
ホームページ >テクノロジー周辺機器 >AI >北京大学の林周晨氏のチームは、一次最適化アルゴリズムに触発されて、普遍的な近似特性を備えたニューラル ネットワーク アーキテクチャの設計方法を提案しました。
北京大学の林周晨氏のチームは、一次最適化アルゴリズムに触発されて、普遍的な近似特性を備えたニューラル ネットワーク アーキテクチャの設計方法を提案しました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-15 18:22:15946ブラウズ
ニューラル ネットワークは、深層学習テクノロジーの基礎として、多くの応用分野で効果的な成果を上げています。実際には、ネットワーク アーキテクチャは学習効率に大きな影響を与える可能性があります。優れたニューラル ネットワーク アーキテクチャは、問題に関する事前知識を組み込み、ネットワーク トレーニングを確立し、コンピューティング効率を向上させることができます。現在、古典的なネットワーク アーキテクチャ設計手法には、手動設計、ニューラル ネットワーク アーキテクチャ検索 (NAS) [1]、および最適化ベースのネットワーク設計手法 [2] が含まれます。 ResNet などの人工的に設計されたネットワーク アーキテクチャ。ニューラル ネットワーク アーキテクチャの検索は、検索または強化学習を通じて最適なネットワーク構造を検索します。最適化ベースの設計手法の主流のパラダイムは、通常、ネットワークを設計します。明示的な目的関数を使用した最適化アルゴリズムの観点から構造を説明します。 これらの手法は、最適化アルゴリズムの観点からネットワーク構造を設計すると同時に、最適化アルゴリズムの観点からネットワーク構造を設計します。
現在の古典的なニューラル ネットワーク アーキテクチャ設計のほとんどは、ネットワークの普遍的な近似を無視しています。これは、ニューラル ネットワークの強力なパフォーマンスの重要な要素の 1 つです。したがって、これらの設計方法では、ネットワークのアプリオリな性能保証がある程度失われます。 2 層ニューラル ネットワークは、幅が無限大になる傾向がある場合に普遍的な近似特性を備えていますが [3]、実際には、通常、限られた幅のネットワーク構造のみを考慮することができ、この領域でのパフォーマンス解析の結果は非常に限られています。