
ホームページ >テクノロジー周辺機器 >AI >BEVFormerを超えて! CR3DT: RV フュージョンは新しい SOTA (ETH) の 3D 検出と追跡を支援します
BEVFormerを超えて! CR3DT: RV フュージョンは新しい SOTA (ETH) の 3D 検出と追跡を支援します

- PHPz転載
- 2024-04-24 18:07:211145ブラウズ
前書き&筆者の個人的理解
この記事では、3D ターゲット検出とマルチターゲット追跡のためのカメラとミリ波レーダーの融合法 (CR3DT) を紹介します。 LIDAR ベースの手法はこの分野に高い基準を設定していますが、その高いコンピューティング能力と高コストにより、カメラベースの 3D ターゲット検出および追跡ソリューションの自動運転分野でのこのソリューションの開発は制限されています。コストが比較的低く、多くの学者の注目を集めていますが、結果が芳しくないためです。そこで、カメラとミリ波レーダーの融合が有力な解決策となりつつあります。既存のカメラ フレームワーク BEVDet の下で、ミリ波レーダーの空間情報と速度情報を融合し、それを CC-3DT トラッキング ヘッドと組み合わせることで、3D ターゲットの検出と追跡の精度が大幅に向上し、性能とコストの矛盾が解消されます。
主な貢献
センサー フュージョン アーキテクチャ 提案された CR3DT は、BEV エンコーダの前後で中間フュージョン テクノロジを使用します。ミリ波レーダーデータ。追跡には、準高密度アピアランス埋め込みヘッドが使用され、ターゲット関連付けにミリ波レーダー速度推定が使用されます。
検出パフォーマンス評価 CR3DT は、nuScenes 3D 検出検証セットで 35.1% の mAP と 45.6% の nuScenes 検出スコア (NDS) を達成しました。レーダー データに含まれる豊富な速度情報を利用して、検出器の平均速度誤差 (mAVE) は、SOTA カメラ検出器と比較して 45.3% 削減されます。
追跡パフォーマンスの評価 nuScenes 追跡検証セットにおける CR3DT の追跡パフォーマンスは 38.1% AMOTA であり、カメラのみを使用した SOTA 追跡モデルと比較して AMOTA が向上しています。 14.9%、トラッカーでの速度情報の明示的な使用とさらなる改善により、IDS の数が約 43% 大幅に減少しました。
モデル アーキテクチャ
この方法は EV-Det フレームワークに基づいており、RADAR の空間情報と速度情報を統合し、付属の CC-3DT トラッキング ヘッドを組み合わせます。データ関連付けでは、改良されたミリ波レーダーを使用して検出器の速度推定を強化し、最終的に 3D ターゲットの検出と追跡を可能にします。
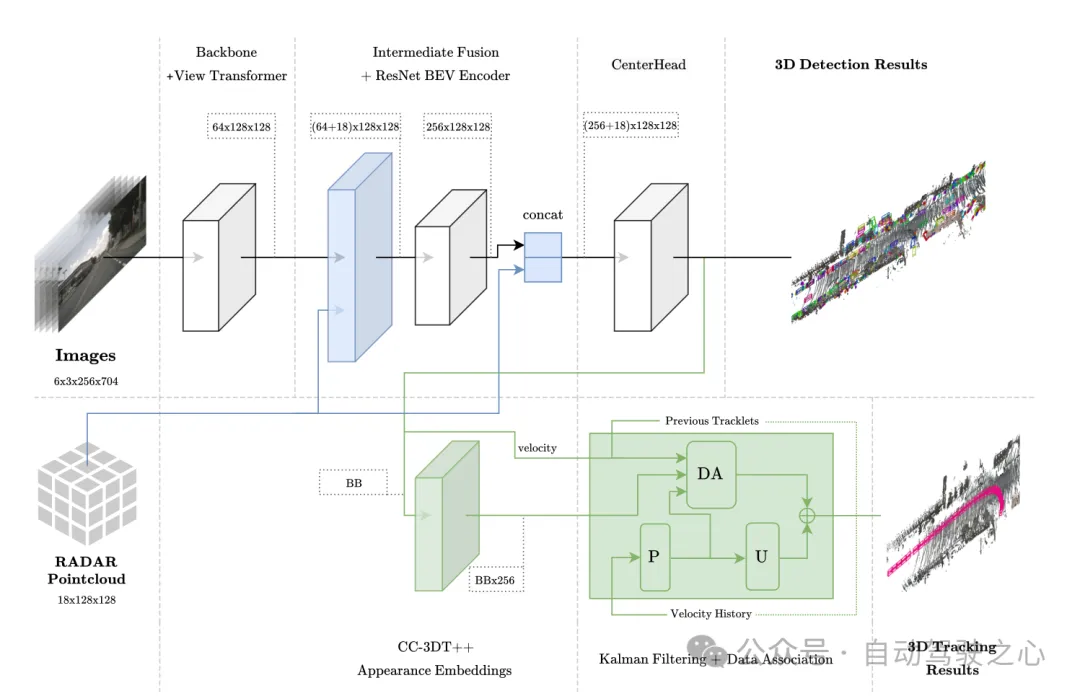 図 1 全体的なアーキテクチャ。検出と追跡はそれぞれ水色と緑色で強調表示されます。
