
로봇 전략 학습을 위한 Game Changer? 버클리는 바디 트랜스포머(Body Transformer)를 제안합니다

- 王林원래의
- 2024-08-19 16:35:031109검색
지난 몇 년 동안 Transformer 아키텍처는 큰 성공을 거두었으며 시각적 작업 처리에 능숙한 ViT(Vision Transformer)와 같은 수많은 변형도 탄생했습니다. 본 글에서 소개하는 BoT(Body Transformer)는 로봇 전략 학습에 매우 적합한 Transformer 변종이다.
우리는 물리적 에이전트가 행동의 수정 및 안정화를 수행할 때 느끼는 외부 자극의 위치에 따라 공간적 반응을 제공하는 경우가 많다는 것을 알고 있습니다. 예를 들어, 이러한 자극에 대한 인간의 반응 회로는 척추 신경 회로 수준에 위치하며 특히 단일 작동기의 반응을 담당합니다. 교정적인 로컬 실행은 효율적인 움직임의 주요 요소이며, 이는 로봇에게도 특히 중요합니다.
그러나 이전 학습 아키텍처는 일반적으로 센서와 액추에이터 간의 공간적 상관관계를 확립하지 못했습니다. 로봇 전략은 주로 자연어 및 컴퓨터 비전용으로 개발된 아키텍처를 사용한다는 점을 고려할 때 로봇 본체의 구조를 효과적으로 활용하지 못하는 경우가 많습니다.
그러나 Transformer는 이와 관련하여 여전히 큰 잠재력을 가지고 있습니다. 연구에 따르면 Transformer는 긴 시퀀스 종속성을 효과적으로 처리하고 많은 양의 데이터를 쉽게 흡수할 수 있는 것으로 나타났습니다. Transformer 아키텍처는 원래 구조화되지 않은 NLP(자연어 처리) 작업을 위해 개발되었습니다. 이러한 작업(예: 언어 번역)에서 입력 시퀀스는 일반적으로 출력 시퀀스에 매핑됩니다.
이러한 관찰을 바탕으로 버클리 캘리포니아 대학의 Pieter Abbeel 교수가 이끄는 팀은 로봇 본체의 센서와 액추에이터의 공간적 위치에 주의를 더하는 BoT(Body Transformer)를 제안했습니다.

논문 제목: Body Transformer: 정책 학습을 위한 로봇 구현 활용
논문 주소: https://arxiv.org/pdf/2408.06316v1
프로젝트 웹사이트: https://sferrazza .cc/bot_site
코드 주소: https://github.com/carlosferrazza/BodyTransformer
구체적으로 BoT는 로봇 몸체를 그래프로 모델링하고 그 안에 있는 노드가 센서와 액추에이터입니다. 그런 다음 Attention 레이어에 매우 희박한 마스크를 사용하여 각 노드가 바로 이웃이 아닌 다른 부분에 주의를 기울이는 것을 방지합니다. 구조적으로 동일한 여러 BoT 레이어를 연결하면 아키텍처의 표현 기능을 손상시키지 않고 전체 그래프의 정보를 통합할 수 있습니다. BoT는 모방 학습과 강화 학습 모두에서 우수한 성능을 발휘하며 일부에서는 전략 학습의 "게임 체인저"로 간주되기도 합니다.
Body Transformer
로봇 학습 전략이 원래의 Transformer 아키텍처를 백본으로 사용하는 경우 로봇 신체 구조에서 제공하는 유용한 정보는 일반적으로 무시됩니다. 그러나 실제로 이 구조적 정보는 Transformer에 더 강력한 유도 바이어스를 제공할 수 있습니다. 팀은 원래 아키텍처의 표현 기능을 유지하면서 이 정보를 활용했습니다.
BoT(Body Transformer) 아키텍처는 마스크된 주의를 기반으로 합니다. 이 아키텍처의 각 계층에서 노드는 자신과 바로 이웃에 대한 정보만 볼 수 있습니다. 이러한 방식으로 정보는 그래프의 구조에 따라 흐르며, 업스트림 레이어는 로컬 정보를 기반으로 추론을 수행하고 다운스트림 레이어는 더 먼 노드에서 더 많은 글로벌 정보를 수집합니다.
