
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 인덱스 및 구조에 대한 심층 설명
MySQL 인덱스 및 구조에 대한 심층 설명

- 黄舟원래의
- 2017-03-01 13:32:561204검색
B-트리
B-트리는 균형 다중 경로 검색 트리(바이너리 아님)라고도 합니다. 녹음 시 경험하는 중간 프로세스를 찾아 액세스 속도를 높입니다.
왼쪽 자식 노드 키 값B-Tree에서 키로 데이터를 검색하는 알고리즘은 매우 직관적입니다. 먼저 루트 노드에서 이진 검색을 수행합니다. 해당 노드의 데이터가 반환됩니다. 그렇지 않으면 해당 간격의 포인터가 가리키는 노드를 노드를 찾거나 널 포인터를 찾을 때까지 재귀적으로 검색합니다. 전자 검색은 성공하고 후자 검색은 실패합니다. 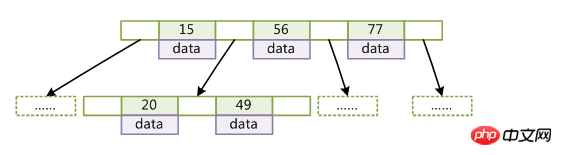
(key는 레코드의 키 값입니다. 데이터 레코드에 따라 키가 서로 다릅니다. data는 키를 제외한 데이터 레코드의 데이터입니다.)
B +tree
B+Tree는 향상된 B-트리입니다. 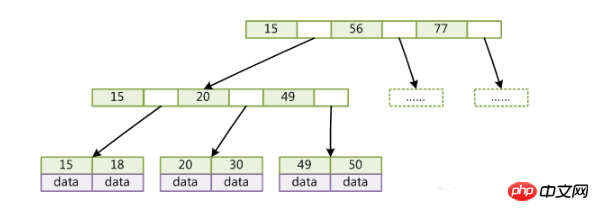
(key는 레코드의 키 값입니다. 서로 다른 데이터 레코드의 경우 키가 서로 다릅니다. data는 키를 제외한 데이터 레코드의 데이터입니다.)
호환 가능 with B-Tree B+Tree와 비교하면 다음과 같은 차이점이 있습니다.
각 노드의 포인터 상한은 2d+1이 아닌 2d입니다.
내부 노드는 데이터를 저장하지 않으며 리프 노드만 포인터를 저장하지 않습니다.
그렇다면 데이터베이스는 왜 B-tree를 사용하는가
컴퓨터의 기계적 디스크는 기계적 이동을 위한 대기시간을 상쇄하기 위해 여러 개의 디스크에 접근하게 된다. 한 번에 읽는 데이터 항목은 한 페이지입니다. 읽거나 쓴 페이지 수를 디스크 액세스 의 주요 근사값으로 사용할 수 있습니다. 언제든지 B 트리 알고리즘은 특정 수의 페이지만 메모리에 유지하면 됩니다. B-트리의 설계는 디스크 사전 읽기를 고려합니다. B-트리 노드는 일반적으로 전체 디스크 페이지(페이지)만큼 크며 디스크 페이지의 크기는 B-트리 노드에는 숫자(분기 요소)가 포함될 수 있으며, 이는 페이지에 대한 키워드의 크기에 따라 달라집니다.
I/O 작업을 최소화하기 위해 디스크 읽기는 매번 미리 읽혀지며 크기는 일반적으로 페이지의 정수배입니다. 1바이트만 읽어야 하는 경우에도 디스크는 한 페이지의 데이터(보통 4K)를 읽어 메모리에 저장합니다. 메모리와 디스크는 페이지 단위로 데이터를 교환합니다. 일반적으로 하나의 데이터를 사용하면 근처의 데이터도 즉시 사용된다는 지역성의 원칙이 있기 때문입니다.
