



前書きと著者の個人的な理解
この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題の解決、つまり MLLM を 2D 理解から 3D 空間に拡張することに特化しています。質問。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。
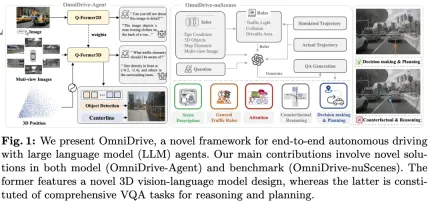
現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度の制限、LLM シーケンスの長さの制限により、通常、(たとえば) 低解像度の画像入力のみを処理できます。ただし、自動運転アプリケーションでは、車両が長距離にわたって環境を認識し、安全な意思決定を行えるようにするために、高解像度のマルチビュー ビデオ入力が必要です。 さらに、既存の 2D モデル アーキテクチャの多くは、膨大なコンピューティング リソースとストレージ リソースを必要とするため、これらの入力を効率的に処理するのに苦労しています。 これらの問題に対処するために、研究者は新しいモデル アーキテクチャとストレージ リソースの開発に取り組んでいます。
これに関連して、このペーパーでは、Q-Former スタイルの設計を利用した、新しい 3D MLLM アーキテクチャを提案します。このアーキテクチャでは、クロスアテンション デコーダを採用して高解像度の視覚情報をスパース クエリに圧縮し、高解像度の入力への拡張が容易になります。このアーキテクチャは、すべてスパース 3D クエリ メカニズムを活用しているため、DETR3D、PETR(v2)、StreamPETR、Far3D などのビュー モデル ファミリと類似点があります。これらのクエリに 3D 位置エンコーディングを追加し、マルチビュー入力と対話することにより、私たちのアーキテクチャは 3D 空間の理解を達成し、それによって 2D 画像の事前トレーニングされた知識をより適切に活用します。
モデル アーキテクチャの革新に加えて、この記事では、より挑戦的なベンチマークである OmniDrive-nuScenes も提案します。このベンチマークは、3D 空間の理解と長距離推論を必要とする一連の複雑なタスクをカバーし、解と軌跡をシミュレートすることで結果を評価する反事実推論ベンチマークを導入しています。このベンチマークは、現在のオープンエンド評価における単一のエキスパート軌道への偏りの問題を効果的に補い、エキスパート軌道への過剰適合を回避します。
このペーパーでは、LLM エージェントに基づいた効果的な 3D 推論および計画モデルを提供し、自動運転分野のさらなる発展を推進する、より挑戦的なベンチマークを構築する、包括的なエンドツーエンドの自動運転フレームワークである OmniDrive について紹介します。具体的な貢献は次のとおりです:
- 目標検出、車線検出、3D 視覚位置決め、意思決定、計画など、さまざまな運転関連タスクに適した 3D Q-Former アーキテクチャ を提案しました。
- OmniDrive-nuScenes ベンチマークを紹介します。これは、正確な 3D 空間情報をカバーし、計画関連の課題を解決するために設計された最初の QA ベンチマークです。
- 計画タスクで最高のパフォーマンスを達成します。
OmniDriveの詳しい説明
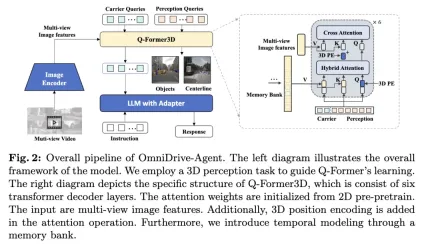
全体構成
この記事で提案するOmniDrive-Agentは、Q-Formerとクエリベースの3D認識モデルの利点を組み合わせて、マルチで3D空間情報を効率的に取得します。 - 画像の特徴を表示し、自動運転における 3D 認識と計画タスクを解決します。全体的なアーキテクチャを図に示します。
- ビジュアル エンコーダー: まず、共有ビジュアル エンコーダーを使用して、マルチビュー画像の特徴を抽出します。
- 位置エンコーディング: 抽出された画像特徴は、位置エンコーディングとともに Q-Former3D に入力されます。
- Q-Former3Dモジュール: このうち、はスプライシング操作を表します。簡潔にするために、位置エンコーディングは式から省略されています。このステップの後、クエリ コレクションは対話型 になります。このうち、は3D位置エンコーディングを表し、は多視点画像の特徴を表します。
- マルチビュー画像の特徴収集: 次に、これらのクエリはマルチビュー画像から情報を収集します:
- クエリの初期化とセルフアテンション: Q-Former3D では、検出クエリとベクトル クエリが初期化されます。
