
ホームページ >テクノロジー周辺機器 >AI >HKU の大規模なオープンソース グラフ基本モデル OpenGraph: 強力な一般化機能、新しいデータを予測するための順伝播
HKU の大規模なオープンソース グラフ基本モデル OpenGraph: 強力な一般化機能、新しいデータを予測するための順伝播

- WBOY転載
- 2024-05-09 12:01:02373ブラウズ
グラフ学習分野におけるデータ不足の問題は、新しいトリックで解決されました。
OpenGraph は、さまざまなグラフ データセットでのゼロショット予測用に特別に設計された基本的なグラフベースのモデルです。
香港ビッグデータインテリジェンス研究所の所長であるChao Huang氏のチームは、新しいタスクに対するモデルの適応性を向上させるためのモデルの改善と調整手法も提案しました。
現在、この作品はGitHubにアップロードされています。
データ拡張手法を紹介します。この作業では、主に、グラフィカル モデルの汎化能力を強化するための詳細な戦略を検討します (特に、トレーニング データとテスト データの間に大きな違いがある場合)。
OpenGraph は、伝播予測を通じて順伝播を実行し、新しいデータのゼロサンプル予測を実現する一般的なグラフ構造モデルです。
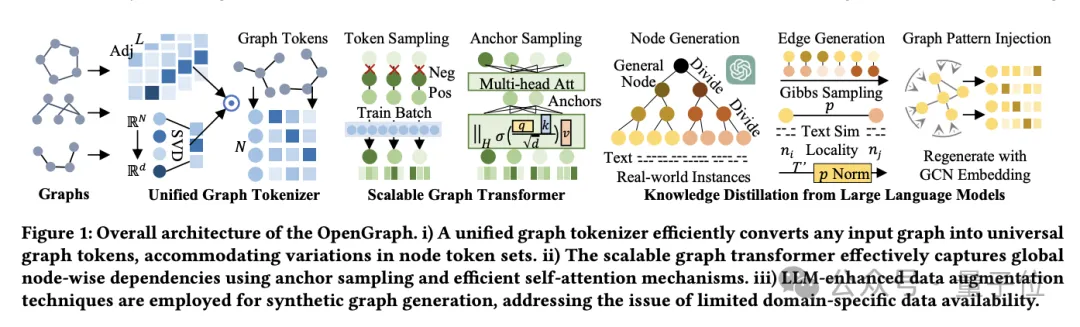
目標を達成するために、チームは次の 3 つの課題を解決しました:
- データセット間のトークンの違い: 多くの場合、異なるグラフ データ セットには異なるグラフ トークン セットがあり、モデルには次のことが必要です。データセットを横断して予測できるようになります。
- ノード関係モデリング: 一般的なグラフ モデルを構築する場合、ノード関係を効果的にモデル化することが重要であり、これはモデルのスケーラビリティと効率に関係します。
- データ不足: データ取得の問題に直面して、私たちは大規模な言語モデルを通じてデータ強化を実行して、複雑なグラフ構造の関係をシミュレートし、モデルのトレーニングの品質を向上させます。
トポロジーを意識した BERT Tokenizer やアンカーベースのグラフ Transformer などの一連の革新的な方法を通じて、OpenGraph は上記の課題に効果的に対処します。複数のデータセットに対するテスト結果は、モデルの優れた汎化能力を実証し、モデルの色の汎化能力の効果的な評価を可能にします。
OpenGraph モデル
OpenGraph モデルのアーキテクチャは、主に 3 つのコア部分で構成されています:
- 統合グラフ トークナイザー。
- 拡張可能なグラフトランスフォーマー。
- 大規模言語モデルに基づく知識蒸留テクノロジー。
まず、統合グラフトークナイザーについて話しましょう。
異なるデータセットのノードとエッジの違いに適応するために、チームは、グラフデータをトークンシーケンスに正規化する統合グラフトークナイザーを開発しました。
このプロセスには、高次の隣接行列のスムージングとトポロジを意識したマッピングが含まれます。
高次の隣接行列平滑化は、隣接行列の高次のべき乗を使用してスパース接続の問題を解決します。一方、トポロジ認識マッピングは、隣接行列をノード シーケンスに変換し、高速特異値分解 (SVD) を使用して最小化します。情報が失われ、より多くのグラフ構造情報が保持されます。
2 つ目は、拡張可能なグラフ Transformer です。
