
Bengio 등의 새로운 연구: Attention은 RNN으로 간주될 수 있습니다. 새 모델은 Transformer와 비슷하지만 메모리를 매우 절약합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-09 16:50:32687검색

논문 주소: https://arxiv.org/pdf/2405.13956 논문 제목: RNN으로 주목
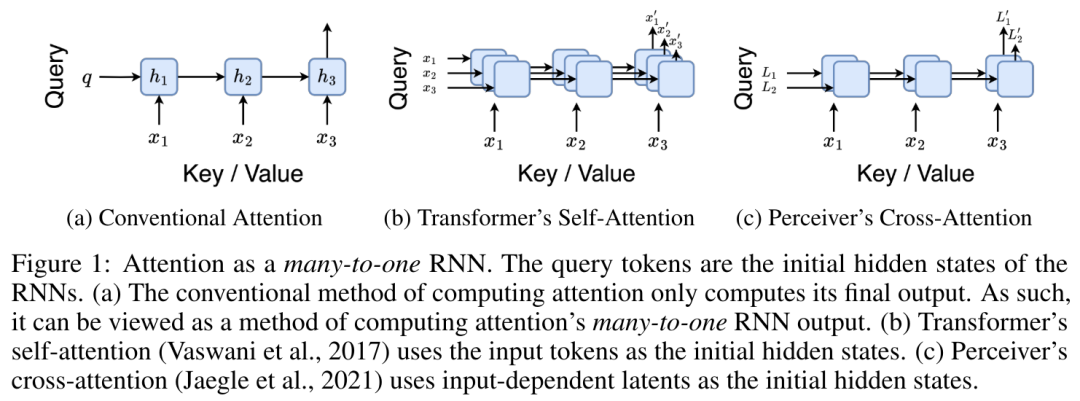
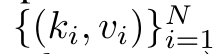 단일 출력 o_N = Attention(q, k_1:N, v_1:N)에 매핑됩니다. s_i = 도트(q, k_i)인 경우 출력 o_N은 다음과 같이 표현될 수 있습니다.
단일 출력 o_N = Attention(q, k_1:N, v_1:N)에 매핑됩니다. s_i = 도트(q, k_i)인 경우 출력 o_N은 다음과 같이 표현될 수 있습니다. 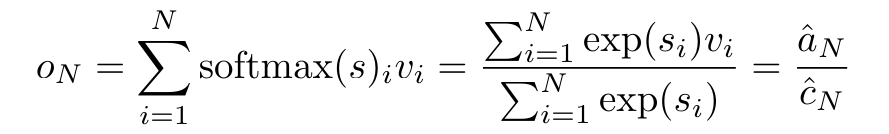
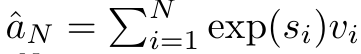 이고 분모는
이고 분모는 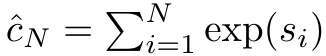 입니다. Attention을 RNN으로 생각하면
입니다. Attention을 RNN으로 생각하면 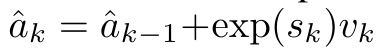 및
및  는 k = 1,...,...일 때 롤링 합산 방식으로 반복적으로 계산할 수 있습니다. 그러나 실제로 이 구현은 불안정하며 제한된 정밀도 표현과 잠재적으로 매우 작거나 매우 큰 지수(예: exp(s))로 인해 수치적 문제를 겪습니다. 이 문제를 완화하기 위해 저자는 누적 최대항
는 k = 1,...,...일 때 롤링 합산 방식으로 반복적으로 계산할 수 있습니다. 그러나 실제로 이 구현은 불안정하며 제한된 정밀도 표현과 잠재적으로 매우 작거나 매우 큰 지수(예: exp(s))로 인해 수치적 문제를 겪습니다. 이 문제를 완화하기 위해 저자는 누적 최대항 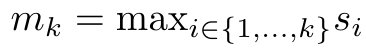 을 사용하여
을 사용하여 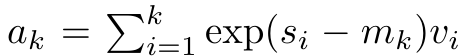 및
및 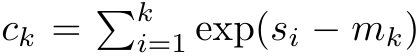 을 계산하는 재귀 공식을 다시 작성합니다. 최종 결과가 동일하다는 점은 주목할 가치가 있습니다.
