
ホームページ >テクノロジー周辺機器 >AI >生成AIとは何ですか?どのような機能タイプがあるか
生成AIとは何ですか?どのような機能タイプがあるか

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-03 17:58:212007ブラウズ
生成 AI は、テキスト、画像、音声、合成データなど、さまざまな種類のコンテンツを生成できる人間用人工知能テクノロジーの一種です。では、人工知能とは何でしょうか?人工知能と機械学習の違いは何ですか?技術的な特徴は何ですか?
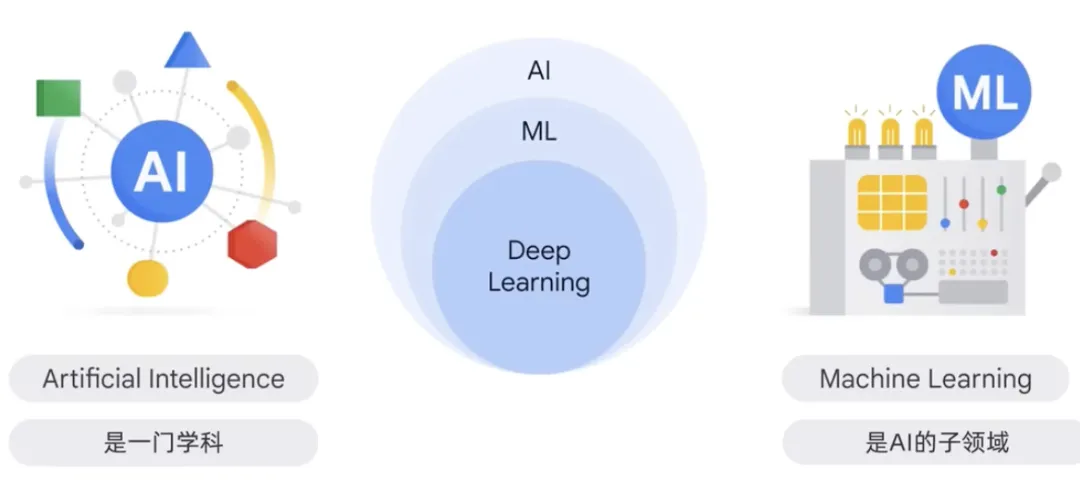
#人工知能は、インテリジェント エージェントの作成を研究するコンピューター サイエンスの一分野です。これらは、インテリジェント エージェントが自律的に推論、学習、行動できるシステムです。インテリジェントエージェントの研究は、自律的に推論し、学習し、行動できるシステムの研究です。
人工知能は、人間のように考えて行動する機械を構築する理論と方法に関係しています。この分野では、機械学習は人工知能の分野です。これは、入力データに基づいてモデルをトレーニングするプログラムまたはシステムです。トレーニングされたモデルは、モデルがトレーニングされた統合データから導き出される、新しいデータまたは未確認のデータから有用な予測を行うことができます。独自のトレーニング モデルからの統合データに基づいてモデルをトレーニングすることにより、このデータをモデルがまだ認識していないデータを予測するために使用できます。このデータは、モデル自体のトレーニングに使用される統合データから取得されており、有用な予測を行うことができます。この手法は、画像、音声認識、自然言語処理などの分野の問題で広く使用されています。
機械学習により、コンピューターは明示的にプログラムされずに学習できるようになります。機械学習モデルの最も一般的な 2 つのタイプは、教師なし学習モデルと教師あり ML モデルです。 2 つの主な違いは、教師ありモデルの場合はラベルがあり、ラベル付きデータは名前、タイプ、番号などのラベルが付いたデータであり、教師なしデータはラベルのないデータであることです。
