시스템을 매우 포괄적이고 자세하게 소개합니다. ext2/ext3/ext4가 있습니다. ext3은 로그가 포함된 ext2의 향상된 버전입니다. ext4는 ext3에 비해 많은 개선이 이루어졌습니다. xfs/btrfs와 같은 파일 시스템은 다르지만 구현 방법과 고유한 특성만 다릅니다.
4.1 파일 시스템의 구성 요소4.1.1 블록의 출현하드 디스크의 읽기 및 쓰기 IO는 섹터당 512바이트입니다. 섹터 단위는 확실히 매우 느립니다. 따라서 성능을 많이 소모하므로 Linux는 파일 시스템 제어를 통해 "블록"을 읽기 및 쓰기 단위로 사용합니다. 현재 파일 시스템에서 블록 크기는 일반적으로 1024바이트(1K), 2048바이트(2K) 또는 4096바이트(4K)입니다. 예를 들어, 하나 이상의 블록을 읽어야 할 경우 파일 시스템의 IO 관리자는 읽어야 할 데이터 블록을 디스크 컨트롤러에 알립니다. 하드 디스크 컨트롤러는 이러한 블록을 섹터별로 읽은 다음 해당 섹터를 통해 전송합니다. 하드 디스크 컨트롤러. 데이터가 재조립되어 컴퓨터로 반환됩니다.
블록의 출현으로 파일 시스템 수준의 읽기 및 쓰기 성능이 크게 향상되고 조각화도 크게 줄어듭니다. 하지만 공간 낭비를 초래할 수 있다는 부작용이 있습니다. 파일 시스템은 블록을 읽기 및 쓰기 단위로 사용하기 때문에 저장된 파일의 크기가 1K에 불과하더라도 한 블록을 차지하게 되고 나머지 공간은 완전히 낭비된다. 특정 비즈니스 요구에 따라 많은 수의 작은 파일이 저장될 수 있으며 이로 인해 많은 공간이 낭비됩니다.단점도 있지만 장점은 충분히 자명합니다. 저렴한 하드디스크 용량과 성능을 추구하는 현 시대에 블록의 활용은 필수입니다. 4.1.2 inode의 등장
저장된 파일이 읽어야 할 블록 수를 많이 차지하면 어떻게 될까요? 블록 크기가 1KB인 경우 10M 파일을 저장하려면 10240개의 블록이 필요하며 이러한 블록은 위치가 불연속적일 가능성이 높습니다(인접하지 않음). 파일을 읽을 때 전체 블록을 앞에서 뒤로 스캔해야 합니까? 파일 시스템의 내용을 확인한 다음 해당 파일에 어떤 블록이 속하는지 알아내시겠습니까? 당연히 이렇게 하면 안 됩니다. 너무 느리고 바보 같기 때문입니다. 다시 생각해보면, 1블록만 차지하는 파일을 읽으면, 1블록만 읽으면 끝나는 걸까요? 아니요, 언제 스캔되는지 알 수 없고, 스캔 후 파일이 완료되었는지 여부도 알 수 없으며 다른 블록을 스캔할 필요가 없기 때문에 여전히 전체 파일 시스템의 모든 블록을 스캔합니다.또한 각 파일에는 속성(예: 권한, 크기, 타임스탬프 등)이 있습니다. 이러한 속성 클래스의 메타데이터는 어디에 저장되나요? 파일의 데이터 부분도 블록에 저장될 수 있습니까? 파일이 여러 블록을 차지하는 경우 파일에 속한 각 블록에 파일 메타데이터를 저장해야 합니까? 하지만 파일 시스템이 각 블록에 메타데이터를 저장하지 않는다면, 특정 블록이 파일에 속하는지 어떻게 알 수 있을까요? 그러나 분명히 각 데이터 블록에 메타데이터 복사본을 저장하는 것은 공간 낭비입니다.
물론 파일 시스템 설계자는 이 저장 방법이 이상적이지 않다는 것을 알고 있으므로 저장 방법을 최적화해야 합니다. 최적화하는 방법? 이와 유사한 문제에 대한 해결책은 인덱스를 사용하여 인덱스를 스캔하여 해당 데이터를 찾는 것이며, 인덱스는 데이터의 일부를 저장할 수 있습니다.
파일 시스템에서는 인덱싱 기술이 인덱스 노드로 구현됩니다. 인덱스 노드에 저장되는 데이터의 일부는 파일의 속성 메타데이터와 기타 소량의 정보입니다. 일반적으로 인덱스가 차지하는 공간은 인덱스가 생성하는 파일 데이터의 공간보다 훨씬 작습니다. 인덱스를 검색하는 것은 전체 데이터를 검색하는 것보다 훨씬 빠릅니다. 그렇지 않으면 인덱스는 의미가 없습니다. 이것은 이전의 모든 문제를 해결합니다.
파일 시스템 용어로 인덱스 노드를 inode라고 합니다. 아이노드 번호, 파일 유형, 권한, 파일 소유자, 크기, 타임스탬프 등과 같은 메타데이터 정보가 아이노드에 저장됩니다. 가장 중요한 것은 파일을 읽을 때 해당 파일에 속한 블록에 대한 포인터도 저장된다는 것입니다. inode에서 파일에 속한 블록을 찾은 다음 이 블록을 읽고 파일의 데이터를 얻을 수 있습니다. 나중에 일종의 포인터가 도입될 것이기 때문에 명명과 구별의 편의를 위해 당분간은 이 아이노드 레코드에서 파일 데이터 블록을 가리키는 포인터를 블록 포인터라고 부른다.
일반적으로 inode 크기는 128바이트 또는 256바이트로 MB 또는 GB 단위로 계산된 파일 데이터보다 훨씬 작습니다. 그러나 파일 크기가 inode 크기보다 작을 수도 있다는 점도 알아야 합니다. 예를 들면 다음과 같습니다. 섹션 파일은 1개만 차지합니다.
4.1.3 bmap이 나타납니다
하드디스크에 데이터를 저장할 때 파일 시스템은 어떤 블록이 비어 있고 어떤 블록이 채워져 있는지 알아야 합니다. 가장 어리석은 방법은 물론 앞에서 뒤로 스캔하고, 사용 가능한 블록이 발견되면 일부를 저장하고, 모든 데이터가 저장될 때까지 계속 스캔하는 것입니다.
물론 최적화 방법으로 인덱스 사용도 고려할 수 있지만 1G 파일 시스템만 1024*1024=1048576의 총 1KB 블록을 갖습니다. 100G, 500G 또는 그 이상이라면 그냥 사용하세요. 인덱스 인덱스가 차지하는 숫자와 공간도 매우 커집니다. 이때 블록 비트맵(비트맵을 bmap이라고 함)을 사용하는 더 높은 수준의 최적화 방법이 나타납니다.
비트맵은 해당 블록이 비어 있는지 또는 점유되어 있는지 식별하기 위해 0과 1만 사용합니다. 비트맵의 0과 1 위치는 첫 번째 블록을 식별하고 두 번째 비트는 식별합니다. 두 블록, 모든 블록이 표시될 때까지 순서대로 진행합니다.
블록 비트맵이 더 최적화된 이유를 생각해 보세요. 비트맵에는 1바이트에 8비트가 있어 8개의 블록을 식별할 수 있습니다. 블록 크기가 1KB이고 용량이 1G인 파일 시스템의 경우 블록 개수는 1024*1024이므로 비트맵에서는 1024*1024비트가 사용되어 총 1024*1024/8=131072바이트=128K가 되며, 이는 1G입니다. 파일에는 일대일 대응을 완료하기 위해 비트맵으로 128개의 블록만 필요합니다. 100개 이상의 블록을 스캔하면 어떤 블록이 비어 있는지 알 수 있으며 속도가 크게 향상됩니다.
하지만 bmap의 최적화는 쓰기 최적화를 목표로 한다는 점에 유의하세요. 쓰기에만 여유 블록을 찾아 여유 블록을 할당하면 되기 때문입니다. 읽기의 경우, 아이노드를 통해 블록의 위치를 알아내기만 하면 CPU는 물리 디스크의 블록 주소를 빠르게 계산할 수 있다. 블록 주소를 계산하는 시간은 매우 빠르다. 거의 무시할 수 있을 정도이므로 읽기 속도는 기본적으로 하드디스크 자체의 성능에 영향을 받을 뿐 파일 시스템과는 관련이 없다고 생각됩니다.
bmap은 검색을 크게 최적화했지만 여전히 병목 현상이 있습니다. 파일 시스템이 100G라면 어떻게 될까요? 100G 파일 시스템은 128*100=12800개의 1KB 블록을 사용하며, 이는 12.5M의 공간을 차지합니다. 불연속 가능성이 있는 12,800개의 블록을 완전히 스캔하는 데 시간이 좀 걸릴 것이라고 상상해 보십시오. 속도는 빠르지만 파일이 저장될 때마다 스캔하는 막대한 오버헤드를 감당할 수는 없습니다.
그러면 어떻게 다시 최적화해야 할까요? 즉, 파일 시스템은 블록 그룹으로 나누어집니다. 블록 그룹에 대한 소개는 나중에 설명하겠습니다.
4.1.4 inode 테이블의 출현
inode 관련 정보를 검토합니다. inode는 inode 번호, 파일 속성 메타데이터 및 파일이 차지하는 블록에 대한 포인터를 저장하며 각 inode는 128바이트 또는 256바이트를 차지합니다.
이제 또 다른 문제가 발생합니다. 파일 시스템에는 수많은 파일이 있을 수 있으며 각 파일은 128바이트의 각 inode를 저장하기 위해 별도의 블록을 차지해야 합니까? 이것은 정말 공간 낭비입니다.
따라서 더 좋은 방법은 여러 개의 inode를 결합하여 블록에 저장하는 것입니다. 128바이트 inode의 경우 한 블록은 256바이트 inode의 경우 4개의 inode를 저장합니다. 이렇게 하면 inode를 저장하는 각 블록이 낭비되지 않습니다.
ext 파일 시스템에서는 inode를 물리적으로 저장하는 이러한 블록을 결합하여 논리적으로 inode 테이블을 구성하여 모든 inode를 기록합니다.
