
ホームページ >テクノロジー周辺機器 >AI >36年前の呪いを解け! Meta、大規模モデルの「逆転の呪い」を解消する逆転トレーニング手法を開始
36年前の呪いを解け! Meta、大規模モデルの「逆転の呪い」を解消する逆転トレーニング手法を開始

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-09 15:40:09826ブラウズ
The "reversal curse" of the large language model has been solved!
This curse was first discovered in September last year, which immediately caused exclamations from LeCun, Karpathy, Marcus and other big guys.

Because the large model with unique scenery and arrogance actually has an "Achilles heel": one in "A is B" The language model trained on the above model cannot correctly answer "whether B is A".
For example, the following example: LLM knows clearly that "Tom Cruise's mother is Mary Lee Pfeiffer", but cannot answer "Mary Lee Pfeiffer's child is Tom" "Cruise".

#——This was the most advanced GPT-4 at the time. As a result, even children could have normal logical thinking, but LLM could not do it.
Based on massive data, I have memorized knowledge that surpasses almost all human beings, yet behaves so dullly. I have obtained the fire of wisdom, but am forever imprisoned in this curse. .

Paper address: https://arxiv.org/pdf/2309.12288v1.pdf
As soon as this happened, the entire network was in an uproar.
On the one hand, netizens said that the big model is really stupid, really. Knowing only "A is B" but not knowing "B is A", I finally retained my dignity as a human being.
On the other hand, researchers have also begun to study this and are working hard to solve this major challenge.
Recently, researchers from Meta FAIR launched a reverse training method to solve the "reversal curse" of LLM in one fell swoop.
Paper address: https://arxiv.org/pdf/2403.13799.pdf
Research We first observed that LLMs train in an autoregressive manner from left to right—which may be responsible for the reversal curse.
So, if you train LLM (reverse training) in the right-to-left direction, it is possible for the model to see the facts in the reverse direction.
Reverse text can be treated as a second language, leveraging multiple different sources through multitasking or cross-language pre-training.
