
집 >데이터 베이스 >MySQL 튜토리얼 >JDBC--데이터베이스 관리 시스템
JDBC--데이터베이스 관리 시스템

- 黄舟원래의
- 2017-02-11 11:12:012401검색
1-JDBC 개요
서문: 데이터 지속성
지속성: 나중에 사용할 수 있도록 전원이 꺼진 저장 장치에 데이터를 저장합니다. 대부분의 경우, 특히 기업 수준의 응용 프로그램의 경우 데이터 지속성이란 메모리의 데이터를 하드 디스크에 저장하고 "고체화"하는 것을 의미하며 지속성 구현 프로세스는 대부분 다양한 관계형 데이터베이스를 통해 완료됩니다.
지속성의 주요 응용 프로그램은 관계형 데이터베이스의 메모리에 데이터를 저장하는 것입니다. 물론 디스크 파일과 XML 데이터 파일에도 저장할 수 있습니다.
Java의 데이터 저장 기술
Java에서 데이터베이스 액세스 기술은 다음과 같은 범주로 나눌 수 있습니다.
JDBC는 데이터베이스에 직접 액세스
JDO 기술
Hibernate, ibatis 등과 같은 타사 O/R 도구
JDBC JDO, Hibernate 등의 데이터베이스에 대한 Java 액세스의 초석입니다. JDBC를 더 잘 캡슐화합니다.
JDBC 기본
JDBC(Java Database Connectivity)는 특정 데이터베이스 관리 시스템( 데이터베이스에 액세스하는 데 사용되는 표준 Java 클래스 라이브러리(java.sql, javax.sql)를 정의하는 API 세트입니다. 이 클래스 라이브러리를 사용하면 JDBC가 다양한 데이터베이스에 대한 액세스를 쉽게 제공합니다. 접근 방식은 개발자로부터 일부 세부 정보를 보호합니다.
JDBC의 목표는 Java 프로그래머가 JDBC를 사용하여 JDBC 드라이버를 제공하는 모든 데이터베이스 시스템에 연결할 수 있도록 하는 것입니다. 데이터베이스 시스템은 개발 프로세스를 크게 단순화하고 속도를 높입니다.
JDBC 아키텍처
JDBC 인터페이스(API)에는 두 가지 수준이 포함됩니다.
지향적 애플리케이션 API: 애플리케이션 개발자가 사용하는 Java API, 추상 인터페이스입니다(데이터베이스에 연결하고, SQL 문을 실행하고, 결과를 얻습니다).
데이터베이스 지향 API: 개발자가 데이터베이스 드라이버를 개발하는 데 사용되는 Java 드라이버 API입니다.
JDBC는 데이터베이스 작업을 위해 Sun에서 제공하는 인터페이스 세트입니다. Java 프로그래머는 이 인터페이스 세트에 대해서만 프로그래밍하면 됩니다. 다양한 데이터베이스 공급업체는 이 인터페이스 세트에 대해 다양한 구현을 제공해야 합니다. 다양한 구현 모음은 다양한 데이터베이스의 드라이버입니다. ——인터페이스 중심 프로그래밍
JDBC 드라이버 분류.
JDBC 드라이버: JDBC 사양에 따라 다양한 데이터베이스 공급업체에서 제작한 JDBC 구현 클래스의 클래스 라이브러리
JDBC 드라이버에는 총 4가지 유형이 있습니다.
범주 1: JDBC-ODBC 브리지.
두 번째 범주: 일부 로컬 API 및 일부 Java 드라이버.
세 번째 카테고리: JDBC 네트워크 순수 Java 드라이버.
범주 4: 로컬 프로토콜용 순수 Java 드라이버.
세 번째와 네 번째 범주는 순수 Java 드라이버이므로 Java 개발자에게는 최고의 성능과 이식성을 제공합니다. 성능과 기능의.
