
1024 프레임과 거의 100% 정확도를 지원하는 NVIDIA 'LongVILA”가 긴 비디오 개발 시작

- 王林원래의
- 2024-08-21 16:35:04678검색
Désormais, Long Context Visual Language Model (VLM) dispose d'une nouvelle solution full-stack - LongVILA, qui intègre le système, la formation de modèles et le développement d'ensembles de données.

문서 주소: https://arxiv.org/pdf/2408.10188 코드 주소: https://github.com/NVlabs/VILA/blob/main/LongVILA.md -
논문 제목: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
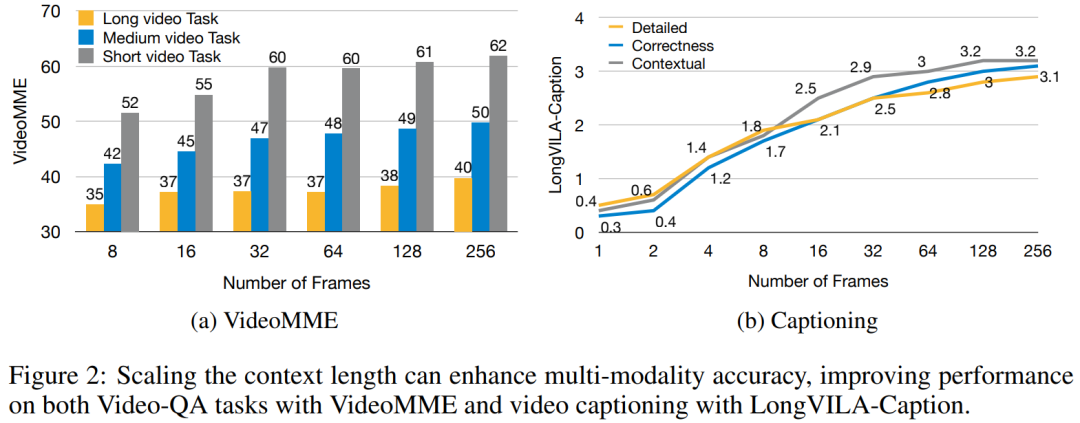

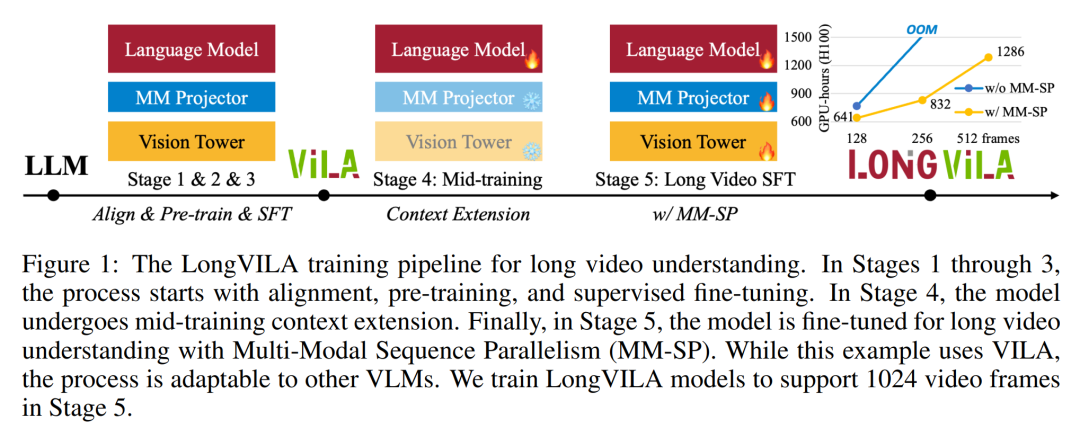
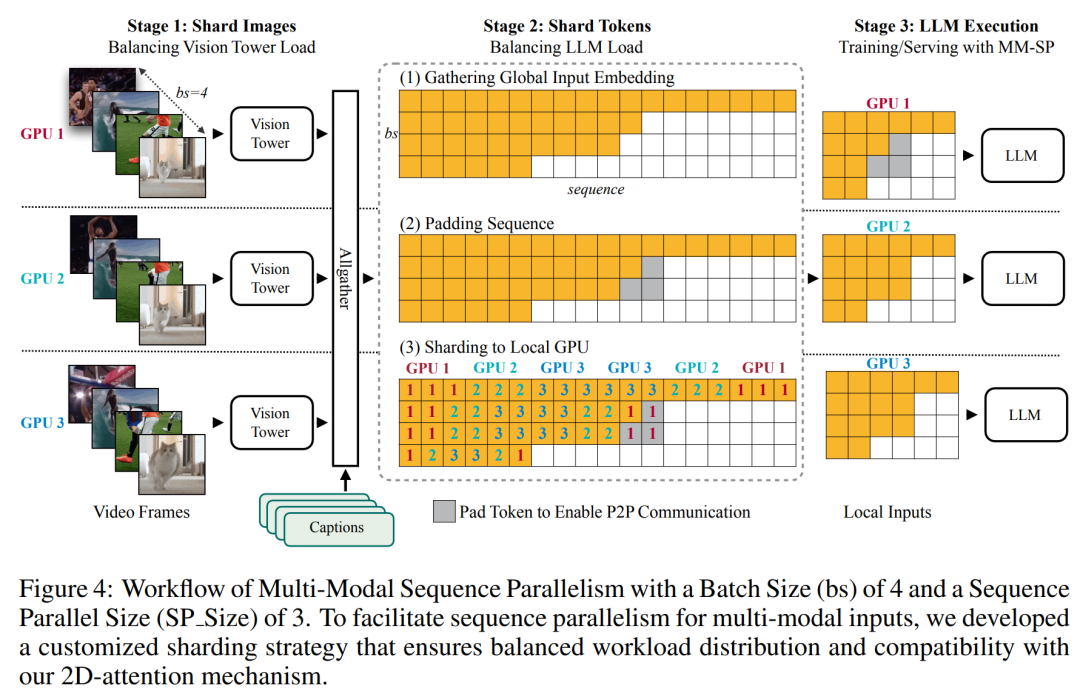

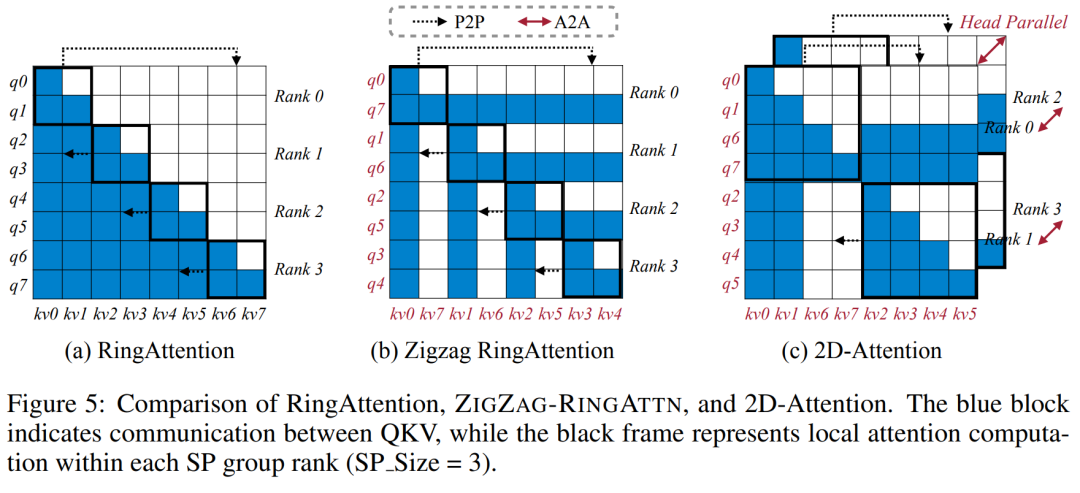
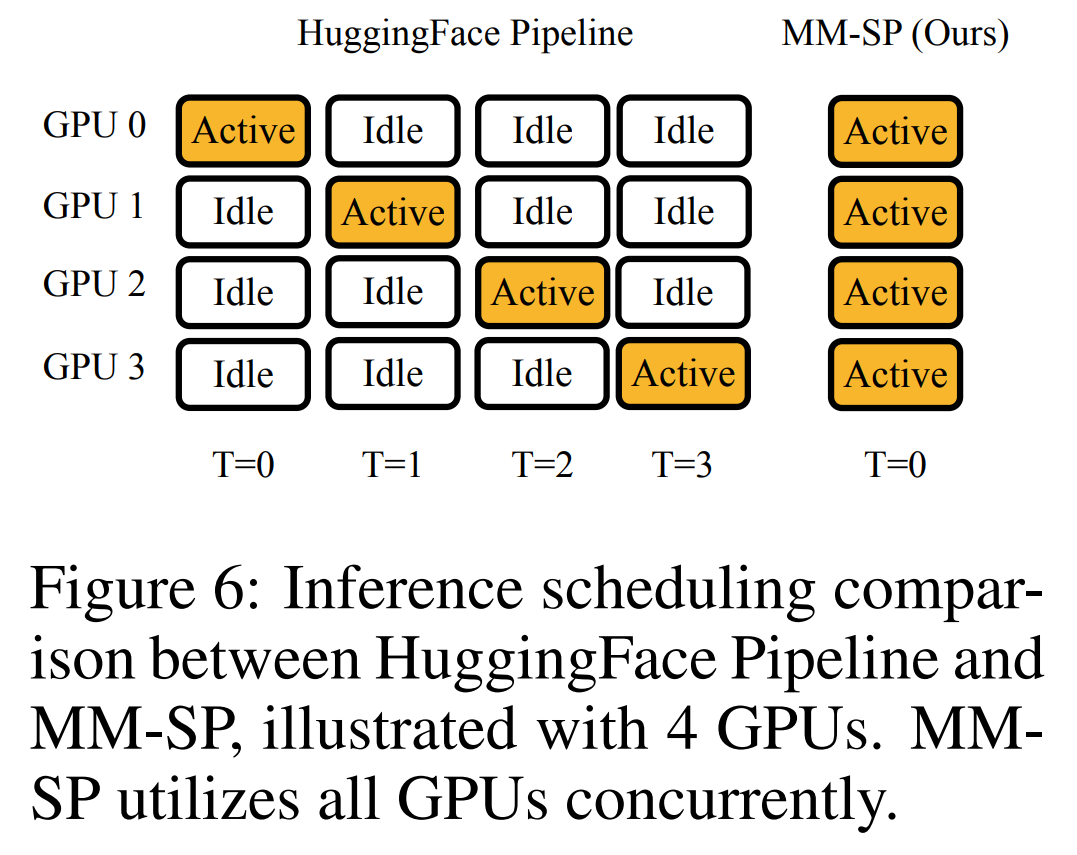
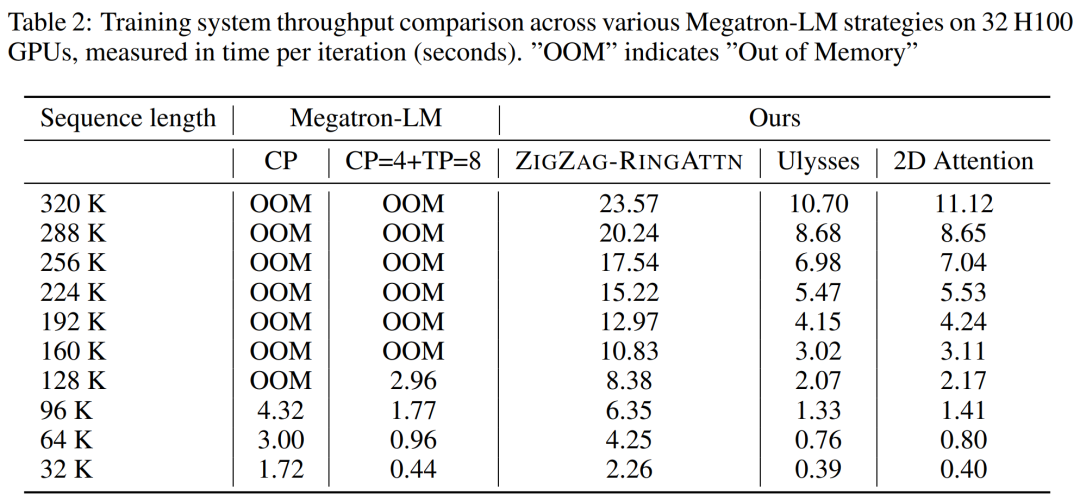