実際、ヒューリスティック人工設計であろうと、ブラックボックス ニューラル ネットワーク アーキテクチャの探索であろうと、ネットワーク設計において普遍的な近似特性を考慮することは困難です。最適化ベースのニューラル ネットワーク設計は比較的解釈しやすいですが、通常は明確な目的関数が必要となるため、設計されるネットワーク構造の種類が限られ、適用範囲が制限されます。普遍的な近似特性を備えたニューラル ネットワーク アーキテクチャを体系的に設計する方法は依然として重要な問題です。
北京大学の Lin Zhouchen 教授のチームは、最適化アルゴリズム設計ツールに基づいたニューラル ネットワーク アーキテクチャを提案しました。この手法は、勾配ベースの一次最適化アルゴリズムとハッシュ ベースの最適化アルゴリズムを組み合わせたものです。二次最適化。アルゴリズムを組み合わせることで、トレーニング速度と収束パフォーマンスが向上し、ニューラル ネットワークの堅牢性の保証が強化されます。このニューラル ネットワーク モジュールは、既存のモジュールベースのネットワーク設計手法でも使用でき、モデルのパフォーマンスを向上させ続けます。最近では、ニューラル ネットワーク微分方程式 (NODE) の近似特性を解析し、層間接続されたニューラル ネットワークが普遍的な近似特性を持つことを証明しました。また、提案されたフレームワークを ConvNext や ViT などのバリアント ネットワークの設計に使用し、成果を上げました。ベースラインを超えました。この論文は、人工知能のトップジャーナルである TPAMI に受理されました。

- 論文: 普遍的に近似するディープ ニューラル ネットワークの設計: 一次最適化アプローチ # #論文アドレス: https://ieeexplore.ieee.org/document/10477580
従来型ベースの最適化されたニューラルネットワーク設計手法は、多くの場合、明示的な式を使用した目的関数から開始し、特定の最適化アルゴリズムを使用してそれを解決し、その後、最適化結果をニューラル ネットワーク構造にマッピングします。たとえば、有名な LISTA-NN は、LISTA アルゴリズムを使用して、 LASSO 問題。結果として得られる明示的な式は、最適化の結果をニューラル ネットワーク構造に変換します [4]。この方法は目的関数の明示的な表現に強く依存するため、結果として得られるネットワーク構造は目的関数の明示的な表現に対してしか最適化できず、実際の状況に適合しない仮定を設計する危険性があります。 