Gemini 1.5 Pro はこのテクノロジーを使用しているのだろうか。
Google はさらに大きな動きを見せ、次世代の Transformer モデル Infini-Transformer をリリースしました。
Infini-Transformer は、メモリや計算要件を増加させることなく、Transformer ベースの大規模言語モデル (LLM) を無限に長い入力に拡張する効率的な方法を導入します。研究者らは、このテクノロジーを使用して、1B モデルのコンテキスト長を 8B モデルに適用して 100 万まで増やすことに成功し、このモデルは 500K の本の要約タスクを処理できます。 Transformer アーキテクチャは、2017 年に画期的な研究論文「Attending is All You Need」が発表されて以来、生成人工知能の分野を支配してきました。 Google による Transformer の最適化設計は最近比較的頻繁に行われており、数日前に Transformer アーキテクチャを更新し、以前の Transformer コンピューティング モデルを変更する Mixture-of-Depths (MoD) をリリースしました。数日以内に、Google はこの新しい調査結果を発表しました。 AI 分野を専門とする研究者は皆、メモリはインテリジェンスの基礎であり、LLM に効率的なコンピューティングを提供できることを理解しています。ただし、Transformer および Transformer ベースの LLM は、アテンション メカニズム (Transformer のアテンション メカニズム) の固有の特性により、メモリ使用量と計算時間の両方で 2 次の複雑さを示します。たとえば、バッチ サイズが 512、コンテキスト長が 2048 の 500B モデルの場合、アテンション キー/値 (KV) 状態のメモリ フットプリントは 3 TB です。しかし実際には、標準の Transformer アーキテクチャでは、LLM をより長いシーケンス (100 万トークンなど) に拡張する必要がある場合があります。これにより、膨大なメモリ オーバーヘッドが発生し、コンテキストの長さが増加するにつれて、導入コストも増加します。 これに基づいて、Google は効果的なアプローチを導入しました。その重要なコンポーネントは、Infini-attention と呼ばれる新しいアテンション テクノロジです。従来のトランスフォーマーとは異なり、ローカル アテンションを使用して古いフラグメントを破棄し、新しいフラグメント用にメモリ領域を解放します。 Infini-attention は圧縮メモリを追加します。これにより、使用された古いフラグメントを圧縮メモリに保存でき、出力時に現在のコンテキスト情報と圧縮メモリ内の情報が集約されるため、モデルは完全なコンテキスト履歴を取得できます。 このメソッドにより、Transformer LLM は限られたメモリで無限に長いコンテキストにスケールし、ストリーミング方式で計算のための非常に長い入力を処理できます。 実験の結果、この方法はメモリ パラメーターを 100 分の 1 以上削減しながら、ロング コンテキスト言語モデリング ベンチマークのベースラインを上回るパフォーマンスを示しました。このモデルは、100K のシーケンス長でトレーニングすると、より優れたパープレキシティを実現します。さらに、この研究では、1B モデルが 5K シーケンス長の主要なインスタンスで微調整され、1M の長さの問題が解決されたことがわかりました。最後に、この論文は、Infini-attention を備えた 8B モデルが、継続的な事前トレーニングとタスクの微調整の後、500K の長さの本の要約タスクで新しい SOTA 結果を達成したことを示しています。
