
ホームページ >テクノロジー周辺機器 >AI >最後に、誰かが小規模モデルの過学習を調査しました。その 3 分の 2 でデータ汚染が発生し、Microsoft Phi-3 と Mixtral 8x22B が命名されました。
最後に、誰かが小規模モデルの過学習を調査しました。その 3 分の 2 でデータ汚染が発生し、Microsoft Phi-3 と Mixtral 8x22B が命名されました。

- 王林転載
- 2024-05-04 13:05:13669ブラウズ
大規模な言語モデルの推論機能を向上させることは、現在の研究の最も重要な方向性の 1 つであり、この種のタスクでは、最近リリースされた多くの小規模なモデルが良好に機能しているようです。そして、この種のタスクをうまく処理できる。たとえば、Microsoft の Phi-3、Mistral 8x22B などのモデルです。
研究者らは、大規模モデル研究の現在の分野には重要な問題があると指摘しました。それは、多くの研究が既存の LLM の機能を正確にベンチマークできていないということです。これは、現在の LLM 機能レベルの評価とテストにもっと時間を費やす必要があることを示唆しています。

これは、現在の研究のほとんどが GSM8k、MATH、MBPP、HumanEval、SWEBench およびその他のテスト セットをベンチマークとして使用しているためです。モデルはインターネットから収集された大規模なデータ セットでトレーニングされるため、トレーニング データ セットにはベンチマークの質問に非常に類似したサンプルが含まれる可能性があります。
この種の汚染により、モデルの推論能力が誤って評価される可能性があります - 彼らは、トレーニング プロセス中に単に質問に混乱し、たまたま正しい答えを暗唱した可能性があります。
たった今、Scale AI による論文で、 OpenAI の GPT-4、Gemini、Claude、Mistral、Llama、Phi、Abdin を含む最も人気のある大規模モデルの詳細な調査が実施されました。 他のシリーズでパラメータ量が異なるモデル。
テスト結果は、多くのモデルがベンチマーク データによって汚染されているという広く広まった疑惑を裏付けました。
- 論文のタイトル: 小学校の算数における大規模言語モデルのパフォーマンスの慎重な検査
論文リンク: https://arxiv.org/pdf/2405.00332
データ汚染の問題を回避するために、Scale AI の研究者は LLM やその他の合成データ ソースを一切使用しませんでした。 GSM1k データセットは、人間によるアノテーションに完全に依存して作成されました。 