예를 들어, 모든 가족은 경찰서에 세대 등록 정보를 등록해야 합니다. 세대 주소는 세대 등록을 통해 알 수 있습니다. 각 마을이나 거리의 경찰서는 해당 동네나 거리의 모든 세대 등록을 통합합니다. 세대 주소를 입력하시면 경찰서에서 빠르게 찾으실 수 있습니다. inode 테이블은 여기 경찰서입니다. 그 내용은 아래와 같습니다.
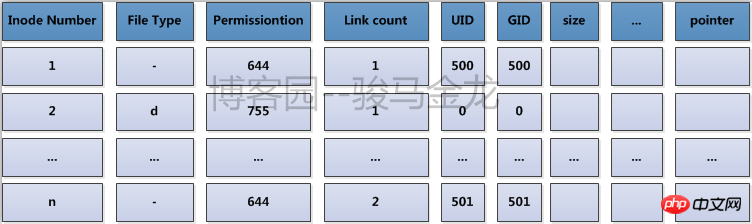
실제로 파일 시스템이 생성된 후에는 모든 inode 번호가 할당되어 inode 테이블에 기록되는데, 사용된 inode 번호가 위치한 행에도 파일 속성의 메타데이터 정보와 블록이 포함됩니다. 위치 정보, 미사용 inode 번호에는 inode 번호만 있고 다른 정보는 없습니다.
좀 더 자세히 생각해 보면, 큰 파일 시스템이 inode를 저장하기 위해 여전히 많은 블록을 차지한다는 것을 알 수 있습니다. 또한 inode 레코드 중 하나를 찾으려면 많은 오버헤드가 필요합니다. 논리적 테이블이 너무 크고 레코드가 너무 많습니다. 따라서 inode를 빠르게 찾는 방법도 최적화해야 합니다. 최적화 방법은 파일 시스템의 블록을 그룹으로 나누는 것입니다. 각 그룹에는 그룹의 inode 테이블 범위, bmap 등이 포함됩니다.
4.1.5 imap의 출현
앞서 언급했듯이 bmap은 파일 시스템에서 어떤 블록이 비어 있고 어떤 블록이 점유되어 있는지 식별하는 데 사용되는 블록 비트맵입니다.
inode도 마찬가지입니다. 파일을 저장할 때(Linux에서는 모든 것이 파일입니다) inode 번호를 할당해야 합니다. 그러나 파일 시스템을 포맷하고 생성한 후에는 모든 inode 번호가 사전 설정되어 inode 테이블에 저장되므로 다음과 같은 질문이 생깁니다. 파일에 어떤 inode 번호를 할당해야 합니까? 특정 inode 번호가 할당되었는지 어떻게 알 수 있나요?
"점유 여부"에 대한 질문이므로 bmap이 블록의 점유를 기록하는 것처럼 비트맵을 사용하는 것이 가장 좋은 솔루션입니다. inode 번호가 할당되었는지 식별하는 비트맵을 inodemap 또는 줄여서 imap이라고 합니다. 이때, 파일에 inode 번호를 할당하려면 imap을 스캔하여 어떤 inode 번호가 비어 있는지 알아보세요.
imap에는 bmap 및 inode 테이블처럼 해결해야 할 동일한 문제가 있습니다. 파일 시스템이 상대적으로 크면 imap 자체도 매우 커지며 파일이 저장될 때마다 스캔해야 하므로 다음과 같은 문제가 발생합니다. 효율성이 부족합니다. 마찬가지로 최적화 방법은 파일 시스템이 차지하는 블록을 블록 그룹으로 나누는 것이며, 각 블록 그룹은 자체 imap 범위를 갖습니다.
4.1.6 블록 그룹의 출현
위에서 언급한 최적화 방법은 파일 시스템이 차지하는 블록을 블록 그룹으로 나누어 너무 큰 bmap, inode 테이블 및 imap 문제를 해결하는 것입니다.
물리적 수준에서의 분할은 디스크를 실린더를 기준으로 여러 파티션, 즉 여러 파일 시스템으로 나누는 것입니다. 논리적 수준에서의 분할은 파일 시스템을 블록 그룹으로 나누는 것입니다. 각 파일 시스템에는 여러 블록 그룹이 포함되어 있으며 각 블록 그룹에는 여러 메타데이터 영역과 데이터 영역이 포함되어 있습니다. 메타데이터 영역은 bmap, inode 테이블, imap 등이 저장되는 영역입니다. . 블록 그룹은 논리적 개념이므로 실제로 디스크의 열, 섹터, 트랙 등으로 구분되지 않습니다.
4.1.7 블록 그룹 분할
블록 그룹은 파일 시스템이 생성된 후 분할되었습니다. 즉, 메타데이터 영역 bmap, inode 테이블, imap 및 기타 정보가 차지하는 블록과 데이터가 차지하는 블록을 의미합니다. 영역이 나뉘어져 있어요. 그렇다면 파일 시스템은 블록 메타데이터 영역에 포함된 블록 수와 데이터 영역에 포함된 블록 수를 어떻게 알 수 있습니까?
단 하나의 데이터, 즉 각 블록의 크기만 결정한 다음 bmap이 최대 하나의 완전한 블록만 차지할 수 있다는 기준에 따라 블록 그룹을 분할하는 방법을 계산하면 됩니다. 파일 시스템이 매우 작고 모든 bmap이 총 하나의 블록을 차지할 수 없는 경우 bmap 블록은 해제만 가능합니다.
각 블록의 크기는 파일 시스템을 생성할 때 수동으로 지정할 수 있습니다. 지정하지 않은 경우 기본값도 있습니다.
현재 블록 크기가 1KB라면 한 블록을 완전히 차지하는 bmap은 1024*8= 8192개의 블록을 식별할 수 있습니다. (물론 이 8192개의 블록은 메타데이터에 할당된 블록이 있기 때문에 총 8192개의 데이터 영역과 메타데이터 영역입니다. 영역도 bmap으로 식별해야 합니다. 각 블록은 1K이고 각 블록 그룹은 8192K 또는 8M입니다. 1G 파일 시스템을 만들려면 1024/8 = 128개의 블록 그룹을 나누어야 합니다. 1.1G 파일 시스템이라면 어떨까요? 128+12.8=128+13=141개의 블록 그룹.
그룹별로 블록 개수가 나누어져 있는데, 그룹별로 inode 개수는 몇 개로 설정되어 있나요? inode 테이블은 몇 블록을 차지합니까? "데이터 영역에 inode 번호가 할당된 블록 수"를 설명하는 표시기는 기본적으로 우리에게 알려져 있지 않기 때문에 이는 시스템에서 결정해야 합니다. 물론 이 표시기 또는 백분율은 파일을 생성할 때 수동으로 지정할 수도 있습니다. 체계. 아래의 "inode 깊이"를 참조하십시오.
ext 클래스의 모든 파일 시스템 정보를 표시하려면 dumpe2fs를 사용하십시오. 물론 bmap은 각 블록 그룹에 대해 하나의 블록을 수정하므로 표시할 필요가 없습니다. 따라서 1블록만 차지하며 표시되지 않습니다. 표시해야 합니다.
아래 그림은 파일 시스템 정보의 일부를 보여줍니다. 이 정보 뒤에는 각 블록 그룹의 정보가 있습니다.
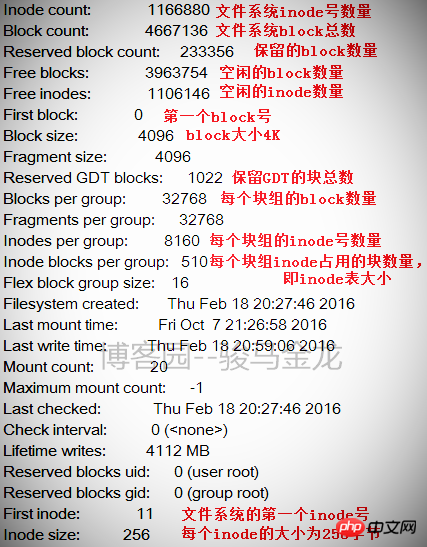
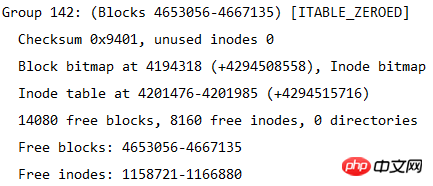
이 표에서 파일 시스템의 크기를 계산할 수 있습니다. 파일 시스템에는 총 4667136개의 블록이 있고 각 블록 크기는 4K이므로 파일 시스템 크기는 4667136*4/1024/1024=17.8입니다. GB.
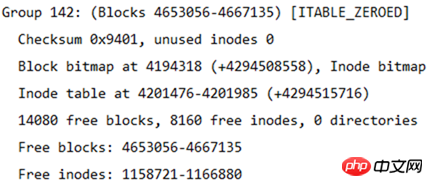
각 블록 그룹의 블록 수가 32768이므로 블록 그룹이 몇 개로 나누어져 있는지 계산할 수도 있으므로 블록 그룹 수는 4667136/32768=142.4, 즉 143개의 블록 그룹입니다. 블록 그룹 번호는 0부터 시작하므로 마지막 블록 그룹 번호는 그룹 142입니다. 아래 그림과 같이 마지막 블록 그룹의 정보가 나와 있습니다.
4.2 파일 시스템의 전체 구조
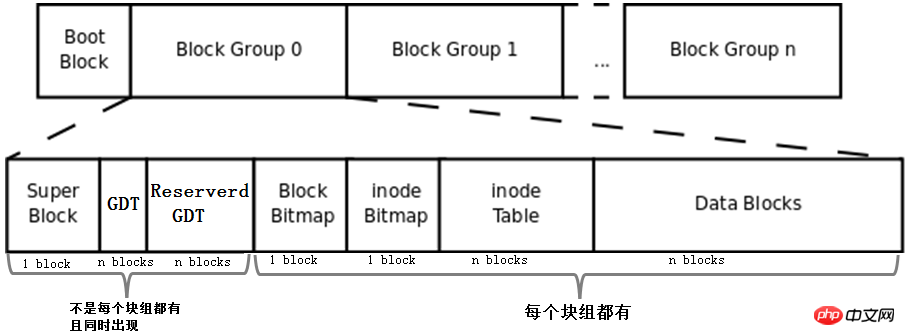
위에서 설명한 bmap, inode 테이블, imap, 데이터 영역 블록 및 블록 그룹의 개념을 결합하여 파일 시스템을 구성하는 것은 아직 완성되지 않았습니다. 파일 시스템. 전체 파일 시스템은 아래와 같습니다.