目的関数をカスタマイズしたり、アルゴリズム拡張などの手法を用いてネットワーク構造を設計しようとする研究者もいますが、重みの再結合などの仮定も必要となり、実際の状況では必ずしもその仮定を満たさない可能性があります。したがって、一部の研究者は、ニューラル ネットワークに基づく進化的アルゴリズムを使用してネットワーク アーキテクチャを探索し、より合理的なネットワーク構造を取得することを提案しています。
ネットワーク アーキテクチャ設計スキームの更新形式は、一次最適化アルゴリズムから近接点アルゴリズムまでの考え方に従い、段階的な最適化を実行する必要があります。たとえば、オイラー角アルゴリズムを四元数アルゴリズムに変更したり、より効率的な反復アルゴリズムを使用して解を近似したりできます。更新された形式では、計算精度の向上と運用効率の向上を考慮する必要があります。
ここで、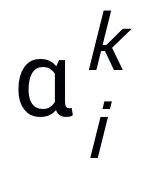 と
と 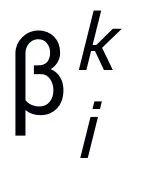 は k 番目のステップ更新時の (ステップ長) 係数を表し、勾配項をニューラル ネットワーク内の学習可能なモジュール T に置き換えます。 L 層ニューラル ネットワークのスケルトンを取得します。
は k 番目のステップ更新時の (ステップ長) 係数を表し、勾配項をニューラル ネットワーク内の学習可能なモジュール T に置き換えます。 L 層ニューラル ネットワークのスケルトンを取得します。
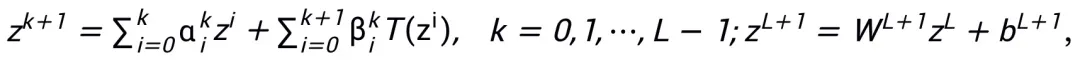
全体的なメソッドのフレームワークを図 1 に示します。
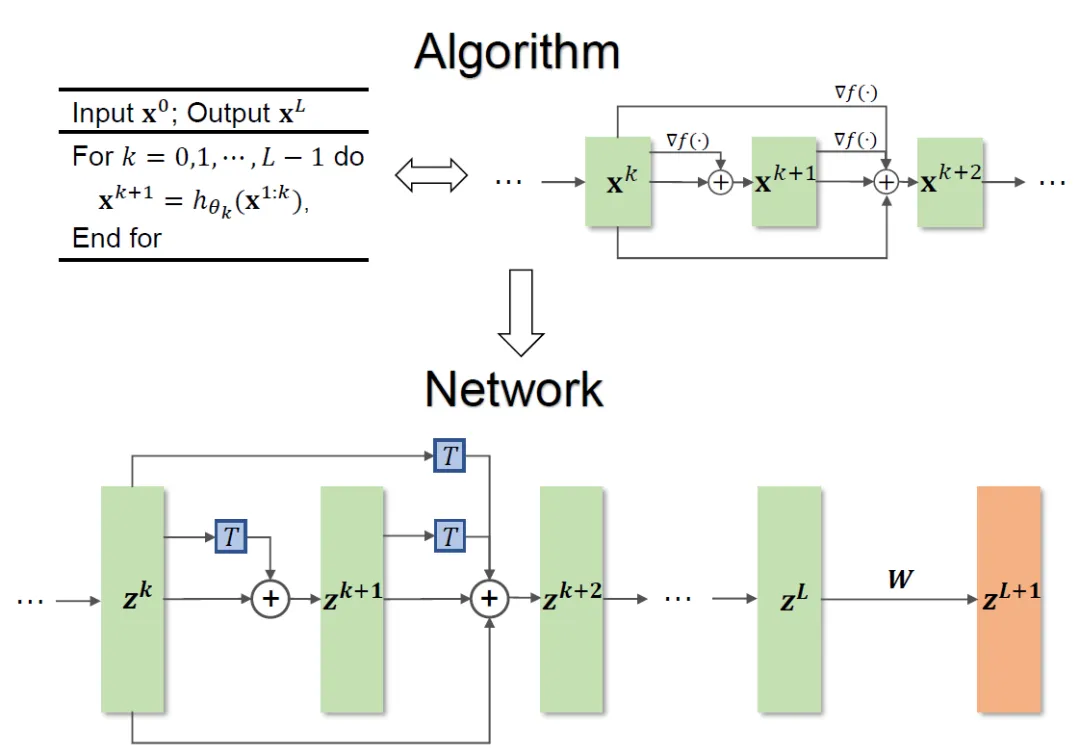
#図 1 ネットワーク設計図
この論文で提案されている方法は、ResNet の設計にインスピレーションを与えることができます。 、DenseNet などの古典的なネットワークであり、ネットワーク アーキテクチャの最適化設計に基づく従来の手法が特定の目的関数に限定されるという問題を解決します。
モジュールの選択とアーキテクチャの詳細
この方法で設計されたネットワーク モジュール T には、2 層ネットワークのみが必要です構造、つまり 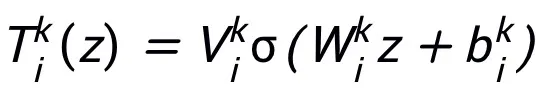 をその下部構造として使用すると、設計されたネットワークが普遍的な近似特性を持つことを保証できます。この特性では、表現される層の 幅が制限されます (つまり、ランダムではなく(近似精度の向上とともに増加します)、