을 계산하는 재귀 공식을 다시 작성합니다. 최종 결과가 동일하다는 점은 주목할 가치가 있습니다. 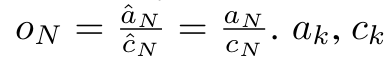 m_k의 루프 계산은 다음과 같습니다.
m_k의 루프 계산은 다음과 같습니다. 

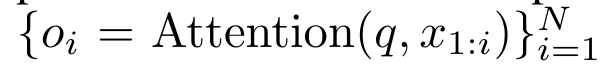 으로 먼저 소개했습니다. 이를 위해 저자는 상관 연산자 ⊕를 통해 N개의 연속 데이터 포인트에서 N개의 접두어를 계산하는 병렬 컴퓨팅 방법인 병렬 접두어 스캔 알고리즘(알고리즘 1 참조)을 활용합니다.이 알고리즘은
으로 먼저 소개했습니다. 이를 위해 저자는 상관 연산자 ⊕를 통해 N개의 연속 데이터 포인트에서 N개의 접두어를 계산하는 병렬 컴퓨팅 방법인 병렬 접두어 스캔 알고리즘(알고리즘 1 참조)을 활용합니다.이 알고리즘은 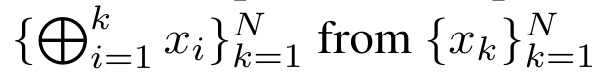

 을 효율적으로 계산할 수 있는데, 여기서
을 효율적으로 계산할 수 있는데, 여기서 
 ,
, 
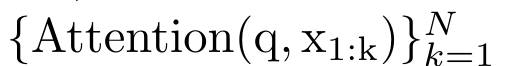 를 효율적으로 계산하기 위해 병렬 스캔 알고리즘을 통해
를 효율적으로 계산하기 위해 병렬 스캔 알고리즘을 통해 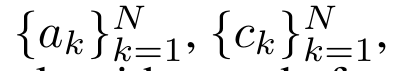 및
및  를 계산한 다음 a_k 및 c_k와 결합하여 계산할 수 있습니다.
를 계산한 다음 a_k 및 c_k와 결합하여 계산할 수 있습니다.  . ㅋㅋㅋ
. ㅋㅋㅋ 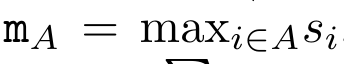
 ,
, 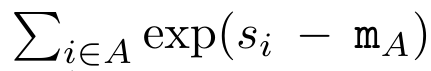
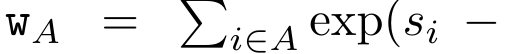 .
. 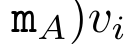
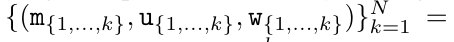
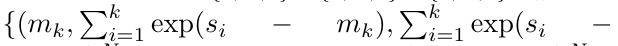
 을 출력합니다.
을 출력합니다. 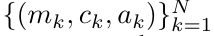 라고도 합니다. 출력 튜플의 마지막 두 값을 결합하면
라고도 합니다. 출력 튜플의 마지막 두 값을 결합하면 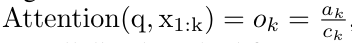 가 검색되어 다대다 RNN으로서 주의를 계산하는 효율적인 병렬 방법이 됩니다(그림 3).
가 검색되어 다대다 RNN으로서 주의를 계산하는 효율적인 병렬 방법이 됩니다(그림 3). 
