
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 인덱스 길이 계산 세부 정보
MySQL의 인덱스 길이 계산 세부 정보

- 黄舟원래의
- 2017-03-01 13:31:022490검색
먼저 질문을 살펴보겠습니다. 테이블 t에는 세 개의 필드 a, b, c가 포함되어 있습니다. 기본값이 비어 있지 않다고 가정하고 이제 결합 인덱스 인덱스(a)를 만듭니다. , b, c) 분석 select * from t where a=1 및 c=1과 select * from t where a=1 및 b=1의 차이점은 무엇입니까?
먼저 테이블을 생성하세요
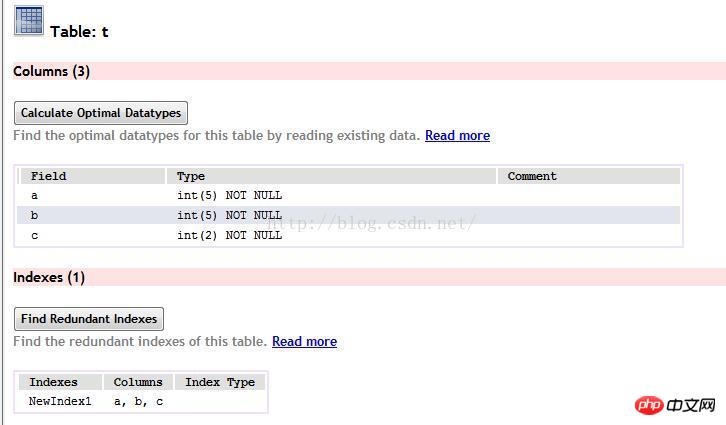
이 두 항목을 실행하세요 각각
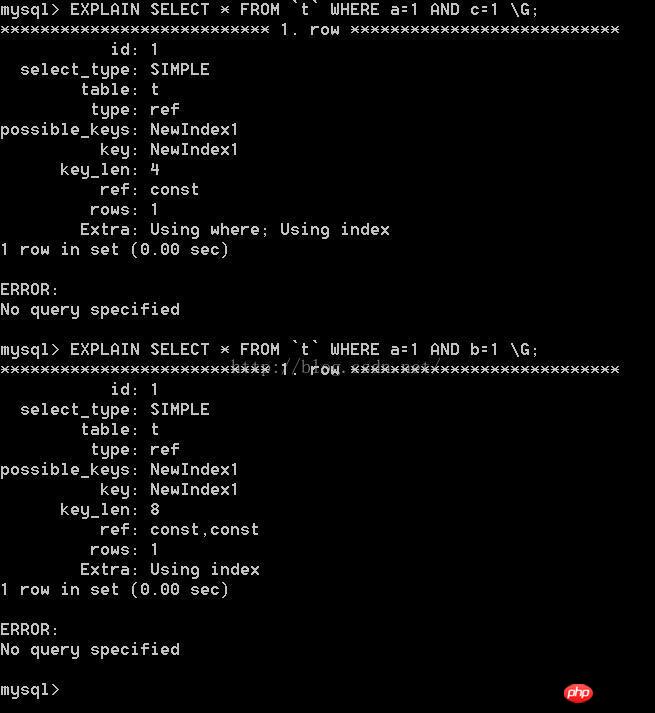
명령문은 두 명령문의 차이점이 주로 key_len에 있음을 발견했습니다. 두 진술이 다른가요?
제가 이해한 바는 다음과 같습니다.
결합된 인덱스를 1차 디렉터리, 2차 디렉터리, index(a,b,c)와 같은 책의 세 번째 수준 디렉터리는 a가 첫 번째 수준 디렉터리이고, b는 첫 번째 수준 디렉터리 아래의 두 번째 수준 디렉터리이고, c는 세 번째 수준 디렉터리입니다. 두 번째 수준 디렉터리 아래의 디렉터리입니다. 디렉터리를 사용하려면 먼저 첫 번째 수준 디렉터리를 제외한 상위 디렉터리를 사용해야 합니다.
그래서
여기서 a=1 및 c=1은 첫 번째 수준 디렉터리만 사용하고 c는 세 번째 수준 디렉터리에 있습니다. 레벨 디렉터리가 있고 두 번째 수준 디렉터리 사용이 없으면 세 번째 수준 디렉터리를 사용할 수 없습니다.
여기서 a=1 및 b=1은 A의 첫 번째 수준 디렉터리와 두 번째 수준 디렉터리만 사용합니다.