をその下部構造として使用すると、設計されたネットワークが普遍的な近似特性を持つことを保証できます。この特性では、表現される層の 幅が制限されます (つまり、ランダムではなく(近似精度の向上とともに増加します)、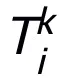 層を広げることでネットワーク全体の普遍的な近似特性が得られるわけではありません。モジュール T は、ResNet で広く使用されている事前アクティベーション ブロックにすることも、Transformer のアテンション フィードフォワード層の構造にすることもできます。 T の活性化関数には、ReLU、GeLU、Sigmoid などの一般的な活性化関数を使用できます。特定のタスクに応じて、対応する正規化レイヤーを追加することもできます。さらに、
層を広げることでネットワーク全体の普遍的な近似特性が得られるわけではありません。モジュール T は、ResNet で広く使用されている事前アクティベーション ブロックにすることも、Transformer のアテンション フィードフォワード層の構造にすることもできます。 T の活性化関数には、ReLU、GeLU、Sigmoid などの一般的な活性化関数を使用できます。特定のタスクに応じて、対応する正規化レイヤーを追加することもできます。さらに、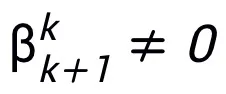 の場合、設計されたネットワークは陰的ネットワーク [5] であり、固定小数点反復法を使用して陰的形式を近似することも、陰的微分法を使用して勾配を解くこともできます。
の場合、設計されたネットワークは陰的ネットワーク [5] であり、固定小数点反復法を使用して陰的形式を近似することも、陰的微分法を使用して勾配を解くこともできます。
#等価表現によるより多くのネットワークの設計
この方法では、同じアルゴリズムが 1 つのみに対応する必要はありません。それとは対照的に、構造では、この方法は最適化問題の同等の表現を使用して、その柔軟性を反映してより多くのネットワーク アーキテクチャを設計できます。たとえば、線形化された交互方向乗算法は、制約付きの最適化問題を解決するためによく使用されます。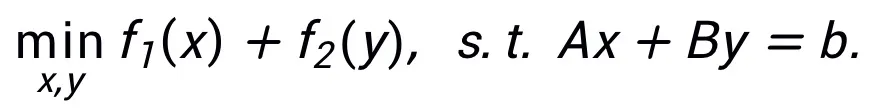