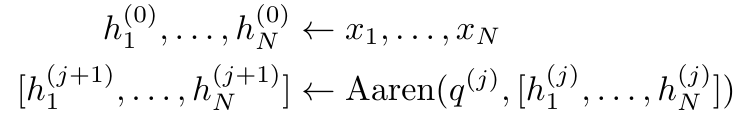
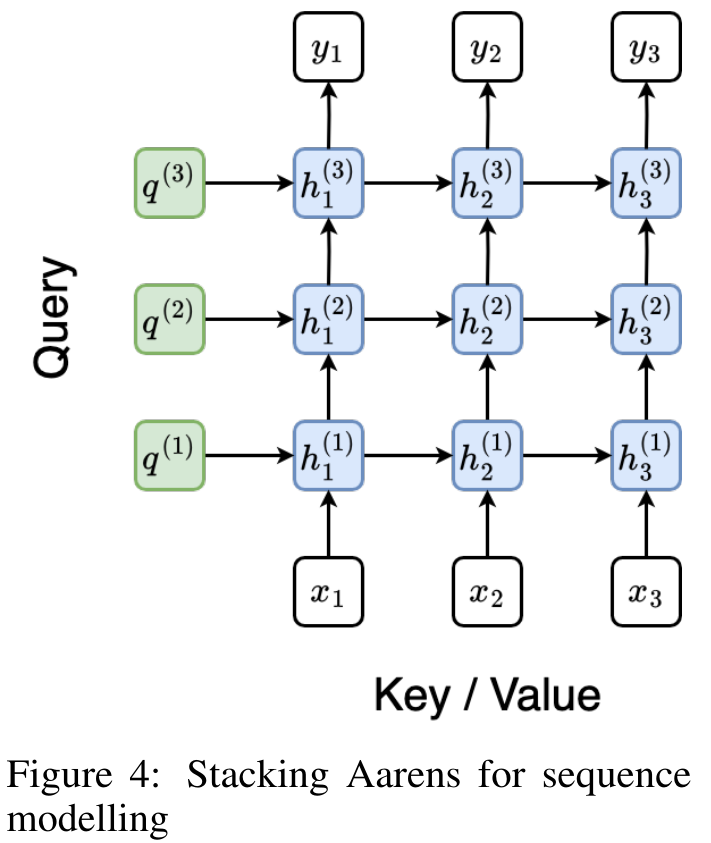

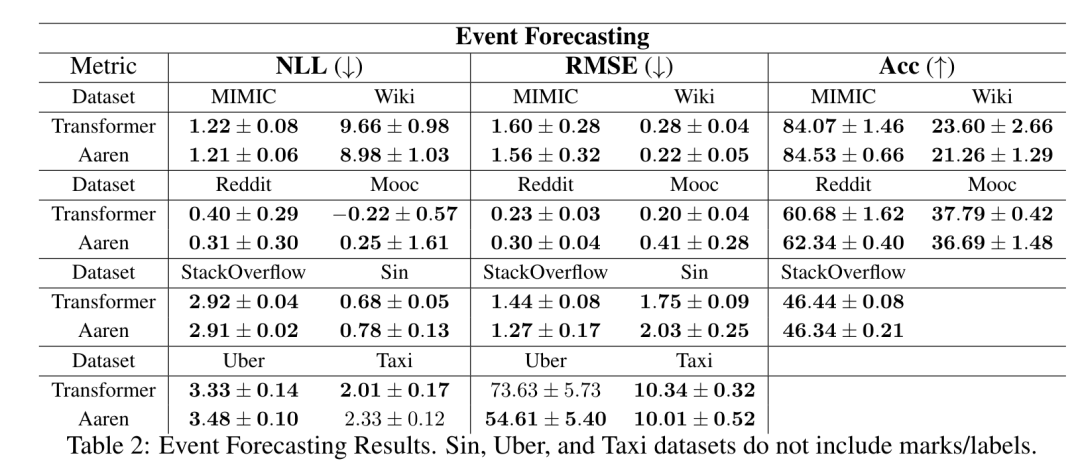
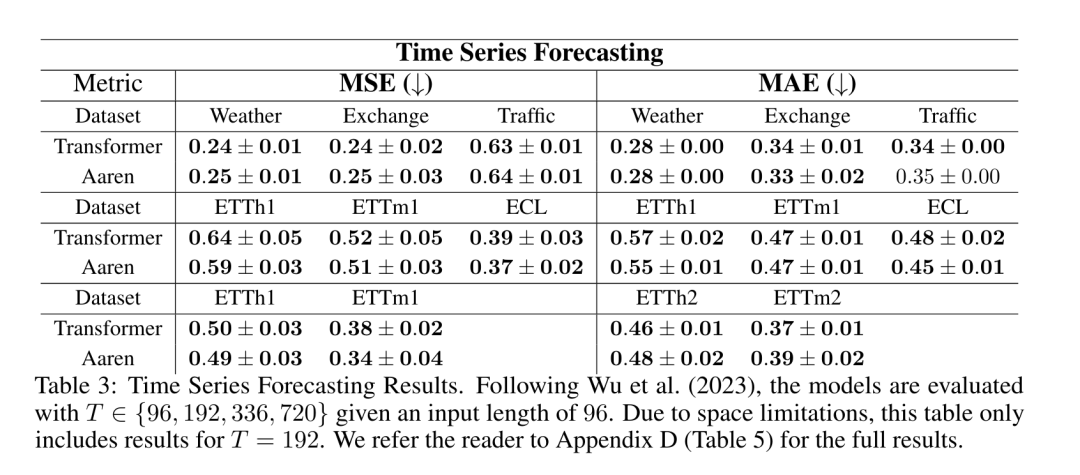
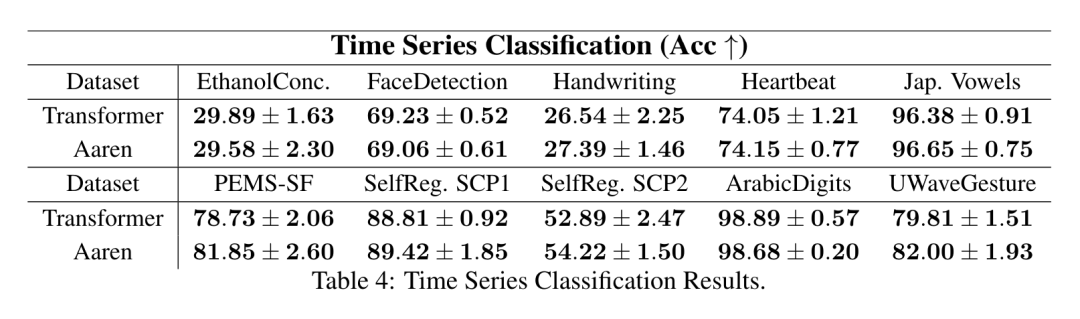