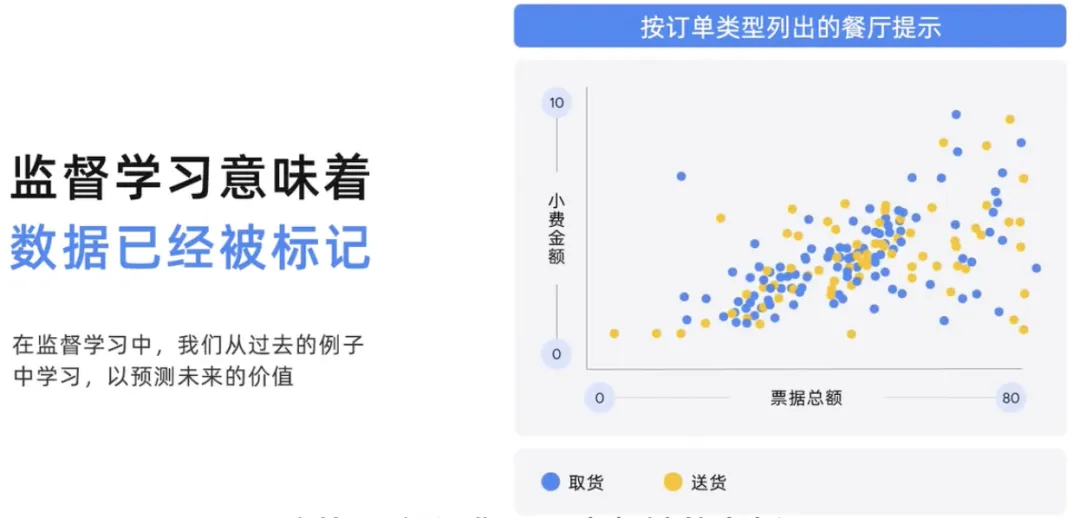
あなたがレストランのオーナーで、請求額、注文の種類に基づいてさまざまな人々が与えたチップの量、注文の種類に応じてチップの金額が異なっていたことに関する履歴データがあるとします。集荷か配達の人でした。教師あり学習では、モデルは過去のデータから学習し、将来の価値を予測します。したがって、このモデルでは、注文の種類に応じて、合計請求金額を使用して、今後の購入がピックアップか配達か、およびチップの金額を予測します。過去のモデルに基づく予測により、今後の消費量を正確に予測できることが期待されます。したがって、ここでのモデルでは、合計請求金額を使用して、注文タイプに基づいて将来の支出とチップを予測します。
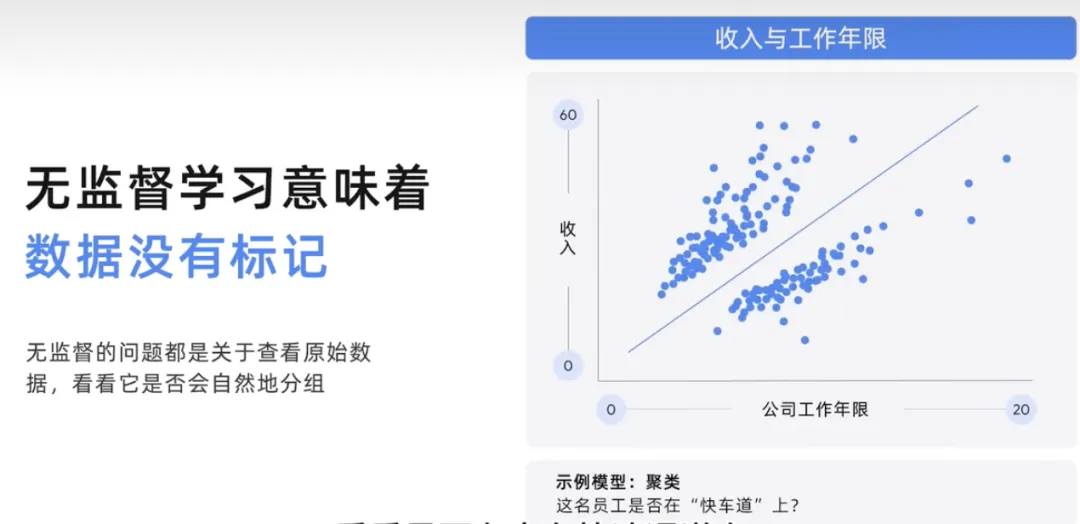
上記の概念は、生成 AI を理解するための基礎です。

予測されたテスト データ値と実際のトレーニング データ値が大きく離れている場合、それはエラーと呼ばれ、モデルは予測値と実際の値が一致するまでこの誤差を削減しようとします。より近いです。
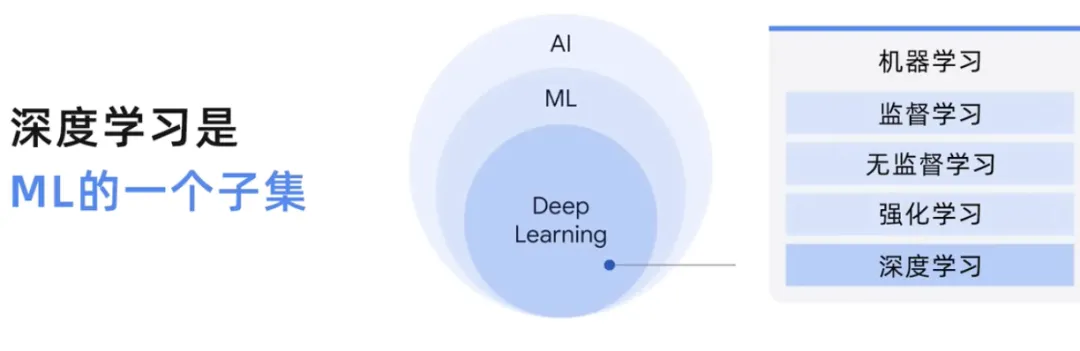
機械学習はさまざまな技術を含む幅広い分野ですが、ディープラーニングは人工ニューラル ネットワークを使用する機械学習の一種であり、機械学習よりも複雑なパターンを処理できます。
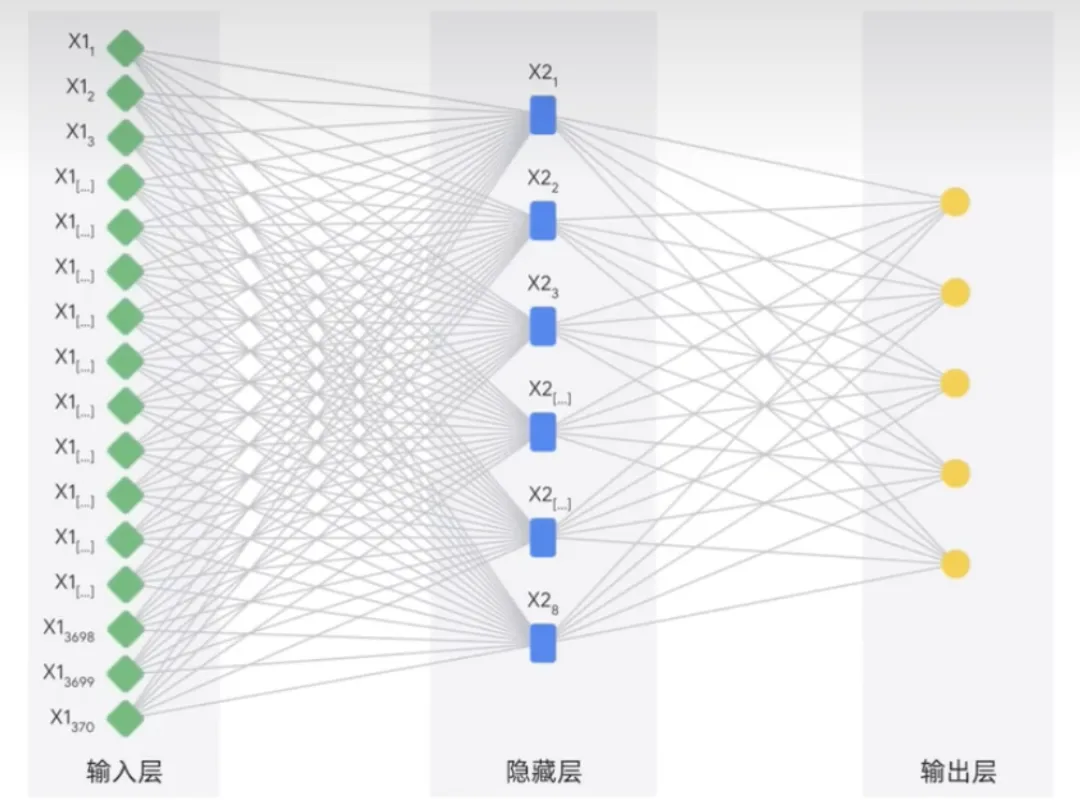 #人工ニューラル ネットワークは人間の脳からインスピレーションを得たもので、相互接続された多くのノードまたはニューロンで構成されており、データを処理することでタスクの実行方法を学習できます。そして予測を立てます。
#人工ニューラル ネットワークは人間の脳からインスピレーションを得たもので、相互接続された多くのノードまたはニューロンで構成されており、データを処理することでタスクの実行方法を学習できます。そして予測を立てます。
