AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
이 논문의 저자는 Huawei의 Montreal Noah's Ark Laboratory Kang Jikun, Li Xinze, Chen Xi, Amirreza Kazemi 및 Chen Boxing입니다. 인공 지능(AI)은 지난 10년 동안 특히 자연어 처리 및 컴퓨터 비전 분야에서 큰 발전을 이루었습니다. 그러나 AI의 인지 능력과 추론 능력을 어떻게 향상시킬지는 여전히 큰 과제로 남아 있습니다. 최근 "MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time"이라는 논문에서는 오픈소스 모델인 Llama에 구현된 트리 검색 기반 추론 시간 역량 향상 방법인 MindStar[1]를 제안했습니다. -13-B 및 Mistral-7B는 수학적 문제에 대한 대략적인 비공개 소스 대형 모델 GPT-3.5 및 Grok-1의 추론 기능을 달성했습니다. 
- 논문 제목: MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
- 논문 주소: https://arxiv.org/abs/2405.16265v2
마인드스타 수학 문제에 대한 응용 프로그램 효과:
그림 1: 다양한 대규모 언어 모델의 수학적 정확성. LLaMA-2-13B는 수학적 성능이 GPT-3.5(4샷)와 유사하지만 약 200배 더 많은 계산 리소스를 절약합니다. Transformer 기반 LLM(대형 언어 모델)은 지침 준수[1,2] 및 코딩 지원[3,4] ] 문예 창작 등의 분야에서 인상적인 결과가 입증되었습니다[5]. 그러나 복잡한 추론 작업을 해결하기 위해 LLM의 능력을 활용하는 것은 여전히 어려운 일입니다. 일부 최근 연구[6,7]는 SFT(Supervised Fine-Tuning)를 통해 문제를 해결하려고 시도합니다. 새로운 추론 데이터 샘플을 원래 데이터 세트와 혼합함으로써 LLM은 이러한 샘플의 기본 분포를 학습하고 기본 분포를 모방하려고 시도합니다. 보이지 않는 추론 작업을 해결하기 위해 논리를 배우십시오. 이 접근 방식은 성능이 향상되었지만 광범위한 교육과 추가 데이터 준비에 크게 의존합니다[8,9]. Llama-3 보고서[10]는 중요한 관찰을 강조합니다. 즉, 어려운 추론 문제에 직면할 때 모델이 때때로 올바른 추론 궤적을 생성한다는 것입니다. 이는 모델이 정답을 생성하는 방법을 알고 있지만 정답을 선택하는 데 어려움을 겪고 있음을 의미합니다. 이 결과를 바탕으로 우리는 LLM이 올바른 결과를 선택하도록 도와줌으로써 LLM의 추론 능력을 향상시킬 수 있는지 간단한 질문을 했습니다. 이를 탐색하기 위해 우리는 LLM 출력 선택에 대한 다양한 보상 모델을 활용하는 실험을 수행했습니다. 실험 결과에 따르면 단계 수준 선택이 기존 CoT 방법보다 훨씬 뛰어난 것으로 나타났습니다.
ㅋㅋ 그림 2 MindStar의 알고리즘 아키텍처 다이어그램
새로운 추론 검색 프레임워크를 소개합니다 - MindStar(M*)는 추론 작업을 검색 문제로 처리하고 프로세스 감독 모델(Process)의 보상을 활용하여 -감독 보상 모델(PRM), M*은 추론 트리 공간을 효과적으로 탐색하고 대략적인 최적 경로를 식별합니다. Beam Search(BS)와 Levin Tree Search(LevinTS)의 아이디어를 결합하면 검색 효율성이 더욱 향상되고 제한된 계산 복잡도 내에서 최적의 추론 경로를 찾을 수 있습니다.
프로세스 감독 보상 모델(PRM)은 LLM(대형 언어 모델) 생성의 중간 단계를 평가하여 올바른 추론 경로를 선택하는 데 도움을 주도록 설계되었습니다. 이 접근 방식은 다른 애플리케이션에서의 PRM의 성공을 기반으로 합니다. 구체적으로 PRM은 현재 추론 경로
와 잠재적인 다음 단계를 입력으로 사용하고 보상 값
PRM은 현재 추론 궤적 전체를 고려하여 새로운 단계를 평가하고 전체 경로에 대한 일관성과 충실도를 장려합니다. 높은 보상 값은 새로운 단계
)가 주어진 추론 경로 에 대해 정확할 가능성이 높으므로 확장 경로를 추가 탐색할 가치가 있음을 나타냅니다. 반대로, 낮은 보상 값은 새 단계가 잘못되었을 수 있음을 나타내며, 이는 이 경로를 따르는 솔루션도 잘못될 수 있음을 의미합니다.
M* 알고리즘은 올바른 솔루션을 찾을 때까지 반복하는 두 가지 주요 단계로 구성됩니다.
