
ホームページ >テクノロジー周辺機器 >AI >LoRAの初期化方法を変更、北京大学の新手法PiSSAで微調整効果が大幅に向上
LoRAの初期化方法を変更、北京大学の新手法PiSSAで微調整効果が大幅に向上

- 王林転載
- 2024-04-13 08:07:051171ブラウズ
大規模なモデルのパラメーターの数が増加するにつれて、モデル全体を微調整するコストは徐々に許容できなくなります。
そこで、北京大学の研究チームは、主流のデータセットに対して現在広く使用されている LoRA の微調整効果を超える、PiSSA と呼ばれる効率的なパラメータ微調整方法を提案しました。

論文: PiSSA: 大規模言語モデルの主特異値と特異ベクトルの適応
論文リンク: https://arxiv.org/pdf/2404.02948.pdf
コードリンク: https://github.com/GraphPKU/PiSSA
図 1 は、PiSSA (図 1c) がモデル アーキテクチャ (図 1b) の点で LoRA [1] と完全に一致していることを示していますが、アダプターの初期化方法が異なります。 LoRA は A をガウス ノイズで初期化し、B を 0 で初期化します。 PiSSA は、主特異値と特異ベクトルを使用してアダプターを初期化し、A と B を初期化します。
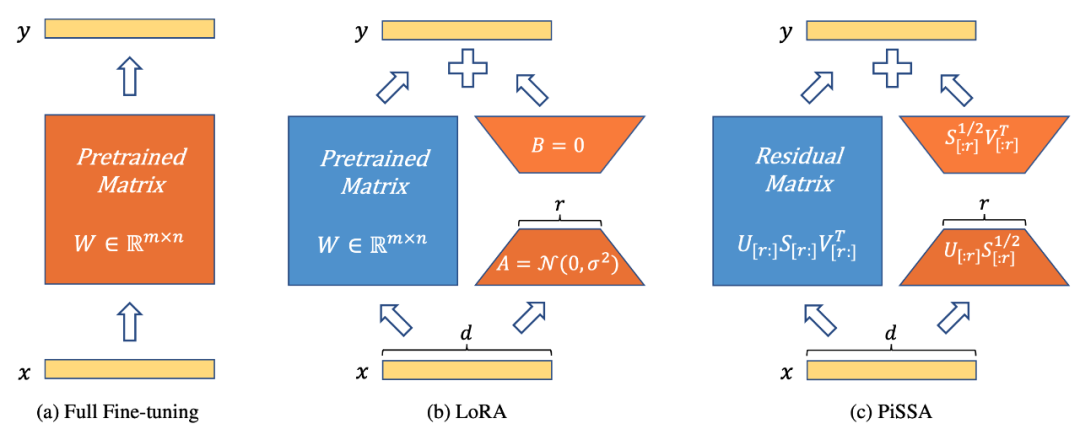
図 1 は、左から右に、完全なパラメータ微調整、LoRA および PiSSA を示しています。青色は凍結されたパラメーターを表し、オレンジ色はトレーニング可能なパラメーターとその他の初期化メソッドを表します。フルパラメータ微調整と比較して、LoRA と PiSSA は両方ともトレーニング可能なパラメータの数を大幅に減らします。同じ入力に対して、これら 3 つのメソッドの初期出力はまったく同じです。ただし、PiSSA はモデルの二次部分をフリーズし、主要部分 (最初の r 特異値と特異ベクトル) を直接微調整しますが、LoRA はモデルの主要部分をフリーズし、ノイズを微調整するとみなすことができます。一部。
さまざまなタスクに対する PiSSA と LoRA の微調整効果を比較