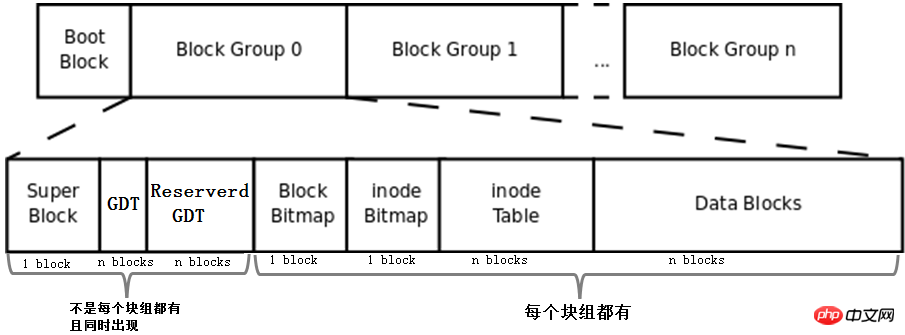
먼저 이 사진에는 Boot Block, Super Block, GDT, Reserve GDT의 개념이 추가되어 있습니다. 아래에서 별도로 소개하겠습니다.
그러면 그림은 블록 그룹의 각 부분이 차지하는 블록 수를 나타냅니다. 1블록을 차지한다고 판단할 수 있는 superblock, bmap, imap을 제외하고 다른 부분은 여러 블록을 차지한다고 판단할 수 없습니다.
마지막으로 그림은 Superblock, GDT 및 Reserved GDT가 동시에 나타나며 각 블록 그룹에 반드시 존재하지는 않는다는 것을 나타냅니다. 또한 각 블록 그룹에는 bmap, imap, inode 테이블 및 데이터 블록이 존재함을 나타냅니다.
4.2.1 부트 블록
은 위 그림의 부트 블록 부분으로 부트 섹터라고도 합니다. 이는 파티션의 첫 번째 블록에 위치하며 1024바이트를 차지합니다. 모든 파티션에 이 부트 섹터가 있는 것은 아닙니다. 부트 로더도 여기에 저장됩니다. 이 부트 로더는 VBR이 됩니다. 여기의 부트 로더와 MBR의 부트 로더 사이에는 엇갈린 관계가 있습니다. 부팅할 때 먼저 MBR에 부트로더를 로드한 다음 운영 체제가 있는 파티션의 부트 서버를 찾아서 여기에서 부트로더를 로드합니다. 여러 시스템이 있는 경우 mbr에 부트로더를 로드한 후 운영 체제 메뉴가 나열되고 메뉴의 각 운영 체제는 자신이 위치한 파티션의 부팅 섹터를 가리킵니다. 이들 사이의 관계는 아래 그림에 나와 있습니다.
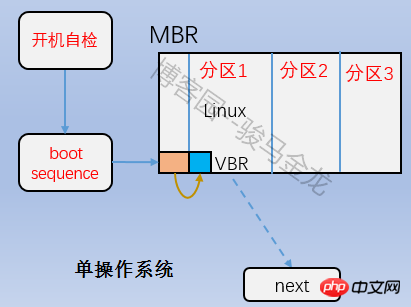
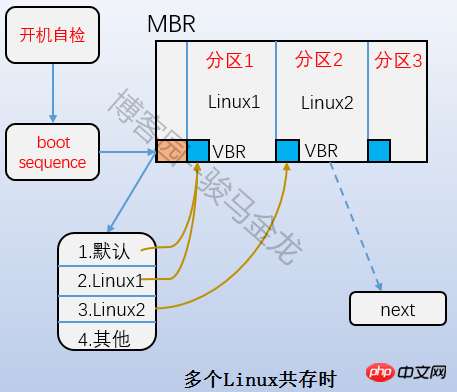
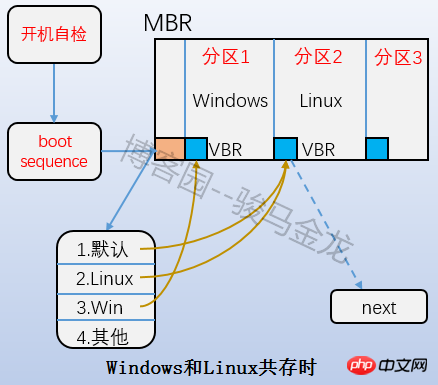
4.2.2 Superblock
파일 시스템이 여러 개의 블록 그룹으로 나누어져 있는데, 파일 시스템은 자신이 몇 개의 블록 그룹으로 나누어져 있는지 어떻게 알 수 있나요? 각 블록 그룹에는 블록 수, inode 번호 및 기타 정보가 몇 개 있습니까? 또한 다양한 타임스탬프, 총 블록 수 및 사용 가능한 블록 수, 총 블록 수 및 사용 가능한 inode 수 등 파일 시스템 자체의 속성 정보, 현재 파일 시스템이 정상인지 여부, 자체 검사 시 테스트가 필요한 경우 등은 어디에 저장됩니까?
이 정보가 블록에 저장되어야 한다는 것은 의심의 여지가 없습니다. 이 정보를 저장하는 데에는 1024KB가 필요하므로 블록도 필요합니다. 이 블록을 슈퍼블록이라고 하며 블록 번호는 0 또는 1이 될 수 있습니다. 블록 크기가 1024K이면 부트 블록은 정확히 한 블록을 차지합니다. 이 블록 번호는 0이므로 블록 크기가 1024K보다 크면 부트 블록과 슈퍼 블록이 같은 위치에 있습니다. 동일한 블록입니다. 이 블록 번호는 0입니다. 즉, 슈퍼블록의 시작과 끝 위치는 두 번째 1024(1024-2047)바이트이다.
df 명령을 사용하여 각 파일 시스템의 슈퍼블록을 읽으므로 통계가 매우 빠릅니다. 반대로, 더 큰 디렉토리의 사용된 공간을 보기 위해 du 명령을 사용하는 것은 전체 디렉토리의 모든 파일을 순회하는 것이 불가피하기 때문에 매우 느립니다.
[root@xuexi ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on/dev/sda3 ext4 18G 1.7G 15G 11% /tmpfs tmpfs 491M 0 491M 0% /dev/shm/dev/sda1 ext4 190M 32M 149M 18% /boot
슈퍼블록은 파일 시스템에 매우 중요합니다. 슈퍼블록이 손실되거나 손상되면 파일 시스템이 손상될 수 있습니다. 따라서 기존 파일 시스템은 슈퍼 블록을 블록 그룹별로 백업하지만 이는 공간 낭비이므로 ext2 파일 시스템은 블록 그룹 0, 1과 3, 5, 7 파워 블록 그룹의 블록 정보에만 슈퍼 블록을 저장한다. , Group9, Group25 등과 같은 이렇게 많은 슈퍼블록이 저장되어 있지만 파일 시스템은 첫 번째 블록 그룹인 Group0의 슈퍼블록 정보만 사용하여 파일 시스템 속성을 얻습니다. Group0의 슈퍼블록이 손상되거나 손실된 경우에만 다음 백업 슈퍼블록을 찾아 복사합니다. Group0. 파일 시스템을 복원합니다.
아래 그림은 ext4 파일 시스템의 슈퍼블록 정보를 보여줍니다. 모든 ext 제품군 파일 시스템은 dumpe2fs -h를 사용하여 얻을 수 있습니다.

4.2.3 블록 그룹 설명자 테이블(GDT)
파일 시스템이 블록 그룹으로 나누어져 있는데, 각 블록 그룹의 정보와 속성 메타데이터는 어디에 저장되나요?
ext 파일 시스템의 각 블록 그룹 정보는 32바이트를 사용하여 설명됩니다. 이 32바이트를 블록 그룹 설명자라고 합니다. 모든 블록 그룹의 블록 그룹 설명자는 블록 그룹 설명자 테이블 GDT(그룹 설명자 테이블)를 형성합니다.
블록 그룹의 정보와 속성 메타데이터를 기록하려면 각 블록 그룹에 블록 그룹 설명자가 필요하지만 모든 블록 그룹이 블록 그룹 설명자를 저장하는 것은 아닙니다. ext 파일 시스템의 저장 방법은 GDT를 구성하여 특정 블록 그룹에 GDT를 저장하는 것입니다. GDT를 저장하는 블록 그룹은 슈퍼 블록과 백업 슈퍼 블록을 저장하는 블록과 동일합니다. 블록 그룹의 특정 블록 그룹.
블록 크기가 4KB인 파일 시스템을 143개의 블록 그룹으로 나누고 각 블록 그룹 설명자가 32바이트라면 GDT는 143*32=4576바이트, 즉 두 개의 블록을 저장해야 합니다. 이 두 개의 GDT 블록에는 모든 블록 그룹의 블록 그룹 정보가 기록되며, GDT를 저장하는 블록 그룹의 GDT는 완전히 동일합니다.
아래 그림은 블록 그룹 설명자(dumpe2fs를 통해 얻은) 정보를 보여줍니다.
4.2.4 예약된 GDT(예약된 GDT)
확장 후 블록 그룹이 너무 많아 블록 그룹 설명자가 현재 GDT를 저장하는 블록을 초과하는 것을 방지하기 위해 향후 파일 시스템 확장을 위해 예약된 GDT입니다. GDT와 GDT는 항상 동시에 나타나며, 물론 슈퍼블록으로도 동시에 나타납니다.
예를 들어 첫 번째 143개 블록 그룹은 2개의 블록을 사용하여 GDT를 저장하지만 이때 두 번째 블록에는 여전히 여유 공간이 많이 남아 있어 용량이 어느 정도 확장되면 2개의 블록은 더 이상 GDT를 기록할 수 없습니다. 블록 그룹 설명자 이 때 초과된 블록 그룹 설명자를 저장하려면 하나 이상의 예약된 GDT 블록을 할당해야 합니다.