トークン化後、OpenGraph は Transformer アーキテクチャを使用してノード間の依存関係をシミュレートし、主に次のテクノロジーを使用してモデルのパフォーマンスと効率を最適化します:
まず、トークン シーケンス サンプリングでは、モデルに必要な関係の数を減らすためにサンプリング テクノロジーを使用します。処理することで、トレーニングの時間とスペースの複雑さが軽減されます。
2 つ目は、アンカーサンプリングの自己注意メカニズムです。この方法では、段階的に学習ノード間で情報を転送することにより、計算の複雑さがさらに軽減され、モデルのトレーニング効率と安定性が効果的に向上します。
最後のステップは、大規模な言語モデルの知識の蒸留です。
一般的なグラフ モデルをトレーニングするときに直面するデータ プライバシーとカテゴリの多様性の問題に対処するために、チームは大規模言語モデル (LLM) の知識と理解機能からインスピレーションを得て、LLM を使用してさまざまなグラフ構造データを生成しました。
このデータ拡張メカニズムは、現実世界のグラフの特性をシミュレートすることにより、データの品質と実用性を効果的に向上させます。
また、チームはまず、特定のアプリケーションに適応したノード セットを生成します。各ノードにはエッジ生成用のテキスト説明が含まれています。
電子商取引プラットフォームなどの大規模なノード セットに直面した場合、研究者はノードをより具体的なサブカテゴリーに細分化することでこれに対処します。
たとえば、「電子製品」から特定の「携帯電話」、「ラップトップ」などに至るまで、ノードが実際のインスタンスに近くなるまで十分に洗練されるまで、このプロセスが繰り返されます。
プロンプトツリーアルゴリズムは、ツリー構造に従ってノードを細分化し、より詳細なエンティティを生成します。
「製品」などの一般的なカテゴリから開始し、徐々に特定のサブカテゴリに絞り込み、最終的にノード ツリーを形成します。
エッジの生成に関しては、研究者はギブズ サンプリングを使用して、生成されたノードのセットに基づいてエッジを形成します。
計算負荷を軽減するために、LLM を介してすべての可能なエッジを直接走査するのではなく、最初に LLM を使用してノード間のテキストの類似性を計算し、次に単純なアルゴリズムを使用してノードの関係を決定します。
これに基づいて、チームはいくつかの技術的な調整を導入しました:
- 動的確率正規化: 動的調整を通じて、類似度をサンプリングにより適した確率範囲にマッピングします。
- ノード局所性: 局所性の概念を導入し、ノードのローカルサブセット間の接続のみを確立して、現実世界のネットワーク局所性をシミュレートします。
- グラフ トポロジ パターンの挿入: グラフ畳み込みネットワークを使用してノード表現を変更し、グラフ構造の特性に適切に適応し、分布の偏差を低減します。
上記の手順により、生成されたグラフ データが豊富で多様であるだけでなく、現実世界の接続パターンや構造的特徴に近いものになります。
実験検証とパフォーマンス分析
この実験は、LLM によってのみ生成されたデータセットを使用した OpenGraph モデルのトレーニングと、多様な現実のシナリオ データセットでのテストに焦点を当てており、ノード分類とリンク予測タスクをカバーしていることに注意してください。
実験計画は次のとおりです:
ゼロサンプル設定。