범주 1: ODBC
데이터베이스에 대한 조기 액세스는 데이터베이스 공급업체가 제공하는 독점 API 호출을 기반으로 했습니다. Microsoft는 Windows 플랫폼에서 통합된 액세스 방법을 제공하기 위해 ODBC(Open Database Connectivity, 개방형 데이터베이스 연결)를 출시하고 ODBC API를 제공했습니다. 사용자는 프로그램에서 ODBC API를 호출하기만 하면 ODBC 드라이버가 이를 변환합니다. 호출은 특정 데이터베이스에 대한 호출 요청이 됩니다. ODBC 기반 응용 프로그램은 데이터베이스 작업을 위해 DBMS(데이터베이스 관리자 시스템)에 의존하지 않으며 모든 데이터베이스 작업은 ODBC 드라이버에 의해 완료됩니다. 해당 DBMS. 즉, FoxPro인지, Access인지
, MYSQL 또는 Oracle 데이터베이스는 ODBC API를 통해 액세스할 수 있습니다. ODBC의 가장 큰 장점은 모든 데이터베이스를 통일된 방식으로 처리할 수 있다는 점이라고 볼 수 있습니다.
JDBC-ODBC 브릿지
JDBC-ODBC 브릿지 자체도 드라이버로 사용할 수 있는 드라이버입니다. ODBC 데이터베이스를 통해 액세스합니다. 이 메커니즘은 실제로 표준 JDBC 호출을 해당 ODBC 호출로 변환하고 ODBC를 통해 데이터베이스에 액세스합니다. 이는 여러 호출 계층이 필요하기 때문에 JDK에서 JDBC-ODBC 브리지를 사용하여 데이터베이스에 액세스하는 것은 비효율적입니다. ODBC 브릿지 구현 클래스(sun.jdbc.odbc.JdbcOdbcDriver)가 제공됩니다.
두 번째 카테고리: 일부는 로컬 API, 일부는 Java 드라이버
이 유형의 JDBC 드라이버는 Java로 작성되며 이 유형을 통해 데이터베이스 제조업체에서 제공하는 로컬 API를 호출합니다. JDBC 드라이버의 데이터베이스 액세스는 ODBC 호출 수를 줄이고 데이터베이스 액세스 효율성을 향상시킵니다. 이러한 방식으로 로컬 JDBC 드라이버와 특정 공급업체의 로컬 API를 고객의 컴퓨터에 설치해야 합니다.
세 번째 범주: JDBC 네트워크 순수 Java 드라이버
이러한 종류의 드라이버는 미들웨어 응용 프로그램 서버를 사용하여 데이터베이스에 액세스합니다. 애플리케이션 서버는 클라이언트가 다른 데이터베이스 서버에 연결할 수 있는 여러 데이터베이스에 대한 게이트웨이 역할을 합니다.
응용 프로그램 서버에는 일반적으로 자체 네트워크 프로토콜이 있습니다. Java 사용자 프로그램은 JDBC 드라이버를 통해 응용 프로그램 서버에 JDBC 호출을 전송하여 데이터베이스에 액세스합니다. 요구.
범주 4: 로컬 프로토콜용 순수 Java 드라이버
대부분의 데이터베이스 공급업체는 이미 클라이언트 프로그램이 네트워크 프로토콜과 직접 통신할 수 있도록 지원합니다. 데이터베이스 통신용.
이 유형의 드라이버는 전적으로 Java로 작성되었습니다. 데이터베이스와 설정된 소켓 연결을 통해 제조업체의 특정 네트워크 프로토콜을 사용하여 JDBC 호출을 JDBC API에 직접 연결된 네트워크 호출로 변환합니다.
JDBC API는 애플리케이션이 데이터베이스에 연결하고, SQL 문을 실행하고, 결과를 반환할 수 있도록 하는 일련의 인터페이스입니다.
2-데이터베이스 연결 가져오기
드라이버 인터페이스
java.sql. 드라이버 인터페이스는 모든 JDBC 드라이버가 구현해야 하는 인터페이스입니다. 이 인터페이스는 데이터베이스 공급업체에 제공되며, 다른 데이터베이스 공급업체는 프로그램에서 드라이버 인터페이스를 구현하는 클래스에 직접 액세스할 필요가 없습니다. 구현.