深層学習モデルには通常、複数のニューロン層があります。これにより、従来の機械学習モデルよりも複雑なパターンを学習できるようになります。ニューラル ネットワークは、ラベル付きデータとラベルなしデータの両方を処理できます。これは、半教師あり学習と呼ばれます。半教師あり学習では、少量のラベル付きデータと大量のラベルなしデータでニューラル ネットワークがトレーニングされます。ラベル付きデータは、ニューラル ネットワークがタスクの基本概念を学習するのに役立ちます。また、ラベルのないデータは、ニューラル ネットワークを新しい例に一般化するのに役立ちます。
この人工知能分野における位置づけ、つまり人工ニューラル ネットワークを使用すると、ラベル付きデータとラベルなしデータを教師あり、教師なし、半教師ありの方法で処理できます。大規模な言語モデルは、深層学習、深層学習モデル、または機械学習モデル一般のサブセットでもあります。
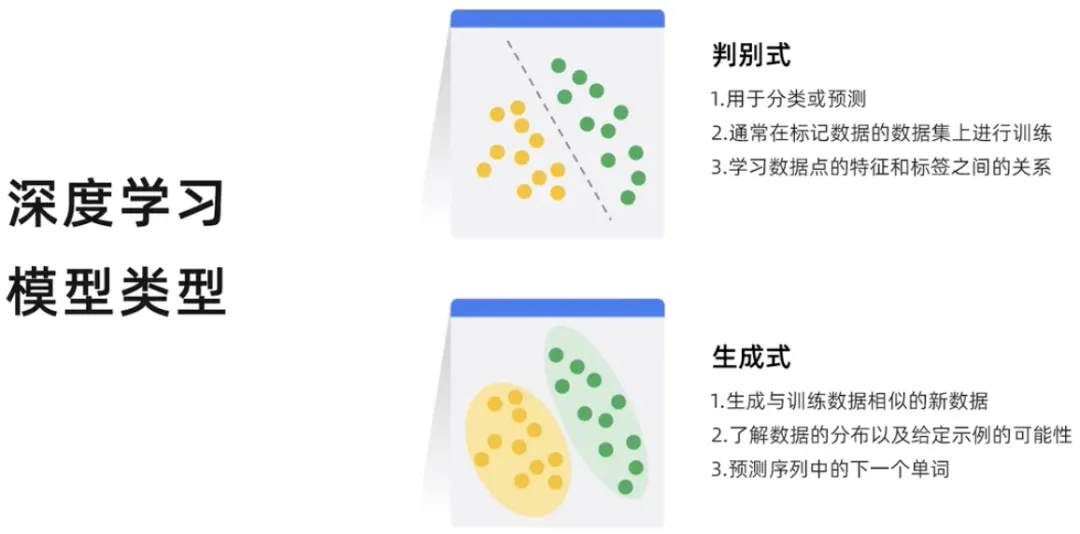
# ディープラーニングは、識別型と生成型の 2 つのタイプに分類できます。識別モデルは、データ ポイントのラベルを分類または予測するために使用されるモデルです。識別モデルは通常、ラベル付けされたデータ ポイントのデータセットでトレーニングされます。データ ポイントの特徴とラベルの間の関係を学習し、識別モデルがトレーニングされると、それを使用して新しいデータ ポイントのラベルを予測できます。生成モデルは、学習された既存データの確率分布に基づいて新しいデータ インスタンスを生成するため、生成モデルは新しいコンテンツを生成します。
生成モデルは新しいデータ インスタンスを出力でき、識別モデルはさまざまなタイプのデータ インスタンスを区別できます。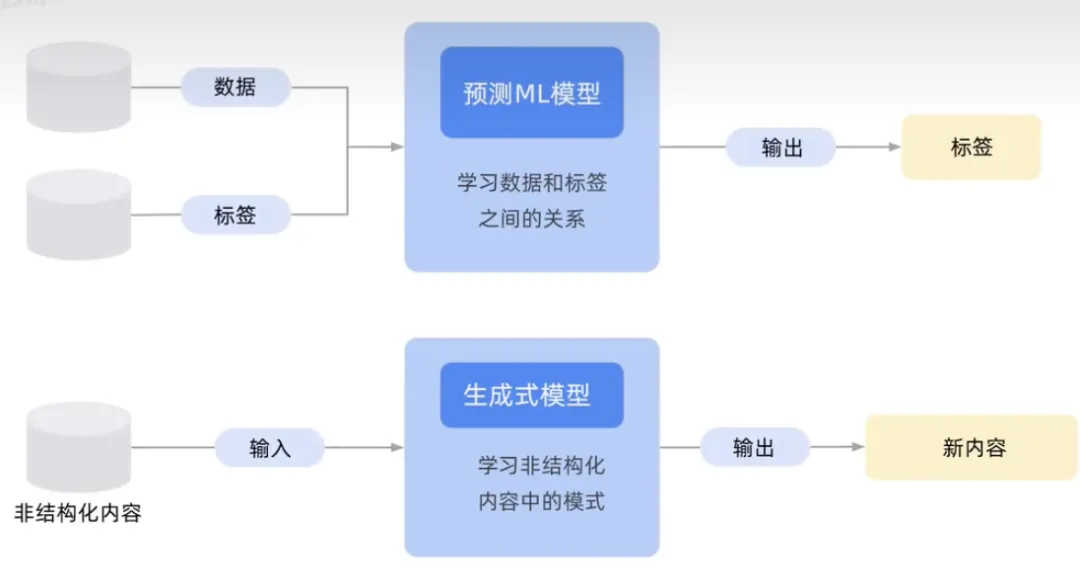
出力される外部ラベルが数値または確率である場合、それはスパムや非スパムなどの非生成 AI です。出力が自然言語の場合、音声、テキスト、画像、ビデオなどの生成 AI になります。