図 1 全体的なアーキテクチャ。検出と追跡はそれぞれ水色と緑色で強調表示されます。
BEV 空間におけるセンサー融合
このモジュールは、内部の集約と接続を含む、PointPillars と同様の融合手法を採用しています。 BEV グリッドは、解像度 0.8 で [-51.2, 51.2] に設定され、(128×128) フィーチャ グリッドになります。画像特徴を BEV 空間に直接投影すると、各グリッド ユニットのチャネル数は 64 になり、画像 BEV 特徴は同様に各 In に集約されます。グリッド単位。これにはポイントの x、y、z 座標が含まれます。レーダー データには拡張は行われません。著者は、レーダー点群にはすでに LiDAR 点群よりも多くの情報が含まれていることを確認したため、レーダー BEV 特徴は (18×128×128) になります。最後に、画像 BEV 特徴 (64×128×128) とレーダー BEV 特徴 (18×128×128) は、BEV 特徴符号化層の入力として直接接続されます ((64 18)×128×128)。その後のアブレーション実験では、(256×128×128) の寸法で BEV 特徴エンコード層の出力に残留接続を追加すると有益であることが判明しました。その結果、CenterPoint 検出ヘッドの最終入力サイズは ( (256 18)×128×128)。

図 2 核融合操作のために BEV 空間に集約されたレーダー点群の視覚化
追跡モジュールのアーキテクチャ
追跡動きの相関性と視覚的特徴の類似性に基づいて、2 つの異なるフレーム内のターゲットを関連付けます。トレーニング プロセス中に、準高密度多変量ポジティブ コントラスト学習を通じて 1 次元の視覚特徴埋め込みベクトルが取得され、CC-3DT の追跡段階で検出と特徴埋め込みが同時に使用されます。データ関連付けステップ (図 1 の DA モジュール) は、改良された CR3DT 位置検出と速度推定を利用するように変更されました。詳細は次のとおりです:

実験と結果
は nuScenes データセットに基づいて完了しましたが、すべてのトレーニングが完了したわけではありません。 CBGSを使用します。
制限付きモデル
作成者は 3090 グラフィックス カードを搭載したコンピューターでモデル全体を実行したため、これは制限付きモデルと呼ばれます。このモデルのターゲット検出部分は検出ベースラインとして BEVDet を使用し、画像エンコード バックボーンは ResNet50 に設定され、画像入力は (3×256×704) に設定されます。モデルでは過去または未来の時間画像情報は使用されません。バッチサイズは 8 に設定されます。レーダー データのまばらさを軽減するために、5 回のスキャンを使用してデータを強化します。融合モデルでは追加の時間情報は使用されません。
