
단일 저자 논문, Google은 조밀한 피드포워드 및 희박한 MoE를 능가하는 수백만 개의 전문가 혼합물을 제안합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-07-17 14:34:17688검색
계산 효율성을 유지하면서 Transformer를 더욱 확장할 수 있는 잠재력을 활용하세요.



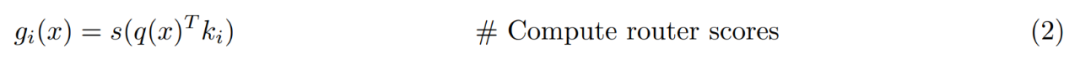



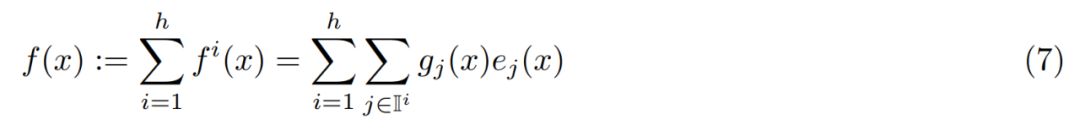


-
Curation Corpus Lambada Pile Wikitext 사전 훈련 데이터 세트 C4
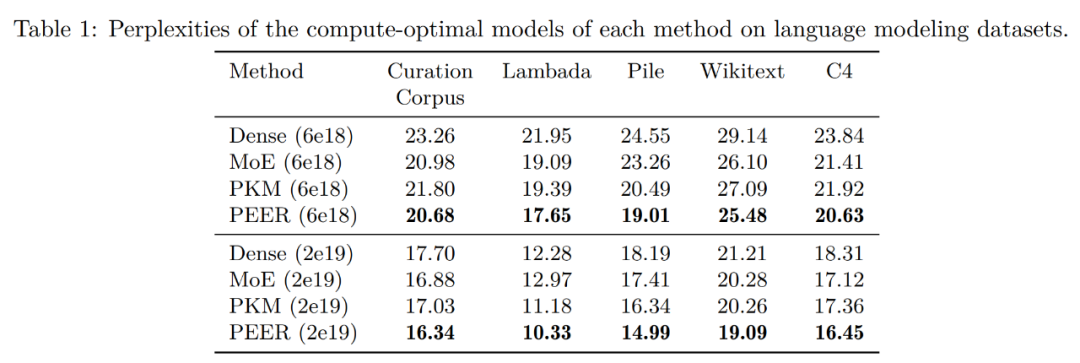
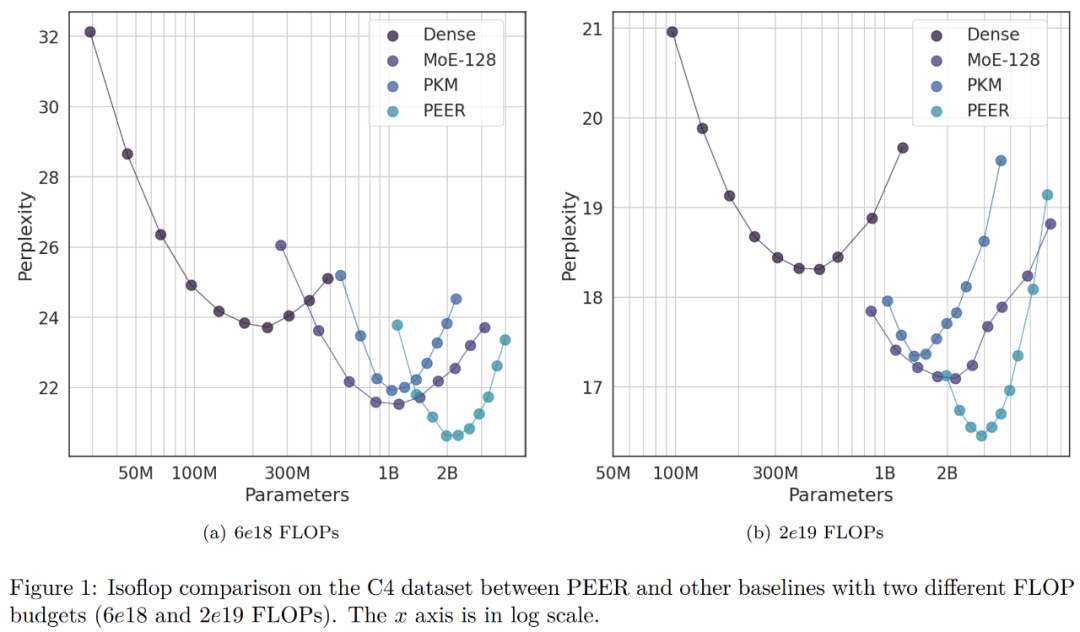




위 내용은 단일 저자 논문, Google은 조밀한 피드포워드 및 희박한 MoE를 능가하는 수백만 개의 전문가 혼합물을 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.