
집 >위챗 애플릿 >미니 프로그램 개발 >음양사 미니 프로그램 24시간 개발
음양사 미니 프로그램 24시간 개발
- 巴扎黑원래의
- 2017-04-01 15:26:122492검색
0.서문
인장이 매일 오전 5시, 오후 6시에 두 번 갱신된다는 것은 누구나 알고 있습니다. 작업을 수행할 때마다 가장 짜증나는 일은 다양한 몬스터의 복사본과 신비한 단서를 찾는 것입니다. Onmyoji는 일부 데이터 쿼리에 대해 NetEase Genie를 제공하지만 경험이 너무 감동적이어서 대부분의 사람들은 몬스터 배포 및 신비한 단서를 검색하기 위해 검색 엔진을 선택합니다.
매번 검색엔진을 사용하는 것이 너무 불편해서 저자는 음양사 유통을 쿼리하는 작은 프로그램을 작성하기로 결정했습니다. 개밥과 영혼 통제에 더 많은 시간을 할애하여 지름길을 사용하여 더 빠른 경험을 달성하도록 노력하십시오.
지난 주말에 마침 이틀이 있어서 바로 글을 쓰기 시작했어요.
1. 구상 및 설계(3시간)1.1 구상
만들려는 미니 프로그램의 주요 기능은 쿼리 기능이므로 홈페이지는 검색 엔진만큼 간결해야 하며 검색창은 반드시 필요합니다.
인기 검색 및 가장 인기 있는 식신 검색
검색은 전체 일치 또는 단일 단어 일치를 지원합니다.
-
검색 결과를 클릭하면 이동합니다. 53. Shikigami 세부 정보 페이지에는 식신의 그림, 이름, 희귀도, 출몰 장소가 포함되어야 하며 출몰 장소는 몬스터가 많은 곳에서 적은 곳으로 정렬됩니다. 🎜>
데이터 오류 보고 및 제안 기능 추가 - 사용자의 개인 검색 기록 지원
- 미니프로그램 이름은 식신사냥꾼으로 결정되었습니다(사실 미니프로그램의 기능을 생각해보면) 최종 개발이 완료된 후에 생각한 것입니다); 🎜>1.2 디자인
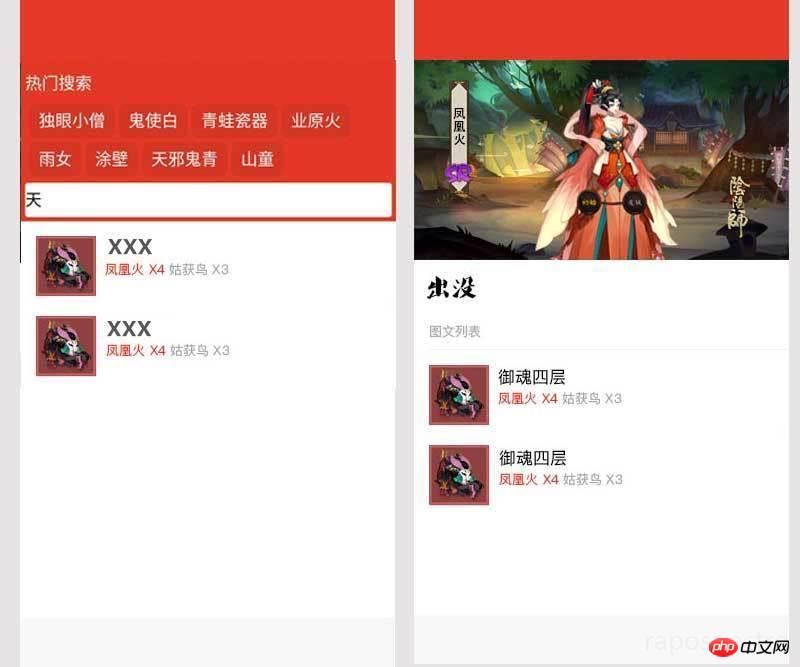 자, 가장 중요한 홈페이지와 상세페이지가 디자인되었으니 어떻게 하면 좋을지 고민을 시작하시면 됩니다!
자, 가장 중요한 홈페이지와 상세페이지가 디자인되었으니 어떻게 하면 좋을지 고민을 시작하시면 됩니다!
1.3 기술 아키텍처프론트 엔드는 의심할 여지없이 WeChat 애플릿입니다.
백엔드는 Django를 사용하여 Restful API 서비스를 제공합니다.