- 出力処理:
- 知覚タスク予測: 知覚クエリを使用して前景要素のカテゴリと座標を予測します。
- キャリア クエリのアライメントとテキスト生成: キャリア クエリは、単層 MLP を通じて LLM トークンのディメンション (LLaMA の 4096 ディメンションなど) にアライメントされ、さらにテキスト生成に使用されます。
- キャリアクエリの役割
このアーキテクチャ設計により、OmniDrive-Agent はマルチビュー画像から豊富な 3D 空間情報を効率的に取得し、それをテキスト生成用の LLM と組み合わせて、3D 空間認識を提供します。自動運転は新たなソリューションを提供します。
マルチタスクと時間モデリング
著者の方法は、マルチタスク学習と時間モデリングの恩恵を受けています。マルチタスク学習では、作成者は認識タスクごとに特定の Q-Former3D モジュールを統合し、統一された初期化戦略を採用できます (cref{トレーニング戦略} を参照)。さまざまなタスクで、キャリア クエリはさまざまなトラフィック要素に関する情報を収集できます。著者の実装では、中心線の構築や 3D オブジェクトの検出などのタスクがカバーされています。トレーニングおよび推論フェーズ中、これらのモジュールは同じ 3D 位置エンコーディングを共有します。 私たちの方法は、中心線の構築や 3D オブジェクトの検出などのタスクを強化します。トレーニングおよび推論フェーズ中、これらのモジュールは同じ 3D 位置エンコーディングを共有します。 私たちの方法は、中心線の構築や 3D オブジェクトの検出などのタスクを強化します。トレーニングおよび推論フェーズ中、これらのモジュールは同じ 3D 位置エンコーディングを共有します。
時間モデリングに関して、著者は上位 k の分類スコアを持つ知覚クエリをメモリ バンクに保存し、フレームごとに伝播させます。伝播されたクエリは、クロスアテンションを通じて現在のフレームの知覚クエリおよびキャリア クエリと相互作用し、それによってビデオ入力に対するモデルの処理能力が拡張されます。
トレーニング戦略
OmniDrive-Agent のトレーニング戦略は、2D 事前トレーニングと 3D 微調整の 2 つの段階に分かれています。初期段階では、著者らはまず 2D 画像タスクでマルチモーダル大規模モデル (MLLM) を事前トレーニングし、Q-Former とベクトル クエリを初期化しました。検出クエリを削除した後、OmniDrive モデルは、画像に基づいてテキストを生成できる標準の視覚言語モデルとみなすことができます。したがって、著者は LLaVA v1.5 のトレーニング戦略とデータを使用して、558K の画像とテキストのペアで OmniDrive を事前トレーニングしました。事前トレーニング中、Q-Former を除くすべてのパラメータはフリーズされたままになります。続いて、LLaVA v1.5 の命令調整データセットを使用して MLLM が微調整されました。微調整中、画像エンコーダーはフリーズしたままになり、他のパラメーターをトレーニングできます。
3D 微調整段階では、2D 意味理解機能を可能な限り維持しながら、モデルの 3D 位置決め機能を強化することが目標です。この目的を達成するために、作者は 3D 位置エンコーディングおよびタイミング モジュールをオリジナルの Q-Former に追加しました。この段階で、著者は LoRA テクノロジーを使用して、小さな学習率でビジュアル エンコーダーと大規模な言語モデルを微調整し、比較的大きな学習率で Q-Former3D をトレーニングします。これら 2 つの段階では、OmniDrive-Agent の損失計算にはテキスト生成損失のみが含まれており、BLIP-2 の対比学習およびマッチング損失は考慮されていません。
OmniDrive-nuScenes

マルチモーダル大規模モデルエージェントをベンチマーク運転するために、著者らは、高品質の視覚的な質問応答 (QA) を含む nuScenes データセットに基づく新しいベンチマークである OmniDrive-nuScenes を提案します。 3D ドメインでの認識、推論、計画タスク。
OmniDrive-nuScenes のハイライトは、GPT-4 を使用して質問と回答を生成する、完全に自動化された QA 生成プロセスです。 LLaVA と同様に、私たちのパイプラインは 3D 対応の注釈をコンテキスト情報として GPT-4 に提供します。これに基づいて、著者はさらに、GPT-4 が 3D 環境をよりよく理解できるように、追加の入力として交通ルールと計画シミュレーションを使用します。著者のベンチマークは、モデルの認識能力と推論能力をテストするだけでなく、注意力、反事実推論、および開ループ計画を含む長期的な問題を通じて 3D 空間におけるモデルの実際の空間理解と計画能力に挑戦します。これらの問題には運転計画が必要であるためです。次の数秒で、正しい答えに到達するまでのシミュレーションが行われます。