研究チームは、ラマ 2-7B、ミストラル-7B、およびGemma-7B はベース モデルとして機能し、数学、コーディング、会話機能を強化するために微調整が施されています。これらには、MetaMathQA でのトレーニング、GSM8K および MATH データ セットでのモデルの数学的能力の検証、CodeFeedBack でのトレーニング、HumanEval および MBPP データ セットでのモデルのコード能力の検証、および WizardLM-Evol-Instruct でのトレーニングが含まれます。 MT を使用して - ベンチ上でモデルの会話機能を検証します。以下の表の実験結果からわかるように、同じ規模のトレーニング可能なパラメーターを使用した場合、PiSSA の微調整効果は LoRA を大幅に上回り、さらにはフルパラメーターの微調整をも上回ります。
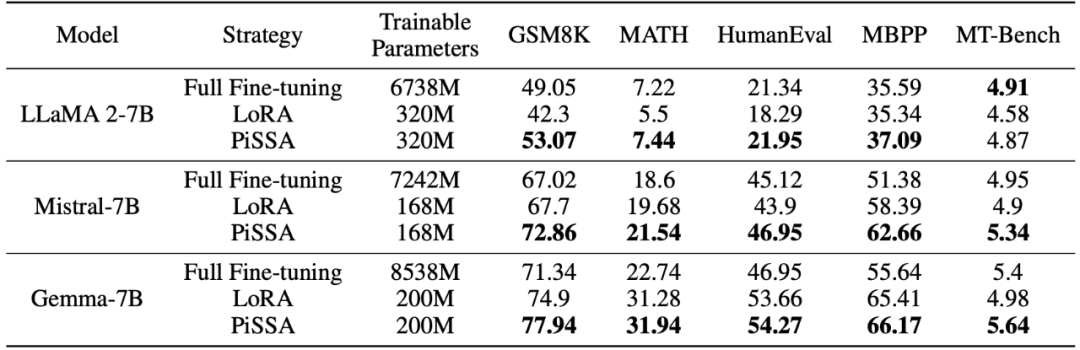
さまざまな量のトレーニング可能なパラメータの下での PiSSA と LoRA 微調整の効果の比較
研究チームはモデルをテストしました数学的タスク トレーニング可能なパラメータの量と効果の関係についてアブレーション実験を実施します。図 2.1 から、訓練の初期段階では、PiSSA の訓練損失は非常に急速に減少しますが、LoRA には減少しないか、わずかに増加する段階があることがわかります。さらに、PiSSA のトレーニング損失は全体を通して LoRA よりも低く、トレーニング セットによりよく適合していることを示しています。図 2.2、2.3、および 2.4 から、各設定の下で PiSSA の損失は常に LoRA よりも低く、その精度が高いことがわかります。常に LoRA よりも高いため、PiSSA は、より少ないトレーニング可能なパラメーターを使用して、フルパラメーター微調整の効果に追いつくことができます。
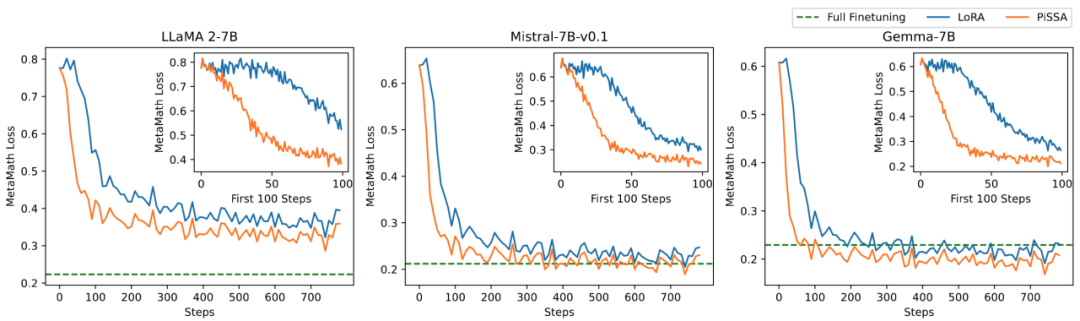
図 2.1) ランクが 1 の場合のトレーニング プロセス中の PiSSA と LoRA の損失。各図の右上隅は、最初の 100 回の反復の拡大曲線です。このうち、PiSSA はオレンジ色の線、LoRA は青色の線で表され、フルパラメータ微調整では緑色の線を使用して最終的な損失を基準として示します。ランクが[2,4,8,16,32,64,128]の場合の現象はこれと一致します。詳細は記事の付録を参照してください。
#そして、LoRA の最後のトレーニング損失。
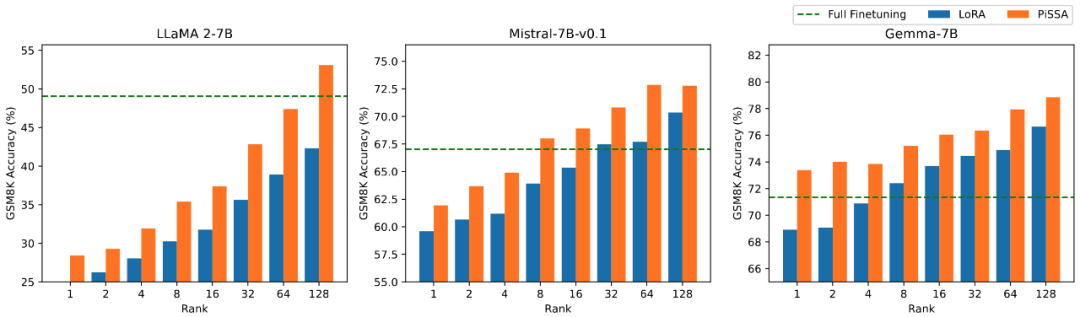
#およびGSM8KのLORA微調整モデルの精度。
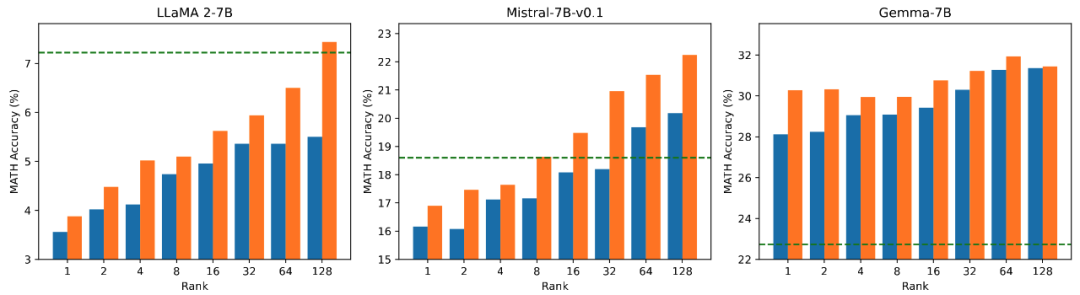