새로 추가된 GDT 블록으로 인해 이 GDT 블록은 GDT를 저장하는 각 블록 그룹에 동시에 추가되어야 합니다. 따라서 예약된 GDT와 GDT가 동일한 블록 그룹에 저장되면 예약된 GDT를 직접 사용할 수 있습니다. 필요없이 GDT로 변환하여 GDT가 저장된 각 블록 그룹을 백업하는 비효율적인 복사 방법을 사용합니다.
마찬가지로 새로 추가된 GDT는 각 블록 그룹의 슈퍼블록에 있는 파일 시스템 속성을 수정해야 하므로 슈퍼블록과 예약된 GDT/GDT를 함께 사용하면 효율성을 높일 수 있습니다.
4.3 Data Block
위 그림과 같이 Data Block을 제외한 다른 부분에 대해 설명하였습니다. 데이터 블록은 데이터를 직접 저장하는 블록이지만 실제로는 그렇게 간단하지 않습니다.
데이터가 차지하는 블록은 파일에 해당하는 inode 레코드의 블록 포인터로 찾습니다. 파일 유형에 따라 데이터 블록에 저장된 내용이 다릅니다. Linux에서 다양한 유형의 파일이 저장되는 방법은 다음과 같습니다.
일반 파일의 경우 파일의 데이터가 데이터 블록에 정상적으로 저장됩니다.
디렉터리의 경우 모든 파일의 디렉터리 이름과 해당 디렉터리 아래의 첫 번째 수준 하위 디렉터리가 데이터 블록에 저장됩니다.
파일 이름은 자체 inode에 저장되지 않고 해당 파일이 위치한 디렉터리의 데이터 블록에 저장됩니다.
심볼릭 링크의 경우 대상 경로 이름이 더 짧으면 더 빠른 조회를 위해 inode에 직접 저장됩니다. 대상 경로 이름이 더 길면 이를 저장하기 위해 데이터 블록이 할당됩니다.
장치 파일, FIFO 및 소켓과 같은 특수 파일에는 데이터 블록이 없습니다. 장치 파일의 메이저 장치 번호와 마이너 장치 번호는 inode에 저장됩니다.
일반 파일의 저장 방법은 아래에서 설명하지 않습니다.
4.3.1 디렉터리 파일의 데이터 블록
디렉터리 파일의 경우 inode 레코드에는 디렉터리의 inode 번호, 디렉터리의 속성 메타데이터, 디렉터리 파일의 블록 포인터가 저장됩니다. 디렉토리 자체의 이름입니다.
데이터 블록의 저장 방법은 아래 그림과 같습니다.
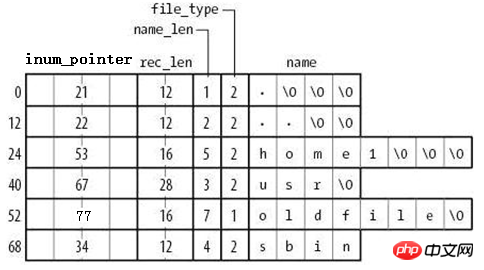
由图可知,在目录文件的数据块中存储了其下的文件名、目录名、目录本身的相对名称"."和上级目录的相对名称"..",还存储了指向inode table中这些文件名对应的inode号的指针(并非直接存储inode号码)、目录项长度rec_len、文件名长度name_len和文件类型file_type。注意到除了文件本身的inode记录了文件类型,其所在的目录的数据块也记录了文件类型。由于rec_len只能是4的倍数,所以需要使用"\0"来填充name_len不够凑满4倍数的部分。至于rec_len具体是什么,只需知道它是一种偏移即可。
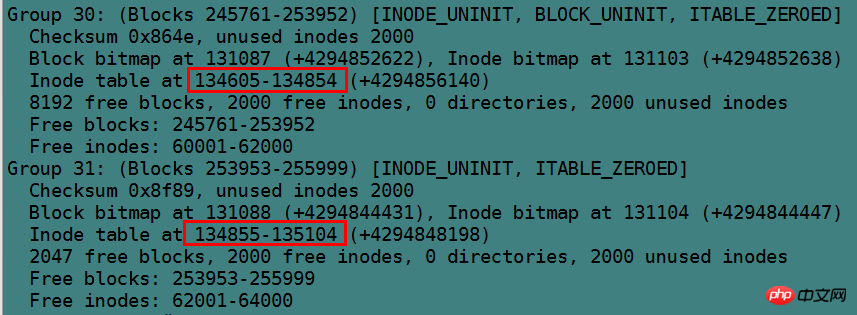
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针,暂且称之为inode指针(至此,已经知道了两种指针:一种是inode table中每个inode记录指向其对应data block的block指针,一个此处的inode指针)。一个很有说服力的例子,在目录只有读而没有执行权限的时候,使用"ls -l"是无法获取到其内文件inode号的,这就表明没有直接存储inode号。实际上,因为在创建文件系统的时候,inode号就已经全部划分好并在每个块组的inode table中存放好,inode table在块组中是有具体位置的,如果使用dumpe2fs查看文件系统,会发现每个块组的inode table占用的block数量是完全相同的,如下图是某分区上其中两个块组的信息,它们都占用249个block。
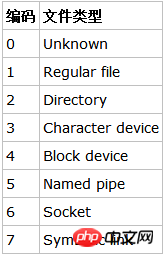
除了inode指针,目录的data block中还使用数字格式记录了文件类型,数字格式和文件类型的对应关系如下图。
注意到目录的data block中前两行存储的是目录本身的相对名称"."和上级目录的相对名称"..",它们实际上是目录本身的硬链接和上级目录的硬链接。硬链接的本质后面说明。
由此也就容易理解目录权限的特殊之处了。目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。以下是没有目录x权限时的查询状态,可以看到除了文件名和文件类型,其余的全是"?"。
[lisi4@xuexi tmp]$ ll -i d ls: cannot access d/hehe: Permission denied ls: cannot access d/haha: Permission denied total 0? d????????? ? ? ? ? ? haha? -????????? ? ? ? ? ? hehe
注意,xfs文件系统和ext文件系统不一样,它连文件类型都无法获取。
4.3.2 符号链接存储方式
符号链接即为软链接,类似于Windows操作系统中的快捷方式,它的作用是指向原文件或目录。
软链接之所以也被称为特殊文件的原因是:它一般情况下不占用data block,仅仅通过它对应的inode记录就能将其信息描述完成;符号链接的大小是其指向目标路径占用的字符个数,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",则其文件大小为11字节;只有当符号链接指向的目标的路径名较长(60个字节)时文件系统才会划分一个data block给它;它的权限如何也不重要,因它只是一个指向原文件的"工具",最终决定是否能读写执行的权限由原文件决定,所以很可能ls -l查看到的符号链接权限为777。
注意,软链接的block指针存储的是目标文件名。也就是说,链接文件的一切都依赖于其目标文件名。这就解释了为什么/mnt的软链接/tmp/mnt在/mnt挂载文件系统后,通过软链接就能进入/mnt所挂载的文件系统。究其原因,还是因为其目标文件名"/mnt"并没有改变。
例如以下筛选出了/etc/下的符号链接,注意观察它们的权限和它们占用的空间大小。
[root@xuexi ~]# ll /etc/ | grep '^l'lrwxrwxrwx. 1 root root 56 Feb 18 2016 favicon.png -> /usr/share/icons/hicolor/16x16/apps/system-logo-icon.png lrwxrwxrwx. 1 root root 22 Feb 18 2016 grub.conf -> ../boot/grub/grub.conf lrwxrwxrwx. 1 root root 11 Feb 18 2016 init.d -> rc.d/init.d lrwxrwxrwx. 1 root root 7 Feb 18 2016 rc -> rc.d/rc lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc0.d -> rc.d/rc0.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc1.d -> rc.d/rc1.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc2.d -> rc.d/rc2.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc3.d -> rc.d/rc3.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc4.d -> rc.d/rc4.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc5.d -> rc.d/rc5.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc6.d -> rc.d/rc6.d lrwxrwxrwx. 1 root root 13 Feb 18 2016 rc.local -> rc.d/rc.local lrwxrwxrwx. 1 root root 15 Feb 18 2016 rc.sysinit -> rc.d/rc.sysinit lrwxrwxrwx. 1 root root 14 Feb 18 2016 redhat-release -> centos-release lrwxrwxrwx. 1 root root 11 Apr 10 2016 rmt -> ../sbin/rmt lrwxrwxrwx. 1 root root 14 Feb 18 2016 system-release -> centos-release
4.3.3 设备文件、FIFO、套接字文件
关于这3种文件类型的文件只需要通过inode就能完全保存它们的信息,它们不占用任何数据块,所以它们是特殊文件。
设备文件的主设备号和次设备号也保存在inode中。以下是/dev/下的部分设备信息。注意到它们的第5列和第6列信息,它们分别是主设备号和次设备号,主设备号标识每一种设备的类型,次设备号标识同种设备类型的不同编号;也注意到这些信息中没有大小的信息,因为设备文件不占用数据块所以没有大小的概念。
[root@xuexi ~]# ll /dev | tailcrw-rw---- 1 vcsa tty 7, 129 Oct 7 21:26 vcsa1 crw-rw---- 1 vcsa tty 7, 130 Oct 7 21:27 vcsa2 crw-rw---- 1 vcsa tty 7, 131 Oct 7 21:27 vcsa3 crw-rw---- 1 vcsa tty 7, 132 Oct 7 21:27 vcsa4 crw-rw---- 1 vcsa tty 7, 133 Oct 7 21:27 vcsa5 crw-rw---- 1 vcsa tty 7, 134 Oct 7 21:27 vcsa6 crw-rw---- 1 root root 10, 63 Oct 7 21:26 vga_arbiter crw------- 1 root root 10, 57 Oct 7 21:26 vmci crw-rw-rw- 1 root root 10, 56 Oct 7 21:27 vsock crw-rw-rw- 1 root root 1, 5 Oct 7 21:26 zero
4.4 inode基础知识
每个文件都有一个inode,在将inode关联到文件后系统将通过inode号来识别文件,而不是文件名。并且访问文件时将先找到inode,通过inode中记录的block位置找到该文件。
4.4.1 硬链接
虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为"硬链接"。
硬链接文件的inode都相同,每个文件都有一个"硬链接数"的属性,使用ls -l的第二列就是被硬链接数,它表示的就是该文件有几个硬链接。
[root@xuexi ~]# ls -l total 48drwxr-xr-x 5 root root 4096 Oct 15 18:07 700-rw-------. 1 root root 1082 Feb 18 2016 anaconda-ks.cfg-rw-r--r-- 1 root root 399 Apr 29 2016 Identity.pub-rw-r--r--. 1 root root 21783 Feb 18 2016 install.log-rw-r--r--. 1 root root 6240 Feb 18 2016 install.log.syslog
例如下图描述的是dir1目录中的文件name1及其硬链接dir2/name2,右边分别是它们的inode和datablock。这里也看出了硬链接文件之间唯一不同的就是其所在目录中的记录不同。注意下图中有一列Link Count就是标记硬链接数的属性。

每创建一个文件的硬链接,实质上是多一个指向该inode记录的inode指针,并且硬链接数加1。
删除文件的实质是删除该文件所在目录data block中的对应的inode指针,所以也是减少硬链接次数,由于block指针是存储在inode中的,所以不是真的删除数据,如果仍有其他指针指向该inode,那么该文件的block指针仍然是可用的。当硬链接次数为1时再删除文件就是真的删除文件了,此时inode记录中block指针也将被删除。
不能跨分区创建硬链接,因为不同文件系统的inode号可能会相同,如果允许创建硬链接,复制到另一个分区时inode可能会和此分区已使用的inode号冲突。
硬链接只能对文件创建,无法对目录创建硬链接。之所以无法对目录创建硬链接,是因为文件系统已经把每个目录的硬链接创建好了,它们就是相对路径中的"."和"..",分别标识当前目录的硬链接和上级目录的硬链接。每一个目录中都会包含这两个硬链接,它包含了两个信息:(1)一个没有子目录的目录文件的硬链接数是2,其一是目录本身,其二是".";(2)一个包含子目录的目录文件,其硬链接数是2+子目录数,因为每个子目录都关联一个父目录的硬链接".."。很多人在计算目录的硬链接数时认为由于包含了"."和"..",所以空目录的硬链接数是2,这是错误的,因为".."不是本目录的硬链接。另外,还有一个特殊的目录应该纳入考虑,即"/"目录,它自身是一个文件系统的入口,是自引用(下文中会解释自引用)的,所以"/"目录下的"."和".."的inode号相同,硬链接数除去其内的子目录后应该为3,但结果是2,不知为何?