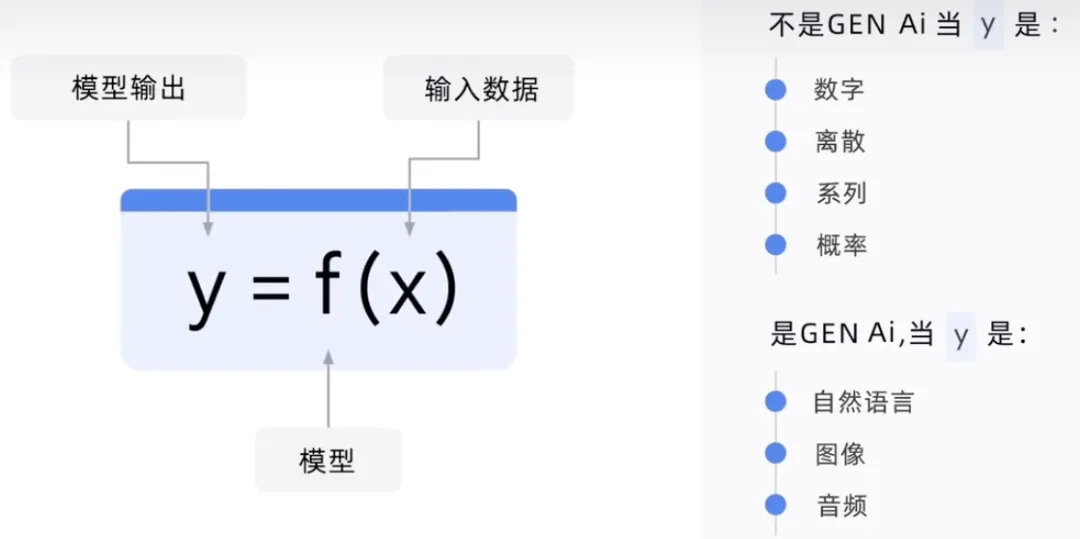
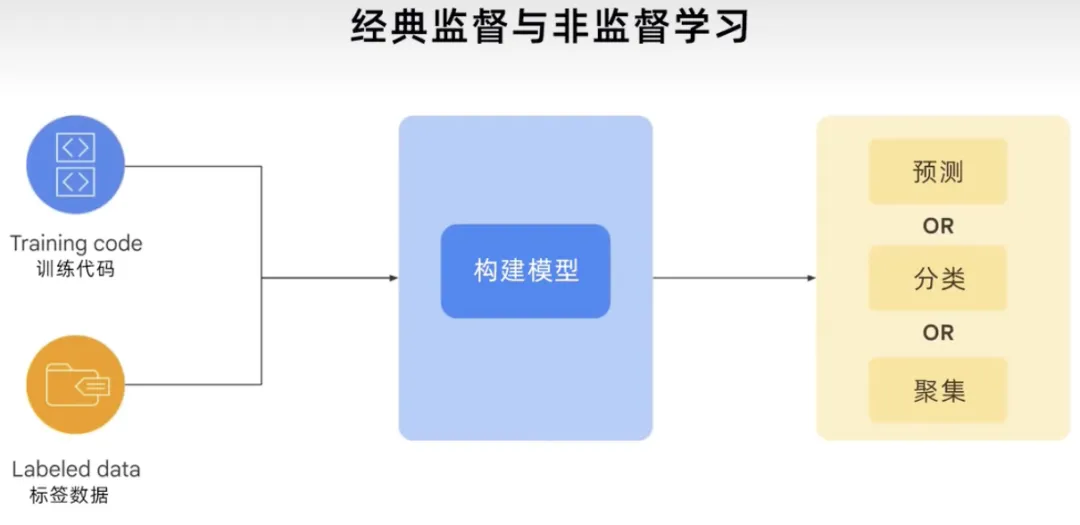
要約すると、従来の教師ありおよび教師なし学習プロセスでは、トレーニング コードとラベル付きデータを使用してモデルを構築します。ユースケースや問題に応じて、モデルは予測を提供したり、何かを分類またはクラスター化したり、この力を使用してモデルを生成したプロセスがどれほど堅牢であるかを示すことができます。
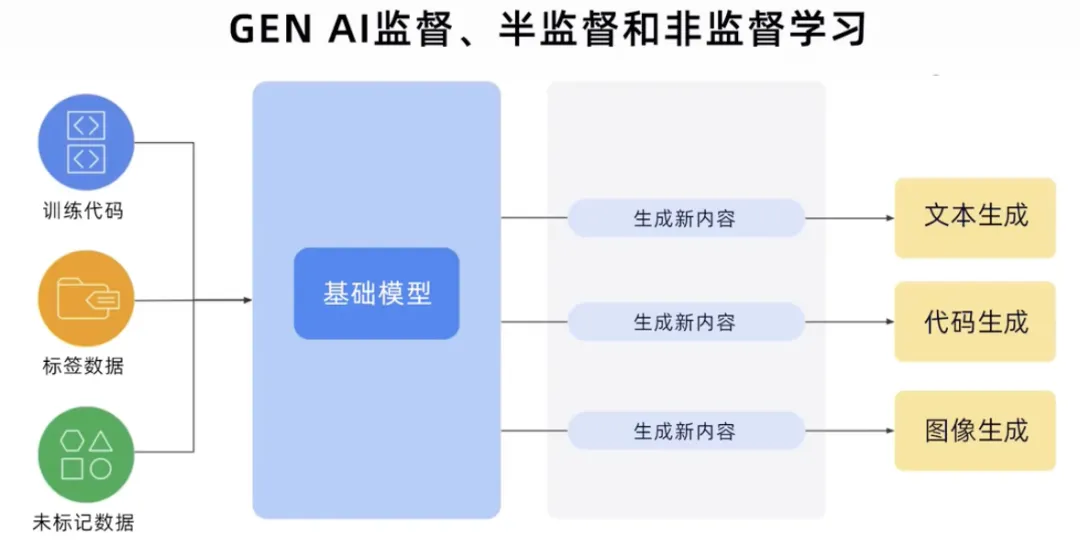
 #GenAI プロセスは、トレーニング コード、すべてのデータ型のラベル付きデータおよびラベルなしデータを取得し、基本モデルを構築できます。新しいコンテンツを生成します。テキスト、コード、画像、オーディオ、ビデオなど。
#GenAI プロセスは、トレーニング コード、すべてのデータ型のラベル付きデータおよびラベルなしデータを取得し、基本モデルを構築できます。新しいコンテンツを生成します。テキスト、コード、画像、オーディオ、ビデオなど。
 従来のプログラミングからニューラル ネットワーク、生成モデルに至るまで、私たちは長い道のりを歩んできました。従来のプログラミングでは、猫を区別するためのルールをコーディングする必要がありました。種類は動物で、足が4本、耳が2つ、毛皮などが生えています。
従来のプログラミングからニューラル ネットワーク、生成モデルに至るまで、私たちは長い道のりを歩んできました。従来のプログラミングでは、猫を区別するためのルールをコーディングする必要がありました。種類は動物で、足が4本、耳が2つ、毛皮などが生えています。
ニューラル ネットワークの波の中で、私たちは猫や犬の写真をネットワークに与えることができます。そしてそれは猫ですかと尋ねました。彼は猫を予言するだろう。生成型 AI の波では、ユーザーとして私たちは独自のコンテンツを生成できます。
