LLM에 인과 사슬을 보여주면 공리를 배울 수 있습니다.
AI는 이미 수학자 및 과학자의 연구를 돕고 있습니다. 예를 들어 유명한 수학자 Tao Zhexuan은 GPT 및 기타 AI 도구의 도움을 받아 자신의 연구 및 탐색 경험을 반복적으로 공유했습니다. AI가 이러한 분야에서 경쟁하려면 강력하고 신뢰할 수 있는 인과관계 추론 능력이 필수적입니다. 이 기사에서 소개할 연구에서는 작은 그래프에 대한 인과 전이성 공리 시연을 위해 훈련된 Transformer 모델이 큰 그래프에 대한 전이성 공리로 일반화할 수 있다는 사실을 발견했습니다. 즉, Transformer가 간단한 인과 추론을 수행하는 방법을 학습하면 더 복잡한 인과 추론에 사용될 수 있습니다. 연구팀이 제안하는 공리 훈련 프레임워크는 수동적 데이터를 기반으로 인과 추론을 학습하는 새로운 패러다임으로, 시연만 충분하다면 임의의 공리를 학습하는 데 사용할 수 있다. 인과 추론은 특별히 인과 관계에 대해 사전 정의된 공리 또는 규칙을 따르는 일련의 추론 프로세스로 정의할 수 있습니다. 예를 들어 d-separation(유도 분리) 및 do-calculus 규칙은 공리로 간주될 수 있으며, 충돌체 세트 또는 백도어 세트의 사양은 공리에서 파생된 규칙으로 간주될 수 있습니다. 일반적으로 인과 추론은 시스템의 변수에 해당하는 데이터를 사용합니다. 공리 또는 규칙은 정규화, 모델 아키텍처 또는 특정 변수 선택을 통해 귀납적 편향의 형태로 기계 학습 모델에 통합될 수 있습니다. 사용 가능한 데이터 유형(관찰 데이터, 개입 데이터, 반사실 데이터)의 차이를 기반으로 Judea Pearl이 제안한 "인과 사다리"는 가능한 인과 추론 유형을 정의합니다. 공리는 인과관계의 초석이기 때문에, 머신러닝 모델을 직접 활용하여 공리를 학습할 수 있는지 궁금하지 않을 수 없습니다. 즉, 공리를 학습하는 방법이 어떤 데이터 생성 과정을 통해 얻은 데이터를 학습하는 것이 아니라 공리의 상징적 실증을 직접 학습(따라서 인과 추론을 학습)하는 것이라면 어떨까요? 특정 데이터 분포를 사용하여 구축된 작업별 인과 모델과 비교할 때 이러한 모델은 장점이 있습니다. 즉, 다양한 다운스트림 시나리오에서 인과 추론을 달성할 수 있다는 것입니다. 이 문제는 언어 모델이 자연어로 표현된 기호 데이터를 학습하는 능력을 얻음에 따라 중요해집니다. 실제로 최근 일부 연구에서는 대형 언어 모델(LLM)이 자연어에서 인과 추론 문제를 인코딩하는 벤치마크를 생성하여 인과 추론을 수행할 수 있는지 평가했습니다. Microsoft, MIT, 인도 하이데라바드 공과대학(IIT Hyderabad)의 연구팀도 이 방향으로 중요한 진전을 이루었습니다. 즉, 공리 훈련을 통해 인과 추론을 학습하는 방법을 제안하는 것입니다. 