Oracle 드라이버: oracle.jdbc.driver.OracleDriver
mySql 드라이버: com.mysql.jdbc.Driver
JDBC 드라이버 로드 및 등록
방법 1: JDBC 드라이버를 로드하려면 Class 클래스의 정적 메서드 forName()을 호출하고 이를 전달해야 합니다. 로드할 JDBC 드라이버 클래스 이름
Class.forName(“com.mysql.jdbc.Driver”);
방법 2: DriverManager 클래스 드라이버 관리를 담당하는 드라이버 관리자 클래스입니다
DriverManager.registerDriver(com.mysql.jdbc.Driver);
일반적으로 드라이버 클래스의 인스턴스를 등록하기 위해 DriverManager 클래스의 RegisterDriver() 메서드를 명시적으로 호출할 필요가 없습니다. 왜냐하면 Driver 인터페이스의 드라이버 클래스에는 모두 정적 코드 블록이 포함되어 있기 때문입니다. 코드 블록에서는 DriverManager.registerDriver() 메서드가 호출되어 자체 인스턴스를 등록합니다.
연결 설정(Connection)
DriverManager 클래스의 getConnection() 메서드를 호출하여 데이터베이스에 대한 연결을 설정할 수 있습니다.
사용자, 비밀번호는 "속성 이름 = 속성 값"을 사용하여 데이터베이스에 알릴 수 있습니다.
JDBC URL은 등록된 드라이버, 드라이버 관리자를 식별하는 데 사용됩니다. 데이터베이스에 대한 연결을 설정하려면 이 URL을 통해 드라이버를 수정하세요.
JDBC URL 표준은 콜론으로 구분된 세 부분으로 구성됩니다.
jdbc: 하위 프로토콜: 하위 이름
프로토콜: JDBC URL의 프로토콜은 항상 jdbc입니다.
하위 프로토콜: 하위 프로토콜은 데이터베이스 드라이버를 식별하는 데 사용됩니다.
하위 이름: 데이터베이스를 식별하는 방법입니다. 하위 이름은 다른 하위 프로토콜에 따라 변경될 수 있습니다. 하위 이름을 사용하는 목적은 데이터베이스를 찾는 데 충분한 정보를 제공하는 것입니다. 호스트 이름(서버의 IP 주소에 해당), 포트 번호 및 데이터베이스 이름이 포함됩니다.
일반적으로 사용되는 여러 데이터베이스의 JDBC URL
jdbc:mysql://localhost:3306/test
프로토콜 하위 프로토콜 하위 이름
Oracle 데이터베이스 연결의 경우 다음 형식을 사용합니다.
jdbc:oracle:thin:@localhost:1521:atguigu
SQLServer 데이터베이스 연결의 경우 다음 형식을 사용합니다.
jdbc:microsoft:sqlserver//localhost:1433; DatabaseName=sid
MYSQL 데이터베이스 연결의 경우 , 다음 형식을 사용하십시오. :
jdbc:mysql://localhost:3306/atguigu
문
한 번 연결 객체 Connection을 얻었으나 아직 SQL을 실행할 수 없습니다. SQL을 실행하려면 Connection 객체에서 실행 객체인 명령문을 얻어야 합니다.
Connection connection = getConnection(); Statement state = connection.createStatement(); int n = state.executeUpdate(“insert,update,delete…”);
여기서 n은 테이블에 대한 추가, 삭제 및 수정에 의해 영향을 받는 레코드 수입니다. 쿼리가 실행되면 ResultSet 결과 집합이 생성됩니다. 객체가 반환됩니다.
SQL 주입 공격
SQL 주입은 데이터를 완전히 확인하지 않는 특정 시스템을 사용하는 것입니다. 사용자가 입력한 잘못된 SQL 문 세그먼트 또는 명령(예: SELECT user, 비밀번호 FROM user_table WHERE user='a' OR 1 = ' AND 비밀번호 = ' OR '1' = '1')을 삽입하여 시스템의 악성 행위를 완료하기 위한 SQL 엔진 Java의 경우 SQL 주입을 방지하려면 preparedStatement(Statement에서 확장)를 사용하면 됩니다.