 Python 言語モデルや会話型アプリケーション言語モデル、その他のモデルなど、テキスト、画像、オーディオ、ビデオなど。インターネット上の複数のソースから非常に大きなデータを取得します。質問するだけで使用できる基本的な言語モデルを構築します。ですから、猫とは何かと尋ねると、彼は猫について知っていることをすべて教えてくれます。
Python 言語モデルや会話型アプリケーション言語モデル、その他のモデルなど、テキスト、画像、オーディオ、ビデオなど。インターネット上の複数のソースから非常に大きなデータを取得します。質問するだけで使用できる基本的な言語モデルを構築します。ですから、猫とは何かと尋ねると、彼は猫について知っていることをすべて教えてくれます。
GenAI 生成 AI は、既存のコンテンツから学習した知識に基づいて新しいコンテンツを作成する人工知能テクノロジーです。既存のコンテンツから学習するプロセスはトレーニングと呼ばれます。また、プロンプトが与えられたときに統計モデルを作成し、そのモデルを使用して予想される応答を予測し、新しいコンテンツを生成します。
基本的に、データの基礎となる構造コンテンツを学習し、トレーニング データに似た新しいサンプルを生成できます。前に述べたように、生成言語モデルは、示された例から学んだことを取得し、その情報に基づいてまったく新しいものを作成できます。
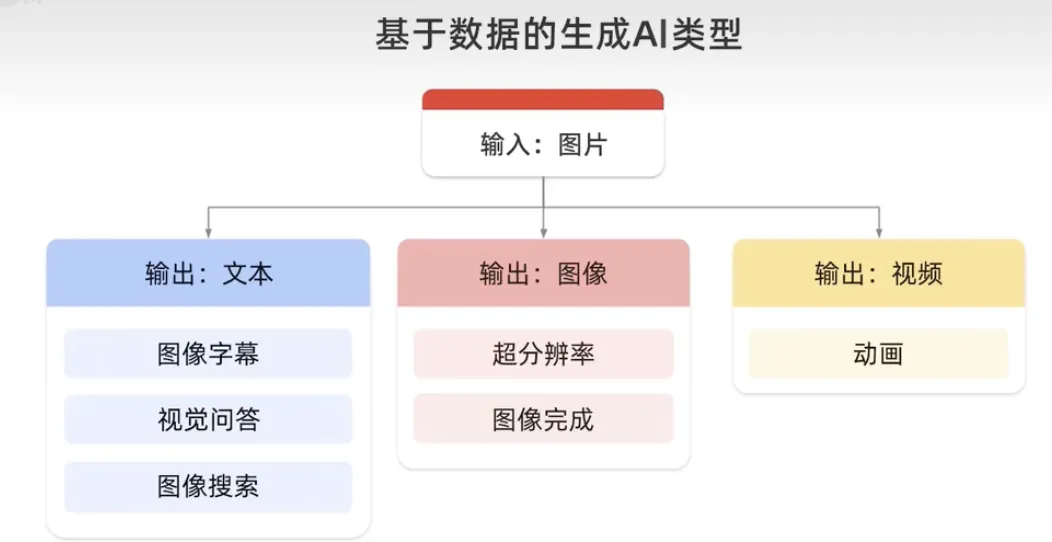
大規模言語モデルは、自然に聞こえる言語の形式でテキストの新しい組み合わせを生成し、画像モデルを生成し、画像を入力として受け取り、テキストや別の画像を出力できるため、生成型人工知能の一種です。またはビデオ。たとえば、「出力テキスト」では視覚的な Q&A を取得でき、「出力画像」ではイメージ補完を生成し、「出力ビデオ」ではアニメーションを生成します。
テキストを入力として受け取り、さらに多くのテキスト、画像、音声、または意思決定を出力できる言語モデルを生成します。たとえば、出力テキストの下に質問と回答を生成し、出力画像の下にビデオを生成します。

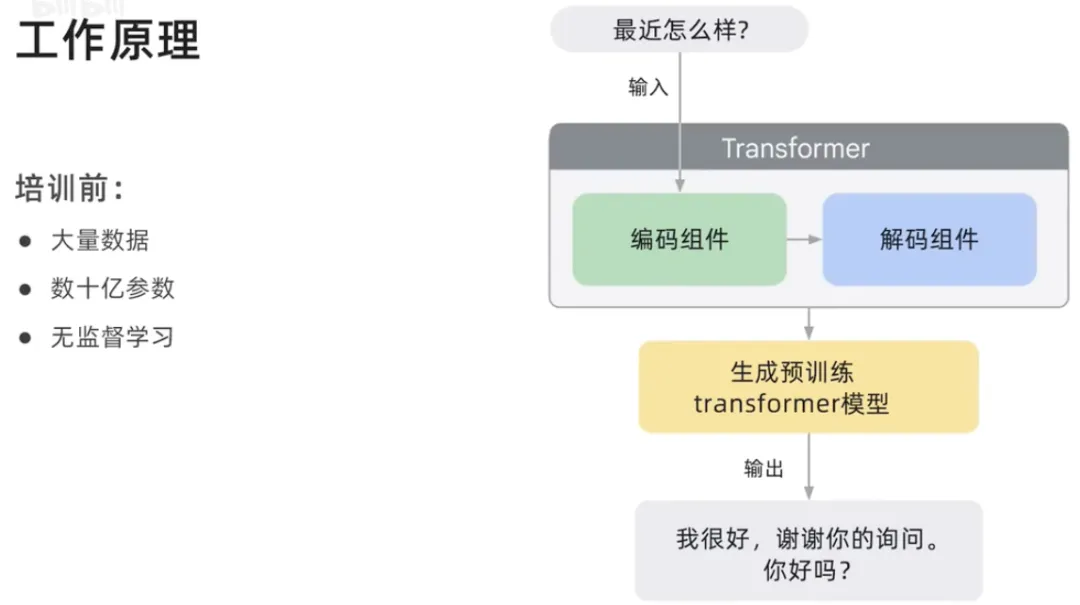