B-Tree: 검색에 4개 노드에 대한 액세스가 필요한 경우 데이터베이스 시스템 설계자는 디스크 미리 읽기 원칙을 사용하여 노드 크기를 한 페이지로 설계한 다음 한 노드를 읽으려면 I 하나만 필요합니다. /O 작업 - 이 검색 작업을 완료하려면 최대 3개의 I/O가 필요합니다(루트 노드는 메모리에 상주합니다). 데이터 레코드가 작을수록 각 노드에 더 많은 데이터가 저장되고 트리 높이가 작아지며 I/O 작업이 줄어들고 검색 효율성이 높아집니다.
B+Tree: 리프가 아닌 노드는 키만 저장하므로 리프가 아닌 노드의 크기가 크게 줄어들므로 각 노드는 더 많은 레코드를 저장할 수 있습니다. 트리가 더 짧고 I/O 작업이 적습니다. . 따라서 B+Tree의 성능이 더 좋습니다.
인덱스란 무엇인가요?
인덱스는 단순한 데이터 구조입니다.
인덱싱 비용
인덱싱에도 비용이 발생합니다. 인덱스 파일 자체가 저장 공간을 소모하고, 인덱스로 인해 레코드 삽입, 삭제, 수정 부담이 늘어납니다. 또한 인덱스를 유지하는 데 리소스가 소비되므로 인덱스가 많을수록 항상 좋은 것은 아닙니다. 일반적으로 두 가지 상황에서는 인덱스 구축을 권장하지 않습니다
첫 번째 경우는 테이블 레코드가 상대적으로 작은 경우입니다.
인덱스 구축을 권장하지 않는 경우는 인덱스의 선택도가 낮기 때문입니다. 낮은. 소위 인덱스 선택성이란 테이블 레코드 수(#T)에 대한 고유 인덱스 값(카디널리티라고도 함)의 비율을 말합니다.
인덱스 카테고리
1.
2. 고유 인덱스
3. 기본 키 인덱스
4. 결합 인덱스
MySQL에서 사용되는 인덱스
B+Tree는 MySQL에서 인덱스로 흔히 사용됩니다. 클러스터형 인덱스와 비클러스터형 인덱스에 따라 구현 방식이 다릅니다.
클러스터형 인덱스와 비클러스터형 인덱스
이른바 클러스터형 인덱스는 메인 인덱스 파일과 데이터 파일이 동일한 파일이라는 뜻으로, 클러스터형 인덱스는 주로 Innodb 스토리지 엔진에서 사용됩니다. 이 인덱스 구현에서는 B+Tree의 리프 노드에 있는 데이터가 데이터 자체이고 키가 기본 키입니다. 아래와 같이 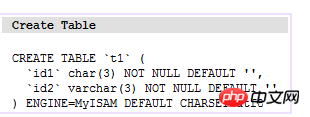
(t1 테이블) 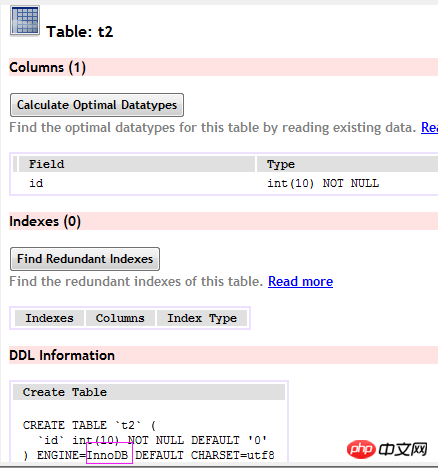
(t2 테이블) 
(데이터베이스에 해당하는 파일)
왜냐하면 InnoDB의 데이터 파일 자체는 기본 키로 집계되어야 하므로 InnoDB에서는 테이블에 기본 키가 있어야 합니다(MyISAM에는 기본 키가 없을 수 있음). 명시적으로 지정하지 않으면 MySQL 시스템은 자동으로 해당 테이블을 고유하게 식별할 수 있는 열을 선택합니다. 해당 열이 없으면 MySQL은 자동으로 InnoDB 테이블의 기본 키로 암시적 필드를 생성합니다. 이 필드의 길이는 6바이트이고 유형은 길다.