그냥'Statement'를 바꾸십시오.
3-PreparedStatement 사용
데이터 유형 변환 테이블
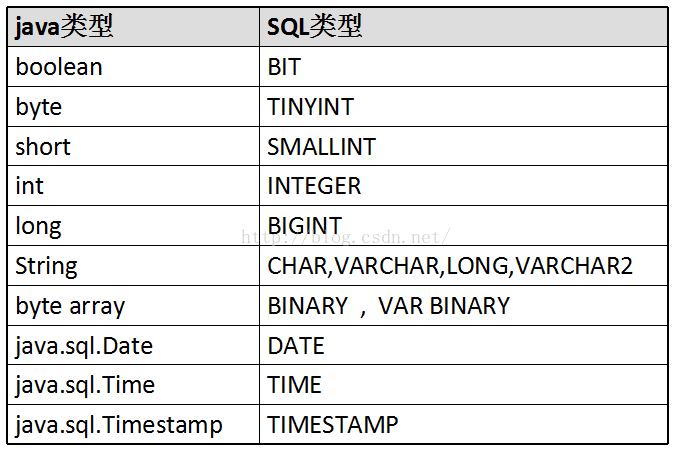
호출 가능 Connection 객체 prepareStatement() 메소드는 preparedStatement 객체를 획득합니다.
PreparedStatement 인터페이스는 미리 컴파일된 SQL 문을 나타내는 Statement의 하위 인터페이스입니다.
PreparedStatement 객체가 나타내는 SQL 문의 매개변수는 물음표(?)로 표시됩니다. 두 개의 매개변수 중 첫 번째 One 매개변수는 설정할 SQL 문에 있는 매개변수의 인덱스(1부터 시작)이고, 두 번째 매개변수는 설정할 SQL 문에 있는 매개변수의 값입니다.
PreparedStatement 대 명령문
코드 가독성 및 유지 관리성.
PreparedStatement는 성능을 극대화할 수 있습니다.
DBServer는 준비된 명령문에 대한 성능 최적화를 제공합니다. 미리 컴파일된 문은 반복적으로 호출될 수 있으므로 DBServer 컴파일러에 의해 컴파일된 후 해당 문의 실행 코드가 캐시됩니다. 그러면 다음 번에 해당 문이 호출될 때 동일한 미리 컴파일된 문이면 컴파일할 필요가 없습니다. , 매개변수가 직접 전달되는 한 컴파일된 문은 실행 코드에서 실행됩니다.
문문문에서는 같은 연산이라도 데이터 내용이 달라도 문 전체가 일치할 수 없고, 문문을 캐싱하는 의미도 없습니다. 사실 어떤 데이터베이스도 일반 명령문의 컴파일된 실행 코드를 캐시하지 않습니다. 이런 방식으로 들어오는 명령문은 실행될 때마다 한 번씩 컴파일되어야 합니다. (구문 검사, 의미 검사, 바이너리 명령으로 변환, 캐싱).
PreparedStatement를 사용하면 SQL 주입을 방지할 수 있습니다.
