
개발자들은 신이 납니다! Meta의 최신 LLM 컴파일러 릴리스는 77%의 자동 튜닝 효율성을 달성했습니다.

- 王林원래의
- 2024-07-01 18:16:391291검색
Meta는 프로그래머가 코드를 보다 효율적으로 작성할 수 있도록 돕는 멋진 LLM 컴파일러를 개발했습니다.







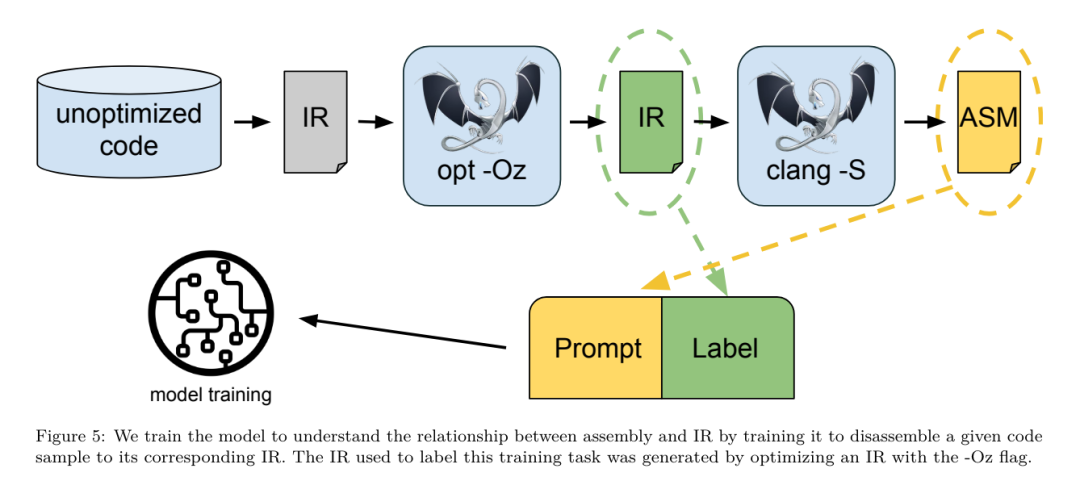
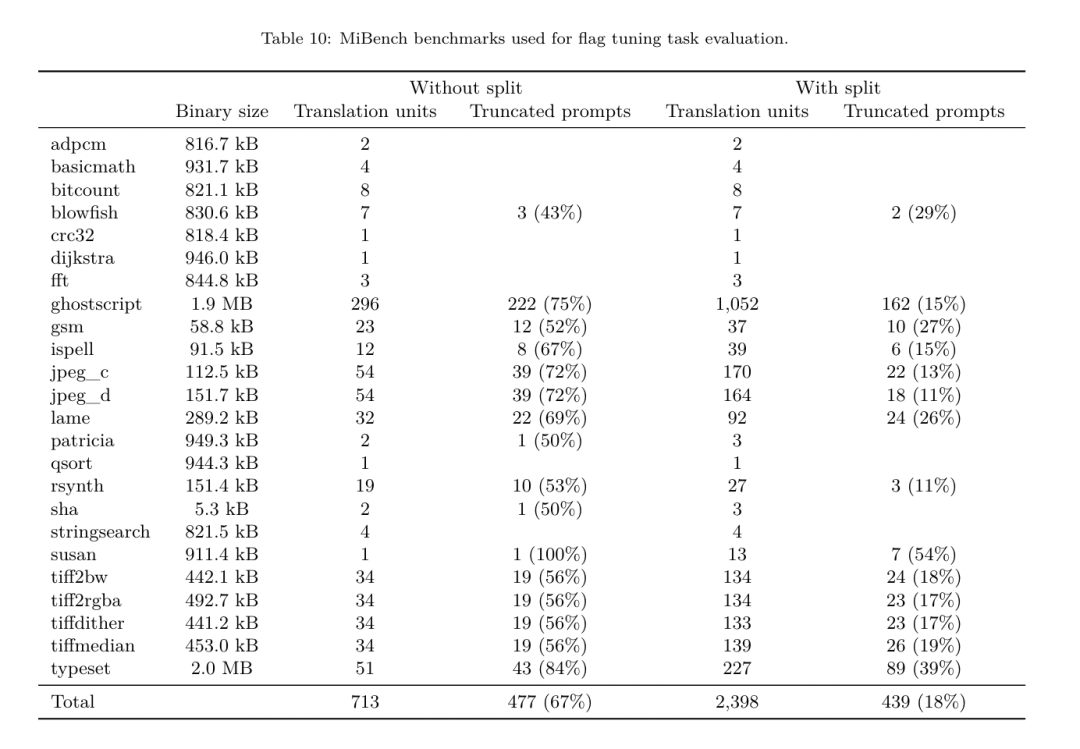
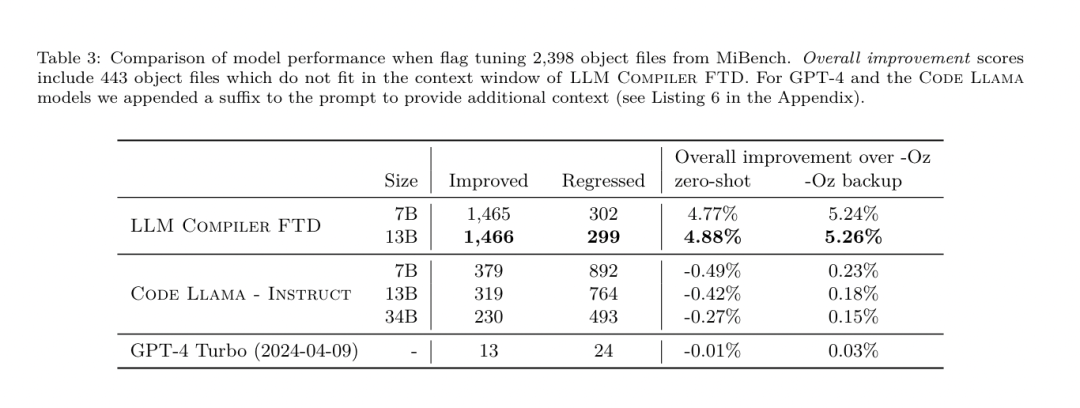