#生成言語モデルはトレーニング データを通じてパターンと言語について学習し、テキストが与えられると、次に何が起こるかを予測すると述べました。何。
生成言語モデルはパターン マッチング システムであり、提供されたデータに基づいてパターンを学習します。トレーニング データから学んだことに基づいて、文を完成させる方法の予測を提供します。大量のテキスト データでトレーニングされ、さまざまなプロンプトや質問に応じて通信し、人間のようなテキストを生成することができました。
#Transformer では、Hallucin はモデルによって生成された単語またはフレーズであり、通常は意味がないか、文法的に間違っています。幻覚は、モデルが十分なデータでトレーニングされていない、モデルがノイズの多いデータや汚いデータでトレーニングされている、モデルに十分なコンテキストが与えられていない、モデルに十分な制約が与えられていないなど、さまざまな要因によって引き起こされる可能性があります。

また、モデルが誤った情報や誤解を招く情報を生成する可能性も高くなります。たとえば、さまざまな TPT3.5 などの情報が生成される可能性があります。必ずしも正しいとは限りません。プロンプトワードは、大規模な言語モデルへの入力として与えられる小さなテキストです。また、これを使用して、さまざまな方法でモデルの出力を制御できます。
ヒント設計は、大規模な言語モデルから目的の出力コンテンツを生成するヒントを作成するプロセスです。前に述べたように、LLM は入力されたトレーニング データに大きく依存します。入力データのパターンと構造を分析することで学習します。ただし、ブラウザベースのプロンプトにアクセスすることで、ユーザーは独自のコンテンツを生成できます。

データベースの入力タイプのロードマップを示しました。関連するモデル タイプは次のとおりです。
テキストツーテキスト モデル。自然言語入力を受け取り、テキスト出力を生成します。これらのモデルは、テキスト間のマッピングを学習するようにトレーニングされています。たとえば、ある言語から別の言語への翻訳です。