데이터베이스 및 작업 테이블에 연결하는 단계:
드라이버 등록(한 번만 수행)
연결 설정(Connection)
SQL을 실행할 문장 생성(PreparedStatement)
실행문
실행 관리 결과(ResultSet)
리소스 해제
Connection conn = null;
PreparedStatement st=null;
ResultSet rs = null;
try {
//获得Connection
//创建PreparedStatement
//处理查询结果ResultSet
}catch(Exception e){
e.printStackTrance();
} finally {
//释放资源ResultSet,
// PreparedStatement ,
//Connection
释放ResultSet, PreparedStatement ,Connection。
数据库连接(Connection)是非常稀有的资源,用完后必须马上释放,如果Connection不能及时正确的关闭将导致系统宕机。Connection的使用原则是尽量晚创建,尽量早的释放。
4-使用ResultSet、ResultSetMetaData操作数据表:SELECT
ORM:Object Relation Mapping
表 与 类 对应
表的一行数据 与 类的一个对象对应
表的一列 与类的一个属性对应
ResultSet
通过调用 PreparedStatement 对象的 excuteQuery() 方法创建该对象。
ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商实现。
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行。
ResultSet 接口的常用方法:
boolean next()
getString()
…
处理执行结果(ResultSet)
读取(查询)对应SQL的SELECT,返回查询结果
st = conn.createStatement();
String sql = "select id, name, age,birth from user";
rs = st.executeQuery(sql);
while (rs.next()) {
System.out.print(rs.getInt("id") + " \t ");
System.out.print(rs.getString("name") + " \t");
System.out.print(rs.getInt("age") + " \t");
System.out.print(rs.getDate(“birth") + " \t ");
System.out.println();}
}
关于Result的说明
1. 查询需要调用 Statement 的 executeQuery(sql) 方法,查询结果是一个 ResultSet 对象
2. 关于 ResultSet:代表结果集
ResultSet: 结果集. 封装了使用 JDBC 进行查询的结果. 调用 Statement 对象的 executeQuery(sql) 可以得到结果集.
ResultSet 返回的实际上就是一张数据表. 有一个指针指向数据表的第一条记录的前面.
3.可以调用 next() 方法检测下一行是否有效. 若有效该方法返回 true, 且指针下移. 相当于Iterator 对象的 hasNext() 和 next() 方法的结合体
4.当指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值.
例如: getInt(1), getString("name")
5.ResultSet 当然也需要进行关闭.
MySQL BLOB 类型
MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。
MySQL的四种BLOB类型(除了在存储的最大信息量上不同外,他们是等同的)。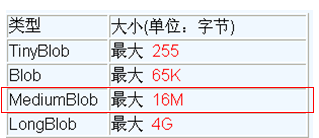
实际使用中根据需要存入的数据大小定义不同的BLOB类型。
需要注意的是:如果存储的文件过大,数据库的性能会下降。
ResultSetMetaData 类
可用于获取关于 ResultSet 对象中列的类型和属性信息的对象。
ResultSetMetaData meta = rs.getMetaData();
getColumnName(int column):获取指定列的名称
getColumnLabel(int column):获取指定列的别名
getColumnCount():返回当前 ResultSet 对象中的列数。
getColumnTypeName(int column):检索指定列的数据库特定的类型名称。
getColumnDisplaySize(int column):指示指定列的最大标准宽度,以字符为单位。
isNullable(int column):指示指定列中的值是否可以为 null。
isAutoIncrement(int column):指示是否自动为指定列进行编号,这样这些列仍然是只读的。
JDBC API 小结
java.sql.DriverManager는 드라이버를 로드하고 데이터베이스 연결을 얻는 데 사용됩니다.
java.sql.Connection은 지정된 데이터베이스에 대한 연결을 완료합니다.
java.sql.Statement는 지정된 연결에서 SQL 실행 문을 위한 컨테이너 역할을 합니다. 여기에는 두 가지 중요한 하위 유형이 포함되어 있습니다.
Java.sql.PreparedSatement는 미리 컴파일된 SQL 문을 실행하는 데 사용됩니다.
Java.sql.CallableStatement는 데이터베이스의 저장 프로시저에 대한 호출을 실행하는 데 사용됩니다.
java.sql.ResultSet은 주어진 명령문에 대한 결과를 얻는 방법입니다.
두 가지 생각
인터페이스 지향 프로그래밍 아이디어
ORM 아이디어: SQL은 열 이름과 테이블 속성 이름을 조합하여 작성해야 하며 별칭에 주의해야 합니다.
두 가지 기술
JDBC 메타데이터: ResultSetMetaData;
PropertyUtils: Class.newInstance()를 통해 객체를 생성하고, 쿼리된 열 값을 이 클래스를 통해 생성된 객체로 어셈블합니다.
5-Batch 처리
JDBC 일괄 처리 명령문 처리 속도를 향상시킵니다.
기록을 일괄 삽입하거나 업데이트해야 할 때. Java의 일괄 업데이트 메커니즘을 사용하면 일괄 처리를 위해 한 번에 여러 명령문을 데이터베이스에 제출할 수 있습니다. 일반적으로 개별 제출 처리보다 효율적입니다.