The researchers considered 4 types of reversal: token reversal, word reversal, entity-preserving reversal and random segment reversal.
Token and word reversal, by splitting a sequence into tokens or words respectively, and reversing their order to form a new sequence.
Entity-preserving reverse finds entity names in a sequence and preserves left-to-right word order within them while doing word reversal.
Random segment inversion splits the tokenized sequence into blocks of random length and then preserves the left-to-right order within each block.
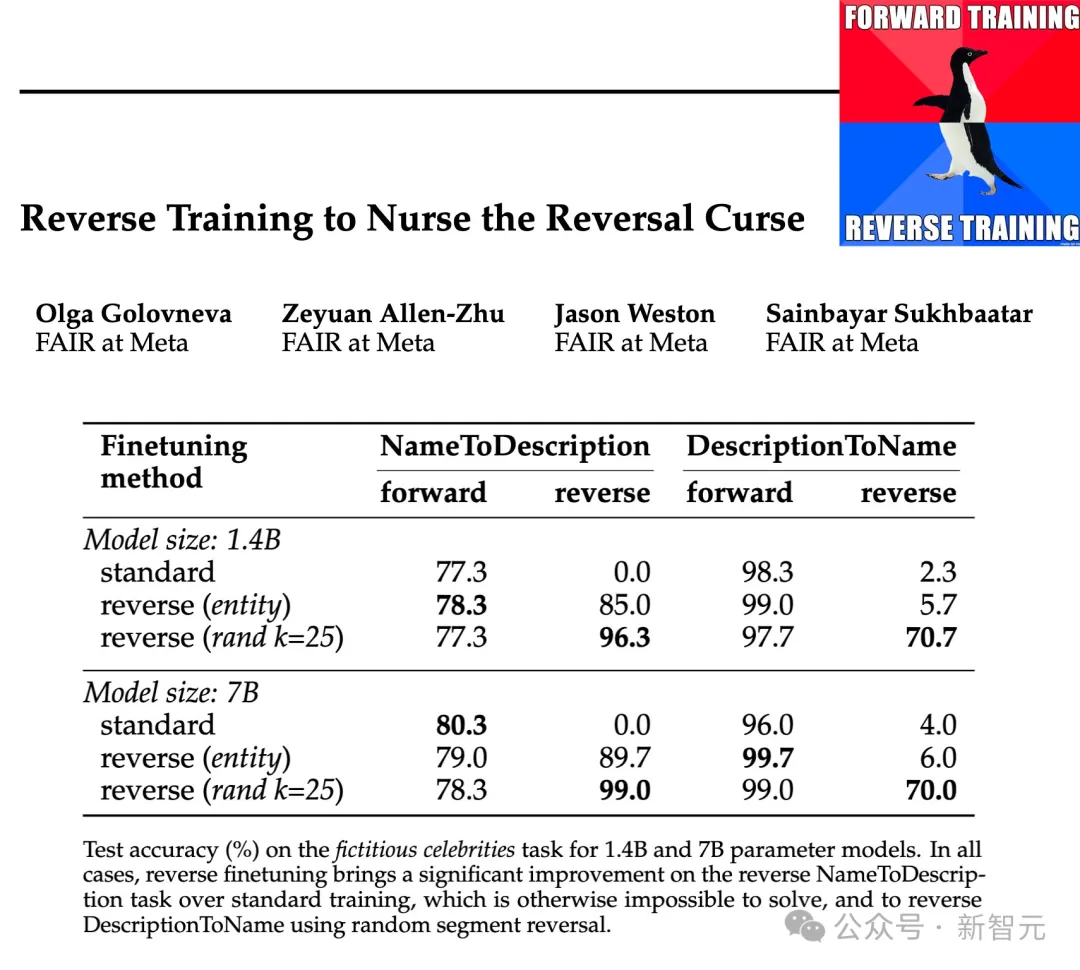
The researchers tested the effectiveness of these inversion types at parameter scales of 1.4B and 7B and showed that entity-preserving and randomized piecewise reverse training can mitigate the inversion curse. , or even eliminate it entirely in some cases.
In addition, the researchers also found that reversing before training improved the performance of the model compared to standard left-to-right training - so reverse training can as a general training method.
Reverse training method
Reverse training includes obtaining a training data set with N samples and constructing a reverse sample set REVERSE (x ).
The function REVERSE is responsible for reversing the given string. The specific method is as follows:
Word reverse: each example is first split for words, then reverse the strings at the word level, concatenating them with spaces.
Инверсия с сохранением сущности: запустите детектор сущностей на заданной обучающей выборке, а также разбивая несущие сущности на слова. Затем слова, не являющиеся сущностями, меняются местами, а слова, представляющие сущности, сохраняют свой первоначальный порядок слов.
Инверсия случайных сегментов: вместо использования детектора сущностей мы пытаемся использовать равномерную выборку, чтобы случайным образом разделить последовательность на сегменты размером от 1 до k токенов, а затем после обращения сегментов, но сохраняя порядок слов внутри каждого сегмента, сегменты соединяются с помощью специального токена [REV].
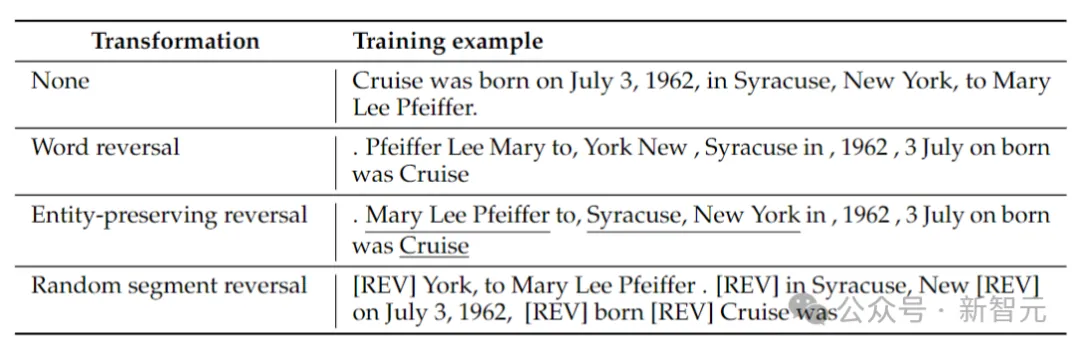
В приведенной выше таблице приведены примеры различных типов обращения для данной строки.