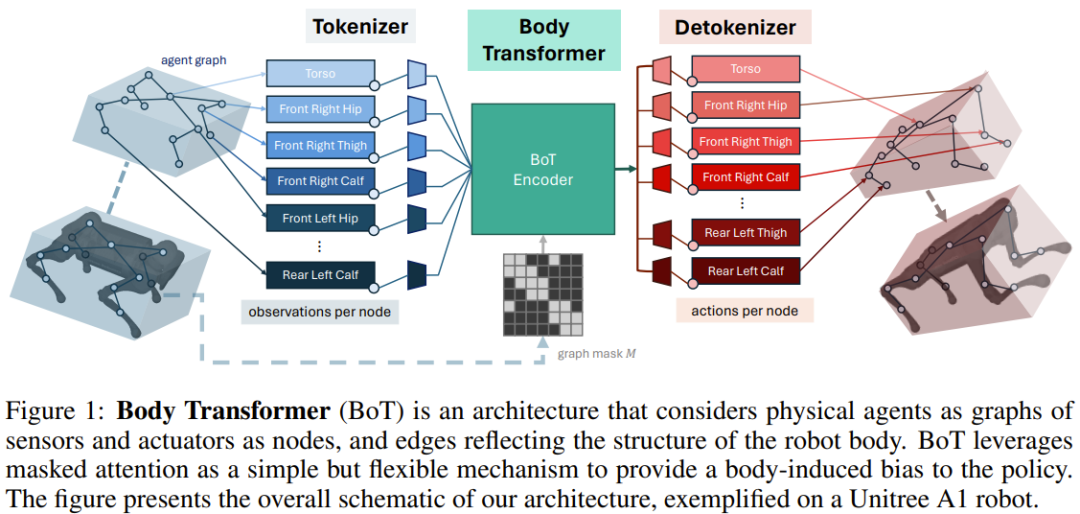
그림 1에 표시된 것처럼 BoT 아키텍처에는 다음 구성 요소가 포함되어 있습니다.
1.tokenizer: 센서 입력을 해당 노드 임베딩에 투영합니다.
2.Transformer 인코더: 입력 임베딩을 처리하고 출력을 생성합니다. 동일한 차원 기능
3.detokenizer: Detokenization, 즉 기능을 동작(또는 강화 학습 비평 훈련에 사용되는 값)으로 디코딩합니다.
tokenizer
팀은 관찰 벡터를 로컬 관찰로 구성된 그래프에 매핑하기로 결정했습니다.
실제로는 로봇 본체의 루트 요소에 전역 수량을 할당하고 해당 팔다리를 나타내는 노드에 지역 수량을 할당합니다. 이 할당은 이전 GNN 방법과 유사합니다.
그런 다음 선형 레이어를 사용하여 로컬 상태 벡터를 임베딩 벡터에 투영합니다. 각 노드의 상태는 노드별 학습 가능한 선형 투영에 입력되어 n개의 임베딩 시퀀스가 생성됩니다. 여기서 n은 노드 수(또는 시퀀스 길이)를 나타냅니다. 이는 일반적으로 다중 작업 강화 학습에서 다양한 수의 노드를 처리하기 위해 단일 공유 학습 가능한 선형 투영만 사용하는 이전 작업과 다릅니다.
BoT 인코더
팀에서 사용하는 백본 네트워크는 표준 다층 Transformer 인코더이며 이 아키텍처에는 두 가지 변형이 있습니다.
BoT-Hard: 그래프의 구조를 반영하는 바이너리 마스크를 사용하여 각 레이어를 마스크합니다. 구체적으로 마스크를 구성하는 방식은 M = I_n + A입니다. 여기서 I_n은 n차원 단위 행렬이고 A는 그래프에 해당하는 인접 행렬입니다. 그림 2는 그 예를 보여줍니다. 이를 통해 각 노드는 자신과 인접한 이웃만 볼 수 있으며 문제에 상당한 희박성을 도입할 수 있습니다. 이는 특히 계산 비용 관점에서 매력적입니다.