JDBC 일괄 처리 문에는 다음 두 가지 방법이 포함됩니다.
addBatch(String): SQL 추가 일괄 처리가 필요한 명령문 또는 매개변수
executeBatch(): 일괄 처리 명령문 실행; clearBatch(): 캐시된 데이터 지우기
일반적으로 두 가지가 발생합니다. SQL 문 일괄 실행 상황:
여러 SQL 문 일괄 처리 하나의 SQL 문 일괄 매개변수 전송
6-Database Connection Pool
데이터베이스 기반 웹 프로그램을 개발할 때 기존 모델은 기본적으로 다음 단계를 따릅니다.
메인 프로그램에서 데이터베이스 연결 설정(서블릿, 빈 등)
SQL 작업 수행
데이터베이스 연결 끊기
이 개발 모델의 문제점:
매번 DriverManager를 사용하여 일반 JDBC 데이터베이스 연결을 얻습니다. 데이터베이스에 대한 연결을 설정하려면 연결을 메모리에 로드한 다음 사용자 이름과 비밀번호를 확인해야 합니다(0.05~1초 소요). 데이터베이스 연결이 필요한 경우 데이터베이스에 연결을 요청한 후 실행이 완료된 후 연결을 끊습니다. 이 접근 방식은 많은 리소스와 시간을 소비합니다. 데이터베이스 연결 리소스는 잘 재사용되지 않습니다. 동시에 수백 또는 수천 명의 사용자가 온라인에 있는 경우 빈번한 데이터베이스 연결 작업은 많은 시스템 리소스를 차지하며 심지어 서버 충돌을 일으킬 수도 있습니다. 모든 데이터베이스 연결은 사용 후 연결을 끊어야 합니다. 그렇지 않으면 프로그램이 이상으로 인해 종료되지 않으면 데이터베이스 시스템에 메모리 누수가 발생하고 결국 데이터베이스가 다시 시작되는 원인이 됩니다. 이러한 개발은 생성되는 연결 개체 수를 제어할 수 없으며, 연결이 너무 많으면 메모리 누수 및 서버 충돌이 발생할 수도 있습니다.
데이터베이스 연결 풀(Connection Pool)
기존 개발에서 데이터베이스 연결 문제를 해결하기 위해 데이터베이스 연결 풀 기술을 사용할 수 있습니다.
데이터베이스 연결 풀의 기본 아이디어는 데이터베이스 연결을 위한 "버퍼 풀"을 구축하는 것입니다. 미리 버퍼 풀에 일정한 수의 연결을 넣어두세요. 데이터베이스 연결을 설정해야 할 때 "버퍼 풀"에서 하나만 꺼내어 사용 후 다시 넣어두면 됩니다.
데이터베이스 연결 풀은 데이터베이스 연결 할당, 관리 및 해제를 담당합니다. 이를 통해 애플리케이션은 새 데이터베이스 연결을 설정하는 대신 기존 데이터베이스 연결을 재사용할 수 있습니다.
데이터베이스 연결 풀은 초기화 중에 특정 수의 데이터베이스 연결을 생성하고 이를 연결 풀에 넣습니다. 이러한 데이터베이스 연결 수는 최소 데이터베이스 연결 수에 따라 설정됩니다. 이러한 데이터베이스 연결의 사용 여부에 관계없이 연결 풀에는 항상 최소한 이만큼의 연결이 보장됩니다. 연결 풀의 최대 데이터베이스 연결 수는 연결 풀이 차지할 수 있는 최대 연결 수를 제한합니다. 연결 풀에서 응용 프로그램이 요청한 연결 수가 최대 연결 수를 초과하면 해당 요청이 데이터베이스에 추가됩니다. 대기 대기열.