- 논문 제목: Teaching Transformers Causal Reasoning through Axiomatic Training
- 논문 주소: https://arxiv.org/pdf/2407.07612
그들은 가정합니다. 인과 공리는 다음과 같은 기호 튜플 〈전제, 가설, 결과〉로 표현될 수 있습니다. 그 중에서 가설은 가설, 즉 인과관계 진술을 말하며, 전제는 진술이 "참"인지 여부를 결정하는 데 사용되는 관련 정보를 의미합니다. 결과는 간단하게 "예" 또는 "아니오"일 수 있습니다. 예를 들어 "대규모 언어 모델이 상관관계로부터 인과관계를 추론할 수 있습니까?"라는 논문의 충돌기 공리는 다음과 같이 표현될 수 있습니다. , 결론은 "예"입니다. 이 템플릿을 기반으로 변수 이름, 변수 번호, 변수 순서 등을 수정하여 수많은 합성 튜플을 생성할 수 있습니다. Transformer를 사용하여 인과 공리를 학습하고 공리 훈련을 달성하기 위해 팀에서는 다음 방법을 사용하여 데이터 세트, 손실 함수 및 위치 임베딩을 구성했습니다. 공리적 훈련: 데이터 세트, 손실 함수 및 위치 컴파일특정 공리를 기반으로 "가설"은 "전제"를 기반으로 적절한 레이블에 매핑될 수 있습니다. ( 예 혹은 아니오). 훈련 데이터 세트를 생성하기 위해 팀은 특정 변수 설정 X, Y, Z, A에서 가능한 모든 튜플 {(P, H, L)}_N을 열거합니다. 여기서 P는 전제이고 H는 가설, L은 레이블입니다. (예 혹은 아니오). 일부 인과 다이어그램을 기반으로 하는 전제 P가 주어졌을 때 가설 P가 특정 공리(1회 이상)를 사용하여 파생될 수 있으면 레이블 L은 예입니다. 그렇지 않으면 아니요입니다. 예를 들어 시스템의 기본 실제 인과 그래프에 X_1 → X_2 → X_3 →・・・→ X_n과 같은 체인 토폴로지가 있다고 가정합니다. 그렇다면 가능한 전제는 X_1 → X_2 ∧ X_2 → X_3이고 X_1 → 위의 공리는 더 복잡한 훈련 튜플을 생성하기 위해 여러 번 귀납적으로 사용될 수 있습니다. 훈련 설정을 위해 전이성 공리에 의해 생성된 N 공리 인스턴스를 사용하여 합성 데이터 세트 D를 구축합니다. D의 각 인스턴스는 (P_i, H_ij, L_ij), 형식으로 구성됩니다. 여기서 n은 각 i번째 전제의 노드 수입니다. P는 전제, 즉 특정 인과 구조(예: X가 Y를 유발하고 Y가 Z를 유발함)에 대한 자연어 표현이며, 그 뒤에 질문 H(예: X가 Y를 유발합니까?)가 표시됩니다. 또는 아니요). 이 형식은 주어진 인과 그래프의 각 고유 체인에 대한 모든 노드 쌍을 효과적으로 포괄합니다. 주어진 데이터 세트에서 손실 함수는 각 튜플의 Ground Truth 레이블을 기반으로 정의되며 다음과 같이 표현됩니다. 분석에서는 다음 토큰 예측과 비교하여 이 손실을 사용합니다. 유망한 결과를 얻을 수 있습니다. 훈련 및 손실 기능 외에도 위치 인코딩의 선택도 또 다른 중요한 요소입니다. 위치 인코딩은 시퀀스에서 토큰의 절대 및 상대 위치에 대한 주요 정보를 제공할 수 있습니다. 유명 논문 "Attention is all you need"에서는 주기 함수(사인 또는 코사인 함수)를 사용하여 이러한 코드를 초기화하는 절대 위치 코딩 전략을 제안합니다. 절대 위치 인코딩은 모든 시퀀스 길이의 모든 위치에 대해 특정 값을 제공할 수 있습니다. 그러나 일부 연구에서는 절대 위치 인코딩이 Transformer의 길이 일반화 작업에 대처하기 어렵다는 것을 보여줍니다. 학습 가능한 APE 변형에서는 각 위치 임베딩이 무작위로 초기화되고 모델을 사용하여 학습됩니다. 