PiSSAメソッドの詳細説明
組み込み SAID [2]「事前トレーニングされた大規模モデルのパラメーターはランクが低い」に触発され、PiSSA は事前トレーニングされたモデルのパラメーター行列 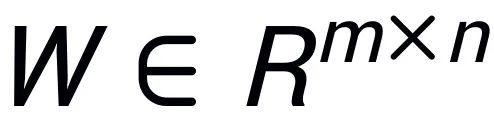 に対して特異値分解を実行します。ここで、最初の r 個の特異値と特異ベクトルが使用されます。アダプターの 2 つの行列
に対して特異値分解を実行します。ここで、最初の r 個の特異値と特異ベクトルが使用されます。アダプターの 2 つの行列  と
と  を初期化します。
を初期化します。 ; 残りの特異値と特異ベクトルは、
; 残りの特異値と特異ベクトルは、 のように残差行列
のように残差行列 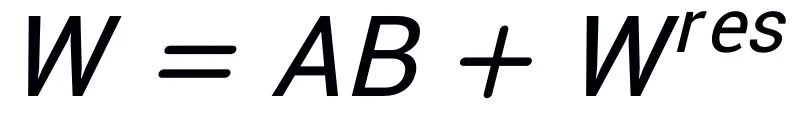 を構築するために使用されます。したがって、アダプター内のパラメーターにはモデルのコア パラメーターが含まれており、残差行列内のパラメーターは補正パラメーターです。より小さいパラメータでコア アダプタ A と B を微調整し、より大きなパラメータで残差行列
を構築するために使用されます。したがって、アダプター内のパラメーターにはモデルのコア パラメーターが含まれており、残差行列内のパラメーターは補正パラメーターです。より小さいパラメータでコア アダプタ A と B を微調整し、より大きなパラメータで残差行列  をフリーズすることにより、非常に少ないパラメータでフルパラメータ微調整に近い効果が得られます。
をフリーズすることにより、非常に少ないパラメータでフルパラメータ微調整に近い効果が得られます。
同様に Intrinsic SAID [1] からインスピレーションを受けていますが、PiSSA と LoRA の背後にある原則は完全に異なります。
LoRA は、大規模モデルの微調整前後の行列 ΔW の変化は、固有ランク r が非常に低いと考えているため、 と
と  を乗算して得られる低ランク行列は、モデル△Wの変化をシミュレーションするために使用されます。初期段階では、LoRA はガウス ノイズを使用して A を初期化し、0 を使用して B を初期化します。したがって、モデルの初期能力が変わらないことを確認するために