オフラインの質問と回答の生成プロセスに加えて、著者は、多様なポジショニングの質問をオンラインで生成するプロセスも提案しています。このプロセスは、モデルの 3D 空間の理解と推論能力を向上させるための暗黙的なデータ強化方法とみなすことができます。
オフラインの質問応答
オフライン QA 生成プロセスでは、作成者はコンテキスト情報を使用して nuScenes 上で QA ペアを生成します。まず、GPT-4 を使用してシーン記述を生成し、3 視点の正面図と 3 視点の背面図を 2 つの独立した画像に結合して GPT-4 に入力します。 GPT-4は、プロンプト入力により、天気、時間、シーンの種類などの情報を記述し、各視野角の方向を識別することができます。同時に、視野角による記述を回避し、相対的な内容を記述します。自車の位置。
次に、GPT-4V が交通要素間の相対的な空間関係をよりよく理解するために、著者はオブジェクトと車線境界線の間の関係をファイル ツリーのような構造に表現し、オブジェクトの 3D 境界ボックスに基づいて、その情報を自然言語記述に変換します。
その後、著者は、車線維持、左車線変更、右車線変更などのさまざまな運転意図をシミュレートして軌道を生成し、深さ優先探索アルゴリズムを使用して車線の中心線を接続して、すべての可能な運転経路を生成しました。さらに、著者は nuScenes データセット内の自車の軌道をクラスタリングし、代表的な運転経路を選択し、それらをシミュレートされた軌道の一部として使用しました。
最後に、オフライン QA 生成プロセスでさまざまなコンテキスト情報を組み合わせることで、作成者は、シーンの説明、注意対象の認識、反事実の推論、意思決定計画など、複数のタイプの QA ペアを生成できます。 GPT-4 は、シミュレーションと専門家の軌跡に基づいて脅威オブジェクトを特定し、走行経路の安全性を推論して合理的な運転提案を提供します。

オンライン質問回答
自動運転データセットの 3D 認識アノテーションを最大限に活用するために、作成者はトレーニング プロセス中にオンラインで多数の測位タスクを生成しました。これらのタスクは、モデルの 3D 空間の理解と推論機能を強化するように設計されており、次のものが含まれます:
- 2D から 3D へのローカリゼーション: 特定のカメラに 2D 境界ボックスがある場合、モデルは対応するオブジェクトの 3D 属性を提供する必要があります。カテゴリ、場所、サイズ、方向、速度が含まれます。
- 3D 距離: ランダムに生成された 3D 座標に基づいて、ターゲット位置付近の交通要素を特定し、その 3D 属性を提供します。
- レーンからオブジェクト: ランダムに選択されたレーンの中心線に基づいて、そのレーン上のすべてのオブジェクトとその 3D プロパティをリストします。
メトリクス
OmniDrive-nuScenes データセットには、シーンの説明、開ループ計画、反事実推論タスクが含まれます。各タスクは異なる側面に焦点を当てているため、単一の指標を使用して評価することが困難です。したがって、著者らはタスクごとに異なる評価基準を設計しました。
シーンの説明に関連するタスク (シーンの説明や注意オブジェクトの選択など) の場合、著者は METEOR、ROUGE、CIDEr などの一般的に使用される言語評価指標を使用して文の類似性を評価します。開ループ計画タスクでは、著者らは衝突率と道路境界横断率を使用してモデルのパフォーマンスを評価しました。反事実推論タスクでは、著者らは GPT-3.5 を使用して予測内のキーワードを抽出し、これらのキーワードをグラウンド トゥルースと比較して、さまざまな事故カテゴリの精度と再現率を計算します。
実験結果
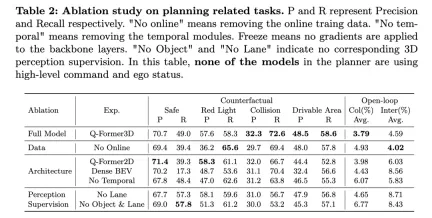
上の表は、反事実推論と開ループ計画のパフォーマンス評価を含む、計画関連のタスクに関するアブレーション研究の結果を示しています。
完全なモデルである Q-Former3D は、反事実推論と開ループ計画タスクの両方で良好に機能します。反事実推論タスクでは、モデルは「赤信号違反」と「立ち入り禁止区域違反」の両方のカテゴリで高い精度と再現率を示し、それぞれ 57.6%/58.3% と 48.5%/58.6% でした。同時に、このモデルは「衝突」カテゴリで最高の再現率 (72.6%) を達成しました。開ループ計画タスクでは、Q-Former3D は平均衝突率と道路境界交差率の両方で優れたパフォーマンスを示し、それぞれ 3.79% と 4.59% に達しました。