- 実践的な内容を紹介します。強力なアテンション 強制メカニズム Infini-attention - 長期圧縮メモリとローカル因果的アテンションを使用して、長期および短期のコンテキスト依存関係を効果的にモデル化できます。標準スケーリングドット積アテンション (標準スケーリングドット積アテンション) は最小限に変更されており、プラグアンドプレイの継続的な事前トレーニングと長いコンテキストの適応をサポートするように設計されています。このアプローチにより、Transformer LLM は、ストリーミング方式で非常に長い入力を処理し、限られたメモリとコンピューティング リソースで無限に長いコンテキストに拡張できるようになります。
- 論文リンク: https://arxiv.org/pdf/2404.07143.pdf
#論文タイトル: コンテキストを残さない: 無限注意による効率的な無限コンテキスト トランスフォーマー
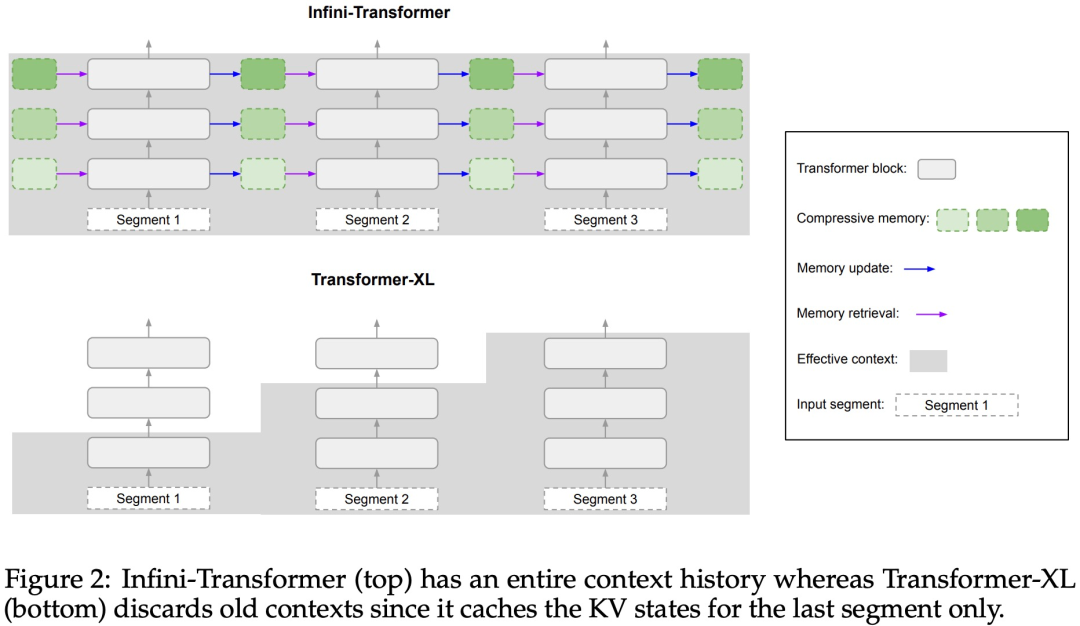
Infini-attention を使用すると、Transformer LLM は限られたメモリ フットプリントと計算で無限に長い入力を効率的に処理できます。以下の図 1 に示すように、Infini-attention は通常のアテンション メカニズムに圧縮メモリを組み込み、マスクされたローカル アテンション メカニズムと長期線形アテンション メカニズムを単一の Transformer ブロック内に構築します。
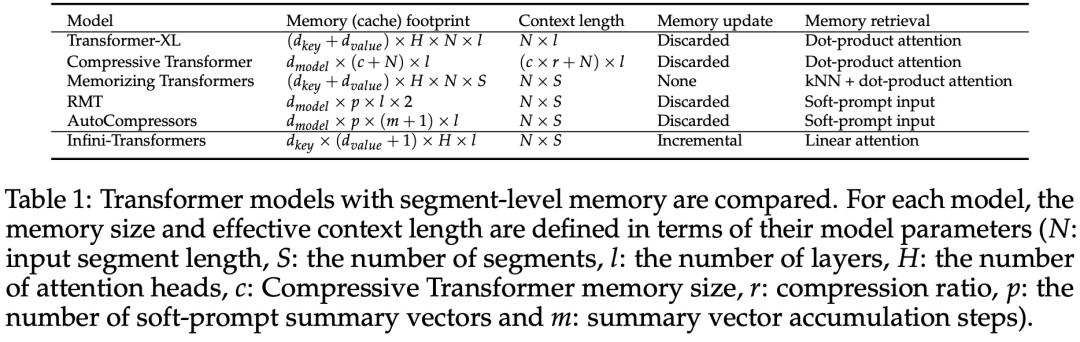
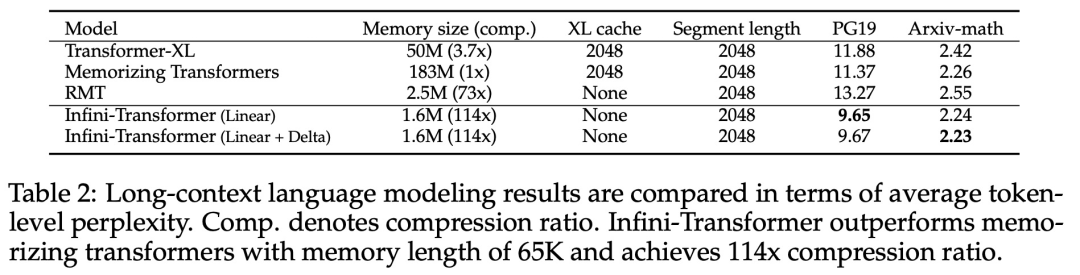
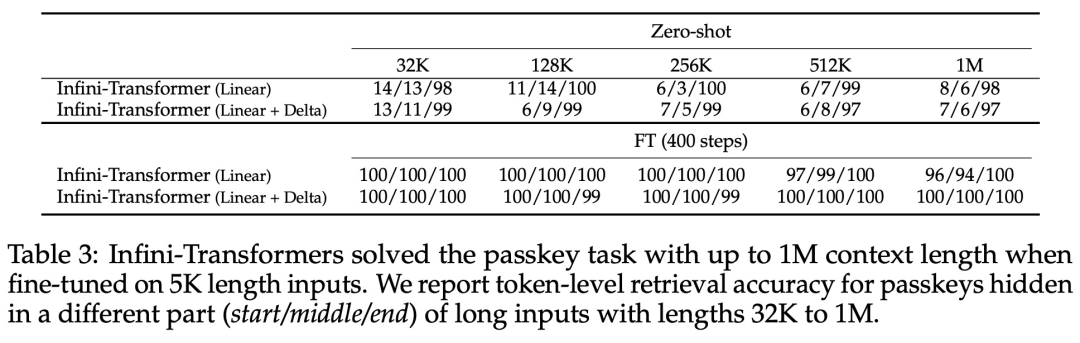
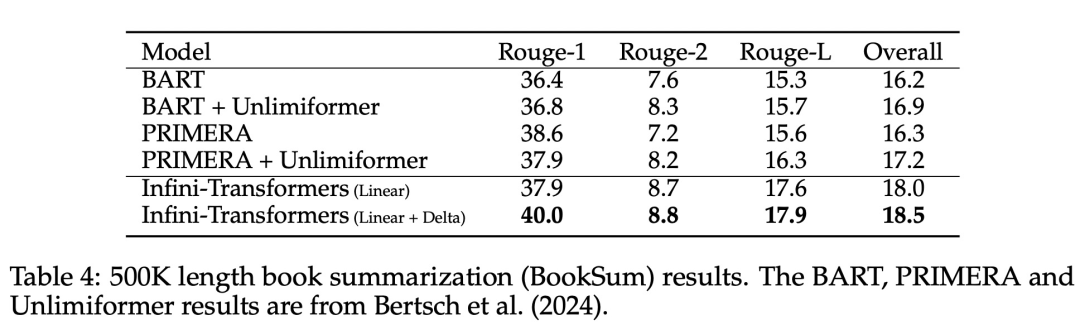
Transformer アテンション レイヤーに対するこの微妙だが重要な変更により、継続的な事前トレーニングと微調整を通じて、既存の LLM のコンテキスト ウィンドウを無限の長さに拡張できます。 Infini-attention は、長期的なメモリの統合と取得のために標準的な Attention 計算のすべてのキー、値、クエリ状態を取得し、アテンションの古い KV 状態が保存されている状態に転送します。標準のアテンション メカニズムのようにメモリを破棄するのではなく、メモリを圧縮します。後続のシーケンスを処理するとき、Infini-attention はアテンション クエリ状態を使用してメモリから値を取得します。最終的なコンテキスト出力を計算するために、Infini-attention は長期メモリ取得値とローカル アテンション コンテキストを集計します。 以下の図 2 に示すように、研究チームは Infini-attention に基づいて Infini-Transformer と Transformer-XL を比較しました。 Transformer-XL と同様に、Infini-Transformer は一連のセグメントを操作し、各セグメントの標準的な因果内積アテンション コンテキストを計算します。したがって、ドット積アテンションの計算はある意味でローカルです。 