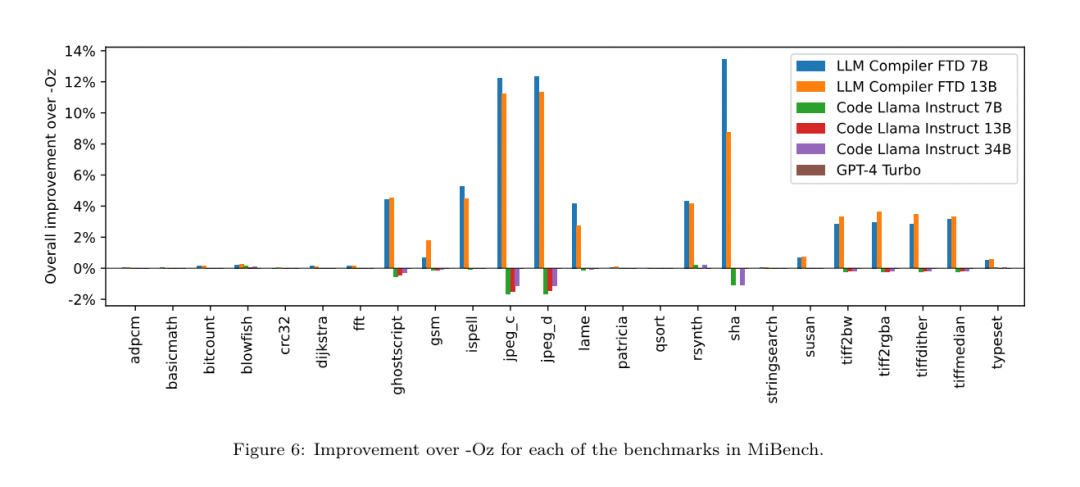



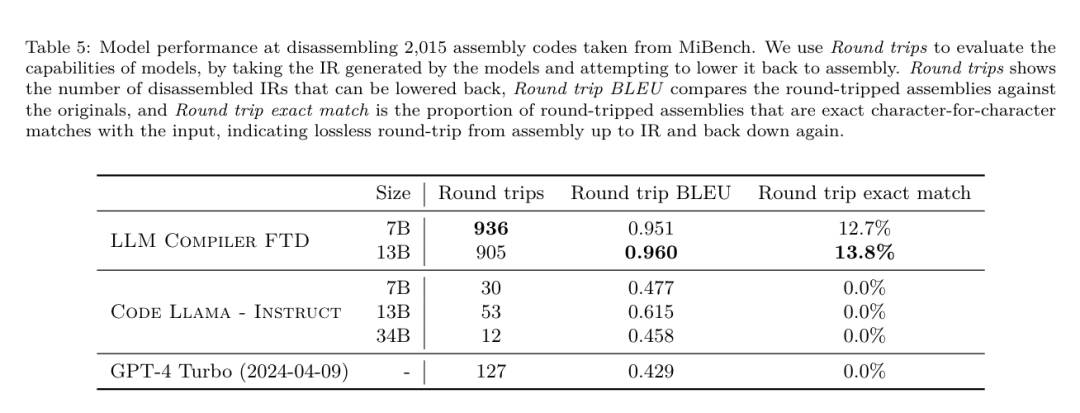


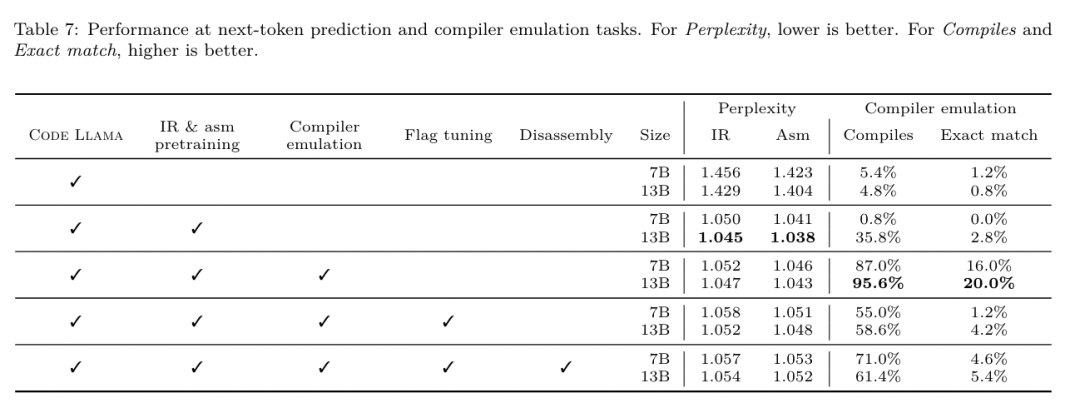
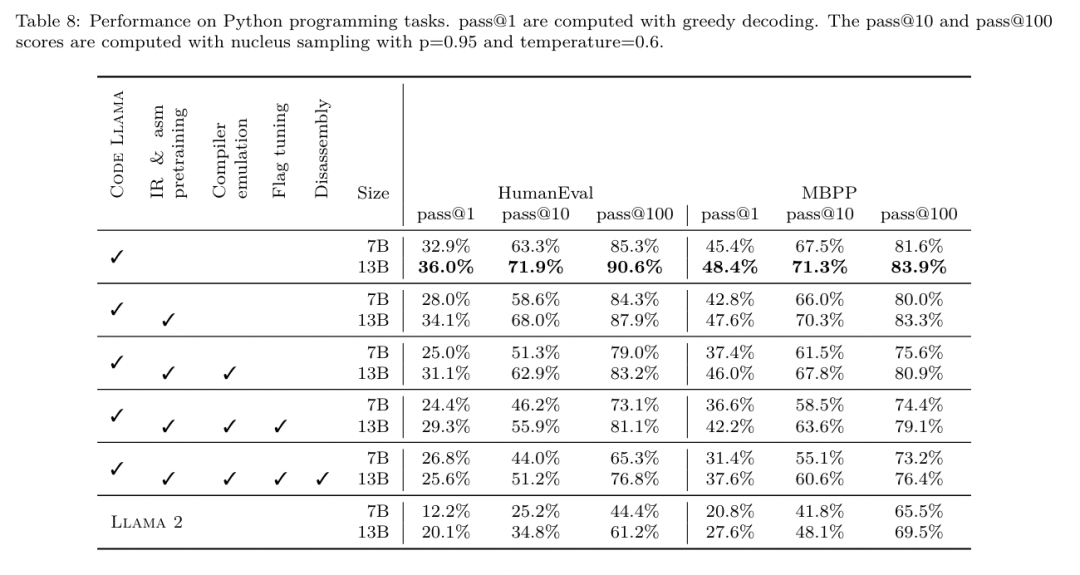
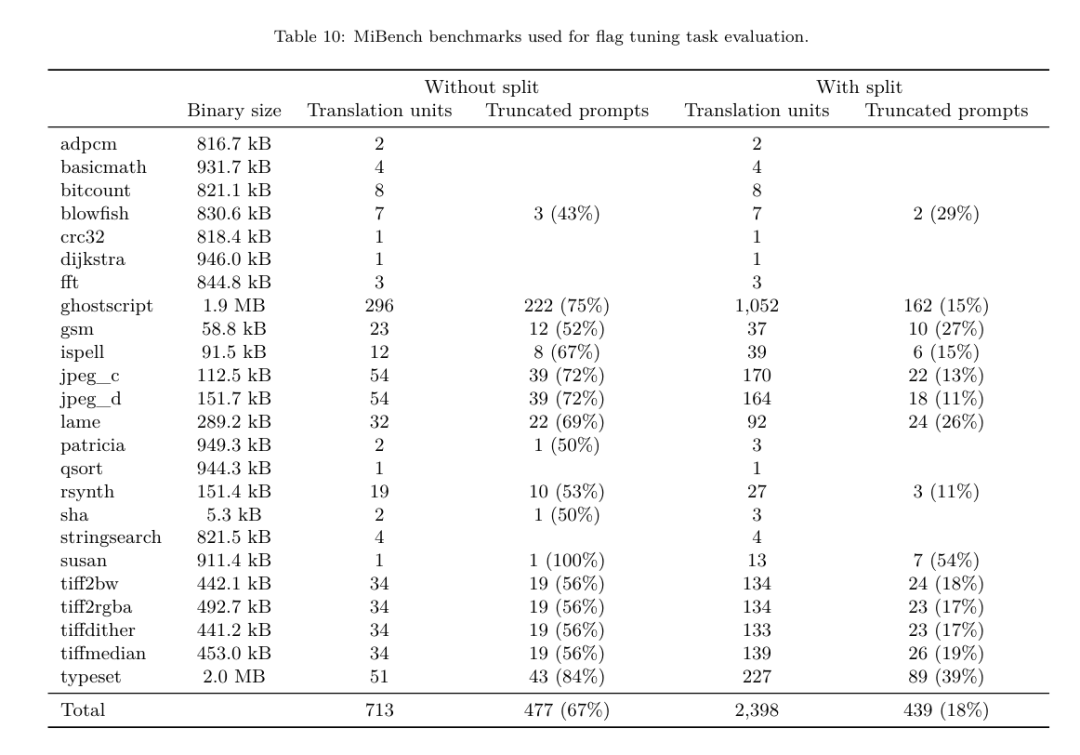
https://ai.meta.com / 연구/출판/메타 -대형 언어 모델-컴파일러-기초-모델-컴파일러-최적화/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fair