オンライン トレーニング データを削除した後 (オンラインなし)、反事実推論タスクの「赤信号違反」カテゴリの再現率は増加しました (65.6%) が、全体的なパフォーマンスはわずかに低下しました。衝突および通行可能領域違反の精度率と再現率は完成モデルよりわずかに低くなりますが、開ループ計画タスクの平均衝突率は 4.93% に増加し、平均道路境界横断率は 4.02% に低下しました。これは、モデルの全体的な計画パフォーマンスを向上させることの重要性に対するオンライン トレーニング データの重要性を反映しています。
アーキテクチャアブレーション実験では、Q-Former2D バージョンは「赤信号違反」カテゴリで最高の精度 (58.3%) と高い再現率 (61.1%) を達成しましたが、他のカテゴリのパフォーマンスは完全版ほど良くありませんでした。特に「衝突」および「立ち入り禁止区域違反」カテゴリーのリコールは大幅に減少しました。開ループ計画タスクでは、平均衝突率と道路境界交差率は完全モデルよりも高く、それぞれ 3.98% と 6.03% でした。
Dense BEV アーキテクチャを使用したモデルは、反事実推論タスクのすべてのカテゴリで優れたパフォーマンスを発揮しますが、全体的な再現率は低くなります。開ループ計画タスクにおける平均衝突率と道路境界交差率は、それぞれ 4.43% と 8.56% に達しました。
時間モジュールが削除されると (時間なし)、反事実推論タスクにおけるモデルのパフォーマンスが大幅に低下し、特に平均衝突率が 6.07% に増加し、道路境界越え率が 5.83% に達します。
知覚監視の観点からは、車線境界線監視 (車線なし) を削除した後、「衝突」カテゴリのモデルの再現率が大幅に低下しましたが、反事実推論タスクと開ループ計画タスクの他のカテゴリのパフォーマンスは大幅に低下しました。比較的安定。オブジェクトと車線の 3D 知覚監視を完全に削除した後 (No Object & Lane)、反事実推論タスクの各カテゴリの正解率と再現率は低下し、特に「衝突」カテゴリの再現率は 53.2% に低下しました。開ループ計画タスクにおける平均衝突率と道路境界交差率はそれぞれ 6.77% と 8.43% に増加し、完全なモデルよりも大幅に高くなりました。
上記の実験結果からわかるように、完全なモデルは反事実推論と開ループ計画タスクで良好に機能します。オンライン トレーニング データ、タイム モジュール、車線とオブジェクトの 3D 認識監視は、モデルのパフォーマンスを向上させる上で重要な役割を果たします。完成したモデルは、効率的な計画と意思決定のためにマルチモーダル情報を効果的に利用することができ、アブレーション実験の結果は、自動運転タスクにおけるこれらのコンポーネントの重要な役割をさらに検証します。
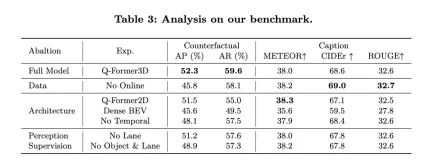
同時に、NuScenes-QA のパフォーマンスを見てみましょう。これは、オープンループ計画タスクにおける OmniDrive のパフォーマンスを実証し、他の既存の方法と比較します。結果は、OmniDrive++ (フルバージョン) がすべての指標、特に開ループ計画の平均誤差、衝突率、道路境界交差率において最高のパフォーマンスを達成し、他の方法よりも優れていることを示しています。
OmniDrive++ のパフォーマンス: OmniDrive++ モデルの L2 平均誤差は、1 秒、2 秒、3 秒の予測時間でそれぞれ 0.14、0.29、0.55 メートルで、最終的な平均誤差はわずか 0.33 メートルです。さらに、このモデルの平均衝突率と平均道路境界交差率もそれぞれ 0.30% と 3.00% に達し、他の方法よりも大幅に低くなりました。特に衝突率に関しては、OmniDrive++ は 1 秒と 2 秒の予測時間帯の両方で衝突率ゼロを達成し、その優れた計画能力と障害物回避能力を十分に発揮しました。
他の方法との比較: UniAD、BEV-Planner++、Ego-MLP などの他の高度なベンチマーク モデルと比較すると、OmniDrive++ はすべての主要な指標で優れています。 UniAD が高度なコマンドと自車ステータス情報を使用する場合、その L2 平均誤差は 0.46 メートルですが、OmniDrive++ は同じ設定でさらに低い誤差 0.33 メートルです。同時に、OmniDrive++ の衝突率と道路境界交差率も UniAD に比べて大幅に低く、特に衝突率はほぼ半分に減少します。