GSM8k と同様に、GSM1k には初級レベルの数学の問題が 1,250 問含まれています。公平なベンチマーク テストを保証するために、研究者は GSM1k の難易度分布が GSM8k と同様になるように最善を尽くしてきました。研究者らは GSM1k に関して、一連の主要なオープンソースおよびクローズドソースの大規模言語モデルのベンチマークを実施し、最もパフォーマンスの悪いモデルのパフォーマンスが GSM8k よりも GSM1k で 13% 低いことを発見しました。
特に、少量かつ高品質で知られる Mistral および Phi モデル シリーズは、GSM1k のテスト結果によると、ほぼすべてのバージョンで一貫した過学習の証拠が示されています。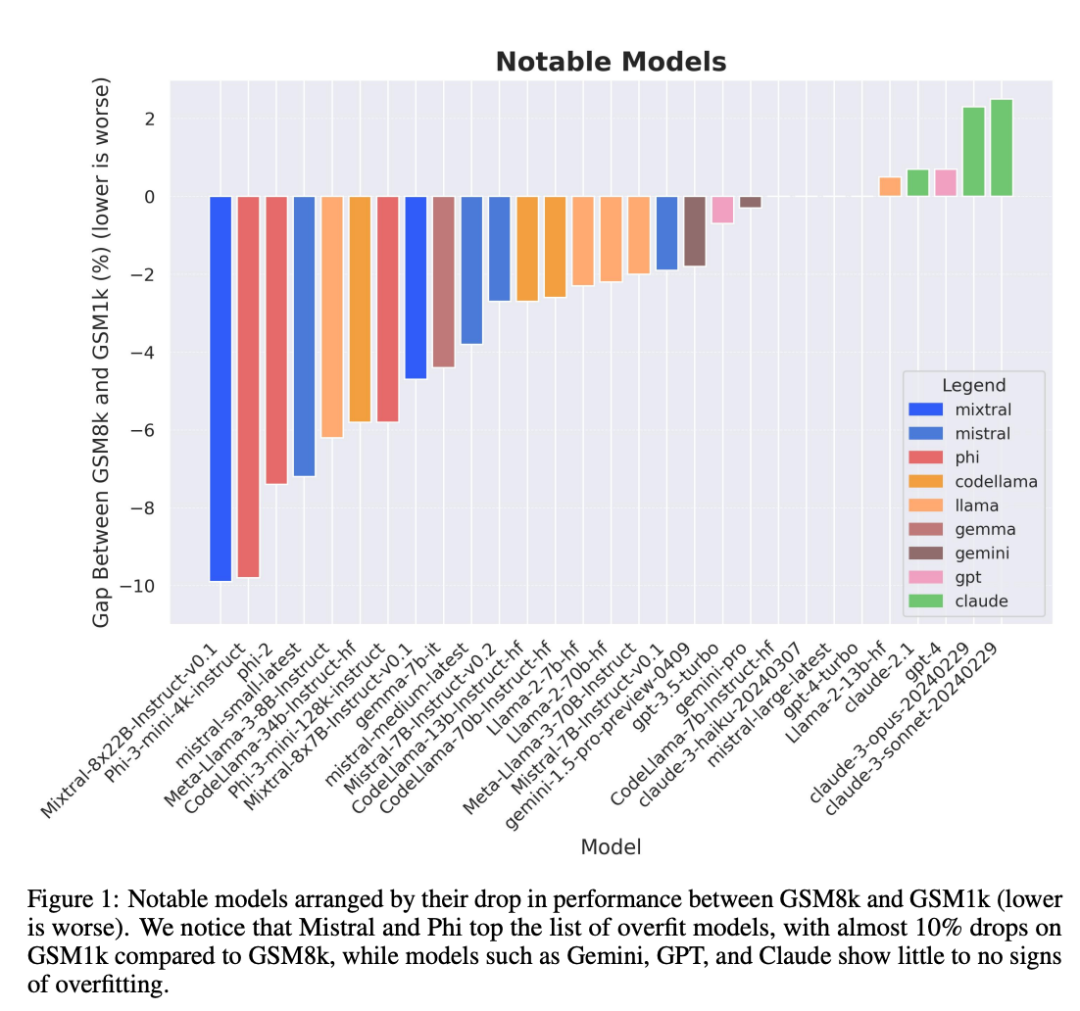
しかし、Gemini、GPT、Claude、Llama2 シリーズは適合する兆候をほとんど示していません。 さらに、最も過剰適合したモデルを含むすべてのモデルは、ベースライン データで示されるよりも成功率が低い場合もありましたが、新しい小学校の算数の問題に正常に一般化することができました。

GSM1k データセット