이 방법은 새로운 위치 임베딩이 아직 훈련되지 않고 초기화되지 않았기 때문에 훈련 중 시퀀스보다 긴 시퀀스를 처리하는 데 어려움을 겪습니다. 흥미롭게도 최근 연구 결과에 따르면 자기 회귀 모델에서 위치 임베딩을 제거하면 모델의 길이 일반화 능력이 향상될 수 있으며 자기 회귀 디코딩 중 주의 메커니즘은 위치 정보를 인코딩하는 데 충분합니다. 팀은 학습 가능한 위치 인코딩(LPE), 정현파 위치 인코딩(SPE), 위치 인코딩 없음(NoPE) 등 다양한 위치 인코딩을 사용하여 인과 작업의 일반화에 미치는 영향을 이해했습니다.모델의 일반화 능력을 향상시키기 위해 팀에서는 길이, 노드 이름, 체인 순서 및 분기 상태의 섭동을 포함한 데이터 섭동도 사용했습니다. 다음과 같은 질문이 생깁니다. 모델이 이 데이터를 사용하여 훈련된 경우 모델이 이 원리를 새로운 시나리오에 적용하는 방법을 배울 수 있습니까? 이 질문에 답하기 위해 팀은 인과 독립 공리의 상징적 시연을 사용하여 Transformer 모델을 처음부터 훈련했습니다. 일반화 성능을 평가하기 위해 그들은 크기가 3-6 노드인 인과적으로 독립적인 단순한 공리 체인에 대해 훈련한 다음 길이 일반화 성능(크기 7-15 체인), 이름 일반화(더 긴 변수 이름), 순차 일반화(역방향 가장자리 또는 섞인 노드가 있는 체인), 구조적 일반화(가지가 있는 그래프). 그림 1은 Transformer의 구조적 일반화를 평가하는 방법을 보여줍니다.
구체적으로 GPT-2 아키텍처를 기반으로 하는 6,700만 개의 매개변수로 디코더 기반 모델을 훈련했습니다. 모델에는 12개의 Attention 레이어, 8개의 Attention 헤드, 512개의 임베딩 차원이 있습니다. 그들은 각 훈련 데이터 세트에 대해 처음부터 모델을 훈련했습니다. 위치 임베딩의 영향을 이해하기 위해 그들은 사인파 위치 인코딩(SPE), 학습 가능한 위치 인코딩(LPE) 및 위치 인코딩 없음(NoPE)이라는 세 가지 위치 임베딩 설정도 연구했습니다. 결과는 표 1, 그림 3, 그림 4에 나와 있습니다.
표 1은 훈련 중에 볼 수 없는 더 큰 인과 사슬을 평가할 때 다양한 모델의 정확도를 제공합니다. 신형 TS2(NoPE)의 성능이 1조 매개변수 규모의 GPT-4와 맞먹는다는 것을 알 수 있다. 그림 3은 더 긴 노드 이름(훈련 세트보다 길음)과 다양한 위치 임베딩의 영향을 갖는 인과 시퀀스에 대한 일반화 능력 평가 결과입니다.
그림 4는 보이지 않는 긴 인과 관계 시퀀스에 대한 일반화 능력을 평가합니다.
그들은 단순한 체인에 대해 훈련된 모델이 더 큰 체인의 여러 공리 적용으로 일반화할 수 있지만 순차 또는 구조적 일반화와 같은 더 복잡한 시나리오로 일반화할 수 없다는 것을 발견했습니다. 그러나 모델이 단순 체인과 임의의 역방향 가장자리가 있는 체인으로 구성된 혼합 데이터 세트에서 훈련된 경우 모델은 다양한 평가 시나리오에 잘 일반화됩니다. NLP 작업의 길이 일반화 결과를 확장하면서 그들은 길이와 다른 차원에 걸쳐 인과 일반화를 보장하는 데 위치 임베딩의 중요성을 발견했습니다. 가장 성능이 좋은 모델에는 위치 인코딩이 없었지만 정현파 인코딩이 어떤 경우에는 잘 작동한다는 사실도 발견했습니다. 이 공리 훈련 방법은 그림 5와 같이 더 어려운 문제로 일반화될 수도 있습니다. 즉, 통계적 독립성을 포함하는 전제를 바탕으로 작업 목표는 인과관계와 상관관계를 식별하는 것입니다. 이 작업을 해결하려면 d-분리 및 마르코프 속성을 포함한 여러 공리에 대한 지식이 필요합니다.