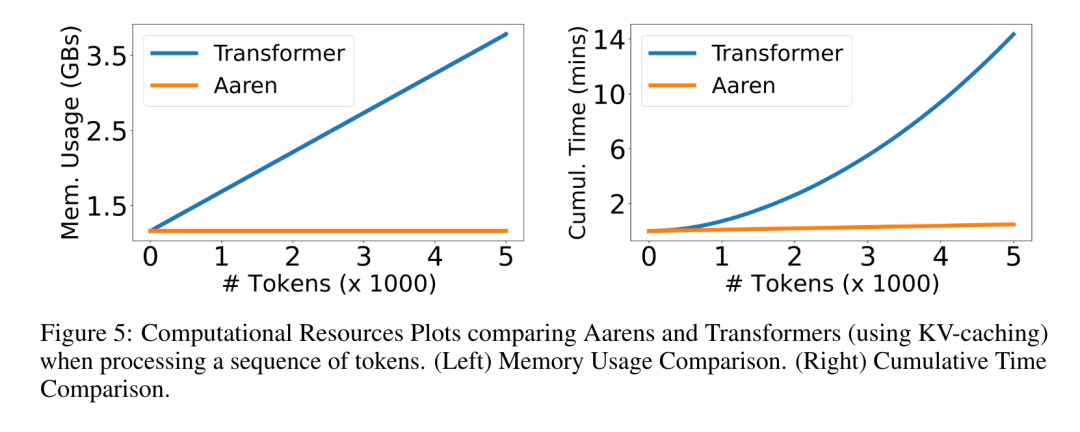
위 내용은 Bengio 등의 새로운 연구: Attention은 RNN으로 간주될 수 있습니다. 새 모델은 Transformer와 비슷하지만 메모리를 매우 절약합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.