GSM1k には、小学校の算数の問題が 1,250 問含まれています。これらの問題は、基本的な数学的推論だけで解決できます。 Scale AI は、各ヒューマン アノテーターに GSM8k からの 3 つのサンプル質問を示し、同様の難易度の新しい質問をするよう求め、結果として GSM1k データセットが作成されました。 研究者らはヒューマン・アノテーターに対し、高度な数学的概念を一切使用せず、基本的な算術 (加算、減算、乗算、除算) のみを使用して質問を作成するよう求めました。 GSM8k と同様、すべての問題に対する解は正の整数です。 GSM1k データセットの構築には言語モデルは使用されませんでした。
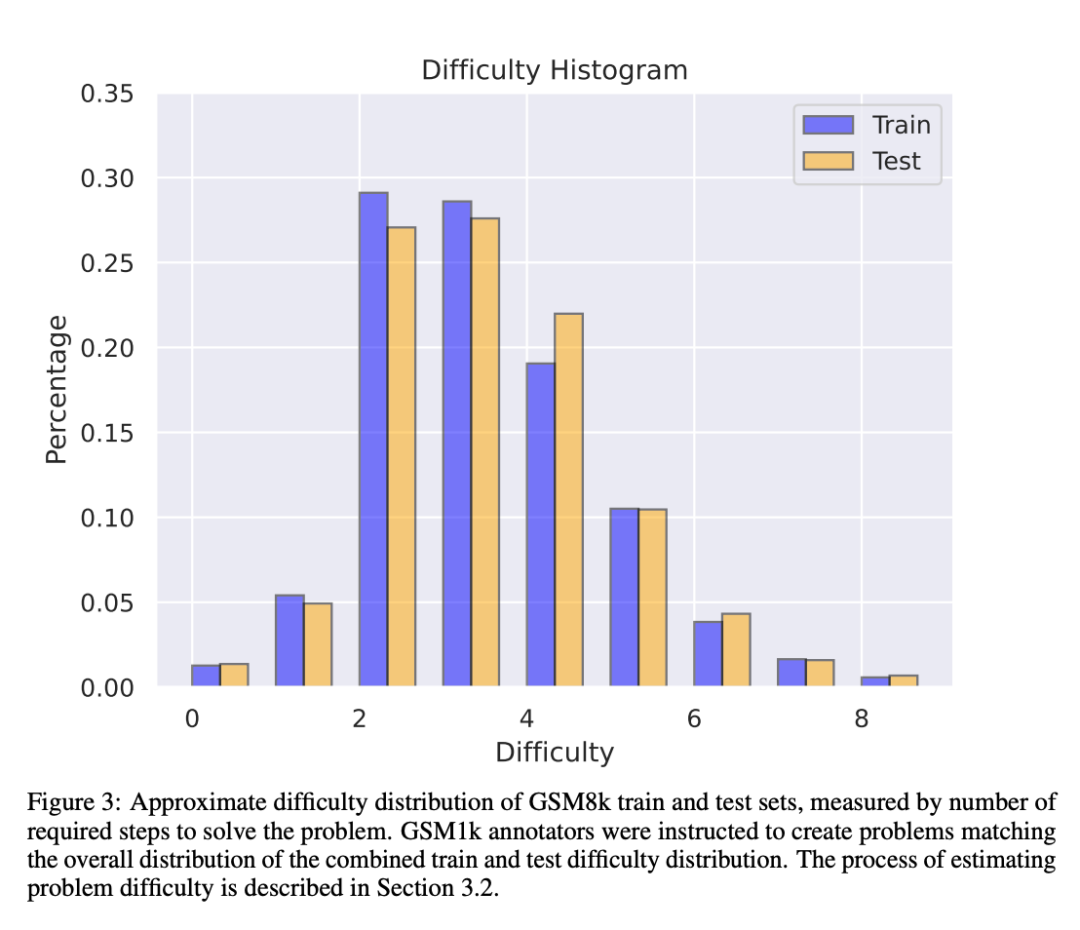
GSM1k データセットのデータ汚染問題を回避するために、Scale AI は現時点ではデータセットを一般公開しませんが、GSM1k 評価フレームワークをオープンソースとして公開します。 EleutherAI の LM 評価ハーネスに基づいています。
しかし、Scale AI は、次の 2 つの条件のいずれかに達した後、完全な GSM1k データセットを MIT ライセンスの下でリリースすると約束します: (1) 異なる事前トレーニング ベースに基づいた 3 つのデータセットがある オープンソースモデル系統のモデルは、2025 年末までに GSM1k で 95% の精度に達します。その時点で、小学校の算数は LLM のパフォーマンスを評価するための有効なベンチマークではなくなる可能性があります。