- 현재 가장 인기 있는 검색은 캐싱을 위한 캐시 서버로 redis를 사용합니다. >
개인 검색 기록은 WeChat 애플릿에서 제공하는 로컬 저장소를 사용합니다.
식신 배포 정보는 크롤러를 사용하여 크롤링 및 정리된 후 json으로 포맷된 후 수동으로 확인되어 저장됩니다.
식신 사진과 아이콘은 공식 정보에서 직접 크롤링됩니다.
-
크롤링할 수 없는 식신 사진과 아이콘을 직접 만들어 보세요. ;
미니 프로그램을 사용하려면 HTTPS 연결이 필요한데, 예전에 연결을 했었는데, 여기서 바로 보실 수 있습니다
HTTPS 무료 배포 가이드-
이쯤 되면 정식 개발을 위한 준비가 완료된 후 정식 개발을 시작할 수 있게 됩니다
2. API 서비스 개발(5시간)
작가는 예전에 Django API 서비스 개발을 자주 했었는데, 비교적 완전한 솔루션이 있으므로 여기를 참조하세요django-simple-serializer
5시간이 걸린 이유는 Django ManyToManyField의 through 기능에 대한 django-simple-serializer 지원을 추가하는 작업에 거의 4시간이 걸렸기 때문입니다.
간단히 말하면 through 기능을 사용하면 다대다 관계의 중간 테이블에 다음과 같은 추가 필드나 속성을 추가할 수 있습니다. 몬스터 간의 많은 관계 각 복사본에 해당 몬스터의 수를 저장하는 필드 수를 추가해야 합니다.
지원을 받은 후 API 구축은 주로 5가지 API로 이루어집니다.
검색 인터페이스;
시키가미 세부정보 인터페이스;
- 시키가미 복사 인터페이스; 🎜> 인기 검색 인터페이스
- 피드백 인터페이스
인터페이스 작성 후 테스트용 모의 데이터 추가프론트엔드 개발(8시간)
프런트엔드가 가장 오래 걸렸습니다.
작가는 정말 백엔드 엔지니어이고, 프론트엔드는 반쯤 괜찮은 편이다. 반면에 미니 프로그램에는 몇 가지 함정이 있습니다. 물론 가장 중요한 것은 인터페이스 효과를 계속해서 조정하는 것이며, 여기에는 많은 시간이 소요됩니다.
작은 프로그램 작성의 전반적인 경험은 일부 html 태그를 사용할 수 없다는 점을 제외하면 vue.js 작성과 완전히 동일합니다. 다만, 미니 프로그램에서 공식적으로 제공하는 컴포넌트에 맞춰 작성해야 하는데, 여기서 느낀 점 중 하나는 미니 프로그램 자체의 컴포넌트 디자인 아이디어는 React를 기반으로 하고, 문법은 vue를 기반으로 해야 한다는 점입니다. js.js.
마지막으로 프론트엔드 개발이 완료되면 크게 아래와 같은 페이지로 나누어집니다.
홈페이지(검색페이지)- 시키가미 상세페이지
- (주로 검색 기록 및 면책 조항 등을 표시하기 위해);
- 피드백 인터페이스,
- 이 인터페이스가 필요한 이유는 무엇입니까? 모든 사진과 일부 리소스는 모두 음양사 공식 리소스에서 직접 가져온 것이므로 여기에는 비영리 용도로만 사용할 수 있으며 지저분한 저작권은 여전히 음양사에 속한다는 점을 여기에 명시해야 합니다.
야 못난 며느리가 조만간 시부모님을 만날 테니까 넣어야지 최종 인터페이스 다이어그램은 여기 WeChat의 경우 미니 프로그램의 소개와 기본 사항에 대해서는 여기서 자세히 설명하지 않겠습니다. 현재 WeChat 미니 프로그램에 관심이 있는 개발자라면 간단한 데모를 작성하는 데 문제가 없을 것이라고 믿습니다. 주로 개발 중에 겪은 함정에 대해 이야기하겠습니다.