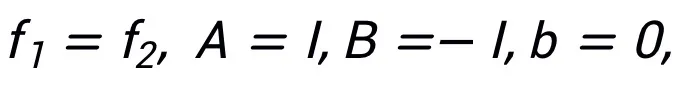 #着想を得たネットワーク構造を図 2 に示します。 。
#着想を得たネットワーク構造を図 2 に示します。 。
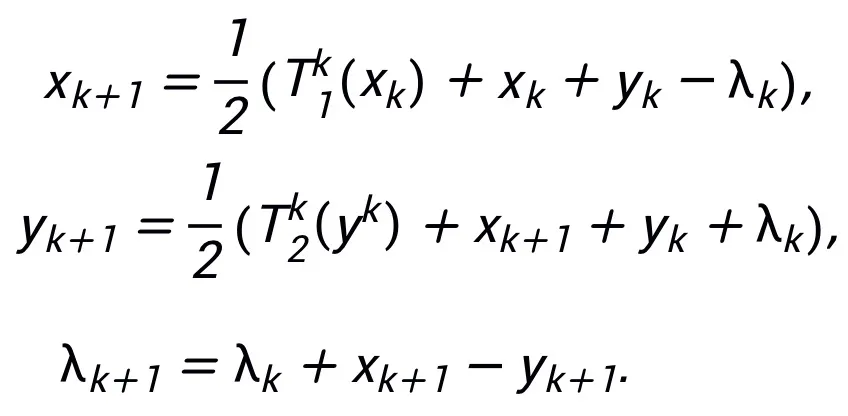
インスピレーションネットワーク普遍的な近似特性を持つ
この方法で設計されたネットワーク アーキテクチャは、モジュールが前述の条件を満たし、最適化アルゴリズム (一般に) が安定して収束するという条件下で、ニューラル ネットワークが一次最適化からインスピレーションを得たものであることを証明できます。アルゴリズムは高次元で実行できます。 連続関数空間は普遍的な近似特性を持ち、近似速度が与えられます。この論文は、制限された幅設定の下で一般的な層間接続を備えたニューラル ネットワークの普遍的な近似特性を初めて証明しました (以前の研究は基本的に FCNN と ResNet に焦点を当てていました。主定理を参照)。この論文の内容は次のように簡単に説明できます:
主定理 (短縮版): 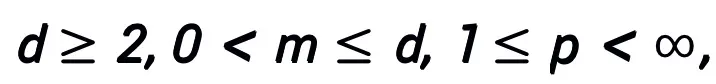 A ## と仮定します。 # は勾配型一次最適化アルゴリズムです。アルゴリズム A が式 (1) の更新形式を持ち、収束条件を満たす場合 (最適化アルゴリズムの一般的なステップ サイズの選択はすべて収束条件を満たします。それらがすべてヒューリスティック ネットワークで学習可能であれば、この条件は必要ありません)、アルゴリズムに触発されたニューラル ネットワーク:
A ## と仮定します。 # は勾配型一次最適化アルゴリズムです。アルゴリズム A が式 (1) の更新形式を持ち、収束条件を満たす場合 (最適化アルゴリズムの一般的なステップ サイズの選択はすべて収束条件を満たします。それらがすべてヒューリスティック ネットワークで学習可能であれば、この条件は必要ありません)、アルゴリズムに触発されたニューラル ネットワーク:
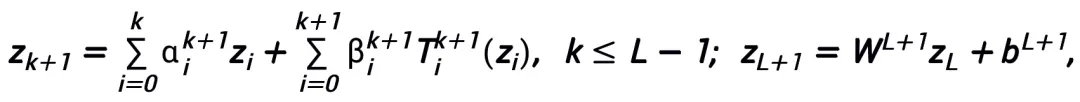
連続 (ベクトル値) 関数空間で 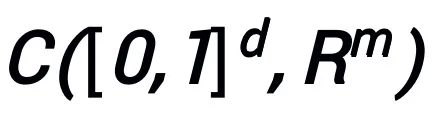 # そしてこれは、ノルム
