
Ibis를 사용한 선언적 다중 엔진 데이터 스택

- 王林원래의
- 2024-07-19 03:34:101455검색
TL;DR
저는 최근 다중 엔진 데이터 스택에 대한 Julien Hurault의 Ju 데이터 엔지니어링 뉴스레터를 접했습니다. 아이디어는 간단합니다. 우리는 새로운 백엔드와 기능이 개발됨에 따라 파이프라인을 확장할 수 있는 유연성을 유지하면서 모든 백엔드에서 코드를 쉽게 포팅하고 싶습니다. 여기에는 최소한 다음과 같은 높은 수준의 워크플로우가 필요합니다.
- SQL 쿼리의 일부를 DuckDB, polars, DataFusion, chdb 등을 사용하는 서버리스 엔진으로 오프로드합니다.
- 다양한 개발 및 배포 시나리오에 적합한 규모의 파이프라인. 예를 들어 개발자는 로컬에서 작업하고 자신 있게 프로덕션으로 배송할 수 있습니다.
- 파이프라인에 데이터베이스 스타일 최적화를 자동으로 적용하세요.
이 게시물에서는 프로그래밍 언어에서 다중 엔진 파이프라인을 구현하는 방법에 대해 자세히 알아봅니다. SQL 대신 대화형 및 일괄 사용 사례 모두에 사용할 수 있는 Dataframe API를 사용하여 제안합니다. 구체적으로 파이프라인을 더 작은 조각으로 나누고 DuckDB, Pandas 및 Snowflake에서 실행하는 방법을 보여줍니다. 또한 다중 엔진 데이터 스택의 장점에 대해 논의하고 해당 분야의 새로운 트렌드를 강조합니다.
이 게시물에 구현된 코드는 GitHub에서 사용할 수 있습니다^[Repo를 빠르게 사용해 볼 수 있도록 nix flake도 제공합니다]. 원래 구현된 뉴스레터의 참고 작업은 여기에서 확인하세요.
개요
다중 엔진 데이터 스택 파이프라인은 다음과 같이 작동합니다. 일부 데이터는 S3 버킷에 저장되고 사전 처리되어 중복 항목을 제거한 다음 Snowflake 테이블에 로드되어 ML 또는 Snowflake 관련 기능으로 추가로 변환됩니다^[참고 우리는 Snowflake에서 가능할 수 있는 유형의 구현을 다루지 않으며 이를 워크플로의 요구 사항으로 가정합니다.] 파이프라인은 방문 위치에 저장되고 사전 처리된 다음 S3 버킷의 준비 위치에 저장되는 쪽모이 세공 파일로 주문을 받습니다. 그런 다음 준비 데이터가 Snowflake에 로드되어 다운스트림 BI 도구에 연결됩니다. 파이프라인은 각 백엔드에 대해 하나의 모델을 사용하여 SQL dbt로 연결되며 뉴스레터에서는 Dagster를 오케스트레이션 도구로 선택합니다.
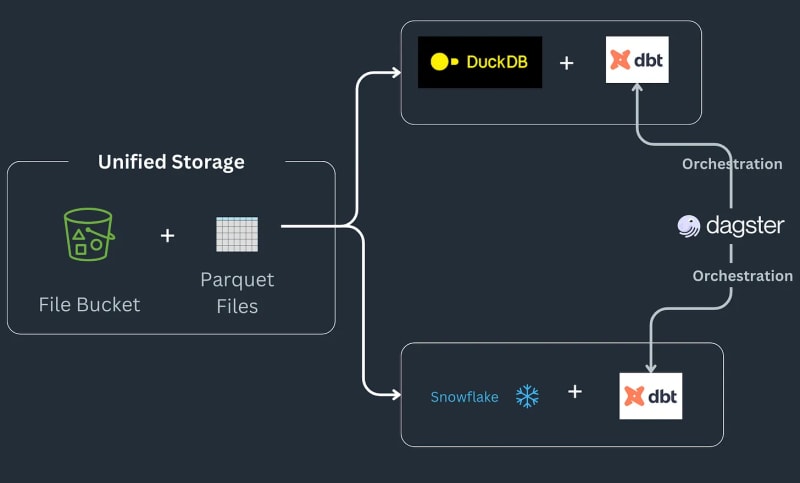
오늘은 Julien Hurault의 다중 엔진 스택 예제1의 전체 예제를 재현하여 팬더 코드를 Ibis 표현식으로 변환하는 방법을 살펴보겠습니다. dbt 모델과 SQL을 사용하는 대신 ibis와 일부 Python을 사용하여 셸에서 SQL 엔진을 컴파일하고 조정합니다. 코드를 Ibis 표현식으로 다시 작성하면 지연 실행이 포함된 데이터 파이프라인을 선언적으로 구축할 수 있습니다. 또한 Ibis는 20개 이상의 백엔드를 지원하므로 코드를 한 번만 작성하면 ibis.exprs를 여러 백엔드로 포팅할 수 있습니다. 더욱 단순화하기 위해 Dagster에서 제공하는 일정 관리 및 작업 조정2을 독자의 몫으로 남겨둡니다.