#テキストから画像へのモデル。テキストから画像へのモデルは多数の画像でトレーニングされるためです。各画像には短いテキストの説明が付いています。拡散はこれを達成するために使用される 1 つの方法です。

#テキストをタスク モデルに送信します。トレーニングが完了すると、テキスト入力に基づいて定義されたタスクやアクションを実行できるようになります。このタスクは広範囲にわたる場合があります。たとえば、質問に答える、検索を実行する、予測を行う、または何らかのアクションを実行するなど、テキストからタスクへのモデルをトレーニングして、クエリをガイドしたり、ドキュメントに変更を加えたりすることもできます。
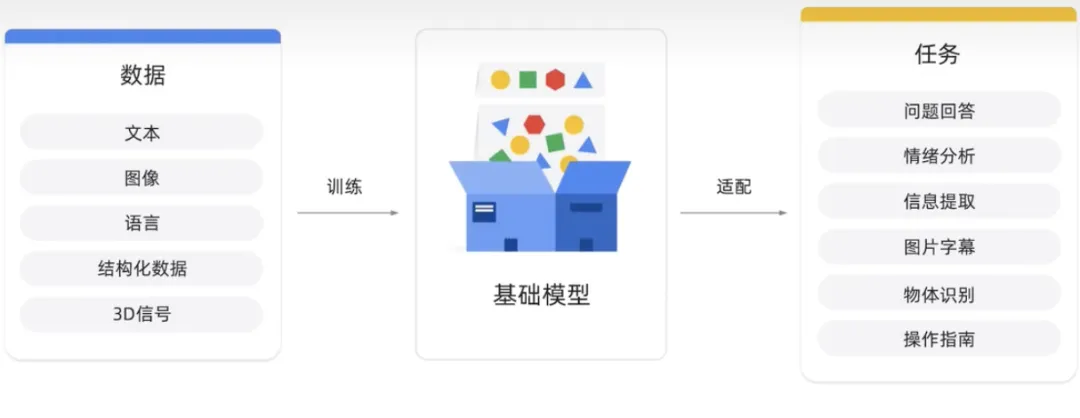 基本モデルは、大量のデータで事前トレーニングされた大規模な AI モデルです。目的は、感情分析、画像、キャプション、オブジェクト認識などのさまざまな下流タスクを適応または微調整することです。
基本モデルは、大量のデータで事前トレーニングされた大規模な AI モデルです。目的は、感情分析、画像、キャプション、オブジェクト認識などのさまざまな下流タスクを適応または微調整することです。
基本モデルは、医療、金融、顧客サービスなどの多くの業界に革命を起こす可能性があり、予測を検出し、個別の顧客サポートを提供するために使用できます。 OpenAI は、チャットやテキスト用のソース言語を含む、基本的なモデル ソース言語を提供します。

Visual Basic モデルには安定した拡散が含まれており、テキストの説明からパッケージ品質の画像を効果的に生成できます。顧客が製品やサービスについてどう感じているかに関する情報を収集する必要がある場合があるとします。

開発者の観点から見ると、Generative AI Studio を使用すると、コードを書かずにアプリケーションを簡単に設計および構築できます。アプリケーションコンテンツを簡単に作成および編集できるビジュアルエディターを備えています。ユーザーがアプリ内の情報を検索できる組み込みの検索エンジンもあります。