目に見えないデータに対する OpenGraph のパフォーマンスを評価するには、生成されたトレーニング セットでモデルをトレーニングし、それからまったく異なる現実世界のテスト セットで評価します。これにより、トレーニング データとテスト データのノード、エッジ、フィーチャに重複がないことが保証されます。
サンプル設定が少なくなります。
多くの方法ではゼロショット予測を効果的に実行することが難しいことを考慮して、ベースラインモデルが事前トレーニングデータで事前トレーニングされた後、微調整にkショットサンプルが使用されます。 。
2 つのタスクと 8 つのテスト セットの結果は、OpenGraph がゼロショット予測において既存の手法を大幅に上回っていることを示しています。
さらに、既存の事前トレーニングされたモデルは、データセット間のタスクで最初からトレーニングされたモデルよりもパフォーマンスが低下する場合があります。
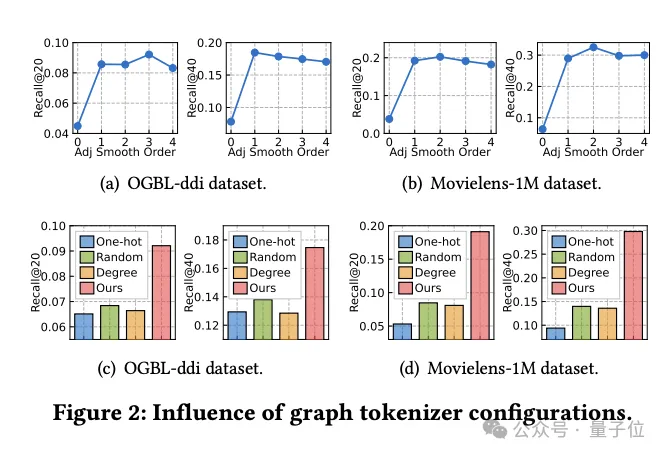
グラフ トークナイザーの設計の影響に関する研究
同時に、チームはグラフ トークナイザーの設計がモデルのパフォーマンスにどのような影響を与えるかを調査しました。
まず、隣接行列の平滑化を行わない(平滑化次数が0)と性能が大幅に低下することが実験により判明しており、平滑化の必要性が示されています。
その後、研究者らは、データセット全体のワンホット エンコード ID、ランダム マッピング、ノード次数ベースの表現など、トポロジを意識した単純な代替案をいくつか試しました。
実験結果は、これらの代替手段のパフォーマンスが理想的ではないことを示しています。
具体的には、データセット間の ID 表現が最悪であり、度数ベースの表現もパフォーマンスが低く、ランダム マッピングはわずかに優れていますが、最適化されたトポロジを意識したマッピングと比較するとパフォーマンスに大きなギャップがあります。
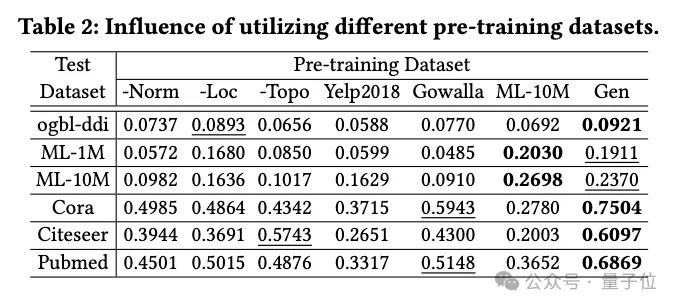
データ生成技術の影響
チームは、LLM ベースの知識蒸留手法を使用して生成されたデータセットやいくつかの実世界のデータセットを含む、OpenGraph パフォーマンスに対するさまざまな事前トレーニング データセットの影響を調査しました。
実験で比較した事前学習データセットには、チーム生成手法から特定の技術を除いたデータセット、テストデータセットとは関係のない実データセット2つ(Yelp2018とGowalla)、データ1つのデータが含まれていますテストデータで設定 同様の実データセット(ML-10M)を設定します。
実験結果は、生成されたデータセットがすべてのテストセットで良好なパフォーマンスを示すことを示しており、3 つの生成手法を削除するとパフォーマンスに大きな影響があり、これらの手法の有効性が検証されています。
テストセットに関係のない実際のデータセット (Yelp や Gowalla など) を使用してトレーニングすると、パフォーマンスが低下することがあります。これは、異なるデータセット間の分布の違いが原因である可能性があります。
ML-10M データセットは、ML-1M や ML-10M などの同様のテスト データセット で最高のパフォーマンスを達成し、トレーニング データセットとテスト データセット間の類似性の重要性を強調しています。
Transformer サンプリング技術の研究
実験のこの部分では、研究チームはグラフ Transformer モジュールで使用される 2 つのサンプリング技術、