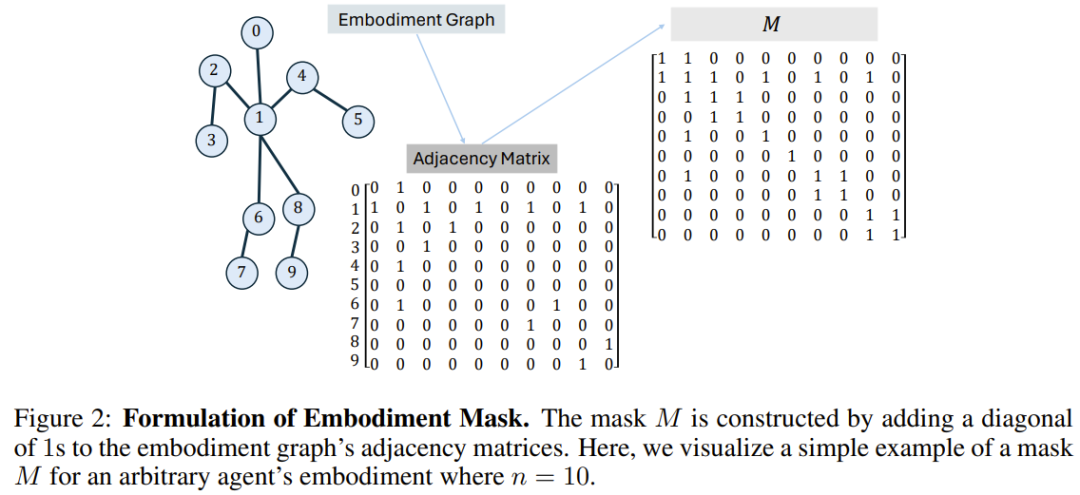
BoT-Mix: 마스크된 주의가 있는 레이어(예: BoT-Hard)와 마스크되지 않은 주의가 있는 레이어를 섞습니다.
detokenizer
Transformer 인코더에 의해 출력된 특징은 선형 레이어에 공급된 다음 노드의 팔다리와 관련된 작업에 투영됩니다. 이러한 작업은 해당 액추에이터와 팔다리의 근접성을 기반으로 할당됩니다. . 다시 말하지만, 이러한 학습 가능한 선형 투영 레이어는 각 노드마다 별개입니다. 강화 학습 설정에서 BoT가 중요한 아키텍처로 사용되는 경우 detokenizer는 동작이 아닌 값을 출력하고 신체 부위에 대한 평균을 구합니다.
실험
팀은 모방 학습 및 강화 학습 설정에서 BoT의 성능을 평가했습니다. 그들은 그림 1과 동일한 구조를 유지했으며 인코더의 효율성을 확인하기 위해 BoT 인코더를 다양한 기본 아키텍처로 교체했습니다.
이 실험의 목표는 다음 질문에 답하는 것입니다.
가려진 주의가 모방 학습의 성능과 일반화 능력을 향상시킬 수 있습니까?
원래 Transformer 아키텍처와 비교하여 BoT가 긍정적인 확장 추세를 보일 수 있습니까?
BoT는 강화 학습 프레임워크와 호환되며 성능을 극대화하기 위한 합리적인 설계 선택은 무엇입니까?
BoT 전략을 실제 로봇 작업에 적용할 수 있나요?
가면주의의 계산상의 이점은 무엇입니까?
모방 학습 실험
팀은 MoCapAct 데이터 세트를 통해 정의된 신체 추적 작업에 대한 BoT 아키텍처의 모방 학습 성능을 평가했습니다.
결과는 그림 3a에 나와 있으며 BoT는 항상 MLP 및 Transformer 기준보다 더 나은 성능을 발휘하는 것을 볼 수 있습니다. 이러한 아키텍처에 비해 BoT의 장점은 보이지 않는 검증 비디오 클립에서 더욱 증가할 것이라는 점은 주목할 가치가 있습니다. 이는 신체 인식 유도 바이어스가 향상된 일반화 기능으로 이어질 수 있음을 입증합니다.