独自のモデルを評価するために、研究者は API 経由でデータセットを公開します。このリリース アプローチの理由は、LLM ベンダーは通常、モデル モデルのトレーニングに API データ ポイントを使用しないと著者が考えているためです。それにもかかわらず、GSM1k データが API を通じて漏洩した場合、論文の著者は最終的な GSM1k データ セットに含まれないデータ ポイントも保持していることになり、これらのバックアップ データ ポイントは、上記の条件が満たされた場合に GSM1k とともにリリースされます。
彼らは、将来のベンチマーク リリースも同様のパターンに従うことを望んでいます。最初は公開せず、将来の日付、または改ざんを防ぐ特定の条件が満たされたときにリリースすることを事前に約束します。
さらに、Scale AI は GSM8k と GSM1k の間で最大限の一貫性を確保するよう努めています。 ただし、GSM8k のテスト セットは公開されており、モデルのテストに広く使用されているため、GSM1k と GSM8k は理想的な条件下での近似値にすぎません。 GSM8k と GSM1k の分布が完全に一致していない場合、次の評価結果が得られます。
評価結果
モデルを評価するために、研究者らは EleutherAI の LM 評価ハーネス ブランチを使用し、デフォルト設定を使用しました。 GSM8k 問題と GSM1k 問題の実行プロンプトは同じです。GSM8k トレーニング セットから 5 つのサンプルがランダムに選択されます。これは、このフィールドの標準構成でもあります (完全なプロンプト情報については、付録 B を参照してください)。
すべてのオープンソース モデルは、再現性を確保するために温度 0 で評価されます。 LM 評価キットは、応答内の最後の数値回答を抽出し、それを正しい回答と比較します。したがって、サンプルと一致しない形式で「正しい」回答を生成するモデル回答は、不正解としてマークされます。
オープンソース モデルの場合、モデルがライブラリと互換性がある場合、vLLM を使用してモデル推論が高速化されます。そうでない場合は、デフォルトで標準の HuggingFace ライブラリが推論に使用されます。クローズドソース モデルは、評価されるすべての独自モデルの API 呼び出し形式を統一する LiteLLM ライブラリを介してクエリされます。すべての API モデルの結果は、2024 年 4 月 16 日から 4 月 28 日までのクエリからのものであり、デフォルト設定が使用されます。