MyISAM과 MySQL 데이터베이스의 InnoDB 데이터 스토리지 엔진의 주요 차이점
:
MyISAM은 트랜잭션이 안전하지 않은 반면 InnoDB는 트랜잭션이 안전합니다.
MyISAM 잠금의 세분성은 테이블 수준인 반면 InnoDB는 행 수준 잠금을 지원합니다.
MyISAM은 전체 텍스트 유형 인덱스를 지원하는 반면 InnoDB는 전체 텍스트 인덱스를 지원하지 않습니다.
MyISAM은 상대적으로 단순하므로 효율성 측면에서 InnoDB보다 낫습니다. 소규모 애플리케이션에서는 MyISAM 사용을 고려할 수 있습니다.
MyISAM 테이블은 파일로 저장됩니다. 크로스 플랫폼 데이터 전송에서 MyISAM 스토리지를 사용하면 많은 문제를 줄일 수 있습니다.
InnoDB 테이블은 MyISAM 테이블보다 더 안전합니다. 데이터가 손실되지 않도록 하면서 비트랜잭션 테이블을 트랜잭션 테이블로 전환할 수 있습니다(alter table tablename type=innodb).
애플리케이션 시나리오:
MyISAM은 비트랜잭션 테이블을 관리합니다. 고속 저장 및 검색은 물론 전체 텍스트 검색 기능도 제공합니다. 애플리케이션이 많은 수의 SELECT 쿼리를 수행해야 하는 경우 MyISAM이 더 나은 선택입니다.
InnoDB는 트랜잭션 처리 애플리케이션에 사용되며 ACID 트랜잭션 지원을 포함한 다양한 기능을 갖추고 있습니다. 애플리케이션이 많은 수의 INSERT 또는 UPDATE 작업을 수행해야 하는 경우 다중 사용자 동시 작업의 성능을 향상시킬 수 있는 InnoDB를 사용해야 합니다.
보충
주 메모리 저장
Fetch 프로세스
시스템이 주 메모리를 읽어야 할 때 주소 신호가 주소 버스에 실려 다음으로 전달됩니다. 주 메모리는 주소 신호를 읽은 후 신호를 분석하고 지정된 저장 단위를 찾은 다음 다른 구성 요소가 읽을 수 있도록 이 저장 단위의 데이터를 데이터 버스에 저장합니다.
메인 메모리에 쓰는 과정은 비슷합니다. 시스템은 쓸 단위 주소와 데이터를 각각 주소 버스와 데이터 버스에 배치합니다. 메인 메모리는 두 버스의 내용을 읽고 해당 쓰기 작업을 수행합니다.
여기에서 볼 수 있듯이 메인 메모리 액세스 시간은 액세스 횟수와 선형적으로만 관련됩니다. 기계적 작업이 없기 때문에 두 번 액세스하는 데이터의 "거리"는 시간에 아무런 영향을 미치지 않습니다. 예를 들어 A0을 먼저 가져온 다음 A1을 가져오는 데 소요되는 시간은 A0, D3을 차례로 가져오는 것과 같습니다
디스크 액세스 원리
디스크에서 데이터를 읽어야 하는 경우 시스템은 데이터 논리 주소를 디스크에 전달하고, 디스크의 제어 회로는 주소 지정 논리에 따라 논리 주소를 물리 주소로 변환합니다. 즉, 읽을 데이터가 어느 트랙과 섹터에 있는지 결정합니다. 이 섹터의 데이터를 읽으려면 자기 헤드를 이 섹터 위에 배치해야 합니다. 이를 위해서는 해당 트랙에 맞춰 자기 헤드를 움직여야 하며, 이 과정을 탐색이라고 합니다. 그러면 디스크 회전이 헤드 아래에서 회전됩니다. 이 프로세스에 소요되는 시간을 회전 시간이라고 합니다.
위 내용은 MySQL 인덱스와 구조에 대한 심도있고 자세한 설명입니다. 더 많은 관련 내용은 PHP 중국어 홈페이지(www.php.cn)를 참고해주세요!