# そしてこれは、ノルム 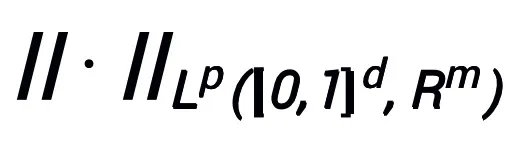 の下で普遍的な近似特性を持ちます。学習可能なモジュール T には、形式
の下で普遍的な近似特性を持ちます。学習可能なモジュール T には、形式  の 2 層構造が含まれているだけで済みます (σ は一般的に活性化関数 ) をその部分構造として使用しました。
の 2 層構造が含まれているだけで済みます (σ は一般的に活性化関数 ) をその部分構造として使用しました。
一般的に使用される T 構造は次のとおりです:
1) 畳み込みネットワークでは、事前アクティブ化ブロック: BN-ReLU-Conv-BN -ReLU -Conv (z),
##2) Transformer: Attn (z) MLP (z Attn (z)).の証明主定理は、NODE の普遍的な近似特性と線形マルチステップ法の収束特性を利用し、最適化アルゴリズムによって触発されたネットワーク構造が収束線形マルチステップによる連続 NODE の離散化に対応することを証明することです。 step メソッドにより、インスピレーションを受けたネットワークが NODE の近似機能を「継承」します。証明では、この論文は、d 次元空間で連続関数を近似するための NODE の近似速度も示し、前の論文 [6] の残された問題を解決します。
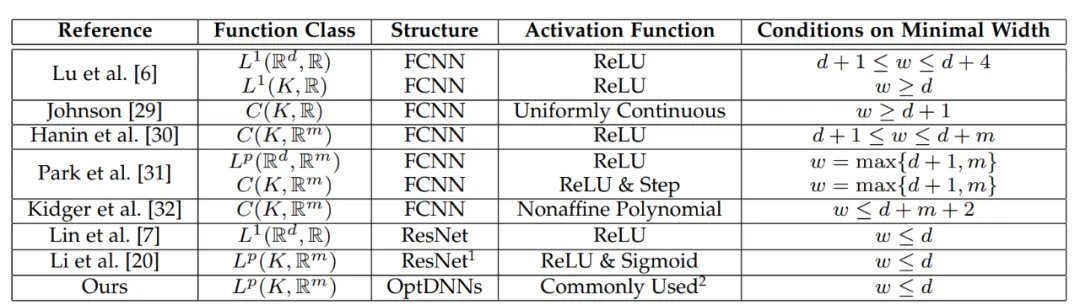 #表 1 ユニバーサル近似の特性に関するこれまでの研究は、基本的に FCNN と ResNet に焦点を当てていました。
#表 1 ユニバーサル近似の特性に関するこれまでの研究は、基本的に FCNN と ResNet に焦点を当てていました。
実験的結果
この論文では、提案されたネットワーク アーキテクチャ設計フレームワークを使用して、8 つの明示的ネットワークと 3 つの暗黙的ネットワーク (OptDNN と呼ばれます) を設計します。ネットワーク情報は表 2 に示されており、実験にネストされています。リング分離、関数近似、画像分類などの問題について研究が行われました。また、この論文では、ResNet、DenseNet、ConvNext、ViT をベースラインとして使用し、提案された方法を使用して改良された OptDNN を設計し、精度と FLOP の 2 つの指標を考慮して画像分類の問題に関する実験を行っています。