1 추론 경로 확장: 각 반복에서 기본 LLM은 현재 추론 경로의 다음 단계를 생성합니다. .
2. 평가 및 선택: PRM을 사용하여 생성된 단계를 평가하고 이러한 평가를 기반으로 다음 반복에 대한 추론 경로를 선택합니다.
확장할 추론 경로를 선택한 후 LLM에서 다음 단계를 수집하기 위한 프롬프트 템플릿(예 3.1)을 설계했습니다. 예에서 볼 수 있듯이 LLM은 원래 질문을 {질문}으로 처리하고 현재 추론 경로를 {답변}으로 처리합니다. 알고리즘의 첫 번째 반복에서 선택된 노드는 질문만 포함하는 루트 노드이므로 {답변}은 비어 있습니다. 추론 경로 의 경우 LLM은 N개의 중간 단계를 생성하고 이를 현재 노드의 하위 항목으로 추가합니다. 알고리즘의 다음 단계에서는 새로 생성된 하위 노드가 평가되고 추가 확장을 위해 새 노드가 선택됩니다. 또한 단계를 생성하는 또 다른 방법은 단계 마커를 사용하여 LLM을 미세 조정하는 것임을 깨달았습니다. 그러나 이는 LLM의 추론 능력을 감소시킬 수 있으며 더 중요한 것은 가중치를 수정하지 않고 LLM의 추론 능력을 향상시키려는 이 기사의 초점에 어긋난다는 것입니다. 추론 트리를 확장한 후 사전 훈련된 절차적 감독 보상 모델(PRM)을 사용하여 새로 생성된 각 단계를 평가합니다. 앞서 언급했듯이 PRM은 경로(path)와 단계(step)를 취하고, 그에 상응하는 보상 값을 반환합니다. 평가 후 확장할 다음 노드를 선택하려면 트리 검색 알고리즘이 필요합니다. 우리의 프레임워크는 특정 검색 알고리즘에 의존하지 않으며 이 작업에서는 Beam Search와 Levin Tree Search라는 두 가지 최선의 검색 방법을 인스턴스화합니다. GSM8K 및 MATH 데이터세트에 대한 광범위한 평가를 통해 M*이 오픈 소스 모델(예: LLaMA-2)의 추론 기능을 크게 향상시켰으며 그 성능도 비슷한 것으로 나타났습니다. 더 큰 비공개 소스 모델(예: GPT-3.5 및 Grok-1)과 비슷하면서도 모델 크기와 계산 비용을 크게 줄입니다. 이러한 발견은 계산 리소스를 미세 조정에서 추론 시간 검색으로 전환하여 효율적인 추론 향상 기술에 대한 향후 연구를 위한 새로운 길을 여는 잠재력을 강조합니다.
표 1은 GSM8K 및 MATH 추론 벤치마크에서 다양한 방식의 비교 결과를 보여줍니다. 각 항목의 숫자는 해결된 문제의 비율을 나타냅니다. SC@32 표기법은 32개 후보 결과 간의 자체 일관성을 나타내고, n-shot은 소수 예의 결과를 나타냅니다. CoT-SC@16은 16개의 CoT(사상 사슬) 후보 결과 간의 자체 일관성을 나타냅니다. BS@16은 각 단계 수준에서 16개의 후보 결과를 포함하는 빔 검색 방법을 나타내고, LevinTS@16은 동일한 수의 후보 결과를 사용하는 레빈 트리 검색 방법을 자세히 설명합니다. MATH 데이터 세트에서 GPT-4에 대한 최신 결과가 GPT-4-turbo-0409라는 점은 주목할 가치가 있습니다. 이는 GPT-4 제품군 중 최고의 성능을 나타내기 때문에 특히 강조합니다.
그림 3 단계별 후보자 수가 변함에 따라 M* 성과가 어떻게 변하는지 연구합니다. 기본 모델로 Llama-2-13B를 선택하고 검색 알고리즘으로 빔 검색(BS)을 각각 선택했습니다.
그림 4 MATH 데이터 세트에 대한 Llama-2 및 Llama-3 모델 계열의 스케일링 법칙. 모든 결과는 원본 소스에서 파생됩니다. 우리는 Scipy 도구와 로그 함수를 사용하여 적합 곡선을 계산합니다.
