
Hot ChatTTS는 오픈소스 음성 상한선을 돌파하고 3일 만에 별 9,000개를 획득했습니다.

- PHPz원래의
- 2024-06-07 17:10:54662검색
사람 간 소통의 미래는 이런 모습일까요?
최근에는 ChatTTS라는 텍스트 음성 변환 프로젝트가 인기를 끌면서 모두의 큰 관심을 받고 있습니다. 단 3일 만에 GitHub에서 별 9.2,000개를 얻었습니다.
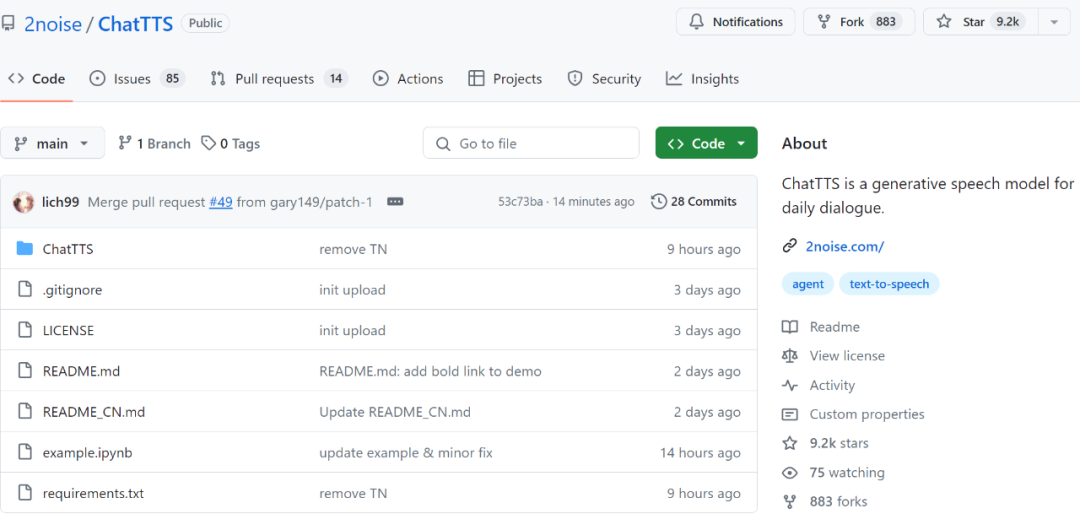
프로젝트 주소: https://github.com/2noise/ChatTTS/tree/main
저자 자신도 x에서 ChatTTS가 오픈 소스 한계를 돌파했다고 말했습니다. 그러나 현재 오픈 소스인 것은 SFT가 감독하고 미세 조정하지 않은 기본 모델일 뿐입니다.
이 프로젝트는 텍스트를 음성으로 변환합니다.  ChatTTS는 중국어뿐만 아니라 영어도 사용할 수 있으므로 세밀한 제어도 지원합니다. 말하기 일시 정지와 모달 입자는 매우 재생 가능합니다.
ChatTTS는 중국어뿐만 아니라 영어도 사용할 수 있으므로 세밀한 제어도 지원합니다. 말하기 일시 정지와 모달 입자는 매우 재생 가능합니다. 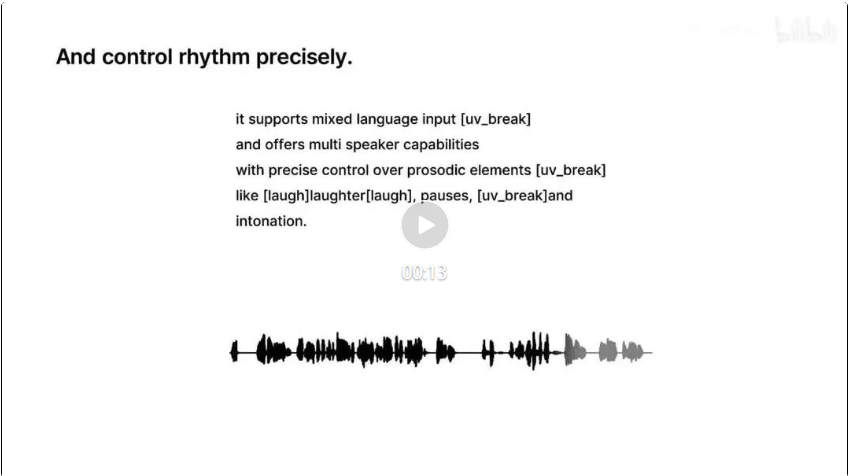 절판된 사람들의 목소리를 재현할 수 있습니다. 스티브 잡스의 개발 컨퍼런스를 다시 듣고 싶다면 언제든지 들으실 수 있습니다. 스위프트의 목소리를 흉내내서 들어보면 억양이나 톤의 변화 모두 스위프트에 가깝고, AI의 느낌은 거의 전혀 없습니다.
절판된 사람들의 목소리를 재현할 수 있습니다. 스티브 잡스의 개발 컨퍼런스를 다시 듣고 싶다면 언제든지 들으실 수 있습니다. 스위프트의 목소리를 흉내내서 들어보면 억양이나 톤의 변화 모두 스위프트에 가깝고, AI의 느낌은 거의 전혀 없습니다.  당신은 중국어와 영어도 잘 구사할 수 있습니다. 이 반은 영어이고 반은 중국어인 억양으로 ChatTTS의 언어 능력이 다음 단계에 도달했습니다.站 위의 오디오는 스테이션 B에서 나온 것입니다: https://www.bilibili.com/video/bv1zn4y1o7iv/?share_source=copy_web&vd_source=983EC32A3036B1CF2699E4FDBCE3C28 디스플레이 중에 Chattts가 자연스러운 부드러움을 얻을 수 있음을 알 수 있습니다. 음성 합성은 동시에 여러 스피커를 지원합니다. 시간, 웃음, 일시정지, 삽입된 단어 등 세밀한 운율 기능을 예측하고 제어할 수 있습니다. ChatTTS는 운율 측면에서 대부분의 오픈 소스 TTS 모델을 능가합니다.
당신은 중국어와 영어도 잘 구사할 수 있습니다. 이 반은 영어이고 반은 중국어인 억양으로 ChatTTS의 언어 능력이 다음 단계에 도달했습니다.站 위의 오디오는 스테이션 B에서 나온 것입니다: https://www.bilibili.com/video/bv1zn4y1o7iv/?share_source=copy_web&vd_source=983EC32A3036B1CF2699E4FDBCE3C28 디스플레이 중에 Chattts가 자연스러운 부드러움을 얻을 수 있음을 알 수 있습니다. 음성 합성은 동시에 여러 스피커를 지원합니다. 시간, 웃음, 일시정지, 삽입된 단어 등 세밀한 운율 기능을 예측하고 제어할 수 있습니다. ChatTTS는 운율 측면에서 대부분의 오픈 소스 TTS 모델을 능가합니다.  현재 ChatTTS는 중국어와 영어를 지원합니다. 가장 큰 모델은 100,000시간이 넘는 중국어 및 영어 데이터를 사용하여 학습되었습니다. HuggingFace의 오픈 소스 버전은 40,000시간 동안 학습되었지만 아직 SFT가 되지 않은 버전입니다.
현재 ChatTTS는 중국어와 영어를 지원합니다. 가장 큰 모델은 100,000시간이 넘는 중국어 및 영어 데이터를 사용하여 학습되었습니다. HuggingFace의 오픈 소스 버전은 40,000시간 동안 학습되었지만 아직 SFT가 되지 않은 버전입니다.