#表 2 設計したネットワークの関連情報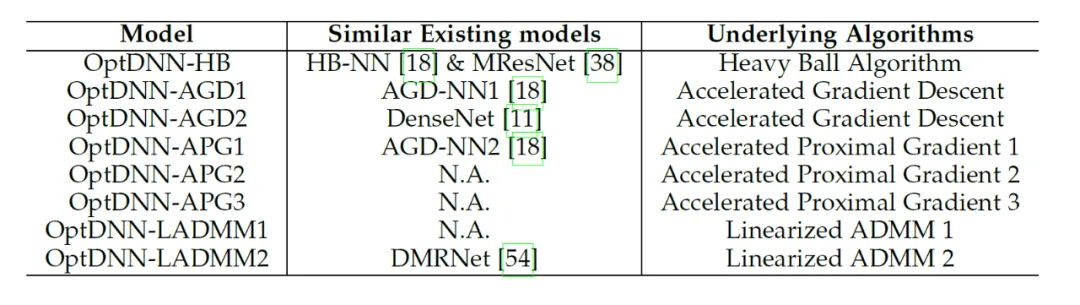
まず、OptDNN を分離し、実験を行います。関数近似の 2 つの問題を取り上げて、その普遍的な近似特性を検証します。関数近似問題では、近似パリティ関数とタルガースキー関数がそれぞれ考慮され、前者は二値分類問題として表現でき、後者は回帰問題として表されます。どちらも浅いネットワークで近似するのは困難です。ネストリング分離における OptDNN の実験結果を図 3 に、関数近似における実験結果を図 3 に示します。OptDNN は良好な分離/近似結果を達成しただけでなく、ベースラインとしての ResNet よりも優れた結果も達成しました。分類間隔とより小さい回帰誤差は、OptDNN の普遍的な近似特性を検証するのに十分です。
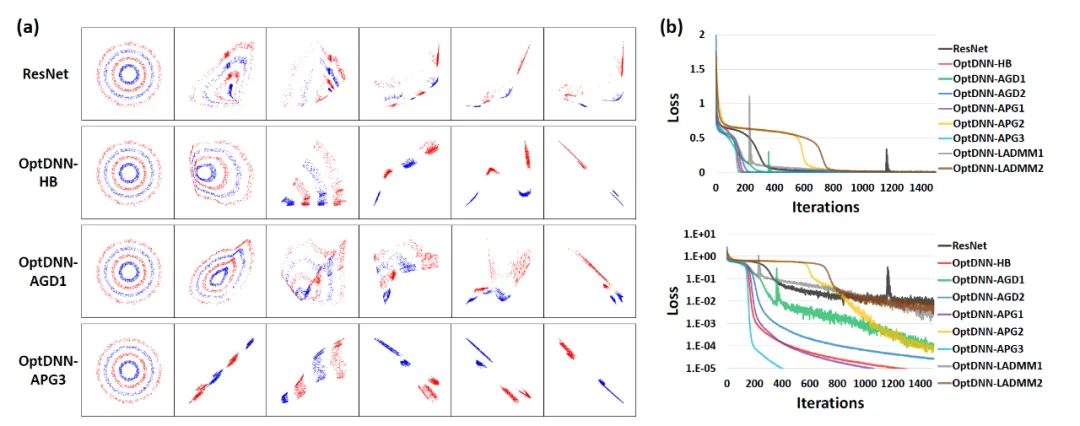
#図 3 OptNN 近似パリティ関数
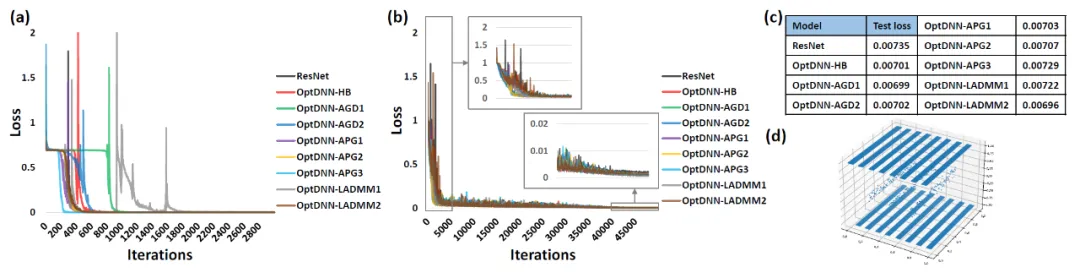
#次に、OptDNN は、広い - 浅い、狭い - 深いという 2 つの設定で CIFAR データ セットの画像分類タスクの実験を実施しました。結果は表を参照してください。 3と4。実験はすべて、強力なデータ拡張設定の下で実施され、一部の OptDNN は同じまたはさらに小さい FLOP オーバーヘッドで ResNet よりも低いエラー率を達成したことがわかります。この論文では、ResNet および DenseNet 設定下でも実験を実施し、同様の実験結果を達成しました。
#表 3 広く浅い設定での OptDNN の実験結果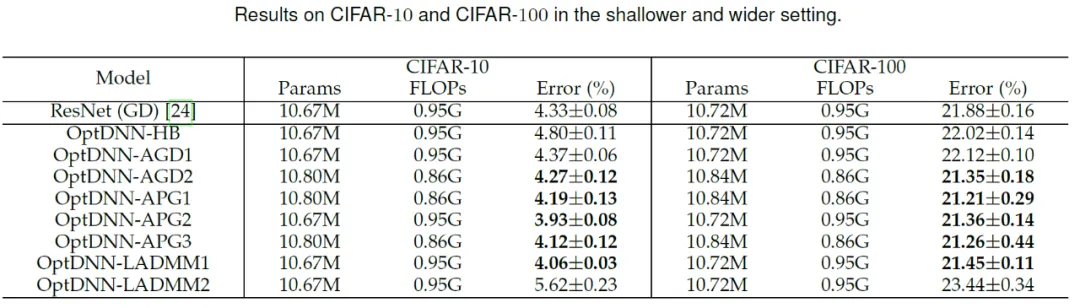
##表 4 ナローディープ設定での OptDNN の実験結果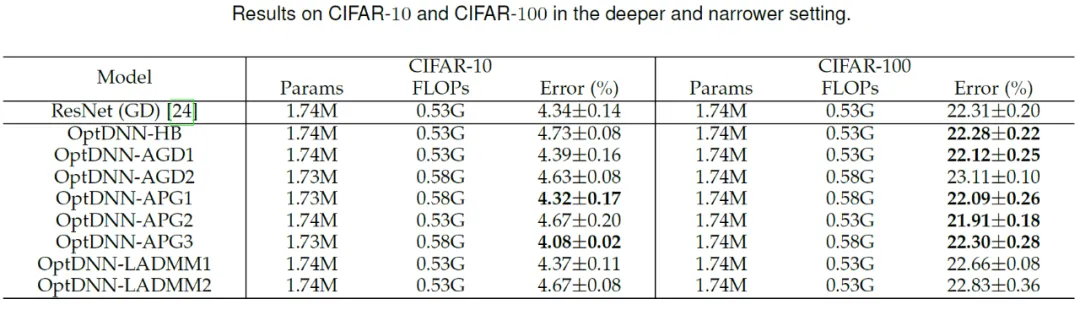
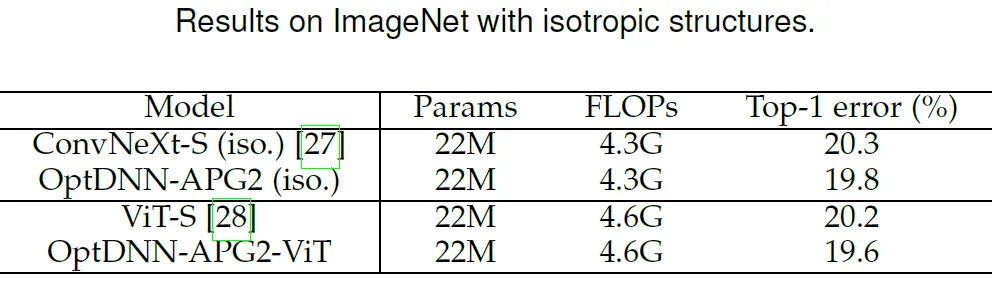
この論文では、以前に優れたパフォーマンスを発揮した OptDNN-APG2 ネットワークをさらに選択し、ConvNext と ViT のパフォーマンスをさらに向上させています。以下の設定で ImageNet データセットに対して実験を実施しました。OptDNN-APG2 のネットワーク構造を図 5 に示し、実験結果を表 5 および表 6 に示します。 OptDNN-APG2 は、等幅 ConvNext および ViT を超える精度率を達成し、このアーキテクチャ設計手法の信頼性がさらに実証されました。