따라서 두 번째 쿼리의 key_len이 더 큽니다.
그런데 key_len은 어떻게 계산되나요? 위의 4와 8은 어떻게 계산하나요? 이전에는 크게 신경 쓰지 않았습니다. 기존에는 explain을 통해 SQL 쿼리문의 성능을 분석할 때 select_type, type, available_key, key, ref, Rows, extra에 더 신경을 썼다는 것을 느꼈습니다. key_len의 계산을 명확히 할 필요가 있습니다.
1. 모든 인덱스 필드에 대해 null이 설정되지 않은 경우 1바이트를 추가해야 합니다.
2. 고정 길이 필드, int는 4바이트, date는 3바이트, char(n)은 n자를 차지합니다.
3. varchar(n) 필드에는 n자 + 2바이트가 있습니다.
4. 문자 세트가 다르면 한 문자가 차지하는 바이트 수가 다릅니다. latin1 인코딩에서는 한 문자가 1바이트를 차지하고, gbk 인코딩에서는 한 문자가 2바이트를 차지하고, utf8 인코딩에서는 한 문자가 3바이트를 차지합니다.
그러므로 은
여기서 a=1이고 c라고 결론을 내릴 수 있습니다. = a=1 및 c=1, key_len=4+4=8
이제 또 다른 질문을 해보겠습니다. 다음 데이터 구조를 사용하여 t2 테이블을 생성해 보겠습니다.
name="001" 및 id=1 G인 t2에서 explain select *를 실행합니다.
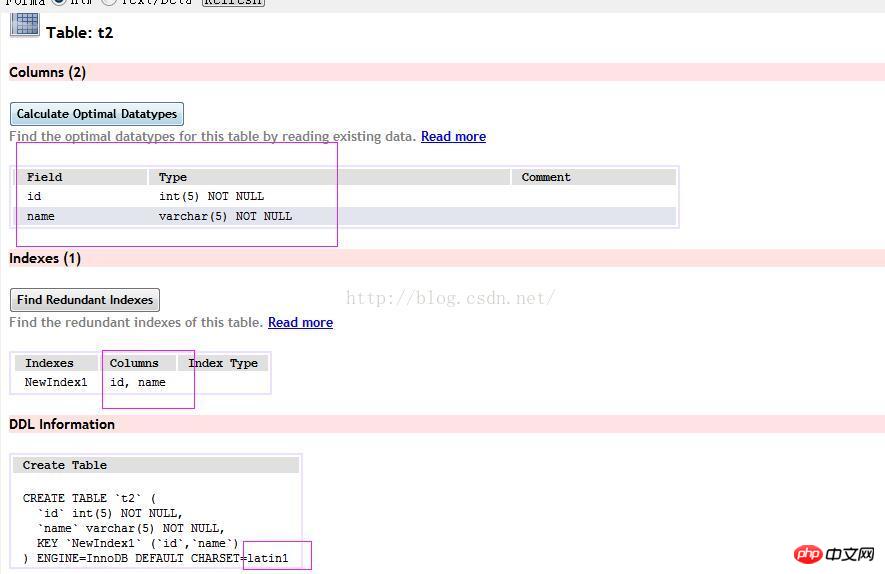
key_len=4+5*1+2=11을 분석합니다. 필드가 null이 아니고 int 유형이 4바이트이고 varchar(5)가 5자 + 2바이트를 차지하기 때문입니다. , latin1로 인코딩된 테이블의 한 문자는 1바이트를 차지하므로 varchar(5)는 7바이트를 차지합니다. 구조는 아래와 같습니다
보충
MySQL에는 쿼리 최적화 프로그램이 있으므로 a=1 및 c=1인 유형의 쿼리에 대해 필드 순서가 영향을 주지 않으면 쿼리 최적화 프로그램이 자동으로 최적화됩니다. where c=1 및 a=1은 where a=1 및 c=1에 최적화되지만 where를 사용하는 것이 좋습니다. a=1 및 c=1, 이해하기 쉽고 쿼리 버퍼링이 용이합니다. 쿼리 버퍼링과 해시키 값은 SQL 문을 기반으로 계산되고 대소문자를 구분하므로 SQL 문 작성 시 동일한 쿼리가 여러 번 캐시되지 않도록 일관성을 유지하도록 노력하세요.
위 내용은 MySQL에서 인덱스 길이를 계산하는 내용입니다. 더 많은 관련 내용은 PHP 중국어 홈페이지(www.php.cn)를 참고해주세요!