3.1 배경 이미지 속성 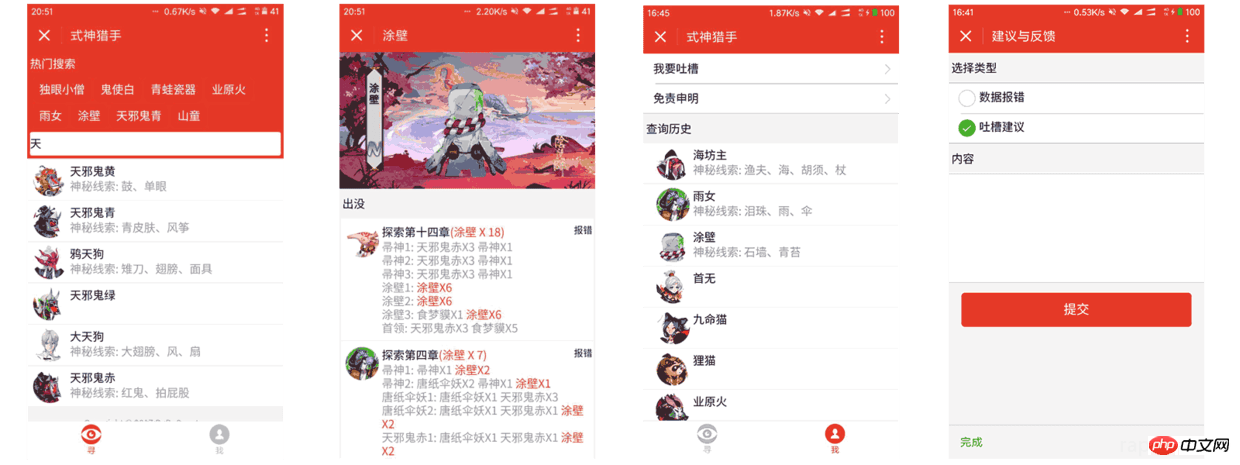
Shikigami 세부 정보 페이지를 작성할 때 background-image 속성을 사용하여 두 곳에서 배경 이미지를 설정해야 합니다. WeChat 개발자 도구에서는 모든 것이 정상적으로 표시되지만 실제 컴퓨터에서 디버깅되면 , 표시할 수 없습니다. 실제 시스템은 로컬 리소스 참조를 지원하지 않습니다.
네트워크 이미지 사용: 배경 이미지의 크기를 고려하여 저자는
이미지 인코딩을 위해 포기했습니다.
일반적으로 CSS의 배경 이미지는 base64를 지원합니다. 이 솔루션은 base64 섹션을 사용하여 이미지를 직접 인코딩하는 것과 같습니다. 의 base64 코드가 저장되어 있으며, 사용시에는 다음과 같이 사용할 수 있습니다:
[CSS] 일반 텍스트 보기 코드 복사
background-image: url(data:image/image-format;base64,XXXX);
image-format은 이미지 자체의 형식이고, xxxx는 base64 이후의 이미지 인코딩입니다. 이 방법은 실제로 로컬 리소스를 참조하는 위장된 방법입니다. 장점은 이미지 요청 수를 줄일 수 있다는 것이지만, CSS 파일의 크기가 커지고 보기에 좋지 않다는 단점이 있습니다.
결국 작성자가 두 번째 방법을 선택한 이유는 이미지의 크기와 wxss의 증가가 허용 범위 내에 있었기 때문입니다. 범위.
3.2 템플릿
미니 프로그램은 템플릿을 지원하지만 템플릿에는 자체 Scope에서는 data에 전달된 데이터만 사용할 수 있습니다.
또한, 데이터를 전달할 때 해당 데이터를 해체하여 전달해야 합니다. 템플릿 내부에서는 직접적으로 {{ xxxx }}로 표시됨 루프에서 {{ item.xxx }} 형식으로 액세스
[XML ] 일반 텍스트 보기 코드 복사
<template is="xxx" data="{{...object}}"/>세번째는 입니다. 일반적으로 템플릿은 일반 wxml에 직접 작성되는 대신 다른 파일이 호출할 수 있도록 별도의 템플릿 파일에 배치됩니다. 예를 들어, 저자의 카탈로그는 다음과 같습니다.