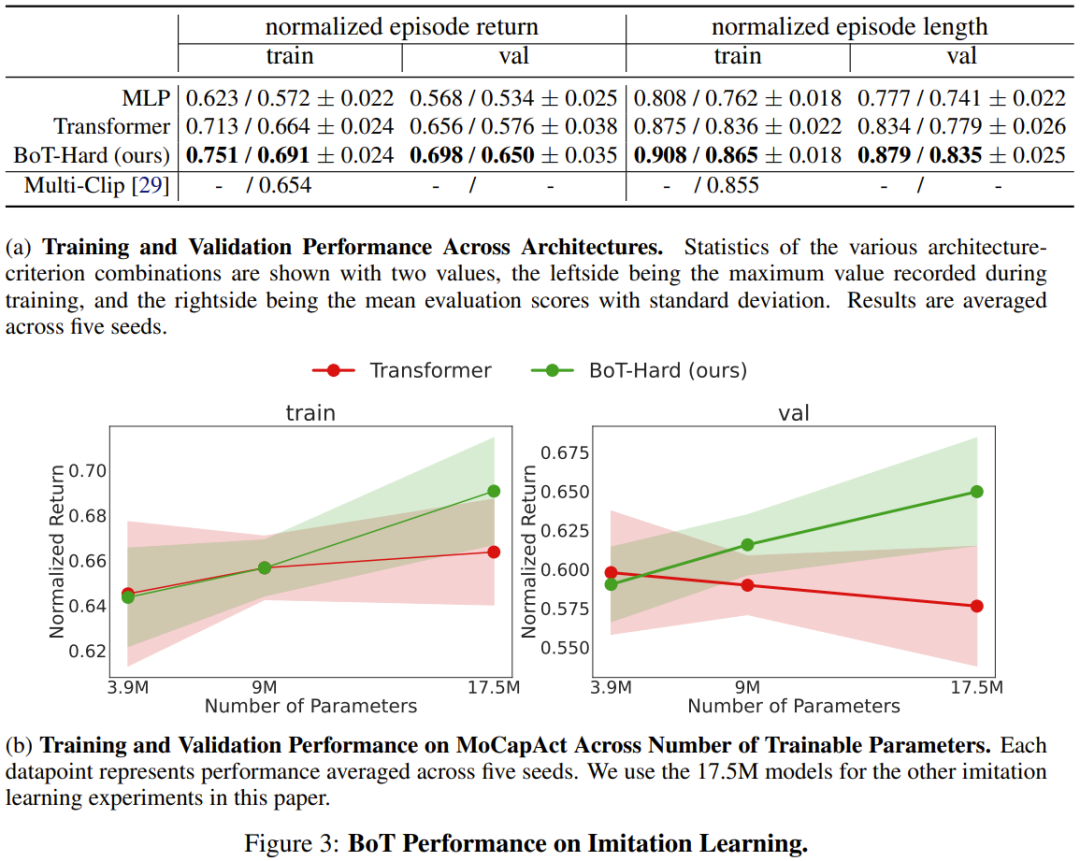
그리고 그림 3b는 BoT-Hard가 Transformer 기준과 비교하여 우수한 확장성을 가지고 있음을 보여줍니다. 훈련 및 검증 비디오 클립의 성능은 훈련 가능한 매개변수 수가 증가함에 따라 증가하며, 이는 BoT-Hard가 더 나은 경향이 있음을 보여줍니다. 훈련 데이터에 과적합이 발생하며 이러한 과적합은 실시예 편향으로 인해 발생합니다. 더 많은 실험 사례가 아래에 나와 있습니다. 자세한 내용은 원본 논문을 참조하세요.


강화 학습 실험
팀은 PPO를 사용한 기준 대비 Isaac Gym의 4가지 로봇 제어 작업에 대한 BoT의 강화 학습 성능을 평가했습니다. 4가지 작업은 Humanoid-Mod, Humanoid-Board, Humanoid-Hill 및 A1-Walk입니다.
그림 5는 MLP, Transformer 및 BoT(Hard 및 Mix) 교육 중 평가 롤아웃의 평균 플롯 반환을 보여줍니다. 여기서 실선은 평균에 해당하고 음영 영역은 5개 시드의 표준 오류에 해당합니다.
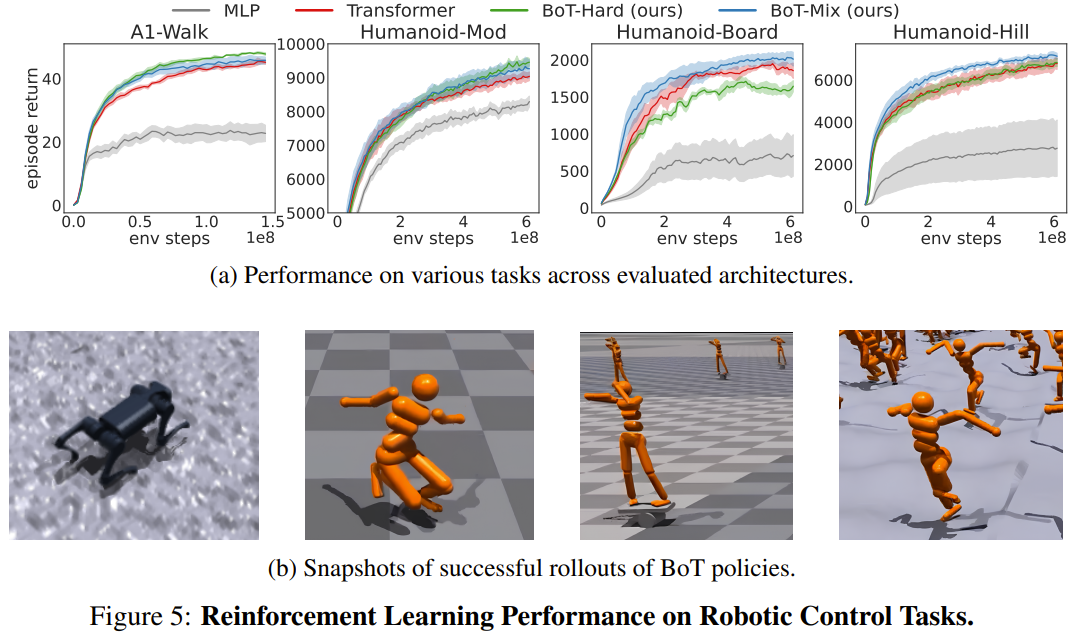

결과에 따르면 BoT-Mix는 샘플 효율성 및 점근 성능 측면에서 MLP 및 원래 Transformer 기준선보다 지속적으로 우수한 성능을 보입니다. 이는 로봇 본체의 편향을 정책 네트워크 아키텍처에 통합하는 것의 유용성을 보여줍니다.