[root@xuexi ~]# ln /tmp /mydataln: `/tmp': hard link not allowed for directory
为什么文件系统自己创建好了目录的硬链接就不允许人为创建呢?从"."和".."的用法上考虑,如果当前目录为/usr,我们可以使用"./local"来表示/usr/local,但是如果我们人为创建了/usr目录的硬链接/tmp/husr,难道我们也要使用"/tmp/husr/local"来表示/usr/local吗?这其实已经是软链接的作用了。若要将其认为是硬链接的功能,这必将导致硬链接维护的混乱。
不过,通过mount工具的"--bind"选项,可以将一个目录挂载到另一个目录下,实现伪"硬链接",它们的内容和inode号是完全相同的。
硬链接的创建方法:ln file_target link_name。
4.4.2 软链接
软链接就是字符链接,链接文件默认指的就是字符文件,使用"l"表示其类型。
软链接在功能上等价与Windows系统中的快捷方式,它指向原文件,原文件损坏或消失,软链接文件就损坏。可以认为软链接inode记录中的指针内容是目标路径的字符串。
创建方式:ln –s file_target softlink_name
查看软链接的值:readlink softlink_name
在设置软链接的时候,target虽然不要求是绝对路径,但建议给绝对路径。是否还记得软链接文件的大小?它是根据软链接所指向路径的字符数计算的,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",它的文件大小为11字节,也就是说只要建立了软链接后,软链接的指向路径是不会改变的,仍然是"../sbin/rmt"。如果此时移动软链接文件本身,它的指向是不会改变的,仍然是11个字符的"../sbin/rmt",但此时该软链接父目录下可能根本就不存在/sbin/rmt,也就是说此时该软链接是一个被破坏的软链接。
4.5 inode深入
4.5.1 inode大小和划分
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[root@xuexi ~]# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
enable_periodic_fsck = 1blocksize = 4096inode_size = 256inode_ratio = 16384[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256}同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inodesize、inode分配比例、blocksize都可以在创建文件系统的时候人为指定。
4.5.2 ext文件系统预留的inode号
Ext预留了一些inode做特殊特性使用,如下:某些可能并非总是准确,具体的inode号对应什么文件可以使用"find / -inum NUM"查看。
Ext4的特殊inode
Inode号 用途
0 不存在0号inode
1 虚拟文件系统,如/proc和/sys
2 根目录
3 ACL索引
4 ACL数据
5 Boot loader
6 未删除的目录
7 预留的块组描述符inode
8 日志inode
11 第一个非预留的inode,通常是lost+found目录
所以在ext4文件系统的dumpe2fs信息中,能观察到fisrt inode号可能为11也可能为12。
并且注意到"/"的inode号为2,这个特性在文件访问时会用上。
需要注意的是,每个文件系统都会分配自己的inode号,不同文件系统之间是可能会出现使用相同inode号文件的。例如:
[root@xuexi ~]# find / -ignore_readdir_race -inum 2 -ls 2 4 dr-xr-xr-x 22 root root 4096 Jun 9 09:56 / 2 2 dr-xr-xr-x 5 root root 1024 Feb 25 11:53 /boot 2 0 c--------- 1 root root Jun 7 02:13 /dev/pts/ptmx 2 0 -rw-r--r-- 1 root root 0 Jun 6 18:13 /proc/sys/fs/binfmt_misc/status 2 0 drwxr-xr-x 3 root root 0 Jun 6 18:13 /sys/fs
결과에서 알 수 있듯이 루트 Inode 번호 2 외에도 inode 번호 2를 가진 여러 파일도 있습니다. 이들은 모두 독립 파일 시스템에 속하며 일부는 /proc 및 /sys와 같은 가상 파일 시스템입니다. .
4.5.3 ext2/3 inode의 직접 및 간접 주소 지정
앞서 언급한 것처럼 블록 포인터는 inode에 저장되지만 inode 레코드에 저장할 수 있는 포인터 수는 제한되어 있습니다. inode 크기(128바이트 또는 256바이트).
ext2 및 ext3 파일 시스템에서는 inode에 최대 15개의 포인터만 있을 수 있으며 각 포인터는 i_block[n]으로 표시됩니다.
i_block[0]부터 i_block[11]까지 처음 12개의 포인터는 직접 주소 지정 포인터이며, 각 포인터는 데이터 영역의 블록을 가리킵니다. 아래 그림과 같습니다.
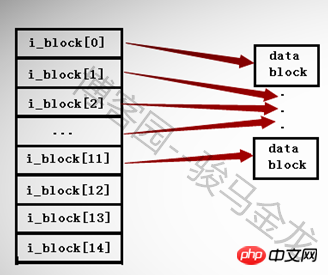
13번째 포인터 i_block[12]는 1레벨 간접 주소 지정 포인터로 여전히 포인터를 저장하고 있는 블록, 즉 i_block[13] --> Pointerblock --> datablock을 가리킨다.
14번째 포인터 i_block[13]은 보조 간접 주소 지정 포인터입니다. 여전히 포인터를 저장하고 있는 블록을 가리키지만 이 블록의 포인터는 계속해서 포인터를 저장하는 다른 블록, 즉 i_block[13]을 가리킵니다. - > 포인터블록1 -->
15번째 포인터 i_block[14]는 세 번째 수준의 간접 주소 지정 포인터입니다. 이 포인터 블록 아래에는 포인터가 두 개 있습니다. 즉, i_block[13] --> Pointerblock1 --> PointerBlock2 --> datablock입니다.
각 포인터의 크기가 4바이트이므로 각 포인터 블록이 저장할 수 있는 포인터 수는 BlockSize/4byte입니다. 예를 들어 블록 크기가 4KB인 경우 블록은 4096/4=1024 포인터를 저장할 수 있습니다.
아래와 같습니다.
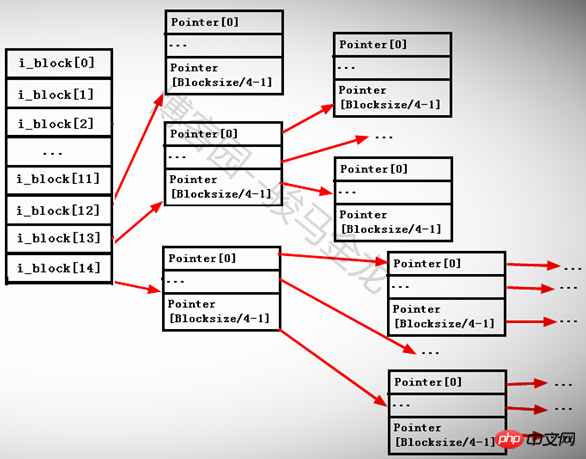
간접 포인터와 직접 포인터를 나누는 이유는 무엇인가요? inode의 15개 포인터가 모두 직접 포인터이고 각 블록의 크기가 1KB인 경우 15개 포인터는 15KB의 블록만 가리킬 수 있습니다. 각 파일은 inode 번호에 해당하므로 이는 제한됩니다. 각 블록의 크기는 파일의 최대 크기가 15*1=15KB인데 이는 분명히 무리입니다.
15KB보다 큰 파일을 저장했지만 너무 크지 않은 경우 1단계 간접 포인터 i_block[12]가 차지하게 됩니다. 이때 저장할 수 있는 포인터 수는 1024/4+12=268입니다. 이므로 268KB의 파일을 저장할 수 있습니다.