BEV-Planner++と比較すると、OmniDrive++のL2誤差はすべての予測期間で大幅に減少しており、特に3秒予測期間では誤差が0.57メートルから0.55メートルに減少しています。同時に、衝突率と道路境界越え率の点でも、OmniDrive++ は BEV-Planner++ より優れています。衝突率は 0.34% から 0.30% に低下し、道路境界越え率は 3.16% から 3.00% に低下しました。
アブレーション実験: OmniDrive アーキテクチャの主要モジュールがパフォーマンスに与える影響をさらに評価するために、著者は OmniDrive モデルの異なるバージョンのパフォーマンスも比較しました。 OmniDrive(高度なコマンドや自車状態情報を使用しない)は、予測誤差、衝突率、道路境界交差率の点で完成モデルに比べて大幅に劣っており、特に3秒間の予測期間におけるL2誤差が顕著です。 2.84メートル、平均衝突率は3.79%にもなります。
OmniDriveモデルのみを使用した場合(高度なコマンドや自車状態情報なし)、予測誤差、衝突率、道路境界交差率は改善されましたが、完全なモデルと比較するとまだギャップがあります。これは、高レベルのコマンドと自車の状態情報を統合することが、モデル全体の計画パフォーマンスの向上に大きな効果があることを示しています。
全体として、実験結果は、開ループ計画タスクにおける OmniDrive++ の優れたパフォーマンスを明確に示しています。 OmniDrive++ は、マルチモーダル情報、高レベルのコマンド、自車ステータス情報を統合することで、複雑な計画タスクにおいてより正確な経路予測と衝突率と道路境界交差率の低減を実現し、自動運転計画と意思決定に強力な情報を提供します。サポート。
ディスカッション

著者が提案した OmniDrive エージェントと OmniDrive-nuScenes データセットは、マルチモーダル大規模モデルの分野に新しいパラダイムを導入し、3D 環境での運転の問題を解決し、運転のための新しいプラットフォームを提供できます。このようなモデルの評価は、包括的なベンチマークを提供します。ただし、新しい方法とデータセットにはそれぞれ長所と短所があります。
OmniDrive エージェントは、2D 事前トレーニングと 3D 微調整という 2 段階のトレーニング戦略を提案します。 2D 事前トレーニング段階では、LLaVA v1.5 の画像とテキストのペアのデータセットを使用して Q-Former とキャリア クエリを事前トレーニングすることで、画像特徴と大規模言語モデルの間のより適切な調整が実現されます。 3D 微調整段階では、モデルの 3D 位置決め機能を強化するために、3D 位置情報エンコードおよび時間モジュールが導入されます。 LoRA を活用してビジュアル エンコーダーと言語モデルを微調整することで、OmniDrive は 2D セマンティクスの理解を維持しながら、3D ローカリゼーションの習熟度を高めます。この段階的なトレーニング戦略は、マルチモーダル大規模モデルの可能性を最大限に引き出し、3D 運転シナリオにおける認識、推論、計画能力を強化します。一方、OmniDrive-nuScenes は、大規模モデルを駆動する能力を評価するために特別に設計された新しいベンチマークです。完全に自動化された QA 生成プロセスは、GPT-4 経由で高品質の質問と回答のペアを生成し、認識から計画までのさまざまなタスクをカバーします。さらに、オンラインで生成された位置決めタスクは、モデルの暗黙的なデータ拡張も提供し、3D 環境をより深く理解するのに役立ちます。このデータ セットの利点は、モデルの認識能力と推論能力をテストするだけでなく、長期的な問題を通じてモデルの空間理解能力と計画能力も評価できることです。この包括的なベンチマークは、将来のマルチモーダル大規模モデルの開発を強力にサポートします。
ただし、OmniDrive エージェントと OmniDrive-nuScenes データセットにもいくつかの欠点があります。まず、OmniDrive エージェントは 3D 微調整段階でモデル全体を微調整する必要があるため、トレーニング リソースの要件が高く、トレーニング時間とハードウェア コストが大幅に増加します。さらに、OmniDrive-nuScenes のデータ生成は GPT-4 に完全に依存していますが、質問の品質と多様性は保証されていますが、生成された質問は強力な自然言語機能を持つモデルに偏り、モデルが不完全になる可能性があります。実際の運転能力よりも言語特性に基づいたベンチマークテストに依存します。 OmniDrive-nuScenes は包括的な QA ベンチマークを提供しますが、カバーできる運転シナリオはまだ限られています。データセットに含まれる交通ルールと計画シミュレーションは nuScenes データセットのみに基づいているため、生成された問題が現実世界のさまざまな運転シナリオを完全に表現することが困難になります。さらに、データ生成プロセスは高度に自動化されているため、生成された質問は必然的にデータのバイアスとプロンプト設計の影響を受けます。