ユーザーが自然言語を使用してアプリケーションと対話できるようにする会話型人工知能エンジンもあります。独自のデジタル アシスタント、カスタム検索エンジン、ナレッジ ベース、トレーニング アプリなどを作成できます。

# モデル デプロイ ツールは、開発者がさまざまなデプロイ オプションを使用して実稼働環境にモデルをデプロイするのに役立ちます。また、モデル監視ツールは、開発者がダッシュボードやさまざまなメトリクスを使用して実稼働環境での ML モデルのパフォーマンスを監視するのに役立ちます。
生成的 AI アプリケーション開発を複雑なパズルの組み立てとみなすと、データ サイエンス、機械学習、プログラミングなどの必要な技術的能力がそれぞれパズルのピースに相当します。 。
技術的な蓄積のない企業がこれらのパズルのピースを理解することはすでに困難であり、それらを組み立てるのはさらに困難な作業になります。しかし、技術力が弱いこれらの伝統的な企業に、あらかじめ組み立てられたパズルのピースを提供できるサービスがあれば、これらの伝統的な企業はパズル全体をより簡単かつ迅速に完成させることができます。
国内市場の実際の状況から判断すると、生成 AI の開発は、トレンドを追いかけている実務者が期待するほど楽観的でもありませんし、否定論者が言うほど悲観的でもありません。
エンタープライズ ユーザーは、アプリケーションの堅牢性、経済性、セキュリティ、使いやすさを追求します。これは、大規模な言語モデルなどの生成 AI がトレーニングに高い計算能力コストを費やすことを躊躇しないという事実と一致しています。より高い機能を実現するためのプロセス、まったく異なるパス。 この背後にある中心的な問題は、より大きな想像力を備えたエンタープライズレベルの生成 AI の分野で最も重要なことは、大規模モデルがどれほど強力であるかではなく、基本モデルからさまざまなモデルにどのように進化できるかであるということです。特定の分野での応用を可能にし、それによって経済と社会全体の発展を促進します。以上が生成AIとは何ですか?どのような機能タイプがあるかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。