評価するモデルに関しては、人気に基づいて選択し、OpenLLMLeaderboard で上位にランクされているあまり知られていないモデルもいくつか評価しました。
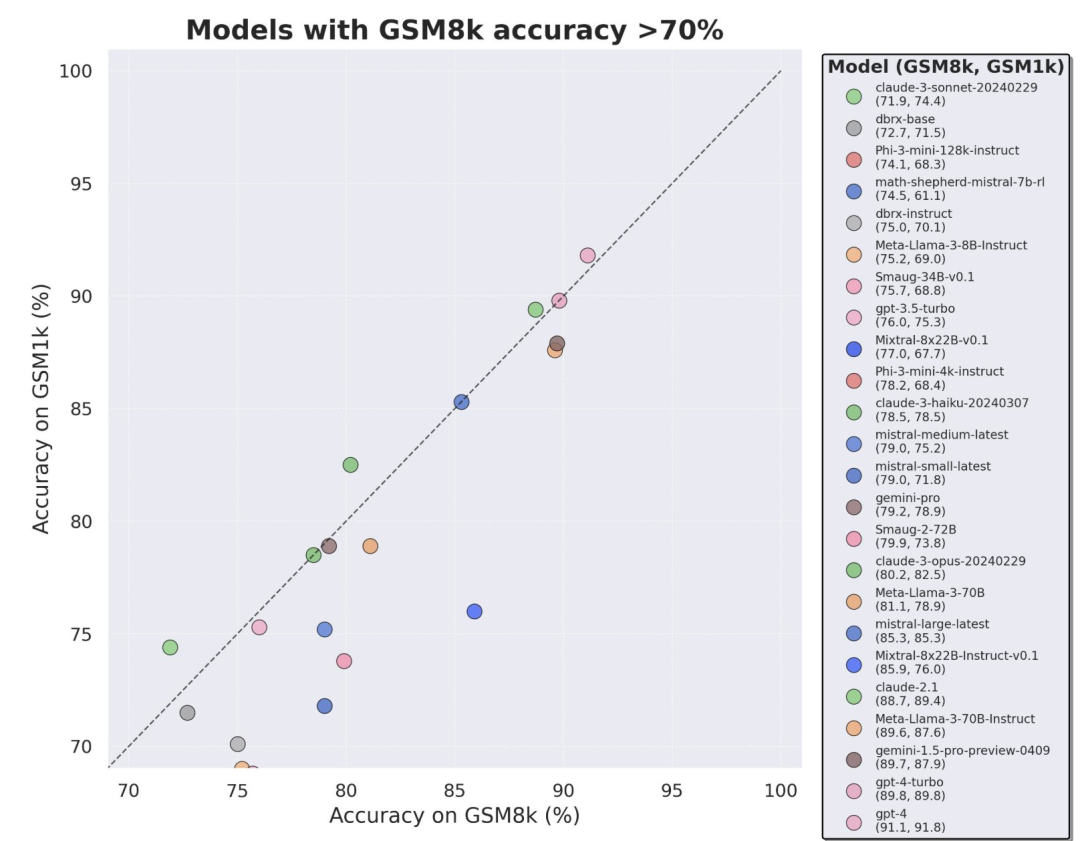
興味深いことに、研究者らはその過程でグッドハートの法則の証拠を発見しました。多くのモデルは、GSM8k よりも GSM1k でのパフォーマンスがはるかに悪く、モデル推論機能を真に向上させるのではなく、主に GSM8k ベンチマークに対応していることを示しています。すべてのモデルのパフォーマンスを以下の付録 D に示します。
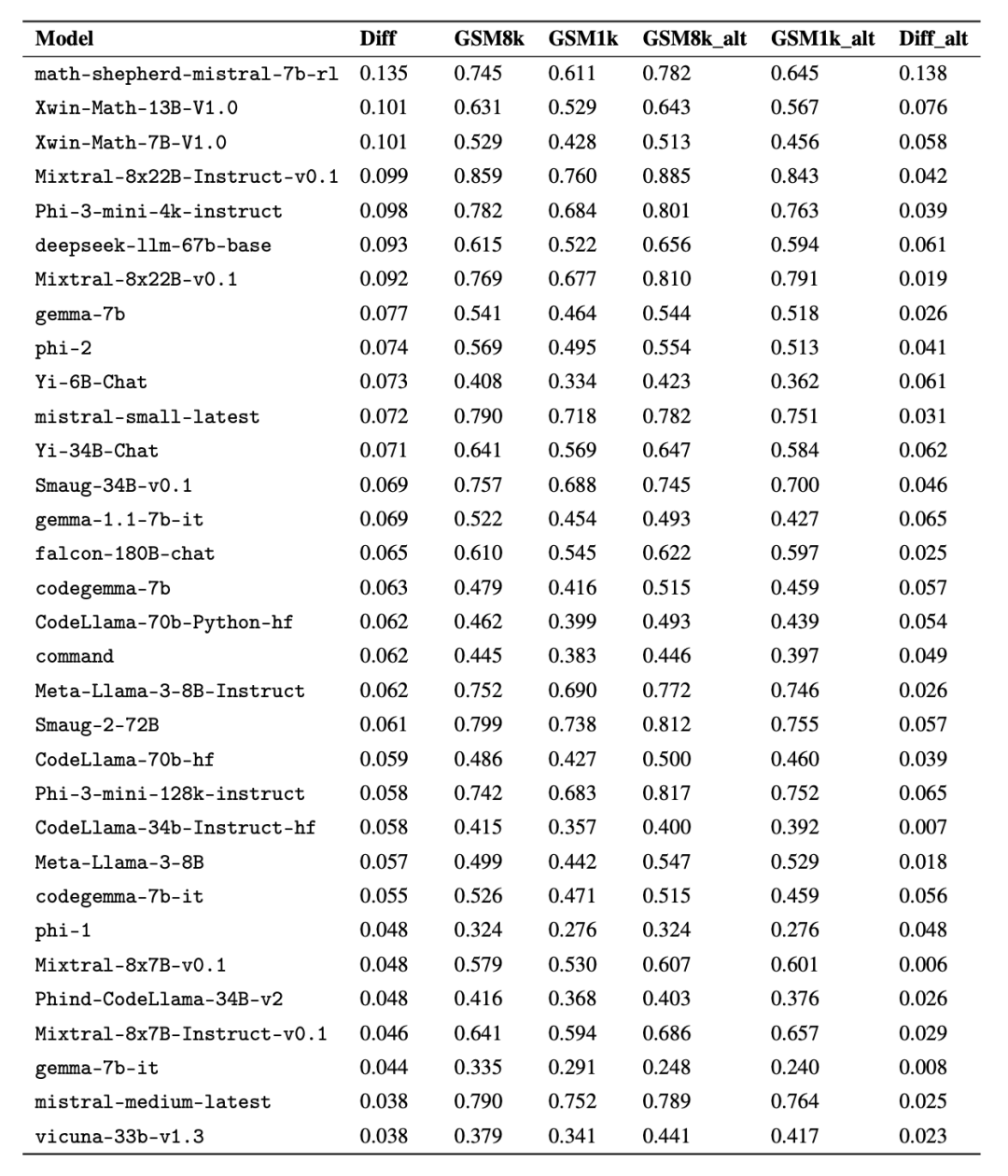
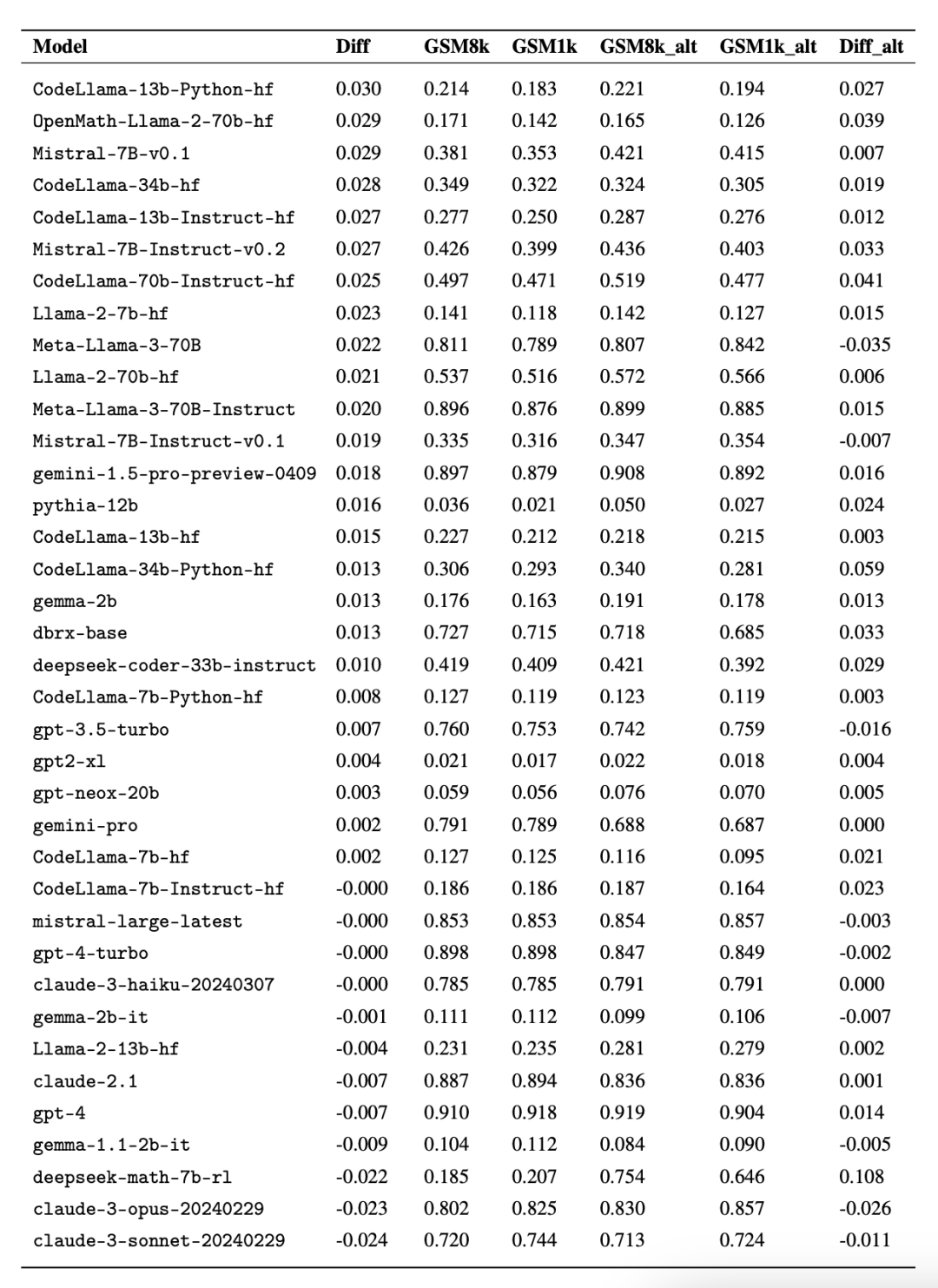
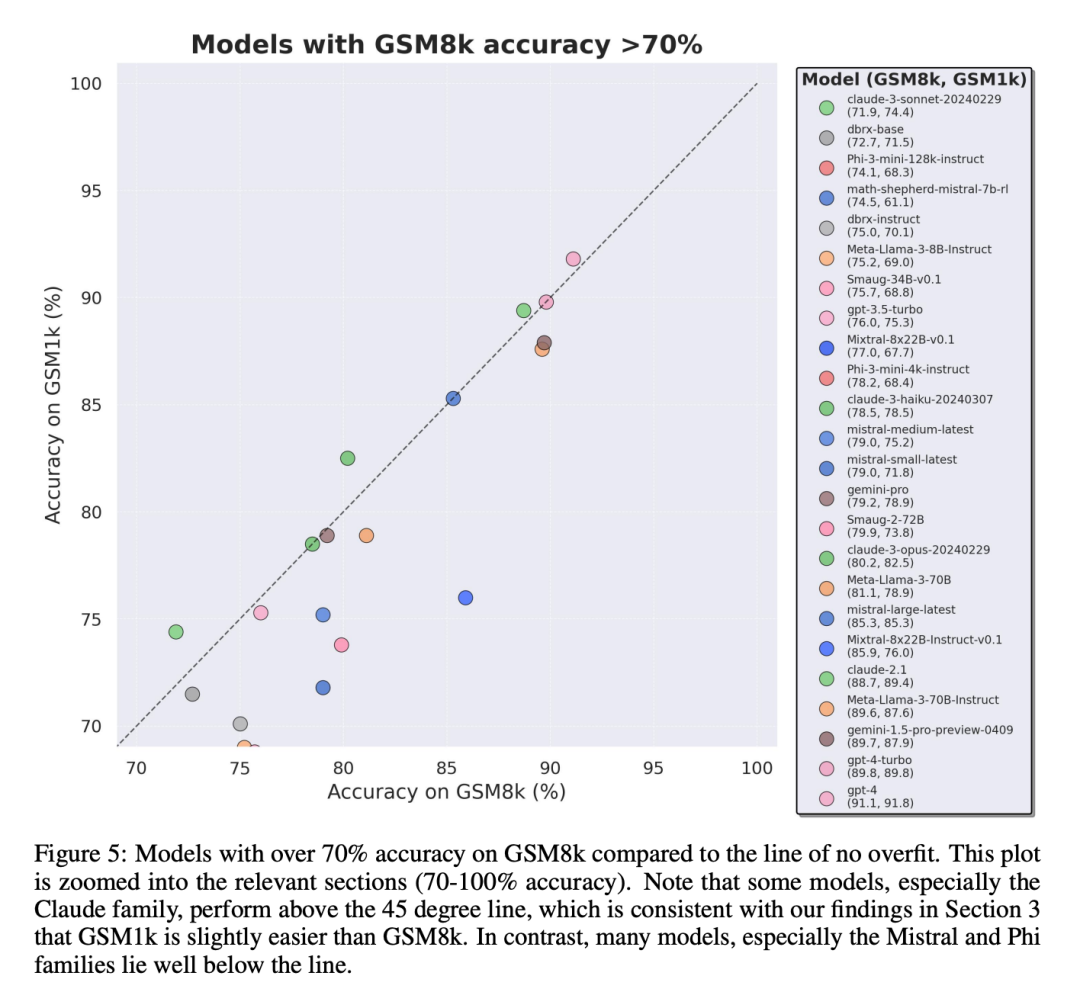
公平な比較を行うために、研究者はGSM8kでのパフォーマンスに応じてモデルを分割し、他のモデルと比較しました。同様に動作するモデルを比較しました (図 5、図 6、図 7)。
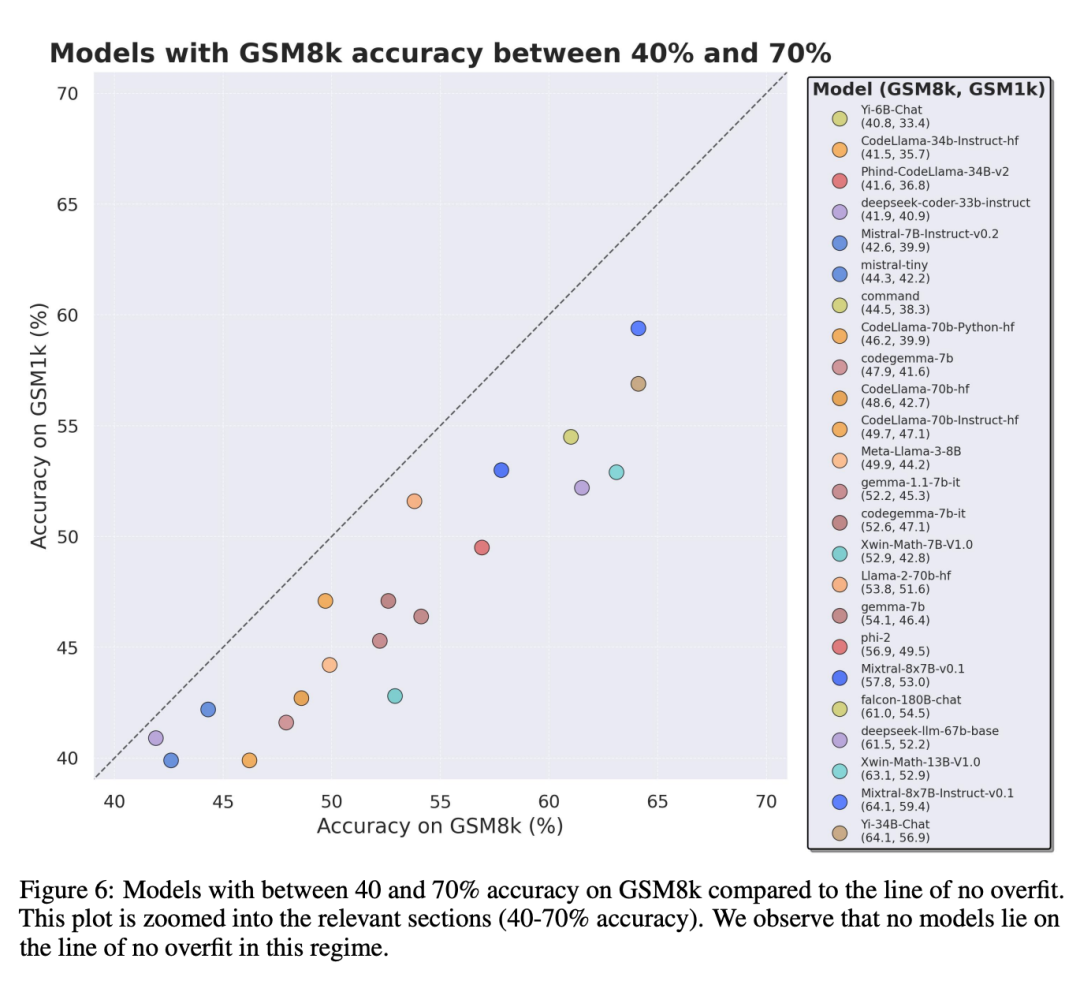
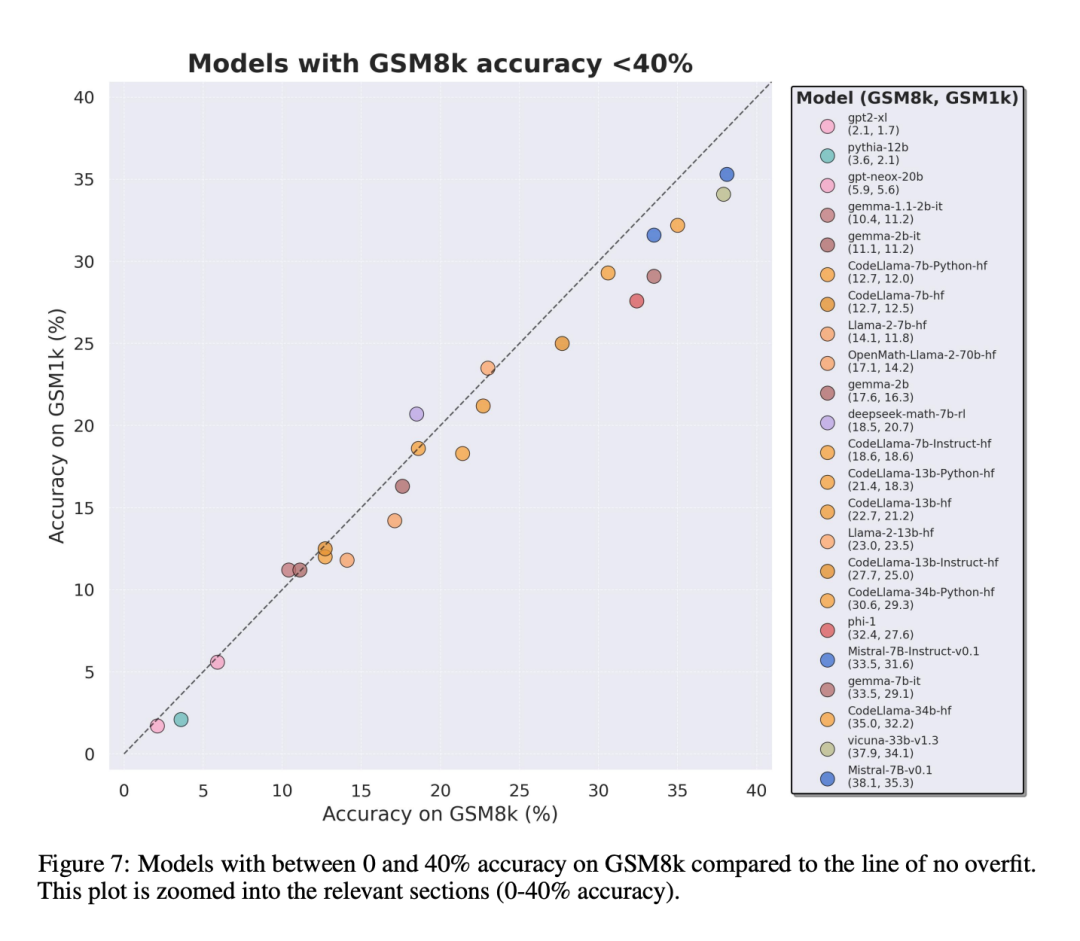 #
#
どのような結論が導き出されましたか?