В настоящее время языковая модель по-прежнему обучается слева направо. В случае перестановки слов это эквивалентно прогнозированию предложений справа налево.
Обратное обучение включает обучение на стандартных и обратных примерах, поэтому количество обучающих токенов удваивается, при этом как прямые, так и обратные обучающие выборки смешиваются вместе.
Обратное преобразование можно рассматривать как второй язык, который модель должна выучить. Обратите внимание, что в процессе инверсии взаимосвязь между фактами остается неизменной, и модель может учиться на основе грамматики. , чтобы определить, находится ли он в режиме прямого или обратного языкового прогнозирования.
Другую перспективу обратного обучения можно объяснить теорией информации: цель языкового моделирования состоит в том, чтобы изучить распределение вероятностей естественного языка Обучение и тестирование обратной задачи
#Сопоставление пар сущностей
Сначала создайте простой символ: основанный набор данных для изучения проклятия инверсии в контролируемой среде.
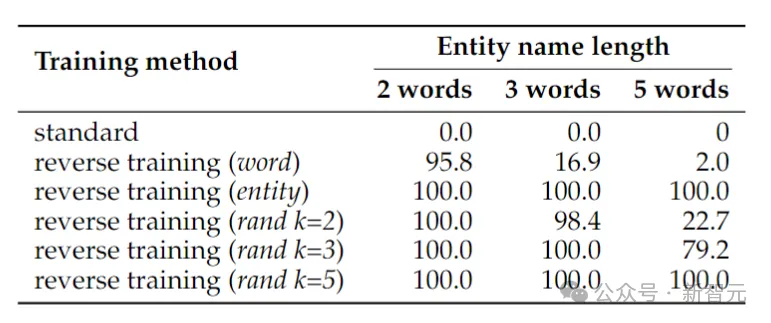
Модель должна вывести правило a→b ⇔ b→a из обучающих данных, а затем обобщить его на пары в тестовых данных.
В приведенной выше таблице показана точность теста (%) задачи символического разворота. Несмотря на простоту задачи, обучение стандартной языковой модели полностью терпит неудачу, что позволяет предположить, что масштабирование само по себе вряд ли решит ее.
Напротив, обратное обучение может почти решить проблему двухсловных сущностей, но его производительность быстро падает по мере того, как сущности становятся длиннее. Реверс слов отлично работает для более коротких объектов, но для объектов с большим количеством слов необходима инверсия с сохранением объекта. Случайное обращение сегмента работает хорошо, когда максимальная длина сегмента k не меньше длины объекта.
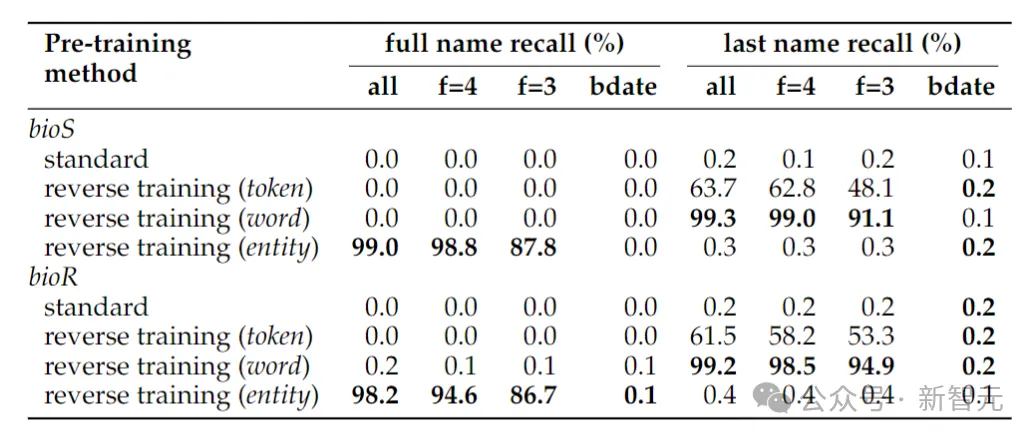
Восстановить имя
#Таблица выше показывает Для инверсионной задачи определения ФИО человека, когда для определения ФИО человека дана только дата рождения, точность решения инверсионной задачи все равно близка к нулю - это связано с тем, что в используемом в данной работе методе обнаружения сущностей статья, дата Рассматриваются как три объекта, поэтому при инверсии их порядок не сохраняется.