268K보다 크지만 너무 크지 않은 파일을 저장하면 보조 포인터 i_block[13]을 계속 차지하게 됩니다. 이때 저장할 수 있는 포인터 수는 [1024/4]^2+1024입니다. /4+12=65804. 따라서 약 65804KB=64M의 파일을 저장할 수 있습니다.
저장된 파일이 64M보다 큰 경우 계속해서 3단계 간접 포인터 i_block[14]을 사용하고 저장된 포인터 수는 [1024/4]^3+[1024/4]^2+[입니다. 1024/4]+12 =16843020 포인터이므로 약 16843020KB=16GB 정도의 파일을 저장할 수 있습니다.
블록 크기=4KB이면 어떻게 되나요? 그러면 저장할 수 있는 최대 파일 크기는 ([4096/4]^3+[4096/4]^2+[4096/4]+12)*4/1024/1024/1024=약 4T입니다.
물론, 이렇게 계산된 것이 반드시 저장할 수 있는 최대 파일 크기는 아닙니다. 또한 다른 조건도 적용됩니다. 여기의 계산은 단순히 대용량 파일이 어떻게 처리되고 할당되는지를 나타냅니다.
실제로 여기서 계산된 값을 보면 매우 큰 파일에 대한 ext2 및 ext3의 액세스 효율성이 낮다는 것을 알 수 있습니다. 특히 블록 크기가 4KB인 경우 너무 많은 포인터를 확인해야 합니다. Ext4는 이 점에 최적화되었습니다. Ext4는 익스텐트 관리를 사용하여 ext2와 ext3의 블록 매핑을 대체하여 효율성을 크게 향상시키고 조각화를 줄입니다.
4.6 단일 파일 시스템의 파일 작업 원칙
Linux에서 삭제, 복사, 이름 바꾸기, 이동 등의 작업을 수행할 때 어떻게 수행되나요? 파일에 액세스할 때 어떻게 찾나요? 사실, 이전 글에서 소개한 여러 용어와 그 기능을 이해한다면 파일 동작의 원리는 쉽게 알 수 있을 것이다.
참고: 이 섹션에서 설명하는 내용은 단일 파일 시스템에서의 동작입니다. 다중 파일 시스템을 사용하는 방법은 다음 섹션인 다중 파일 시스템 연결을 참조하세요.
4.6.1 파일 읽기
"cat /var/log/messages" 명령을 실행할 때 시스템 내부에서는 어떤 단계가 수행되나요? 이 명령의 성공적인 실행에는 cat 명령 검색, 권한 판단, 메시지 파일의 권한 검색 및 판단과 같은 복잡한 프로세스가 포함됩니다. 여기서는 이 섹션의 내용과 관련된 /var/log/messages 파일을 찾는 방법만 설명합니다.
루트 파일 시스템의 블록 그룹 설명자 테이블이 있는 블록을 찾고, GDT(이미 메모리에 있음)를 읽어 inode 테이블의 블록 번호를 찾습니다.
GDT는 항상 슈퍼블록과 같은 블록 그룹에 있고, 슈퍼블록은 항상 파티션의 1024~2047번째 바이트에 있기 때문에 첫 번째 GDT가 위치한 블록 그룹과 그 안에 있는 블록을 쉽게 알 수 있습니다. GDT가 위치한 곳 그룹에서 어떤 블록이 점유되어 있는지.
사실 GDT는 이미 메모리에 있습니다. 시스템이 부팅되면 루트 파일 시스템에 마운트됩니다. 마운트할 때 모든 GDT가 메모리에 들어갑니다.
inode 테이블의 블록에서 루트 "/"의 inode를 찾고 "/"가 가리키는 데이터 블록을 찾습니다.
앞서 언급한 것처럼 ext 파일 시스템은 일부 inode 번호를 예약하고 있는데, 그 중 "/"의 inode 번호는 2이므로, inode 번호를 기준으로 루트 디렉터리 파일의 데이터 블록을 직접 찾을 수 있습니다.
"/"의 데이터 블록에는 var 디렉터리 이름과 var 디렉터리 파일 inode에 대한 포인터가 기록되고, inode 레코드는 var에 대한 블록 포인터를 저장하므로 var 디렉터리 파일 데이터 블록도 발견되었습니다.
var 디렉터리의 inode 포인터를 통해 var 디렉터리의 inode 레코드를 찾을 수 있습니다. 하지만 포인터 위치 지정 과정에서는 inode 레코드가 위치한 블록 그룹과 inode 테이블도 알아야 합니다. 이므로 GDT를 읽어야 합니다. 마찬가지로 GDT도 메모리에 캐시되어 있습니다.
var의 데이터 블록에는 로그 디렉터리 이름과 해당 inode 포인터가 기록됩니다. 이 포인터를 통해 inode가 위치한 블록 그룹과 inode 테이블을 찾을 수 있으며, 이를 기반으로 로그의 데이터 블록을 찾습니다. 아이노드 레코드.
로그 디렉터리 파일의 데이터 블록에는 메시지 파일명과 해당 아이노드 포인터가 기록된다. 이 포인터를 통해 해당 아이노드가 위치한 블록 그룹과 아이노드 테이블이 위치하게 되고, 해당 아이노드 포인터의 데이터가 기록된다. 메시지는 inode 레코드를 기반으로 발견됩니다.
마지막으로 메시지에 해당하는 데이터 블록을 읽습니다.
위 단계 중 GDT 부분을 단순화하면 이해하기 쉽습니다. 다음과 같습니다: GDT 찾기--> "/"의 inode 찾기--> /의 데이터 블록 찾기, var의 inode 읽기--> var의 데이터 블록 찾기, log의 inode 읽기-- > 로그 블록의 데이터 찾기 메시지의 inode 읽기 --> 메시지의 데이터 블록을 찾아서 읽습니다.
4.6.2 파일 삭제, 이름 바꾸기 및 이동
이 작업은 파일 시스템을 넘지 않는 작업입니다.
삭제된 파일은 일반 파일과 디렉터리 파일로 구분됩니다. 이 두 가지 파일 유형의 삭제 원리를 알면 다른 유형의 특수 파일도 삭제하는 방법을 알 수 있습니다.
일반 파일을 삭제하려면: 파일의 inode와 데이터 블록을 찾습니다(이전 섹션의 방법에 따라 찾습니다). imap에서 파일의 inode 번호를 사용되지 않은 것으로 표시합니다. bmap의 데이터 블록 번호는 사용되지 않은 것으로 표시됩니다. 레코드가 삭제되면 Inode에 대한 포인터가 손실됩니다.
디렉토리 파일 삭제: 디렉터리 및 디렉터리에 있는 모든 파일, 하위 디렉터리 및 하위 파일의 inode 및 데이터 블록을 찾습니다. 이 inode 번호를 imap에서 사용되지 않은 것으로 표시합니다. bmap에서 해당 파일이 차지하는 블록 번호를 Not Used로 표시합니다. 디렉토리 상위 디렉토리의 데이터 블록에서 디렉토리 이름이 있는 레코드 라인을 삭제합니다. 상위 디렉터리 데이터 블록의 레코드를 삭제하는 것이 마지막 단계라는 점에 유의하세요. 이 단계를 미리 수행하면 디렉터리에 아직 파일이 남아 있기 때문에 디렉터리가 비어 있지 않음 오류가 보고됩니다.
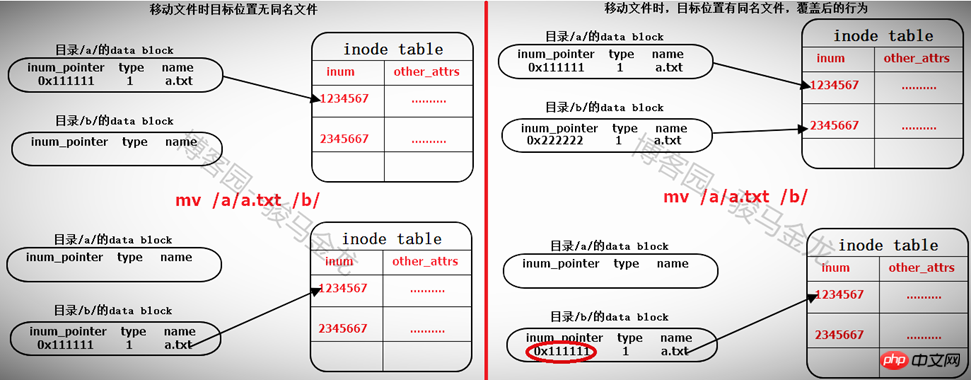
파일 이름 바꾸기는 동일한 디렉터리 내에서 이름 바꾸기와 다른 디렉터리 내에서 이름 바꾸기로 구분됩니다. 다른 디렉터리에서 이름을 바꾸는 것은 실제로 파일을 이동하는 과정입니다. 아래를 참조하세요.
동일 디렉토리에 있는 파일의 이름을 바꾸는 작업은 해당 파일이 위치한 디렉토리의 데이터 블록에 기록된 파일 이름을 수정하는 작업일 뿐이며 삭제하고 다시 빌드하는 과정은 아닙니다.
이름을 바꾸는 동안 파일 이름이 충돌하는 경우(파일 이름이 디렉터리에 이미 존재하는 경우) 덮어쓸지 묻는 메시지가 표시됩니다. 덮어쓰기 프로세스는 디렉터리 데이터 블록에서 충돌하는 파일의 기록을 덮어쓰는 것입니다. 예를 들어 /tmp/ 아래에 a.txt와 a.log가 있습니다. a.txt의 이름을 a.log로 바꾸면 데이터의 a.log에 대한 기록을 덮어쓰라는 메시지가 표시됩니다. /tmp 블록은 덮어쓰여집니다. 이때 해당 포인터는 a.txt의 inode를 가리키고 있습니다.