다중 엔진 데이터 스택의 핵심 개념
Julien의 뉴스레터에 설명된 다중 엔진 데이터 스택의 핵심 개념은 다음과 같습니다.
- 다중 엔진 데이터 스택: Snowflake, Spark, DuckDB, BigQuery와 같은 다양한 데이터 엔진을 결합하는 개념입니다. 이 접근 방식은 비용을 절감하고 공급업체 종속을 제한하며 유연성을 높이는 것을 목표로 합니다. Julien은 특정 벤치마크 쿼리의 경우 DuckDB를 사용하면 Snowflake에 비해 상당한 비용 절감 효과를 얻을 수 있다고 언급합니다.
- 교차 엔진 쿼리 계층 개발: 뉴스레터에서는 데이터 팀이 SQL 또는 데이터 프레임 코드를 한 엔진에서 다른 엔진으로 원활하게 변환할 수 있게 해주는 기술의 발전을 강조합니다. 이러한 개발은 다양한 엔진 전반에 걸쳐 효율성을 유지하는 데 매우 중요합니다.
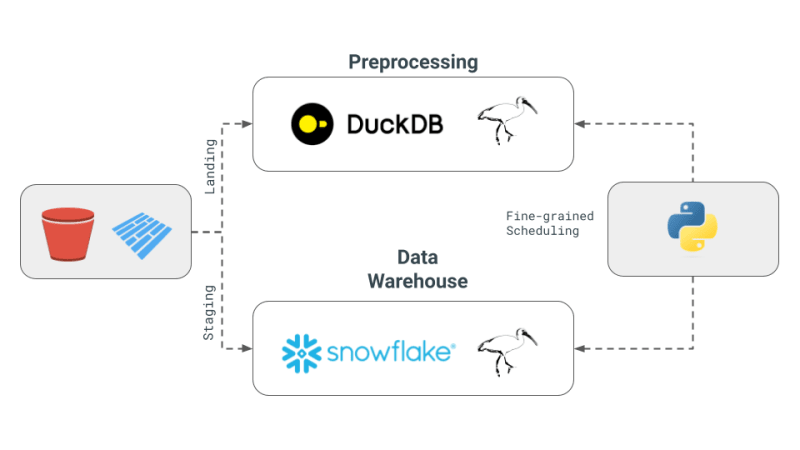
- Apache Iceberg 및 대안 사용: Apache Iceberg는 잠재적인 통합 스토리지 계층으로 간주되지만 통합은 아직 dbt 프로젝트에서 사용할 수 있을 정도로 성숙하지 않습니다. 대신 Julien은 PoC(개념 증명)에서 DuckDB와 Snowflake 모두에서 액세스할 수 있는 S3에 저장된 Parquet 파일을 사용하기로 결정했습니다.
- PoC의 오케스트레이션 및 엔진: Julien은 프로젝트에서 Dagster를 오케스트레이터로 사용하여 dbt 프로젝트 내에서 다양한 엔진의 작업 일정을 단순화했습니다. 이번 PoC에 결합된 엔진은 DuckDB와 Snowflake였습니다.
왜 DataFrames와 Ibis를 사용하나요?
위의 파이프라인은 ETL 및 ELT에 적합하지만 때로는 SQL과 같은 쿼리 언어 대신 완전한 프로그래밍 언어의 기능을 원할 때도 있습니다. 디버깅, 테스트, 복잡한 UDF 등. 과학적 탐색을 위해서는 데이터 과학자가 코드를 빠르게 반복하고, 결과를 시각화하고, 데이터를 기반으로 결정을 내려야 하므로 대화형 컴퓨팅이 필수적입니다.
DataFrame은 이러한 데이터 구조입니다. DataFrame은 주문된 데이터를 처리하고 대화형 방식으로 계산 작업을 적용하는 데 사용됩니다. SQL 스타일 작업으로 대규모 데이터를 처리할 수 있는 유연성을 제공할 뿐만 아니라 Excel 시트와 같은 셀 수준 변경 사항을 편집할 수 있는 낮은 수준의 제어도 제공합니다. 일반적으로 모든 데이터는 메모리 내에서 처리되고 일반적으로 메모리 내에서 적합할 것으로 기대됩니다. 또한 DataFrame을 사용하면 지연/배치 모드와 대화형 모드 사이를 쉽게 이동할 수 있습니다.
DataFrames는 사람들이 사용자 정의 함수를 적용할 수 있게 하고 SQL의 한계에서 사용자를 해방시키는 데 탁월합니다. 즉, 이제 코드를 재사용하고, 작업을 테스트하고, 복잡한 작업을 위해 관계형 기계를 쉽게 확장할 수 있습니다. 또한 DataFrame을 사용하면 테이블 형식의 데이터 표현에서 머신러닝 라이브러리가 요구하는 배열 및 텐서로 빠르게 전환할 수 있습니다.