を乗算して得られる低ランク行列は、モデル△Wの変化をシミュレーションするために使用されます。初期段階では、LoRA はガウス ノイズを使用して A を初期化し、0 を使用して B を初期化します。したがって、モデルの初期能力が変わらないことを確認するために  を使用し、W を更新するために A と B を微調整します。対照的に、PiSSA は△W を気にせず、W の固有ランク r が非常に低いとみなします。そこで、W を直接特異値分解し、主成分 A、B、残差項
を使用し、W を更新するために A と B を微調整します。対照的に、PiSSA は△W を気にせず、W の固有ランク r が非常に低いとみなします。そこで、W を直接特異値分解し、主成分 A、B、残差項  に分解し、
に分解し、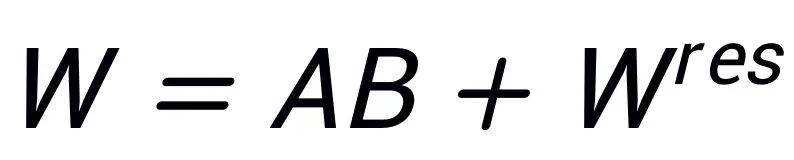 とします。 W の特異値分解が
とします。 W の特異値分解が  であると仮定します。A と B は、SVD 分解後の r 個の特異値と最大の特異値を持つ特異ベクトルを使用して初期化されます。
であると仮定します。A と B は、SVD 分解後の r 個の特異値と最大の特異値を持つ特異ベクトルを使用して初期化されます。
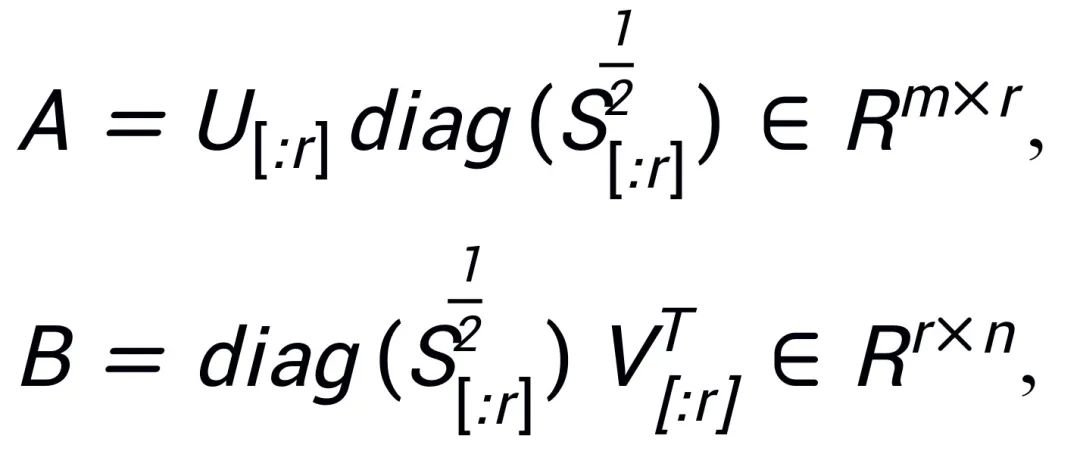
残差行列 残りの特異値と特異ベクトルを初期化に使用します:
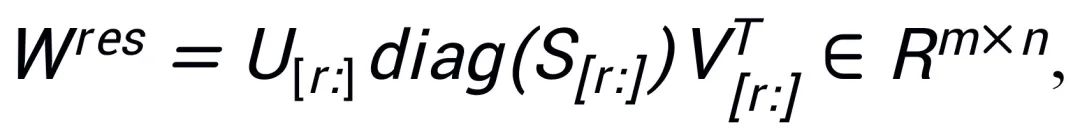
PiSSA は W の低ランク主成分 A と B を直接微調整しますそして軽微な修正条件を凍結します。ガウス ノイズと 0 を使用してアダプター パラメーターを初期化し、コア モデル パラメーターをフリーズする LoRA と比較して、PiSSA はより速く収束し、より良い結果が得られます。
PiSSA は「ピザ」のように発音されます -- 大きなモデル全体を完成したピザと比較すると、PiSSA は 1 つの角を切り落とし、最も濃厚な具材が入った角になります (主特異値、単数形)ベクトル)、好みのフレーバーに再ベイク (ダウンストリーム タスクで微調整) されます。
PiSSA は LoRA とまったく同じアーキテクチャを採用しているため、LoRA のオプションの初期化メソッドとして使用でき、簡単に変更して peft パッケージで呼び出すことができます (次のコードに示すように)。同じアーキテクチャにより、PiSSA は LoRA の利点のほとんどを継承することもできます。たとえば、残差モデルに 4 ビット量子化 [3] を使用して、微調整が完了した後、アダプターを残差モデルにマージできます。推論プロセスのモデル アーキテクチャを変更せずにモデルを作成できます。