파일 이동
동일한 파일 시스템 아래에서 파일을 이동하는 것은 실제로 대상 파일이 있는 디렉터리의 데이터 블록을 수정하고 파일의 inode 포인터를 가리키는 줄을 추가하는 것입니다. inode 테이블에 이동할 파일이 있으면 대상 경로 파일에 같은 이름의 파일이 있으면 덮어쓸 것인지 묻는 메시지가 표시됩니다. 실제로 디렉터리 데이터 블록에 있는 충돌 파일의 기록을 덮어쓰게 됩니다. 동일한 이름을 가진 파일의 inode 레코드 포인터를 덮어쓰면 파일의 데이터 블록을 더 이상 찾을 수 없습니다. 이는 파일이 삭제로 표시됨을 의미합니다(하드 링크가 여러 개인 경우에는 다른 문제입니다).
따라서 동일한 파일 시스템 내에서 파일을 이동하는 것은 매우 빠릅니다. 파일이 위치한 디렉터리의 데이터 블록에 레코드를 추가하거나 덮어쓰는 것뿐입니다. 따라서 파일을 이동할 때 파일의 inode 번호는 변경되지 않습니다.
다른 파일 시스템 내에서 이동하는 경우 먼저 복사한 다음 삭제하는 것과 같습니다. 아래를 참조하세요.
4.6.1 存储和复制文件
对于文件存储
(1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
(2).在inode table中完善该inode号所在行的记录;
(3).在目录的data block中添加一条该文件的相关记录;
(4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。
另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
(5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
对于复制,完全就是另一种方式的存储文件。步骤和存储文件的步骤一样。
4.7 多文件系统关联
在单个文件系统中的文件操作和多文件系统中的操作有所不同。本文将对此做出非常详细的说明。
4.7.1 根文件系统的特殊性
这里要明确的是,任何一个文件系统要在Linux上能正常使用,必须挂载在某个已经挂载好的文件系统中的某个目录下,例如/dev/cdrom挂载在/mnt上,/mnt目录本身是在"/"文件系统下的。而且任意文件系统的一级挂载点必须是在根文件系统的某个目录下,因为只有"/"是自引用的。这里要说明挂载点的级别和自引用的概念。
假如/dev/sdb1挂载在/mydata上,/dev/cdrom挂载在/mydata/cdrom上,那么/mydata就是一级挂载点,此时/mydata已经是文件系统/dev/sdb1的入口了,而/dev/cdrom所挂载的目录/mydata/cdrom是文件系统/dev/sdb1中的某个目录,那么/mydata/cdrom就是二级挂载点。一级挂载点必须在根文件系统下,所以可简述为:文件系统2挂载在文件系统1中的某个目录下,而文件系统1又挂载在根文件系统中的某个目录下。
再解释自引用。首先要说的是,自引用的只能是文件系统,而文件系统表现形式是一个目录,所以自引用是指该目录的data block中,"."和".."的记录中的inode指针都指向inode table中同一个inode记录,所以它们inode号是相同的,即互为硬链接。而根文件系统是唯一可以自引用的文件系统。
[root@xuexi /]# ll -ai /total 102 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 . 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 ..
由此也能解释cd /.和cd /..的结果都还是在根下,这是自引用最直接的表现形式。
[root@xuexi tmp]# cd /. [root@xuexi /]# [root@xuexi tmp]# cd /.. [root@xuexi /]#
但是有一个疑问,根目录下的"."和".."都是"/"目录的硬链接,所以除去根目录下目录数后的硬链接数位3,但实际却为2,不知道这是为何?
[root@server2 tmp]# a=$(ls -al / | grep "^d" |wc -l) [root@server2 tmp]# b=$(ls -l / | grep "^d" |wc -l) [root@server2 tmp]# echo $((a - b))2
4.7.2 挂载文件系统的细节
挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode指针inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
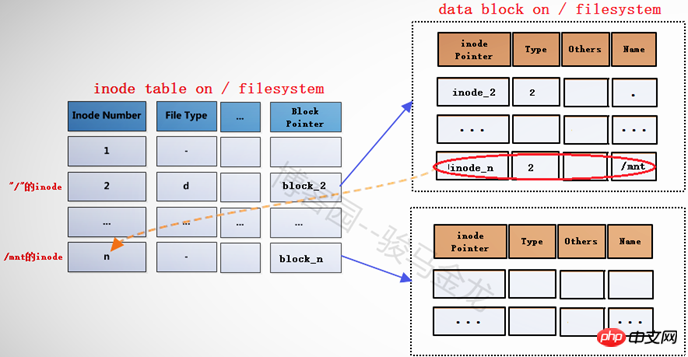
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。但是如何连接呢?如下图。
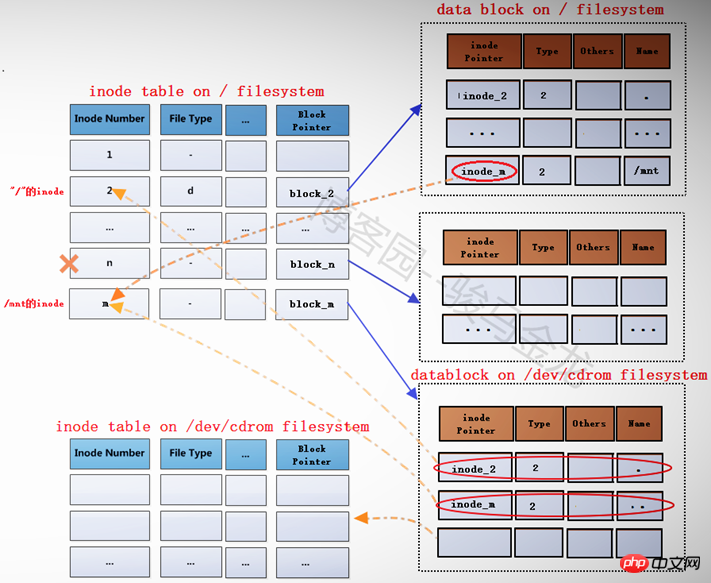
在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。既然为/mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
# 挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt [root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号 [root@server2 tmp]# ll -id /mnt 1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
# 在挂载前,向挂载点中创建几个文件 [root@server2 tmp]# touch /mnt/a.txt [root@server2 tmp]# mkdir /mnt/abcdir
# 挂载 [root@server2 tmp]# mount /dev/cdrom /mnt # 挂载后,挂载点中将找不到刚创建的文件 [root@server2 tmp]# ll /mnt total 636-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI-r--r--r-- 1 root root 215 Dec 10 2015 EULA-r--r--r-- 1 root root 18009 Dec 10 2015 GPL dr-xr-xr-x 3 root root 2048 Dec 10 2015 images dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL # 卸载后,挂载点/mnt中的文件将再次可见 [root@server2 tmp]# umount /mnt [root@server2 tmp]# ll /mnt total 0drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
이런 일이 발생하는 이유는 파일 시스템을 마운트한 후 마운트 지점의 원래 inode 레코드가 일시적으로 사용할 수 없는 것으로 표시되기 때문입니다. 핵심은 inode 레코드를 가리키는 inode 포인터가 없다는 것입니다. 파일 시스템을 제거한 후 마운트 지점의 원래 inode 레코드가 다시 활성화되고 "/" 디렉터리에 있는 mnt의 inode 포인터가 다시 inode 레코드를 가리킵니다.
(3) 마운트 후에는 마운트 지점의 메타데이터와 데이터 블록이 다른 파일 시스템에 저장됩니다.
(4) 마운트 지점이 마운트된 후에도 여전히 소스 파일 시스템의 파일에 속합니다.
4.7.3 다중 파일 시스템 운영 연관
아래 그림의 원은 3개의 영역, 즉 3개의 파일 시스템으로 나누어진 하드 디스크를 나타낸다고 가정해 보겠습니다. 그 중 root는 루트 파일 시스템이고, /mnt는 다른 파일 시스템 A의 항목이고, 파일 시스템 A는 /mnt에 마운트되고, /mnt/cdrom도 파일 시스템 B의 항목이며, 파일 시스템 B는 다음에 마운트됩니다. /mnt/cdrom. 각 파일 시스템은 일부 아이노드 테이블을 유지한다. 그림의 아이노드 테이블은 각 파일 시스템의 모든 블록 그룹에 있는 아이노드 테이블의 컬렉션 테이블이라고 가정한다.

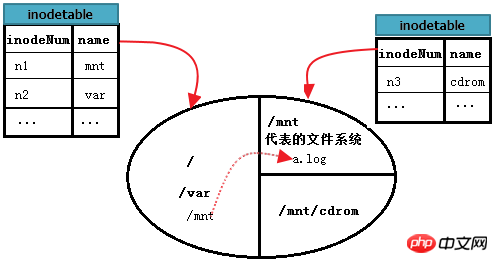
/var/log/messages를 읽는 방법은 무엇입니까? 이는 이전 단일 파일 시스템에서 자세히 설명한 "/"와 동일한 파일 시스템에서 파일을 읽는 것입니다.
하지만 A 파일 시스템에서 /mnt/a.log를 읽는 방법은 무엇입니까? 먼저 루트 파일 시스템에서 /mnt의 inode 레코드를 찾습니다. 이는 단일 파일 시스템 내에서 검색한 다음 이 inode 레코드의 블록 포인터를 기반으로 /mnt의 데이터 블록을 찾습니다. 파일 시스템 A; 그런 다음 /mnt의 데이터 블록에서 a.log 레코드를 읽고, 마지막으로 a.log의 inode 포인터에 따라 A 파일 시스템의 inode 테이블에서 a.log에 해당하는 inode 레코드를 찾습니다. 이 inode 로그 데이터 블록의 블록 포인터에서 a를 찾습니다. 이 시점에서 /mnt/a.log 파일의 내용을 읽을 수 있습니다.
아래 그림은 위의 과정을 더 완벽하게 설명할 수 있습니다.
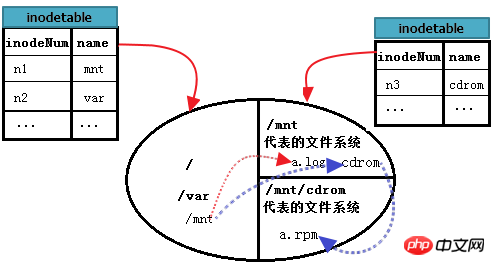
그럼 /mnt/cdrom에서 /mnt/cdrom/a.rpm을 읽는 방법은 무엇일까요? 여기서 cdrom으로 표시되는 파일 시스템 B 마운트 지점은 /mnt 아래에 있으므로 한 단계가 더 있습니다. 먼저 "/"를 찾은 다음 루트에서 mnt를 찾고 mnt 파일 시스템에 들어가서 cdrom의 데이터 블록을 찾은 다음 cdrom을 입력하여 a.rpm을 찾습니다. 즉, mnt 디렉터리 파일이 저장된 위치가 루트, cdrom 디렉터리 파일이 저장된 위치가 mnt, 마지막으로 a.rpm이 저장된 위치가 cdrom이 됩니다.