ターゲット検出の場合は、mAP、NDS、および mAVE のスコアを使用して評価し、追跡の場合は、AMOTA、AMOTP、および IDS を使用して評価します。
オブジェクト検出結果
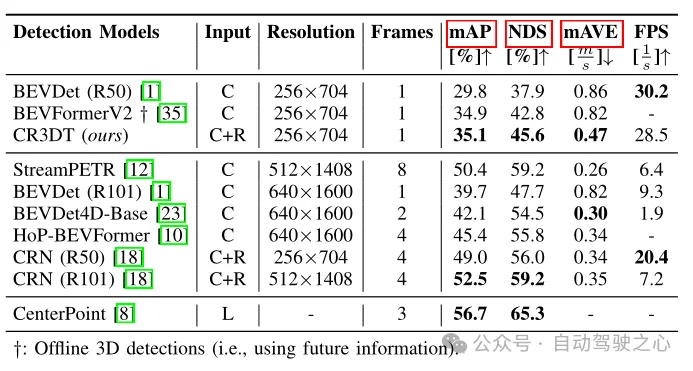
表 1 nuScenes 検証セットの検出結果
表 1 は、CR3DT と CR3DT の違いを示しています。カメラを使用したベースライン BEVDet (R50) アーキテクチャと比較した検出パフォーマンスのみ。 Radar を追加すると、検出性能が大幅に向上することは明らかです。小さな解像度と時間枠の制約の下で、CR3DT はカメラのみの BEVDet と比較して 5.3% の mAP と 7.7% の NDS の向上に成功しました。しかし、計算能力の限界により、この論文では高解像度、マージ時間情報などの実験結果は得られませんでした。さらに、推論時間も表 1 の最後の列に示されています。
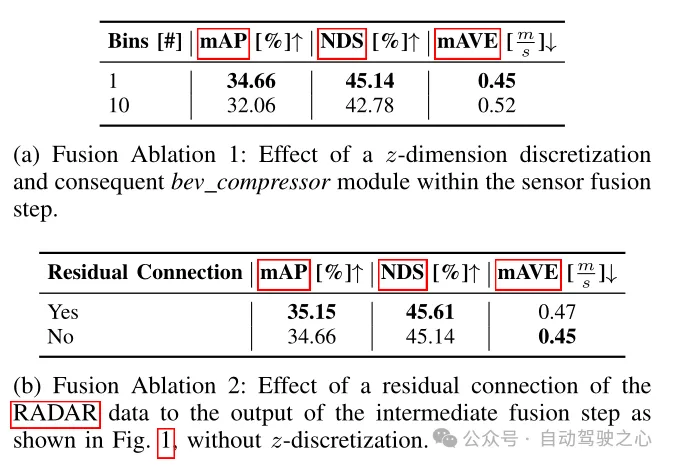
表 3 ベースライン BEVDet および CR3DT のさまざまな構成に基づく nuScenes 検証セットでの追跡結果 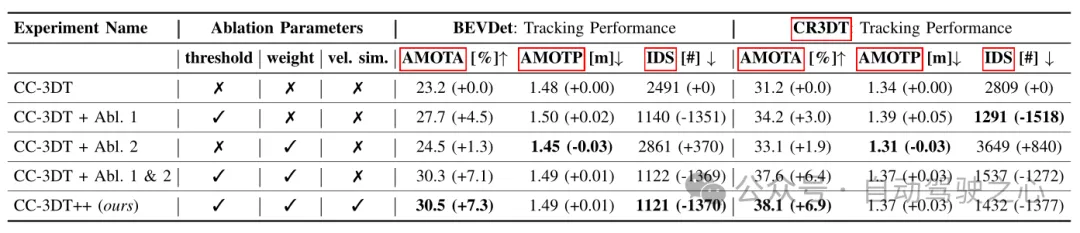
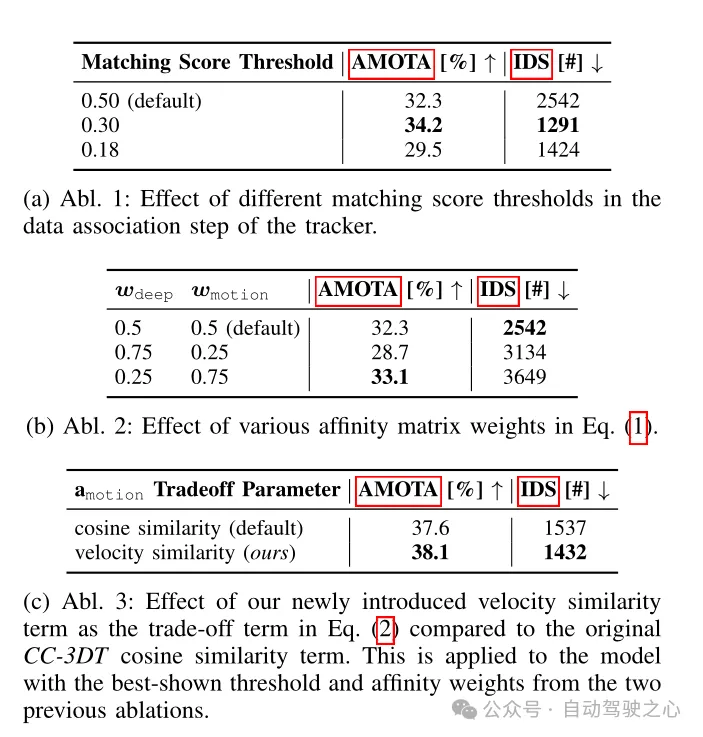 #表 4 CR3DT 検出バックボーンの追跡アーキテクチャ アブレーション実験
#表 4 CR3DT 検出バックボーンの追跡アーキテクチャ アブレーション実験

この研究では、特に 3D ターゲット検出とマルチターゲット追跡のための、効率的なカメラとレーダーの融合モデル CR3DT を提案します。レーダー データをカメラ専用の BEVDet アーキテクチャに統合し、CC-3DT 追跡アーキテクチャを導入することにより、CR3DT は 3D ターゲットの検出と追跡の精度を大幅に向上させ、mAP と AMOTA がそれぞれ 5.35% と 14.9% 増加しました。
カメラとミリ波レーダーの融合ソリューションは、純粋な LiDAR または LiDAR とカメラの融合ソリューションと比較して低コストという利点があり、現在の自動運転車の開発に近いものです。さらに、ミリ波レーダーには悪天候にも強いという利点があり、さまざまな応用シナリオに対応できます。現在の大きな問題は、ミリ波レーダーの点群がまばらであり、高さ情報を検出できないことです。しかし、4D ミリ波レーダーの継続的な開発により、将来的にはカメラとミリ波レーダー ソリューションの統合がより高いレベルに達し、さらに良い結果が得られると信じています。
以上がBEVFormerを超えて! CR3DT: RV フュージョンは新しい SOTA (ETH) の 3D 検出と追跡を支援しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。