표 2 질문에 답변할 때 다양한 방법으로 생성된 평균 토큰 수본 논문에서는 추론 능력 향상을 위한 새로운 검색 기반 추론 프레임워크인 MindStar(M*)를 소개합니다. 사전 훈련된 대규모 언어 모델. 추론 작업을 검색 문제로 처리하고 프로세스 감독의 보상 모델을 활용함으로써 M*은 추론 트리 공간을 효율적으로 탐색하여 최적에 가까운 경로를 식별합니다. 빔 검색과 레빈 트리 검색의 아이디어를 결합하면 검색 효율성이 더욱 향상되고 제한된 계산 복잡성 내에서 최상의 추론 경로를 찾을 수 있습니다. 광범위한 실험 결과에 따르면 M*은 오픈 소스 모델의 추론 기능을 크게 향상시키며 그 성능은 더 큰 폐쇄 소스 모델과 비슷하면서도 모델 크기와 계산 비용을 크게 줄입니다. 이러한 연구 결과는 컴퓨팅 리소스를 미세 조정에서 추론 시간 검색으로 전환하는 것이 큰 잠재력을 가지며 효율적인 추론 향상 기술에 대한 향후 연구를 위한 새로운 길을 열어준다는 것을 보여줍니다. [1] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei 및 Paul F Christiano. 신경 정보 처리 시스템의 발전, 33:3008–3021, 2020.[2] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray 등 인간의 피드백을 통해 지침을 따르도록 언어 모델 교육. 신경 정보 처리 시스템의 발전, 35:27730–27744, 2022. [3] Ziyang Luo, Can Xu , Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin 및 Daxin Jiang. Wizardcoder: evol-instruct로 코드 대규모 언어 모델 강화: arXiv 사전 인쇄 arXiv:2306.08568, 2023. [4] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. arXiv에서 훈련된 대규모 언어 모델 평가. preprint arXiv:2107.03374, 2021.[5] Carlos Gómez-Rodríguez 및 Paul Williams: 창의적인 글쓰기에 대한 llms의 종합 평가: 2310.08433, 2023. [6] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller 및 Weiyang Liu: 대규모 언어 모델에 대한 부트스트랩 수학 질문. 사전 인쇄 arXiv:2309.12284, 2023. [7] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Y Wu 및 Daya Guo: Deepseekmath의 한계를 뛰어넘다. 개방형 언어 모델의 수학적 추론. arXiv:2402.03300, 2024.[8] Keiran Paster, Marco Dos Santos, Zhangir Azerbayev 및 Jimmy Ba. Openwebmath: 고품질 수학적 웹 텍스트의 공개 데이터세트 . arXiv 사전 인쇄 arXiv:2310.06786, 2023.[9] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu 및 Zhifang Sui: 사람의 주석 없이 LLM을 단계별로 검증하고 강화합니다. CoRR, abs/2312.08935, 2023.[10] Meta AI 소개: 현재까지 공개된 가장 유능한 LLM, 2024년 4월. URL https://ai.meta.com/blog/meta-llama-3/ 접속일: 2024-04-30.위 내용은 LLM 추론을 탐색할 수 있는 Huawei Noah의 비밀 무기인 OpenAI의 Q*가 가장 먼저 출시됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






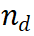
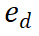
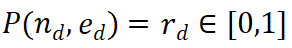
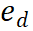
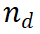
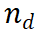 LLM에서 다음 단계를 수집하기 위한 프롬프트 템플릿(예 3.1)을 설계했습니다. 예에서 볼 수 있듯이 LLM은 원래 질문을 {질문}으로 처리하고 현재 추론 경로를 {답변}으로 처리합니다. 알고리즘의 첫 번째 반복에서 선택된 노드는 질문만 포함하는 루트 노드이므로 {답변}은 비어 있습니다. 추론 경로
LLM에서 다음 단계를 수집하기 위한 프롬프트 템플릿(예 3.1)을 설계했습니다. 예에서 볼 수 있듯이 LLM은 원래 질문을 {질문}으로 처리하고 현재 추론 경로를 {답변}으로 처리합니다. 알고리즘의 첫 번째 반복에서 선택된 노드는 질문만 포함하는 루트 노드이므로 {답변}은 비어 있습니다. 추론 경로  의 경우 LLM은 N개의 중간 단계를 생성하고 이를 현재 노드의 하위 항목으로 추가합니다. 알고리즘의 다음 단계에서는 새로 생성된 하위 노드가 평가되고 추가 확장을 위해 새 노드가 선택됩니다. 또한 단계를 생성하는 또 다른 방법은 단계 마커를 사용하여 LLM을 미세 조정하는 것임을 깨달았습니다. 그러나 이는 LLM의 추론 능력을 감소시킬 수 있으며 더 중요한 것은 가중치를 수정하지 않고 LLM의 추론 능력을 향상시키려는 이 기사의 초점에 어긋난다는 것입니다.
의 경우 LLM은 N개의 중간 단계를 생성하고 이를 현재 노드의 하위 항목으로 추가합니다. 알고리즘의 다음 단계에서는 새로 생성된 하위 노드가 평가되고 추가 확장을 위해 새 노드가 선택됩니다. 또한 단계를 생성하는 또 다른 방법은 단계 마커를 사용하여 LLM을 미세 조정하는 것임을 깨달았습니다. 그러나 이는 LLM의 추론 능력을 감소시킬 수 있으며 더 중요한 것은 가중치를 수정하지 않고 LLM의 추론 능력을 향상시키려는 이 기사의 초점에 어긋난다는 것입니다. 