完全なモデル パラメータを共有する必要はなく、少数のパラメータを含む PiSSA モジュールのみを共有する必要があります。 PiSSA モジュール; モデルは複数の PiSSA モジュールを同時に使用できます。 LoRA メソッドのいくつかの改良点は、PiSSA と組み合わせることもできます。たとえば、各レイヤーのランクを固定する代わりに、PiSSA ガイドによる更新 [5] を使用して学習を通じて最適なランクを見つけ、ランク制限を突破します。等
# 在 peft 包中 LoRA 的初始化方式后面增加了一种 PiSSA 初始化选项:if use_lora:nn.init.normal_(self.lora_A.weight, std=1 /self.r)nn.init.zeros_(self.lora_B.weight) elif use_pissa:Ur, Sr, Vr = svd_lowrank (self.base_layer.weight, self.r, niter=4) # 注意:由于 self.base_layer.weight 的维度是 (out_channel,in_channel, 所以 AB 的顺序相比图示颠倒了一下)self.lora_A.weight = torch.diag (torch.sqrt (Sr)) @ Vh.t ()self.lora_B.weight = Ur @ torch.diag (torch.sqrt (Sr)) self.base_layer.weight = self.base_layer.weight - self.lora_B.weight @ self.lora_A.weight
高、中、低の特異値の微調整効果に関する比較実験
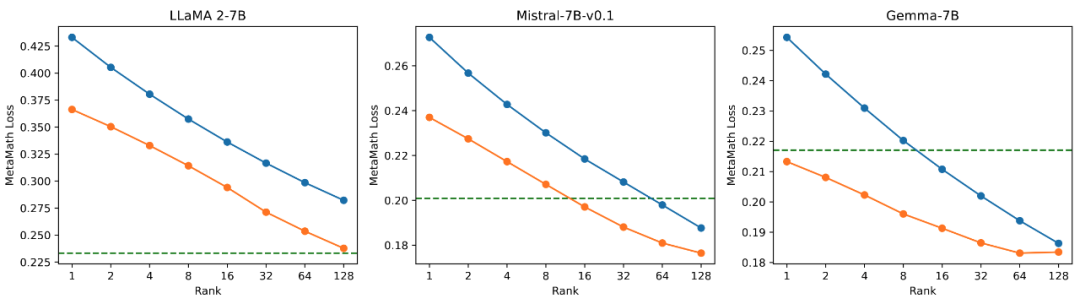
異なるサイズを使用した場合の影響を検証するため研究者らは、LLaMA 2-7B、Mistral-7B-v0.1、および Gemma- のアダプターを初期化するために、高、中、低の特異値を使用しました。実験結果を図 3 に示します。図からわかるように、主特異値初期化を使用する方法は、トレーニング損失が最小であり、GSM8K および MATH 検証セットでの精度が高くなります。この現象は、主要な特異値と特異ベクトルの微調整の有効性を検証します。
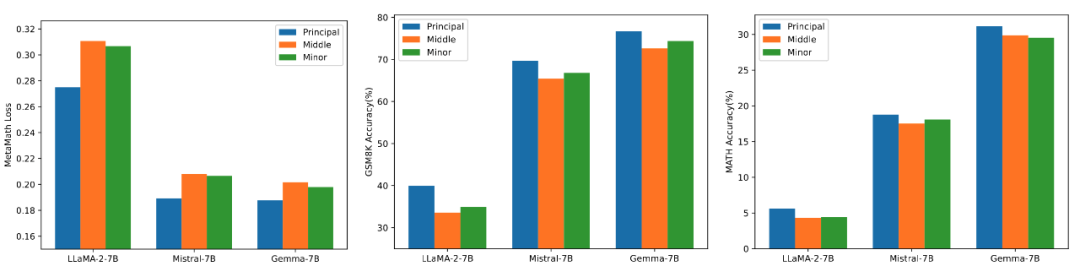