데이터베이스 연결 풀링 작동 방식
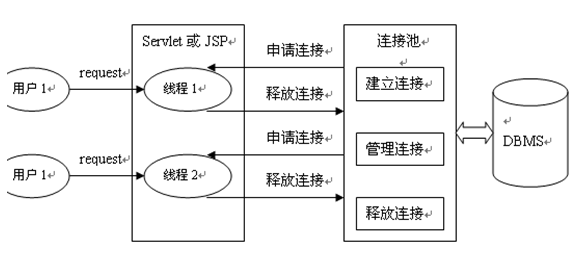
데이터베이스 연결 풀링 기술의 장점
리소스 재사용
데이터베이스 연결을 재사용할 수 있으므로 잦은 연결 생성 및 해제로 인해 많은 성능 오버헤드 발생 방지됩니다. 한편, 시스템 소비 감소를 기반으로 시스템 운영 환경의 안정성도 향상됩니다.
빠른 시스템 응답 속도
데이터베이스 연결 풀 초기화 과정에서 여러 개의 데이터베이스가 생성되는 경우가 많다. 연결은 나중에 사용할 수 있도록 연결 풀에 배치됩니다. 이 시점에서 연결 초기화 작업이 완료되었습니다. 비즈니스 요청 처리의 경우 기존 사용 가능한 연결을 직접 사용하여 데이터베이스 연결 초기화 및 해제 프로세스의 시간 오버 헤드를 방지하여 시스템 응답 시간을 줄입니다.
새로운 리소스 할당 방법
여러 애플리케이션이 동일한 데이터베이스를 공유하는 시스템의 경우 다음 구성을 통해 다음을 수행할 수 있습니다. 데이터베이스 연결 풀에서는 특정 애플리케이션이 모든 데이터베이스 리소스를 독점하는 것을 방지하기 위해 특정 애플리케이션에 사용 가능한 최대 데이터베이스 연결 수가 제한됩니다.
데이터베이스 연결 누출을 방지하기 위한 균일한 연결 관리
비교적 완전한 데이터베이스 연결 풀 구현에서는 다음을 수행할 수 있습니다. Pre-occupancy timeout 설정으로 점유된 연결을 강제로 재활용하여 일반적인 데이터베이스 연결 작업에서 발생할 수 있는 리소스 누출을 방지합니다.
두 개의 오픈 소스 데이터베이스 연결 풀:
JDBC의 데이터베이스 연결 풀은 javax.sql.DataSource로 표현되며 일반적으로 사용되는 인터페이스입니다. server.(Weblogic, WebSphere, Tomcat)이 구현을 제공하고 일부 오픈 소스 조직은
구현을 제공합니다.
DBCP 데이터베이스 연결 풀
C3P0 데이터베이스 연결 풀
DataSource는 일반적으로 데이터 소스라고 합니다. 연결 풀과 연결 풀 관리라는 두 부분으로 구성됩니다.
DataSource는 DriverManager를 대체하여 Connection을 얻는 데 사용되며, 이는 빠르고 데이터베이스 액세스 속도를 크게 향상시킬 수 있습니다.
DBCP 데이터 소스
DBCP는 Apache Software Foundation의 오픈 소스 연결 풀 구현입니다. 연결 풀은 Common- pool 이 연결 풀 구현을 사용하려면 다음 두 개의 jar 파일을 시스템에 추가해야 합니다.
Commons-dbcp.jar: 연결 풀 구현
Commons-pool.jar: 연결 풀 구현을 위한 종속성 라이브러리
Tomcat의 연결 풀은 이 연결 풀을 사용하여 구현됩니다. 데이터베이스 연결 풀은 애플리케이션 서버와 통합되거나 애플리케이션에서 독립적으로 사용될 수 있습니다.
DBCP 데이터 소스 사용 예
데이터 소스는 데이터베이스 연결과 다르며, 여러 개의 데이터 소스를 생성할 필요가 없으며, 따라서 전체 애플리케이션에는 하나의 데이터 소스만 있으면 충분합니다.
데이터베이스 액세스가 종료되면 프로그램은 여전히 이전과 같이 데이터베이스 연결을 닫습니다. conn.close() 그러나 위 코드는 데이터베이스의 물리적 연결을 닫지 않고 해제하고 반환만 합니다. 데이터베이스 연결 데이터베이스 연결 풀이 제공됩니다.