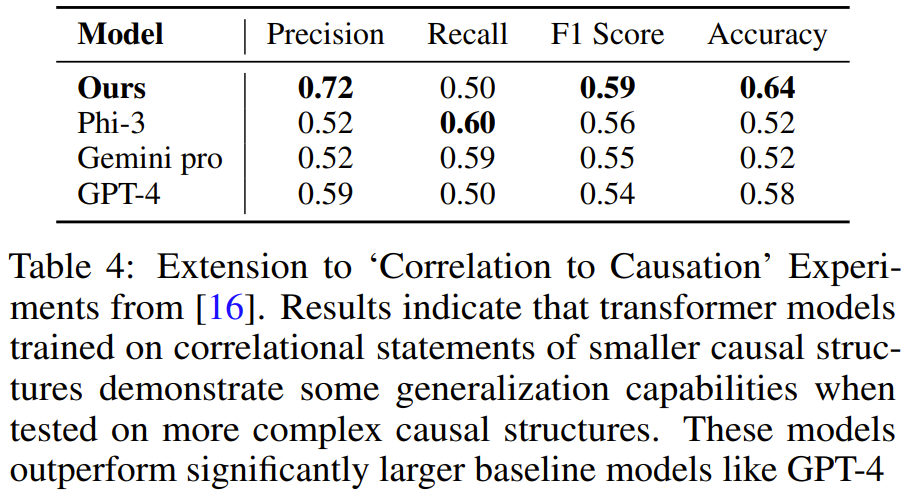
팀은 위와 동일한 방법을 사용하여 합성 훈련 데이터를 생성한 후 모델을 훈련시켰으며, 3~4개의 변수가 포함된 작업 데모에서 훈련된 Transformer가 5개의 변수가 포함된 문제를 해결하는 방법을 학습할 수 있음을 발견했습니다. 작업. 그리고 이 작업에서 모델은 GPT-4 및 Gemini Pro와 같은 대규모 LLM보다 더 정확합니다.
팀은 "우리의 연구는 공리의 상징적 시연을 통해 인과 추론을 학습하는 모델을 가르치는 새로운 패러다임을 제공하며, 이를 공리 훈련이라고 합니다."라고 말했습니다. 이 방법의 데이터 생성 및 훈련 절차는 일반적입니다. 공리는 기호 튜플의 형식으로 표현될 수 있으므로 이 방법을 사용하여 학습할 수 있습니다. 위 내용은 Axiom 교육을 통해 LLM은 인과 추론을 학습할 수 있습니다. 6,700만 개의 매개변수 모델은 1조 매개변수 수준 GPT-4와 비슷합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



 , 결론은 "예"입니다.
, 결론은 "예"입니다.  형식으로 구성됩니다. 여기서 n은 각 i번째 전제의 노드 수입니다. P는 전제, 즉 특정 인과 구조(예: X가 Y를 유발하고 Y가 Z를 유발함)에 대한 자연어 표현이며, 그 뒤에 질문 H(예: X가 Y를 유발합니까?)가 표시됩니다. 또는 아니요). 이 형식은 주어진 인과 그래프의 각 고유 체인에 대한 모든 노드 쌍을 효과적으로 포괄합니다.
형식으로 구성됩니다. 여기서 n은 각 i번째 전제의 노드 수입니다. P는 전제, 즉 특정 인과 구조(예: X가 Y를 유발하고 Y가 Z를 유발함)에 대한 자연어 표현이며, 그 뒤에 질문 H(예: X가 Y를 유발합니까?)가 표시됩니다. 또는 아니요). 이 형식은 주어진 인과 그래프의 각 고유 체인에 대한 모든 노드 쌍을 효과적으로 포괄합니다.  분석에서는 다음 토큰 예측과 비교하여 이 손실을 사용합니다. 유망한 결과를 얻을 수 있습니다.
분석에서는 다음 토큰 예측과 비교하여 이 손실을 사용합니다. 유망한 결과를 얻을 수 있습니다.