전문적이고 처리 중인 데이터베이스(예: OLAP용 DuckDB3는 Snowflake와 같은 무거운 원격 데이터베이스와 pandas와 같은 인체공학적 라이브러리 사이의 경계를 모호하게 만들고 있습니다. 우리는 이것이 DataFrames가 로컬 Python 셸의 상호 작용 기대치와 개발자의 느낌을 유지하면서 메모리 데이터보다 큰 데이터를 처리할 수 있도록 하여 메모리보다 큰 데이터를 작게 느낄 수 있는 기회라고 믿습니다.
기술 심층 분석
우리의 구현은 앞서 제시된 4가지 개념에 중점을 둡니다.
- 다중 엔진 데이터 스택: DuckDB, pandas, Snowflake를 엔진으로 사용하겠습니다.
- 교차 엔진 쿼리 계층: Ibis를 사용하여 표현식을 작성하고 컴파일하여 DuckDB, pandas 및 Snowflake에서 실행합니다.
- Apache Iceberg 및 대안: s3fs 패키지를 사용하여 S3로 확장하는 것이 쉽지 않을 것이라는 기대와 함께 로컬에 저장된 Parquet 파일을 스토리지 계층으로 사용할 것입니다.
- PoC의 오케스트레이션 및 엔진: 우리는 엔진에 대한 세분화된 스케줄링에 중점을 두고 오케스트레이션은 독자에게 맡길 것입니다. 세분화된 스케줄링은 오케스트레이션 프레임워크(예: Dagster, Airflow 등
팬더로 구현하기

pandas는 전형적인 DataFrame 라이브러리이며 아마도 위의 작업 흐름을 구현하는 가장 간단한 방법을 제공할 것입니다. 먼저, 뉴스레터의 구현에서 빌려온 무작위 데이터를 생성합니다.
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
Pandas 구현은 스타일 면에서 필수적이며 데이터가 메모리에 맞도록 설계되었습니다. pandas API는 미묘한 차이가 있는 SQL로 컴파일하기가 어렵고 대부분 Python 시각화, 플로팅, 기계 학습, AI 및 복잡한 처리 라이브러리를 통합하는 고유한 위치에 있습니다.
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
Pandas 연산자를 사용하여 중복을 제거한 후 데이터를 Snowflake로 보낼 준비가 되었습니다. Snowflake에는 우리 사용 사례에 유용한 write_pandas라는 메서드가 있습니다.
Ibis(Ibisify)로 구현
Pandas의 한 가지 제한 사항은 관계형 대수로 다시 매핑되지 않는 자체 API가 있다는 것입니다. Ibis는 말 그대로 여러 SQL 백엔드에 다시 매핑할 수 있는 정상적인 표현식 시스템을 제공하기 위해 팬더를 만든 사람들이 만든 라이브러리입니다. Ibis는 dplyr R 패키지에서 영감을 얻어 관계형 대수로 쉽게 매핑하여 SQL로 컴파일할 수 있는 새로운 표현 시스템을 구축했습니다. 또한 선언적 스타일이므로 전체 논리 계획이나 표현식에 데이터베이스 스타일 최적화를 적용할 수 있습니다. Ibis는 뛰어난 구성 가능 코덱스에서 강조된 것처럼 구성 가능성을 활성화하는 핵심 구성 요소입니다.
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ibis 표현은 데이터베이스의 전통적인 논리적 계획과 유사한 계획으로 자체적으로 인쇄됩니다. 논리 계획은 수행해야 하는 계산을 설명하는 관계형 대수 연산자 트리입니다. 그런 다음 이 계획은 쿼리 최적화 프로그램에 의해 최적화되고 쿼리 실행기에 의해 실행되는 실제 계획으로 변환됩니다. Ibis 표현식은 수행해야 하는 계산을 설명한다는 점에서 논리 계획과 유사하지만 즉시 실행되지는 않습니다. 대신 SQL로 컴파일되어 필요할 때 백엔드에서 실행됩니다. 논리적 계획은 일반적으로 Dask와 같은 작업 스케줄링 프레임워크에서 생성된 DAG보다 더 높은 수준의 세분성을 갖습니다. 이론적으로 이 계획은 Dask의 DAG로 정리될 수 있습니다.
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Multi-Engine Data Stack w/ Ibis
DuckDB + pandas + Snowflake
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
Acknowledgments
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
Resources
- The Road to Composable Data Systems
- The Composable Codex
- Apache Arrow
- Multi-Engine Data Stack Newsleter v0 v1
- Ibis, the portable dataframe library
- dbt Docs
- Dagster Docs
- LanceDB
- KuzuDB
- DuckDB
-
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
-
Orchestration Vs fine-grained scheduling: ↩
- The orchestration is left to the reader. The orchestration can be done using a tool like Dagster, Prefect, or Apache Airflow.
- The fine-grained scheduling can be done using a tool like Dask, Ray, or Spark.
-
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
-
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
위 내용은 Ibis를 사용한 선언적 다중 엔진 데이터 스택의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!