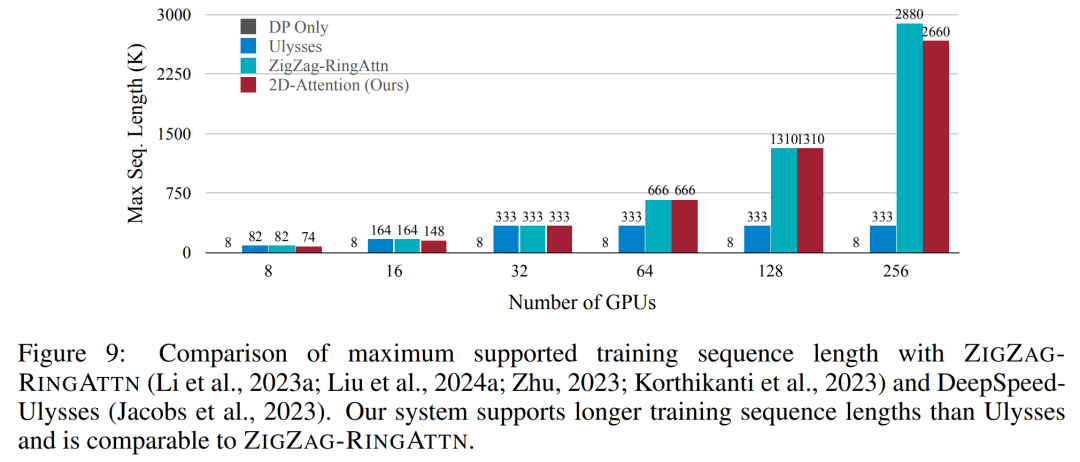

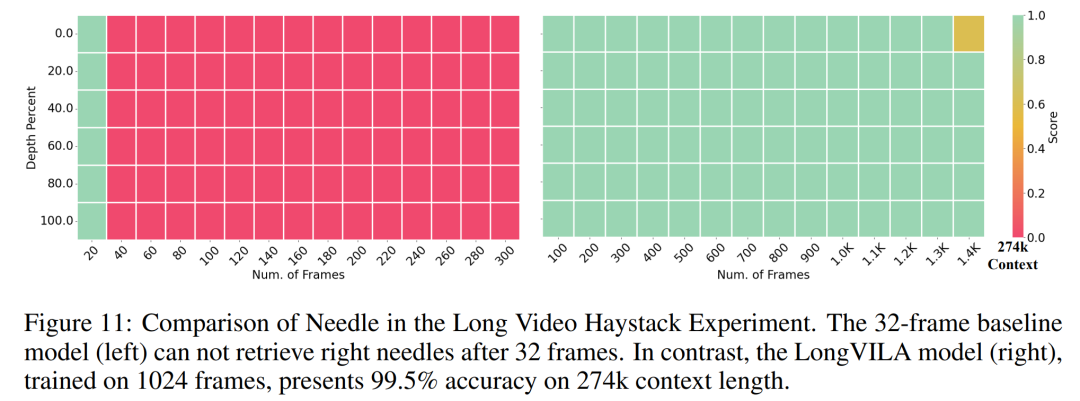
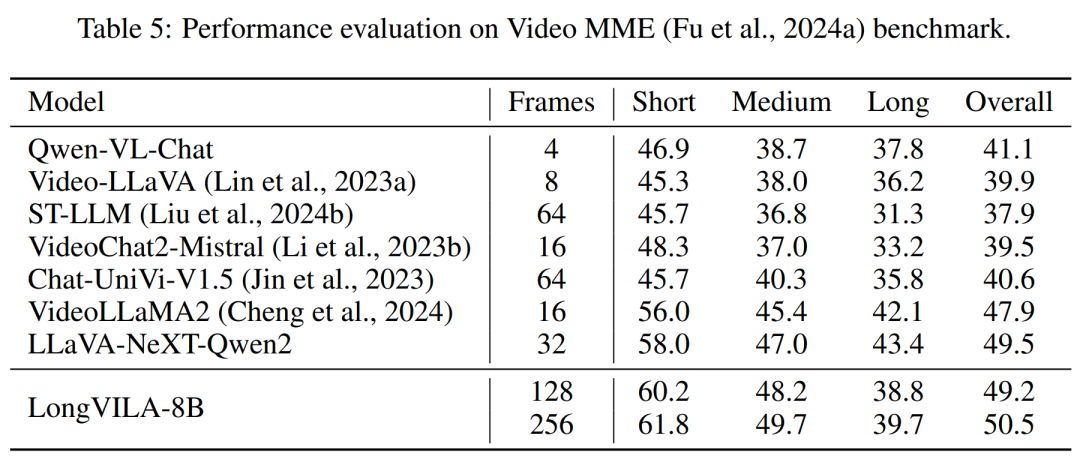
위 내용은 1024 프레임과 거의 100% 정확도를 지원하는 NVIDIA 'LongVILA”가 긴 비디오 개발 시작의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.