 온라인 체험 주소 : https://huggingface.co/spaces/Dzkaka/ChatTTS
온라인 체험 주소 : https://huggingface.co/spaces/Dzkaka/ChatTTS
ChatTTS에는 주로 두 가지 핵심 기능이 있습니다. 첫 번째는 텍스트 음성 변환이고, 두 번째는 대규모 언어 모델을 사용한 실시간 음성 대화입니다. 이러한 기능 외에도 "Audio Seed"에서 디지털로 지정된 스피커의 음색을 조정하거나 주사위를 굴려 무작위로 생성할 수 있습니다. 그러나 많은 테스터들은 매번 동일한 매개 변수를 사용하면 생성되는 톤이 반드시 고정되지는 않는다고 말했습니다.

2Noise에서는 현재 사운드 복제를 지원하지만 더 많은 양의 데이터가 필요하다고 합니다.
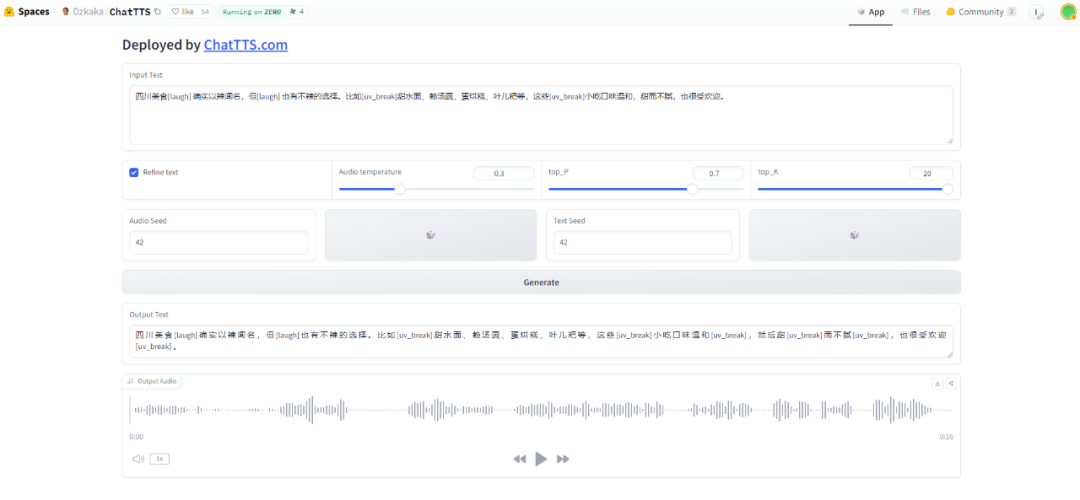
텍스트 상자에 텍스트를 입력하면 ChatTTS가 자동으로 운율과 일시정지를 생성하고 "then"과 같은 모달 입자도 추가합니다. 입력할 때 텍스트에 [laugh] 및 [uv_break]를 추가하면 ChatTTS를 수동으로 제어하여 말할 때 약간의 "웃음"을 생성할 수 있습니다. 
ChatTTS는 아직 상대적으로 긴 텍스트를 처리할 수 없습니다. 일부 네티즌들이 오디오북에 도전해 달라고 요청했는데 초기 버전에서는 30초 이상의 오디오를 생성할 수 없어 수동으로 복구해야 한다는 사실을 발견했습니다. 상대적으로 긴 텍스트를 접할 때 ChatTTS의 단어 분할에도 문제가 있습니다.


위 내용은 Hot ChatTTS는 오픈소스 음성 상한선을 돌파하고 3일 만에 별 9,000개를 획득했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!