
트랜스포머의 최강 경쟁자인 맘바를 이해하기 위한 한 편의 글

- 王林원래의
- 2024-08-19 16:33:34419검색
Mamba c'est bien, mais son développement est encore précoce.
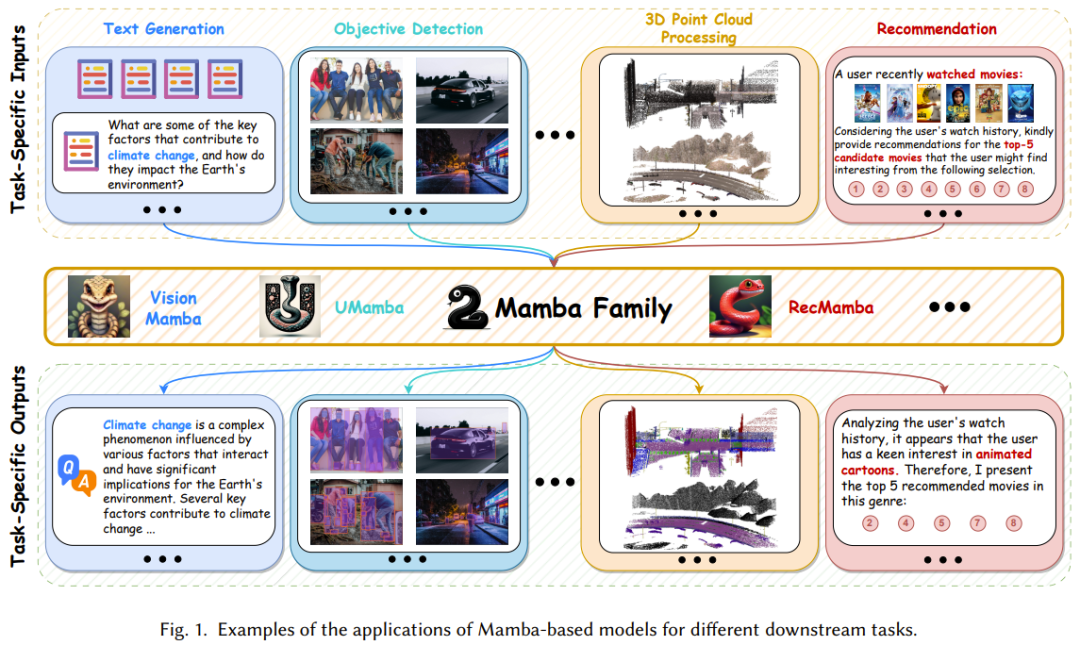

Titre de l'article : A Survey of Mamba Adresse de l'article : https://arxiv.org/pdf/2408.01129
Mamba-360 : Enquête sur les modèles d'espace d'état comme alternative de transformateur pour la modélisation de séquences longues : méthodes, applications et défis arXiv : 2404.16112
Modèle d'espace d'état pour une alternative de réseau de nouvelle génération à. transformateurs : une enquête. arXiv : 2404.09516
-
Vision Mamba : une enquête complète et une taxonomie. arXiv : 2404.15956
.
离散化
卷积计算





集成方法:将 Mamba 块与其它模型集成到一起,实现效果与效率的平衡; 替换方法:用 Mamba 块替换其它模型框架中的主要层; 修改方法:修改经典 Mamba 块内的组件。

展平式扫描方法:以展平的视角看待 token 序列,并基于此处理模型输入; 立体式扫描方法:跨维度、通道或尺度扫描模型输入,这又可进一步分为三类:分层扫描、时空扫描、混合扫描。


Cara untuk membangunkan dan menambah baik model asas berdasarkan Mamba; Cara meningkatkan Mamba Kredibiliti model, yang memerlukan penyelidikan lanjut tentang keselamatan dan keteguhan, keadilan, kebolehjelasan dan privasi Cara menggunakan teknologi baharu dalam medan Transformer untuk Mamba, seperti penalaan halus yang cekap parameter; dan bencana melupakan Mitigation, Retrieval Augmented Generation (RAG).
위 내용은 트랜스포머의 최강 경쟁자인 맘바를 이해하기 위한 한 편의 글의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.