研究者らは、複数のモデルの客観的な評価結果を提供しましたが、評価結果の解釈は、夢の解釈と同様に、非常に主観的な作業であることが多いとも述べています。論文の最後の部分では、上記の評価の 4 つの影響について、より主観的な方法で詳しく説明しています。単一のデータ ポイントまたはモデル バージョンから結論を引き出すことは多くの場合困難ですが、モデルのファミリーを調べて過剰適合のパターンを観察すると、より決定的なステートメントを得ることができます。 Phi や Mistral などの一部のモデル ファミリでは、ほぼすべてのモデル バージョンとサイズにおいて、GSM1k よりも GSM8k の方がシステム パフォーマンスが向上する傾向が見られます。 Yi、Xwin、Gemma、CodeLlama などの他のモデル ファミリも、程度は低いですが、このパターンを示します。
結論 2: 他のモデル、特に最先端のモデルには、過学習の兆候は見られません。
多くのモデルは、すべてのパフォーマンス領域で小さな過学習を示します。特に、独自の Mistral Large を含むすべての主要モデルまたはほぼ主要モデルは、GSM8k と GSM1k で同様に動作するようです。この点に関して、研究者らは 2 つの考えられる仮説を提案しています。 1) フロンティア モデルは十分に高度な推論機能を備えているため、たとえ GSM8k 問題がトレーニング セットにすでに現れていたとしても、フロンティア モデルは新しい問題に一般化することができます。データの汚染にはもっと注意してください。
各モデルのトレーニング セットを調べてこれらの仮定を判断することは不可能ですが、前者を裏付ける証拠の 1 つは、Mistral Large が Mistral シリーズの中で過学習の兆候を示さない唯一のモデルであるということです。 Mistral がその最大のモデルにデータ汚染がないことを保証するだけであるという仮定は考えにくいようです。そのため研究者らは、十分に強力な LLM がトレーニング中に基本的な推論機能も学習することを支持しています。モデルが特定の難易度の問題を解決するのに十分な推論を学習すると、トレーニング セットに GSM8k が存在する場合でも、新しい問題に一般化できるようになります。
結論 3: 過学習モデルには依然として推論能力があるモデルの過学習に関する多くの研究者の懸念の 1 つは、モデルが推論を実行できないことです。訓練データの答えを記憶しますが、この論文の結果はこの仮説を支持しません。モデルが過剰適合しているという事実は、その推論能力が低いことを意味するのではなく、単にベンチマークが示すほど良くないことを意味します。実際、研究者らは、多くの過適合モデルが依然として推論して新しい問題を解決できることを発見しました。たとえば、
Phi-3 の精度は GSM8k と GSM1k の間でほぼ 10% 低下しましたが、それでも GSM1k の問題の 68% 以上を正確に解決しました。これらの問題は、確かにトレーニング配布には現れませんでした。このパフォーマンスは、約 35 倍のパラメーターを含む dbrx-instruct などのより大きなモデルと同等です。同様に、過剰適合を考慮しても、Mistral モデルは依然として最も強力なオープンソース モデルの 1 つです。 これは、ベンチマーク データが誤ってトレーニング分布に漏れた場合でも、十分に強力なモデルは基本的な推論を学習できるという、この記事の結論に対するさらなる証拠を提供します (これはほとんどの過適合モデルで発生する可能性が高いです)。
結論 4: データ汚染は過学習の完全な説明ではない可能性があります先験的かつ自然な仮説は、過学習の主な原因はデータ汚染であるということです。たとえば、テスト セットは、モデル作成の事前トレーニングまたは命令の微調整部分でリークされます。以前の研究では、モデルがトレーニング中に見たデータに高い対数尤度を割り当てることが示されています (Carlini et al. [2023])。研究者らは、モデルがGSM8kテストセットからサンプルを生成する確率を測定し、GSM8kおよびGSM1kと比較して過学習の程度を比較することにより、データの汚染が過学習の原因であるという仮説を検証しました。
# 研究者らは、データ汚染がすべての原因ではない可能性があると述べています。彼らはこれをいくつかの外れ値で観察しました。これらの外れ値を詳しく見てみると、文字あたりの対数尤度が最も低いモデル (Mixtral-8x22b) と文字あたりの対数尤度が最も高いモデル (Mixtral-8x22b-Instruct) が、同じモデルの単なるバリアントではないことがわかります。同様の程度の過学習があります。さらに興味深いことに、最も過学習されたモデル (Math-Shepherd-Mistral-7B-RL (Yu et al. [2023])) は、文字あたりの対数尤度が比較的低くなります (合成データを使用した Math Shepherd プロセスレベルのデータで報酬モデルをトレーニングする) )。
したがって、研究者らは、たとえ問題自体がデータセットに現れなかったとしても、報酬モデリングプロセスが GSM8k の正しい推論チェーンに関する情報を漏洩した可能性があると仮説を立てました。最終的に、Llema モデルの対数尤度が高く、過学習が最小限であることがわかりました。これらのモデルはオープンソースであり、そのトレーニング データが既知であるため、Llema の論文で説明されているように、GSM8k 問題のいくつかのインスタンスがトレーニング コーパスに表示されます。しかし、著者らは、これらの少数の例では深刻な過剰適合が引き起こされないことを発見しました。これらの外れ値の存在は、GSM8k での過剰適合が純粋にデータの汚染によるものではなく、モデル ビルダーがベースラインと同様の特性を持つデータをトレーニング データとして収集したり、モデルのパフォーマンスに基づいたりするなど、他の間接的な手段によって引き起こされている可能性があることを示唆しています。モデル自体がトレーニング中のどの時点でも GSM8k データセットを認識していなかったとしても、ベンチマークはモデルの最終チェックポイントを選択します。逆もまた真で、少量のデータ汚染が必ずしも過学習につながるわけではありません。
研究の詳細については、元の論文を参照してください。
以上が最後に、誰かが小規模モデルの過学習を調査しました。その 3 分の 2 でデータ汚染が発生し、Microsoft Phi-3 と Mixtral 8x22B が命名されました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。