#図 5 OptDNN-APG2 のネットワーク構造
表 5 ImageNet での OptDNN-APG2 のパフォーマンス比較
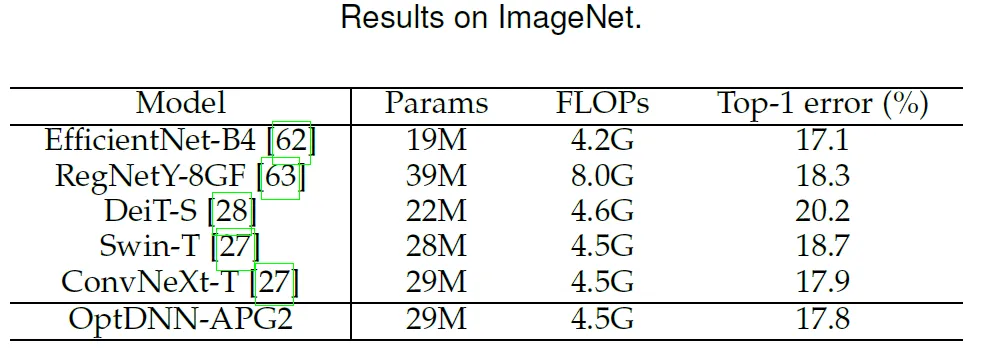
表 6 OptDNN-APG2 と等方性 ConvNeXt および ViT のパフォーマンス比較
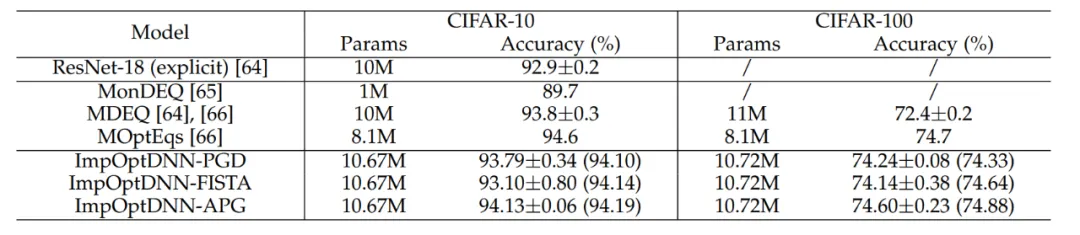
最後に、この論文では、近接勾配降下法や FISTA などのアルゴリズムに基づいて 3 つの陰的ネットワークを設計し、陽的 ResNet といくつかの一般的に使用される陰的ネットワークを使用した CIFAR データセットで実験を実施しました。実験結果は次のとおりです。表 7 に示します。 3 つの暗黙的ネットワークはすべて、高度な暗黙的ネットワークと同等の実験結果を達成しました。これは、手法の柔軟性も示しています。
#表 7 暗黙的ネットワークのパフォーマンスの比較
##ニューラル ネットワーク アーキテクチャの設計は、深層学習における中心的な問題の 1 つです。この論文では、一次最適化アルゴリズムを使用して普遍的な近似特性を持つニューラル ネットワーク アーキテクチャを設計するための統一フレームワークを提案し、最適化設計ネットワーク アーキテクチャ パラダイムに基づいてその方法を拡張します。この方法は、ネットワーク モジュールに焦点を当てたほとんどの既存のアーキテクチャ設計方法と組み合わせることができ、計算量をほとんど増加させることなく効率的なモデルを設計できます。理論の面では、この論文は、収束最適化アルゴリズムによって引き起こされるネットワーク アーキテクチャが穏やかな条件下で普遍的な近似特性を持ち、NODE と一般的な層間接続ネットワークの表現機能の橋渡しとなることを証明しています。この手法は、NAS、SNN アーキテクチャ設計などの分野と組み合わせて、より効率的なネットワーク アーキテクチャを設計することも期待されています。
以上が北京大学の林周晨氏のチームは、一次最適化アルゴリズムに触発されて、普遍的な近似特性を備えたニューラル ネットワーク アーキテクチャの設計方法を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。