한편, BoT-Hard는 간단한 작업(A1-Walk 및 Humanoid-Mod)에서는 원래 Transformer보다 더 나은 성능을 발휘하지만 더 어려운 탐색 작업(Humanoid-Board 및 Humanoid-Hill)에서는 성능이 떨어집니다. 가려진 주의가 멀리 있는 신체 부위의 정보 전파를 방해한다는 점을 감안할 때 BoT-Hard의 정보 통신에 대한 강력한 한계는 강화 학습 탐색의 효율성을 방해할 수 있습니다.
실제 실험
Isaac Gym のシミュレートされたスポーツ環境は、現実世界の調整を必要とせずに、強化学習戦略を仮想環境から現実の環境に移行するためによく使用されます。新しく提案されたアーキテクチャが現実世界のアプリケーションに適しているかどうかを検証するために、チームは上記でトレーニングされた BoT ポリシーを Unitree A1 ロボットにデプロイしました。以下のビデオからわかるように、新しいアーキテクチャは実際の展開でも確実に使用できます。

計算分析
チームは、図 6 に示すように、新しいアーキテクチャの計算コストも分析しました。新しく提案されたマスクされたアテンションと従来のアテンションの異なるシーケンス長 (ノード数) に対するスケーリング結果をここに示します。
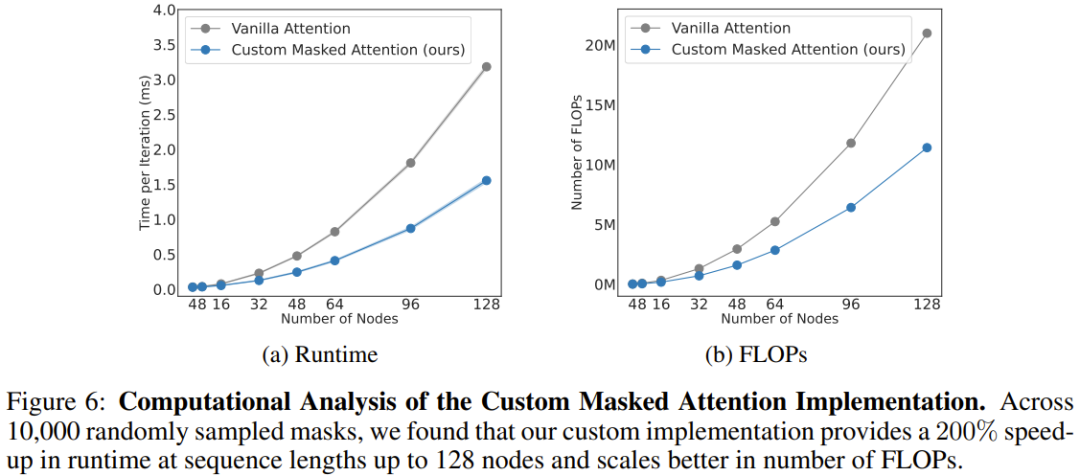
128 個のノード (器用な腕を備えた人型ロボットに相当) がある場合、新しいアテンションにより速度が 206% 向上することがわかります。
全体的に、これは、BoT アーキテクチャにおける身体由来のバイアスが物理エージェントの全体的なパフォーマンスを向上させるだけでなく、アーキテクチャの自然なスパース マスキングの恩恵も受けていることを示しています。この方法では、十分な並列化により学習アルゴリズムのトレーニング時間を大幅に短縮できます。
위 내용은 로봇 전략 학습을 위한 Game Changer? 버클리는 바디 트랜스포머(Body Transformer)를 제안합니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!