7-데이터베이스 트랜잭션
트랜잭션: 데이터를 한 상태에서 다른 상태로 변환하는 논리적 연산 단위 집합입니다.
트랜잭션 처리(트랜잭션 작업): 모든 트랜잭션이 작업 단위로 실행되는지 확인합니다. 오류가 발생하더라도 이 실행 방법은 변경할 수 없습니다. 트랜잭션에서 여러 작업이 수행되면 모든 트랜잭션이 커밋되고 수정 사항이 영구적으로 저장되거나 데이터베이스 관리 시스템이 모든 수정 사항을 취소하고 전체 트랜잭션이 초기 상태로 롤백됩니다.
데이터베이스의 데이터 일관성을 보장하려면 데이터 조작이 논리 단위의 개별 그룹에서 수행되어야 합니다. 모든 작업이 완료되면 데이터의 일관성이 유지될 수 있으며, 일부 작업이 실패하면 전체 트랜잭션을 오류로 간주하고 시작점부터 모든 작업을 시작 상태로 롤백해야 합니다.
트랜잭션의 ACID(산성) 속성
원자성
원자성은 트랜잭션이 분할할 수 없는 작업 단위이며 트랜잭션의 작업이 모두 발생하거나 전혀 발생하지 않음을 의미합니다.
2. 일관성
트랜잭션은 데이터베이스를 한 일관성 상태에서 다른 일관성 상태로 변경해야 합니다.
3. 격리
트랜잭션의 격리는 트랜잭션의 실행이 다른 트랜잭션, 즉 트랜잭션 내의 운영 및 사용에 의해 방해받을 수 없음을 의미합니다. transaction 데이터는 다른 동시 트랜잭션과 격리되며, 동시에 실행되는 트랜잭션은 서로 간섭할 수 없습니다.
4. 내구성
내구성이란 일단 트랜잭션이 제출되면 데이터베이스의 데이터 변경 사항이 후속 작업 및 데이터베이스 오류에 대해 영구적임을 의미합니다. 아무런 영향을 주지 않습니다
JDBC 트랜잭션 처리
연결 개체가 생성되면 트랜잭션이 기본적으로 자동으로 커밋됩니다. SQL 문이 실행될 때마다 실행이 성공하면 자동으로 데이터베이스에 제출되고 롤백될 수 없습니다.
여러 개의 SQL 문을 하나의 트랜잭션으로 실행하려면:
Connection 객체의 setAutoCommit(false)를 호출합니다. ; 자동 커밋 트랜잭션을 취소하려면
모든 SQL 문이 성공적으로 실행된 후 commit() 메서드를 호출하여 트랜잭션을 커밋합니다.
예외가 발생하는 경우 Rollback(); 메소드를 호출하여 트랜잭션을 롤백합니다
이때 연결이 닫히지 않은 경우 자동 제출 상태를 복원해야 합니다
제출 후 데이터 상태
데이터 변경 사항이 데이터베이스에 저장되었습니다.
변경 전 데이터가 손실되었습니다.
모든 사용자가 결과를 볼 수 있습니다.
잠금이 해제되고 다른 사용자가 관련 데이터를 조작할 수 있습니다.
8-DBUtils 도구 클래스
데이터베이스 운영을 위해 일반적으로 사용되는 JDBC 클래스 및 메소드 모음 함께하면 DBUtils입니다.
BeanHandler: 결과 집합을 JavaBean으로 변환
BeanBeanListHandler: 결과 변환 set Bean 컬렉션으로 변환
MapHandler: 결과 세트를 맵으로 변환
MapMapListHandler: 결과 세트를 맵 목록으로 변환
ScalarHandler: 결과 변환 Map으로 설정 일반적으로 문자열 또는 기타 8가지 기본 데이터 유형을 참조하는 데이터 유형을 반환합니다.
위는 JDBC 데이터베이스입니다. 관리 시스템 콘텐츠, 더 많은 관련 콘텐츠를 보려면 PHP 중국어 웹사이트(www.php.cn)를 주목하세요!