[JavaScript] 일반 텍스트 보기 코드 복사
├── app.js ├── app.json ├── app.wxss ├── pages │ ├── feedback │ ├── index │ ├── my │ ├── onmyoji │ ├── statement │ └── template │ ├── template.js │ ├── template.json │ ├── template.wxml │ └── template.wxss ├── static └── utils호출할 다른 파일 템플릿, 직접 사용 그냥 가져오기:
[XML] 일반 텍스트 보기 코드 복사
<import src="../template/template.wxml" />그런 다음 템플릿을 인용해야 하는 위치 :
[ XML] 일반 텍스트 보기 코드 복사
<template is="xxx" data="{{...object}}"/>
这里遇到另一个问题,template 对应的样式写在 template 对应的 wxss 中并没有作用,需要写在调用 template 的文件的 wxss 中,比如 index 需要使用 template 则需要将对应的 css 写在 my/my.wxss 中。
4. 爬取图片资源 ( 2小时 )
式神的图标及形象图基本上阴阳师官网都有,这里自己做也不现实,所以果断写爬虫爬下来然后存到自己的 cdn 。
大图和小图都在 http://yys.163.com/shishen/index.html 这里可以找到。 一开始考虑爬取网页然后 beautiful soup 提取数据,后面发现式神数据竟然是异步加载的,那就更简单了,分析网页得到 https://g37simulator.webapp.163.com/get_heroid_list 直接返回了式神信息的 json 信息,所以很容易写个爬虫就可以搞定了:
[Python] 纯文本查看 复制代码
# coding: utf-8
import json
import requests
import urllib
from xpinyin import Pinyin
url = "https://g37simulator.webapp.163.com/get_heroid_list?callback=jQuery11130959811888616583_1487429691764&rarity=0&page=1&per_page=200&_=1487429691765"
result = requests.get(url).content.replace('jQuery11130959811888616583_1487429691764(', '').replace(')', '')
json_data = json.loads(result)
hellspawn_list = json_data['data']
p = Pinyin()
for k, v in hellspawn_list.iteritems():
file_name = p.get_pinyin(v.get('name'), '')
print 'id: {0} name: {1}'.format(k, v.get('name'))
big_url = "https://yys.res.netease.com/pc/zt/20161108171335/data/shishen_big/{0}.png".format(k)
urllib.urlretrieve(big_url, filename='big/{0}@big.png'.format(file_name))
avatar_url = "https://yys.res.netease.com/pc/gw/20160929201016/data/shishen/{0}.png".format(k)
urllib.urlretrieve(avatar_url, filename='icon/{0}@icon.png'.format(file_name))然而,爬完数据后发现一个问题,网易官方的图片都是无码高清大图,对于笔者这种穷 ds 大图放在 cdn 上两天就得破产,所以需要批量将图片转成既不太大又能看的过去。嗯,这里就可以用到 ps 的批处理能力了。
打开 ps ,然后选择爬到的一张图片;
选择菜单栏上的“窗口”然后选择“动作;
在“动作”选项下,新建一个动作;
点击圆形录制按钮开始录制动作;
按正常处理图片等顺序将一张图片存为 web 格式;
点击方形停止按钮停止录制动作;
选择菜单栏上的 文件-自动-批处理-选择之前录制的动作-配置好输入文件夹和输出文件夹;
点击确定就可以啦;
等批处理结束,期间刷个御魂啥的应该就好了,然后将得到的所有图片上传到静态资源服务器,图片这里就处理完啦。
5. 式神数据爬取 ( 4小时 )
式神分布数据网上比较杂并且数据很多有偏差,所以斟酌再三决定采用半人工半自动的方式,爬到的数据输出为 json:
[JavaScript]
{
"scene_name": "探索第一章",
"team_list": [{
"name": "天邪鬼绿1",
"index": 1,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "天邪鬼绿2",
"index": 2,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "提灯小僧1",
"index": 3,
"monsters": [{
"name": "天邪鬼绿",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "提灯小僧2",
"index": 4,
"monsters": [{
"name": "灯笼鬼",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "首领",
"index": 5,
"monsters": [{
"name": "九命猫",
"count": 3
}]
}]
}然后再人工检查一遍,当然还是会有遗漏,所以数据报错的功能就很重要啦。
这一部分实际写代码的时间可能只有半个多小时,剩下时间一直在检查数据;
一切检查结束后写个脚本直接将 json 导入到数据库中,检查无误后用 fabric 发布到线上服务器进行测试;
6. 测试 ( 2小时 )
最后一步基本上就是在手机上体验查错,修改一些效果,关闭调试模式准备提交审核;
벌써 일요일이군요, 아, 아니, 월요일 아침 1시가 되어야 합니다.
미니프로그램팀의 심사속도가 매우 빠르다고 말씀드리고 싶습니다. 빠르게, 월요일 오후에 리뷰를 통과하고 과감히 온라인에 올라왔습니다.
마지막 렌더링:
위 내용은 음양사 미니 프로그램 24시간 개발의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!