위 그림을 계속해서 개선해 보세요. 다음과 같이.
4.8 ext3 파일 시스템의 로깅 기능
ext2 파일 시스템과 비교하여 ext3에는 추가 로그 기능이 있습니다.
ext2 파일 시스템에는 데이터 영역과 메타데이터 영역의 두 가지 영역만 있습니다. 데이터 블록에 데이터를 채우는 중에 갑자기 정전이 발생하면 다음에 시작할 때 파일 시스템의 데이터 및 상태의 일관성을 확인합니다. 이 확인 및 복구에는 많은 시간이 걸릴 수 있습니다. 점검 후에도 수리가 불가능합니다. 이런 일이 발생하는 이유는 파일 시스템이 갑자기 전원이 꺼진 후 지난번에 저장되었던 파일의 블록이 어디에서 시작하고 끝나는지 알 수 없기 때문에 전체 파일 시스템을 스캔하여 이를 제외시키기 때문입니다(어쩌면 체크인이 되어있을 수도 있습니다) 이 방법으로).
ext3 파일 시스템을 생성할 때 데이터 영역, 로그 영역, 메타데이터 영역의 세 가지 영역으로 구분됩니다. 데이터가 저장될 때마다 ext2의 메타데이터 영역의 활동이 먼저 로그 영역에서 수행됩니다. 파일에 커밋이 표시되어야 로그 영역의 데이터가 메타데이터 영역으로 전송됩니다. 파일 저장 시 갑작스런 정전이 발생한 경우, 다음 번에 파일 시스템을 확인하고 복구할 때 로그 영역의 기록을 확인하고 bmap에 해당하는 데이터 블록을 사용하지 않음으로 표시하고 inode 번호를 표시하기만 하면 됩니다. 사용되지 않은 것으로 간주되므로 전체 파일을 검사할 필요가 없습니다. 시스템에서 많은 시간이 소모됩니다.
ext3는 메타데이터 영역을 변환하는 ext2보다 로그 영역이 하나 더 많지만 특히 작은 파일을 많이 작성할 때 ext3의 성능은 ext2보다 약간 떨어집니다. 그러나 ext3의 다른 측면의 최적화로 인해 ext3과 ext2 사이에는 성능 차이가 거의 없습니다.
4.9 ext4 파일 시스템
ext2 및 ext3 파일 시스템의 이전 저장 형식을 상기해 보세요. 각 블록은 블록을 분할하는 방법이지만 bmap의 비트를 사용하여 사용 가능한지 여부를 표시합니다. 최적화를 사용하면 효율성이 향상되지만 블록 그룹 내에서 블록을 표시하기 위해 여전히 bmap이 사용됩니다. 대용량 파일의 경우 전체 bmap을 스캔하는 것은 엄청난 프로젝트가 됩니다. 또한 inode 주소 지정 측면에서 ext2/3은 직접 및 간접 주소 지정 방법을 사용합니다. 3레벨 간접 포인터의 경우 탐색할 수 있는 포인터 수가 매우 많습니다.
ext4 파일 시스템의 가장 큰 특징은 ext3 기반의 익스텐트(extent, or 세그먼트) 개념을 이용해 관리된다는 점이다. 익스텐트는 물리적으로 인접한 블록을 가능한 한 많이 포함합니다. 섹션 트리를 사용하여 Inode 주소 지정도 개선되었습니다.
기본적으로 EXT4는 더 이상 EXT3의 블록 매핑 할당 방법을 사용하지 않고 대신 Extent 할당 방법을 사용합니다.
(1) EXT4
의 구조적 특성은 전체 구조가 EXT3과 유사합니다. 큰 할당 방향은 동일한 크기의 블록 그룹을 기반으로 하며 각 그룹에는 가능한 슈퍼 블록이 할당됩니다. 블록 그룹(또는 백업) 및 GDT.
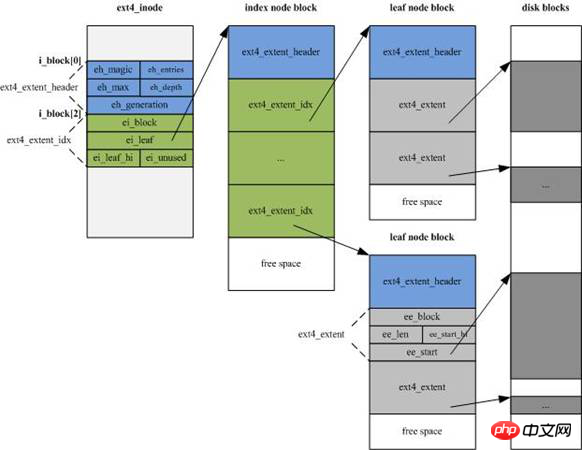
EXT4의 inode 구조가 크게 변경되었습니다. 새로운 정보를 추가하기 위해 크기가 EXT3의 128바이트에서 기본 256바이트로 늘어났습니다. 동시에 inode 주소 지정 인덱스는 더 이상 EXT3의 "12 직접"을 사용하지 않습니다. 주소 지정 블록+" "1 레벨 1 간접 주소 지정 블록 + 1 레벨 2 간접 주소 지정 블록 + 1 레벨 3 간접 주소 지정 블록"의 인덱스 모드가 4 Extent 조각 스트림으로 변경되고 각 조각 스트림은 조각의 시작을 설정합니다. 번호 및 연속 블록 수(데이터 영역을 직접 가리킬 수도 있고 인덱스 블록 영역을 가리킬 수도 있음)
프래그먼트 스트림은 아래 그림의 인덱스 노드 블록(inde node 블록)의 녹색 영역으로 각 15바이트, 총 60바이트입니다.
(2). EXT4는 데이터의 구조적 변경 사항을 삭제합니다.
데이터를 삭제한 후 EXT4는 파일 시스템 비트맵 공간 비트를 해제하고, 디렉터리 구조를 업데이트하고, inode 공간 비트를 순차적으로 해제합니다.
(3) ext4는 다중 블록 할당을 사용합니다.
데이터를 저장할 때 ext3의 블록 할당자는 한 번에 4KB 블록만 할당할 수 있으며 각 블록이 저장되기 전에 bmap이 한 번 표시됩니다. 1G 파일이 저장되고 블록 크기가 4KB인 경우 각 블록이 저장된 후 블록 할당자가 한 번씩 호출됩니다. 즉 호출 횟수는 1024*1024/4KB=262144회이고 bmap의 횟수는 표시도 1024*1024/4= 262,144번입니다.
ext4에서는 블록 할당자를 한 번 호출하여 연속된 블록 묶음을 할당하고, 이 블록 묶음을 저장하기 전에 해당 bmap을 한 번에 표시하는 것이 가능합니다. 이는 대용량 파일의 저장 효율성을 크게 향상시킵니다.
4.10 ext 파일 시스템의 단점
가장 큰 단점은 파일 시스템을 생성할 때 나누어야 할 부분을 모두 나누어서 나중에 사용할 때 직접 할당할 수 있다는 점이다. 동적 파티셔닝 및 동적 할당을 지원하지 않습니다. 작은 파티션의 경우 속도는 괜찮지만 매우 큰 디스크의 경우 속도가 매우 느립니다. 예를 들어 수십 테라바이트의 디스크 어레이를 ext4 파일 시스템으로 포맷하면 인내심이 완전히 상실될 수 있습니다.
매우 느린 포맷 속도 외에도 ext4 파일 시스템이 여전히 매우 선호됩니다. 물론, 다양한 회사에서 개발한 파일 시스템에는 고유한 특성이 있습니다. 가장 중요한 것은 필요에 따라 적절한 파일 시스템 유형을 선택하는 것입니다.
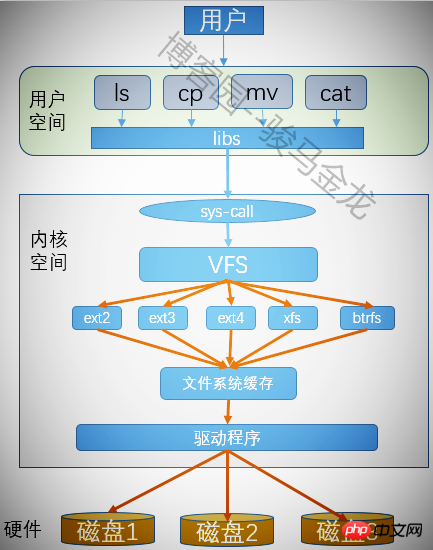
4.11 가상 파일 시스템 VFS
모든 파티션은 포맷 후 파일 시스템을 생성할 수 있습니다. Linux는 많은 파일 시스템을 인식할 수 있는데 어떻게 인식됩니까? 게다가 파티션에 있는 파일을 조작할 때 어떤 파일 시스템에 속하는지 명시하지도 않았는데요. 어떻게 사용자가 다양한 파일 시스템을 무분별하게 조작할 수 있겠습니까? 이것이 가상 파일 시스템이 하는 일입니다.
가상 파일 시스템은 사용자가 다양한 파일 시스템을 운용할 수 있는 공통 인터페이스를 제공하므로, 프로그램을 실행할 때 사용자는 파일이 어떤 파일 시스템에 있는지, 어떤 시스템 호출을 사용해 운용해야 하는지 고려할 필요가 없습니다. .파일. 가상 파일 시스템을 사용하면 실행해야 하는 모든 프로그램에 대해 VFS의 시스템 호출만 호출하면 되며 VFS는 나머지 작업을 완료하는 데 도움이 됩니다.
재인쇄시 출처를 밝혀주세요 :
위 내용은 ext 파일 시스템 메커니즘의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!