トークン シーケンス サンプリング (Seq) とアンカー サンプリング (Anc) を調査しました。
彼らは、モデルのパフォーマンスに対する具体的な影響を評価するために、これら 2 つのサンプリング方法について詳細なアブレーション実験を実施しました。
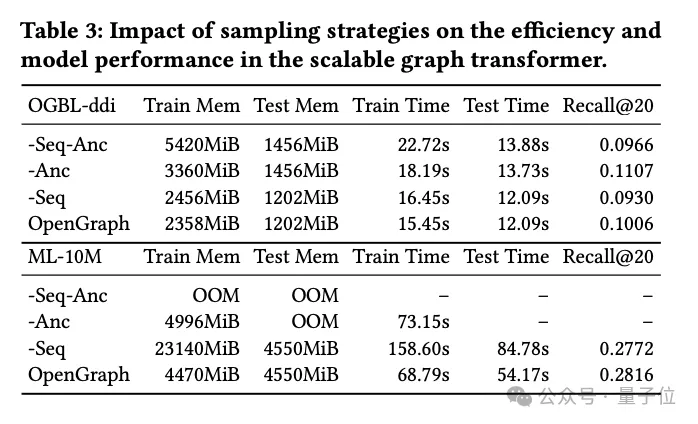
実験結果は、トークン シーケンス サンプリングであってもアンカー ポイント サンプリングであっても、どちらもトレーニングおよびテスト段階でモデルの空間と時間の複雑さを効果的に削減できることを示しています。これは大規模なグラフ データを処理する場合に特に重要であり、効率を大幅に向上させることができます。
パフォーマンスの観点から見ると、トークン シーケンスのサンプリングはモデルの全体的なパフォーマンスにプラスの影響を与えます。このサンプリング戦略は、キー トークンを選択することによってグラフの表現を最適化し、それによって複雑なグラフ構造を処理するモデルの能力を向上させます。
対照的に、ddi データセットの実験では、アンカー サンプリングがモデルのパフォーマンスに悪影響を与える可能性があることが示されています。アンカー サンプリングでは、特定のノードをアンカー ポイントとして選択することでグラフ構造を簡素化しますが、この方法では一部の重要なグラフ構造情報が無視される可能性があるため、モデルの精度に影響します。
要約すると、両方のサンプリング手法にはそれぞれ利点がありますが、実際のアプリケーションでは、特定のデータセットとタスク要件に基づいて適切なサンプリング戦略を慎重に選択する必要があります。
研究の結論
この研究は、さまざまなグラフ構造の複雑なトポロジー パターンを正確に識別して解析できる、適応性の高いフレームワークを開発することを目的としています。
研究者らは、提案されたモデルの機能を最大限に活用することで、さまざまな下流アプリケーションを含むゼロショット グラフ学習タスクにおけるモデルの汎化能力を大幅に強化することを目指しています。
このモデルは、OpenGraph の効率と堅牢性を向上させるために、スケーラブルなグラフ Transformer アーキテクチャと LLM で強化されたデータ拡張メカニズムのサポートを利用して構築されています。
複数の標準データセットに対する広範なテストを通じて、チームはモデルの優れた一般化パフォーマンスを実証しました。
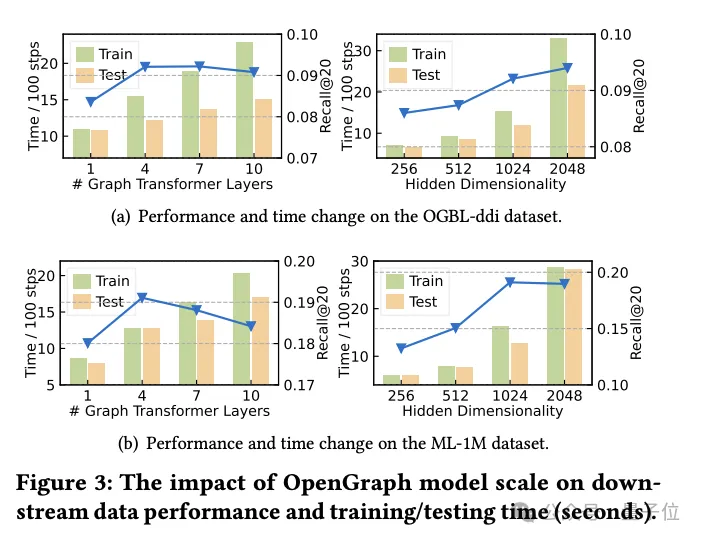
グラフベースのモデルを構築する最初の試みとして、将来的には、チームの作業は、ノイズの多い接続の自動識別や反事実学習の実施など、フレームワークの自動化機能の向上に焦点を当てる予定であると理解されています。
同時に、チームは、モデルの適用範囲と効果をさらに促進するために、さまざまなグラフ構造の共通で移植可能なパターンを学習および抽出することを計画しています。
参考リンク:
[1] 論文: https://arxiv.org/pdf/2403.01121.pdf。
[2] ソースコードライブラリ: https://github.com/HKUDS/OpenGraph。
以上がHKU の大規模なオープンソース グラフ基本モデル OpenGraph: 強力な一般化機能、新しいデータを予測するための順伝播の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。