Если задача инверсии сводится к простому определению фамилии человека, инверсии на уровне слов вполне достаточно.
Еще одно явление, которое может стать неожиданностью, заключается в том, что метод хранения объекта может определить полное имя человека, но не его фамилию. Это известный феномен: языковые модели могут быть совершенно неспособны извлечь поздние токены фрагментов знаний (например, фамилии).
Факты из реального мира
######Вот автор тренировал Ламу-2 с 1,4 миллиардами Модель параметров, обучение базовой модели из 2 триллионов токенов в направлении слева направо. ############Напротив, обратное обучение использует только 1 триллион токенов, но использует одно и то же подмножество данных для обучения в обоих направлениях: слева направо и справа налево. —— Общее количество токенов по двум направлениям составляет 2 триллиона, что обеспечивает честность и справедливость с точки зрения вычислительных ресурсов. ######
現実世界の事実の逆転をテストするために、研究者らは、「有名人の母親は誰ですか?」などの質問と「有名人の子供は誰ですか?」などのより難しい逆転質問を含む有名人タスクを使用しました。某有名人の両親は?」
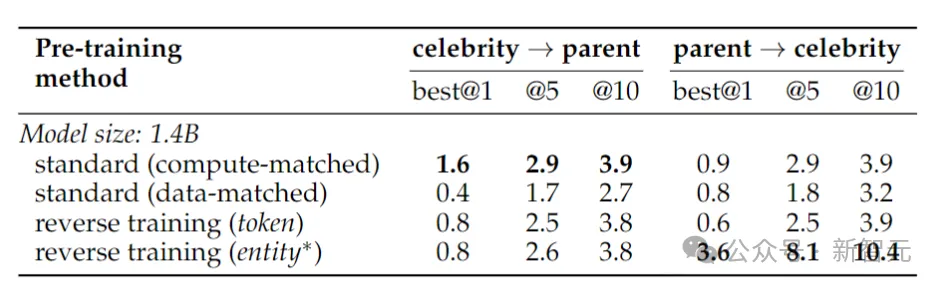
#結果を上の表に示します。研究者らは質問ごとにモデルを複数回サンプリングし、いずれかに正しい答えが含まれていれば成功とみなしました。
一般的に、モデルはパラメーターの数が小さく、事前トレーニングが限られており、微調整が不足しているため、通常、精度は比較的低くなります。ただし、リバーストレーニングのパフォーマンスはさらに優れていました。
36 年前の予言
1988 年、フォーダーとパイリシンは、ジャーナル「認知」の性的記事に思考システムに関する記事を発表しました。

#この世界を本当に理解しているなら、a と b の関係も理解できるはずです。 b と a との相対的な関係。言語を持たない認知生物でもこれはできるはずです。
以上が36年前の呪いを解け! Meta、大規模モデルの「逆転の呪い」を解消する逆転トレーニング手法を開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- メールでのお申込み方法
- AI トレーニング クラスターとは何ですか?
- 会話型セマンティック解析 SParC および CoSQL の国際的な権威リストのトップ、新しいマルチラウンド対話テーブル知識事前トレーニング モデル STAR 解釈
- Kimi Chat の内部テストが開始、Volcano Engine が高速化ソリューションを提供、Moonshot AI 大規模モデル サービスのトレーニングと推論をサポート
- 視覚を利用してプロンプトを表示してください。 Shen Xiangyang 氏は、トレーニングや微調整を必要とせず、すぐに使用できる IDEA Research Institute の新しいモデルを披露しました。