図 3) 左から右へ、トレーニング損失、GSM8K の精度、MATH の精度です。青は最大の特異値を表し、オレンジは中程度の特異値を表し、緑は最小の特異値を表します。
高速特異値分解
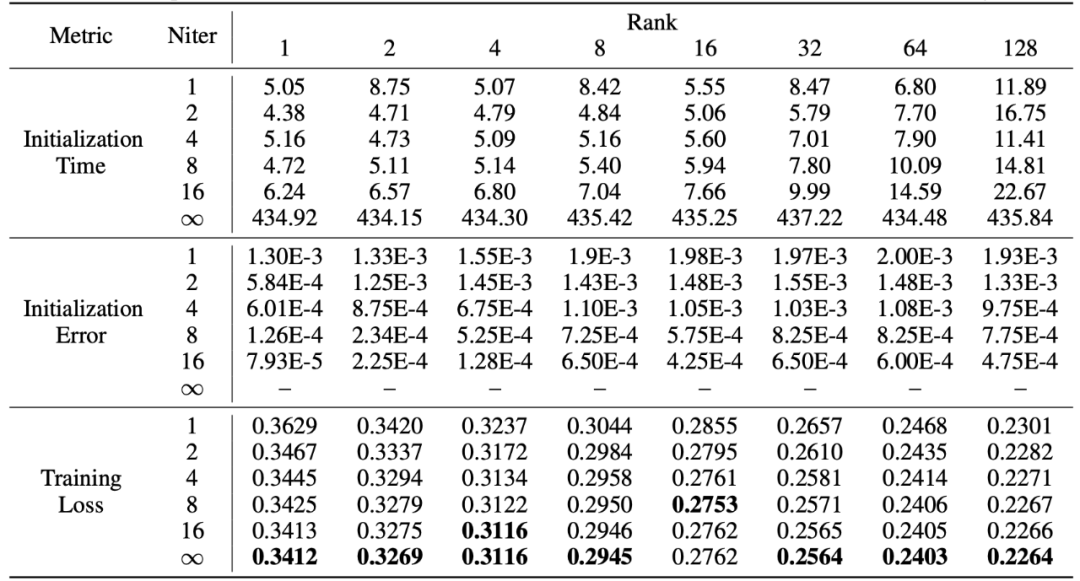
PiSSA は LoRA の利点を継承しており、使いやすく、LoRA よりも優れた効果を持っています。その代償として、初期化フェーズ中にモデルを特異値分解する必要があるということです。分解する必要があるのは初期化中に 1 回だけですが、それでも数分、場合によっては数十分のオーバーヘッドが必要になる場合があります。したがって、研究者らは、標準 SVD 分解の代わりに高速特異値分解 [6] 手法を使用しました。以下の表の実験からわかるように、標準 SVD のトレーニング セット フィッティング効果を近似するのに数秒しかかかりません。分解。 Niter は反復回数を表します。Niter が大きいほど時間は長くなりますが、誤差は小さくなります。 Niter = ∞ は標準 SVD を表します。表内の平均誤差は、高速特異値分解と標準 SVD によって取得された A と B の間の平均 L_1 距離を表します。
概要と展望
この作業では、事前トレーニングされたモデルの重みに対して特異値分解を実行します。重要なパラメーター PiSSA という名前のアダプターを初期化し、このアダプターを微調整して、モデル全体の微調整の効果を近似するために使用されます。実験によると、PiSSA は LoRA よりも収束が速く、最終結果が良好であることが示されています。唯一のコストは、数秒かかる SVD 初期化プロセスです。
それでは、より良いトレーニング結果を得るために、さらに数秒かけて、ワンクリックで LoRA の初期化を PiSSA に変更してもよろしいでしょうか?
#参考文献
[1] LoRA: 大規模言語モデルの低ランク適応
[2] 固有の次元性が言語モデルの微調整の有効性を説明する
[3] QLoRA: 効率的な微調整
#[4] AdaLoRA: パラメータ効率の高い微調整のための適応型予算割り当て
[5] Delta-LoRA: 低ランク行列のデルタによる高ランクパラメータの微調整
##[6] ランダム性のある構造の発見: 近似行列分解を構築するための確率的アルゴリズム以上がLoRAの初期化方法を変更、北京大学の新手法PiSSAで微調整効果が大幅に向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。