ただし、ローカル アテンションは次のセグメントを処理するときに前のセグメントのアテンション状態を破棄しますが、Infini-Transformer は古い KV アテンション状態を再利用して、コンテキスト履歴全体を維持します。圧縮されたストレージ。したがって、Infini-Transformer の各注目層には、グローバルな圧縮状態とローカルのきめの細かい状態があります。 マルチヘッド アテンション (MHA) と同様に、ドット積アテンションに加えて、Infini-attention も H 個の並列圧縮メモリを維持します (H はアテンション ヘッドの数です)。 。 以下の表 1 は、モデル パラメーターと入力セグメント長に基づいて、いくつかのモデルで定義されたコンテキスト メモリのフットプリントと有効なコンテキスト長を示しています。 Infini-Transformer は、限られたメモリ フットプリントで無限のコンテキスト ウィンドウをサポートします。 この研究は、長さの長いコンテキスト言語モデリングに基づいています。 1M. Infini-Transformer モデルは、非常に長い入力シーケンスを持つキー コンテキスト ブロックの取得と 500K の長さの本の要約タスクで評価されます。言語モデリングについては、研究者らはモデルを最初からトレーニングすることを選択しましたが、主要なタスクと本の要約タスクについては、LLM の継続的な事前トレーニングを使用して、Infini-attention のプラグアンドプレイのロングコンテキストへの適応性を証明しました。 ロングコンテキスト言語モデリング。表 2 の結果は、Infini-Transformer が Transformer-XL および Memorizing Transformers のベースラインを上回り、Memorizing Transformer モデルと比較して 114 倍少ないパラメータを保存することを示しています。 主要なタスク。表 3 は、最大 1M コンテキスト長までの重要なタスクを解決する、5K 長の入力で微調整された Infini-Transformer を示しています。実験における入力トークンの範囲は、テスト サブセットごとに 32K から 1M で、研究者はキーが入力シーケンスの先頭、中間、または末尾近くに配置されるように制御しました。実験では、ゼロショットの精度と微調整の精度が報告されています。 5K の長さの入力に対して 400 ステップの微調整を行った後、Infini-Transformer は最大 1M のコンテキスト長までのタスクを解決します。 #要約タスク。表 4 は、Infini-Transformer と、要約タスク専用に構築されたエンコーダー/デコーダー モデルを比較しています。結果は、Infini-Transformer がこれまでの最良の結果を上回り、書籍のテキスト全体を処理することで BookSum で新しい SOTA を達成したことを示しています。
#研究者らは、BookSum データ検証分割の全体的な Rouge スコアも図 4 にプロットしました。ポリラインの傾向は、入力の長さが増加するにつれて、Infini-Transformers が要約パフォーマンス メトリックを向上させることを示しています。

以上が無限の長さに直接拡張できる Google Infini-Transformer がコンテキスト長の議論に終止符を打つの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。