結論
著者が提案した OmniDrive エージェントと OmniDrive-nuScenes データセットは、3D 運転シーンにおけるマルチモーダル大規模モデル研究に新しい視点と評価ベンチマークをもたらします。 OmniDrive エージェントの 2 段階のトレーニング戦略は、2D 事前トレーニングと 3D 微調整をうまく組み合わせており、その結果、知覚、推論、計画において優れたモデルが得られます。新しい QA ベンチマークとして、OmniDrive-nuScenes は大規模な運転モデルを評価するための包括的な指標を提供します。ただし、モデルのトレーニング リソース要件を最適化し、データセット生成プロセスを改善し、生成された質問が実際の運転環境をより正確に表現できるようにするには、さらなる研究がまだ必要です。全体として、著者の手法とデータセットは、運転分野におけるマルチモーダルな大規模モデルの研究を推進し、将来の研究のための強固な基盤を築く上で非常に重要です。
以上がLLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください
 Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PMメタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PM
マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PMつながりの慰めの幻想:私たちはAIとの関係において本当に繁栄していますか? この質問は、MIT Media Labの「AI(AHA)で人間を進める」シンポジウムの楽観的なトーンに挑戦しました。イベントではCondedgを紹介している間
 PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM
PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM導入 あなたが科学者またはエンジニアで複雑な問題に取り組んでいると想像してください - 微分方程式、最適化の課題、またはフーリエ分析。 Pythonの使いやすさとグラフィックスの機能は魅力的ですが、これらのタスクは強力なツールを必要とします
 ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AMメタのラマ3.2:マルチモーダルAIパワーハウス Metaの最新のマルチモーダルモデルであるLlama 3.2は、AIの大幅な進歩を表しており、言語理解の向上、精度の向上、および優れたテキスト生成機能を誇っています。 その能力t
 Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AM
Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AMデータ品質保証:ダグスターと大きな期待でチェックを自動化する データ駆動型のビジネスにとって、高いデータ品質を維持することが重要です。 データの量とソースが増加するにつれて、手動の品質管理は非効率的でエラーが発生しやすくなります。
 メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AM
メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AMMainFrames:AI革命のUnsung Heroes サーバーは汎用アプリケーションで優れており、複数のクライアントの処理を行いますが、メインフレームは大量のミッションクリティカルなタスク用に構築されています。 これらの強力なシステムは、頻繁にヘビルで見られます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 中国語版
中国語版、とても使いやすい

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