위 내용은 개발자들은 신이 납니다! Meta의 최신 LLM 컴파일러 릴리스는 77%의 자동 튜닝 효율성을 달성했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
이전 기사:중국과학원팀의 Transformer 딥러닝 모델은 기존 방법보다 30배 더 효율적으로 당-단백질 상호작용 위치를 예측합니다.다음 기사:중국과학원팀의 Transformer 딥러닝 모델은 기존 방법보다 30배 더 효율적으로 당-단백질 상호작용 위치를 예측합니다.
관련 기사
더보기- 인텔은 응용 사례, 혁신적인 제품 및 솔루션을 해석하여 4가지 주요 비즈니스 영역에서 업계에 대한 심층적인 통찰력을 보유하고 있습니다丨인텔 비전
- 10월의 새로운 규칙이 나왔습니다! 새로운 도로교통표지판, 인공지능 산업 등을 접목
- 아우디 임원: 반도체 부족으로 인해 독일 자동차 산업은 수년 동안 계속되는 병목 현상에 빠졌습니다.
- 바이두, 중국 최초의 '산업 수준' 의료 모델 '영의학 모델' 출시: 바이두, 중국 최초의 '산업 수준' 의료 모델 '영의학 모델' 출시
- 2023년 제1회 장강 삼각주 로봇 산업 체인 협력 개발 정상 포럼이 안후이성 우후에서 성공적으로 개최되었습니다.