犬ロボットはヨガボールの上を安定して歩き、そのバランスは非常に良好です。 
平らな歩道や平らな歩道など、さまざまなシーンに対応できます。 
## 研究者がヨガボールを蹴っても、ロボット犬はひっくり返ることはありません:

風船をしぼませるロボット犬もバランスを保つことができます:

上記のデモはすべて 1 倍速であり、加速されていません。
- 論文アドレス: https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- プロジェクトのホームページ: https://github.com/eureka-research/DrEureka
- 論文のタイトル: DrEureka: Language Model Guided Sim-To-Real転送
この研究は、ペンシルバニア大学、NVIDIA、テキサス大学オースティン校の研究者によって共同作成されたもので、完全にオープンソースです。 。彼らは、LLM を利用して報酬設計とドメインランダム化パラメーター構成を実装し、シミュレーションから現実への移行を同時に実現できる新しいアルゴリズムである DrEureka (Domain Randomized Eureka) を提案しました。この研究では、DrEureka アルゴリズムが、反復的な手動設計を必要とせずに、四足ロボットのバランス調整やヨガ ボール上での歩行などの新しいロボット タスクを解決できる能力を実証しました。
DrEureka は、2023 年の NVIDIA プロジェクト トップ 10 の 1 つに選ばれた Eureka をベースにしています。 Eureka について詳しくは、「
論文の要約セクションで、研究者らは、シミュレーションで学習した戦略を現実世界に移すことが、ロボットスキルの大規模な習得にとって有望な戦略であると述べています。ただし、現実へのシミュレーションのアプローチは、タスク報酬関数とシミュレーションの物理パラメーターの手動設計と調整に依存することが多く、そのためプロセスが遅くなり、労働集約的になります。このペーパーでは、シミュレーションから現実的な設計への移行を自動化および高速化するための大規模言語モデル (LLM) の使用について検討します。
この論文の著者の 1 人であり、NVIDIA の上級科学者である Jim Fan もこの研究に参加しました。以前、Nvidia は、ジム・ファンが率いる、身体化されたインテリジェンスを専門とする AI 研究所を設立しました。 Jim Fan 氏は次のように述べています:
「私たちは、ヨガ ボールの上でバランスを取り、歩くようにロボット犬を訓練しました。これは完全にシミュレーションで行われ、その後、ゼロサンプルの移行が行われました。
##ヨガ ボールの歩行タスクは、弾むボールの表面を正確にシミュレートできないため、特に困難です。大きなサイズを簡単に検索できます。多数のシミュレートされた実際の構成を使用して、ロボット犬がさまざまな地形でボールを制御したり、横に歩いたりできるようにします。 ## 一般的に、シミュレーションから現実への移行は次のように行われます。 GPT-4 のような最先端の LLM には、GPT を使用して、摩擦、減衰、剛性、重力などの多くの物理的直観が組み込まれています。 -4、DrEureka はこれらのパラメータを巧みに調整し、その理由をうまく説明できます。"
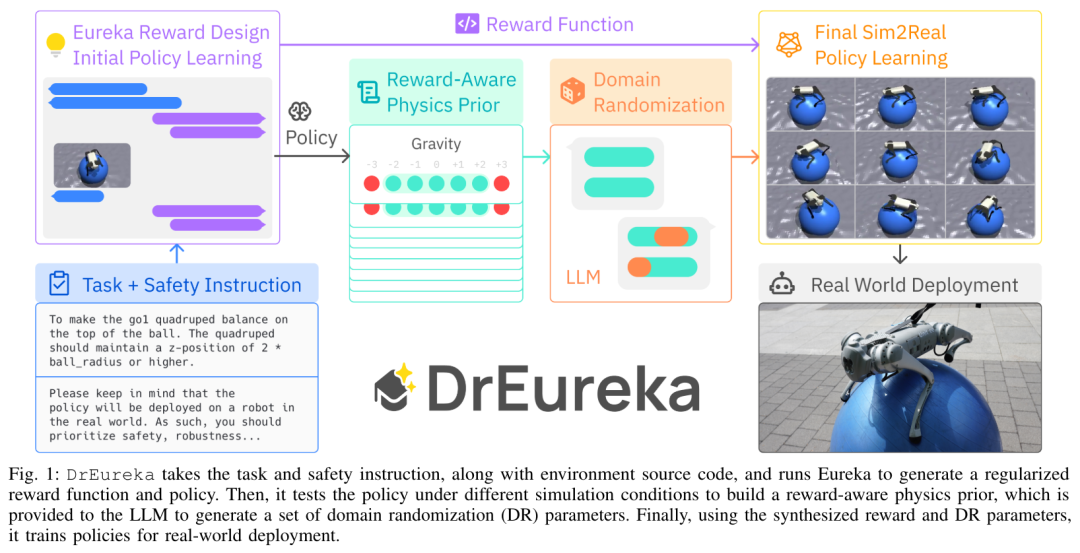
DrEureka のプロセスは次のとおりです。タスクと安全に関する指示と環境ソース コードを受け取り、Eureka を実行して正則化を生成します。報酬関数と戦略。次に、さまざまなシミュレーション条件下で戦略をテストして、報酬を意識した物理事前確率を構築します。これが LLM に供給されて、ドメイン ランダム化 (DR) パラメーターのセットが生成されます。最後に、実際のデプロイメントのために、合成された報酬パラメータと DR パラメータを使用してポリシーがトレーニングされます。 エウレカの報酬デザイン。報酬設計コンポーネントは、そのシンプルさと表現力の高さから Eureka に基づいていますが、このホワイトペーパーでは、シミュレーションから現実世界の環境への適用性を高めるためにいくつかの改良が加えられています。疑似コードは次のとおりです。 #報酬認識物理事前 (RAPP、事前報酬認識物理)。セキュリティ報酬関数は、環境の選択を修正するために政策の動作を規制できますが、それだけではシミュレーションから現実への移行を達成するには十分ではありません。したがって、この文書では、LLM の基本的な範囲を制限するための単純な RAPP メカニズムを紹介します。 LLM はドメインのランダム化に使用されます。各 DR パラメータの RAPP 範囲を指定すると、DrEureka の最後のステップで、LLM に RAPP 範囲の制限内でドメインのランダム化構成を生成するように指示します。具体的なプロセスについては、図 3 を参照してください。 この研究では、実験に Unitree Go1 を使用します。Go1 は、4 つの脚に 12 の自由度を持つ小型の四足ロボットです。この論文では、四足歩行タスクにおいて、現実世界のいくつかの地形における DrEureka ポリシーのパフォーマンスも体系的に評価し、それらのポリシーが堅牢性を維持し、人間が設計した報酬および DR 構成を使用してトレーニングされたポリシーよりも優れていることを発見しました。 以上がヨガボールの上で「犬」の散歩! NVIDIA のトップ 10 プロジェクトの 1 つに選ばれた Eureka が新たな進歩を遂げましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。