
ホームページ >テクノロジー周辺機器 >AI >GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-03 17:40:091246ブラウズ
グループ化されたクエリ アテンションは、大規模な言語モデルにおけるマルチクエリ アテンション手法であり、その目標は、MQA の速度を維持しながら MHA の品質を達成することです。グループ化されたクエリ アテンションは、各グループ内のクエリが同じアテンションの重みを共有するようにクエリをグループ化します。これにより、計算の複雑さが軽減され、推論速度が向上します。
この記事では、GQA の考え方とそれをコードに変換する方法について説明します。
GQA は、「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」という論文で提案されています。これは非常にシンプルでクリーンなアイデアであり、マルチヘッドに基づいて構築されています。注意、強度以上です。
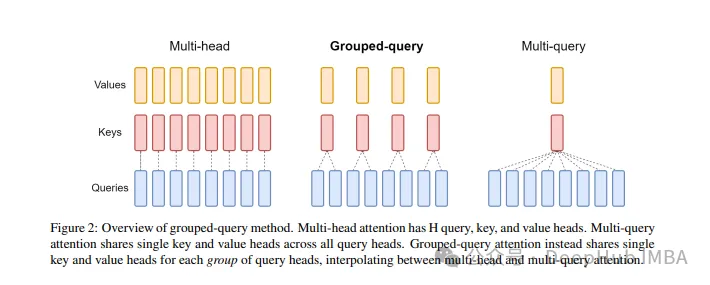
GQA
標準のマルチヘッド アテンション レイヤー (MHA) は、H クエリ ヘッドで構成されます。キーヘッドと値ヘッダーの構成。各ヘッドの寸法はDです。 Pytorch コードは次のとおりです。
from torch.nn.functional import scaled_dot_product_attention # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 8, 64) value = torch.randn(1, 256, 8, 64) output = scaled_dot_product_attention(query, key, value) print(output.shape) # torch.Size([1, 256, 8, 64])
クエリ ヘッダーごとに、対応するキーがあります。このプロセスを次の図に示します。
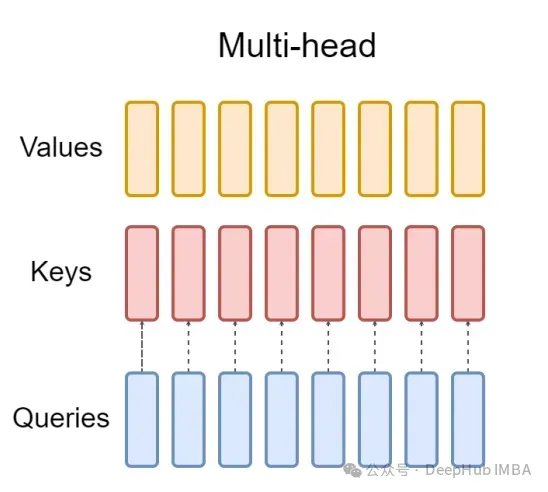
そして、GQA はクエリ ヘッダーを G 個のグループに分割し、各グループがキーと値を共有します。
視覚的な表現を使用すると、上で述べたように、GQA の動作原理を明確に理解できます。 GQA は非常にシンプルでクリーンなアイデアです。
Pytorch コードの実装
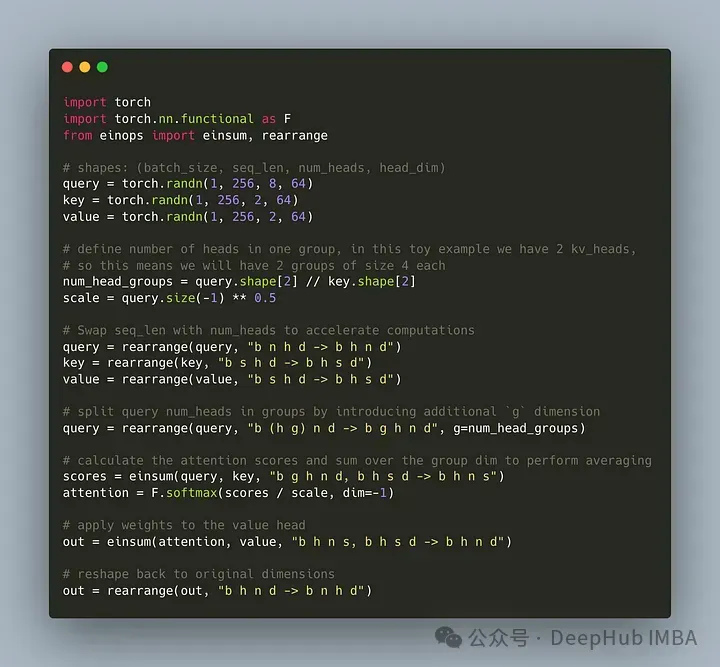
クエリ ヘッダーを G 個のグループに分割し、各グループが key と value を共有するコードを作成しましょう。 einops ライブラリを使用すると、テンソルに対して複雑な演算を効率的に実行できます。
まず、クエリ、キー、値を定義します。次に、アテンション ヘッドの数を設定します。この数は任意ですが、num_heads_for_query % num_heads_for_key = 0、つまり割り切れる必要があることを確認する必要があります。私たちの定義は次のとおりです:
import torch # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 2, 64) value = torch.randn(1, 256, 2, 64) num_head_groups = query.shape[2] // key.shape[2] print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
効率を向上させるために、seq_len 次元と num_heads 次元を交換するために、einops は次のように簡単に実行できます。
from einops import rearrange query = rearrange(query, "b n h d -> b h n d") key = rearrange(key, "b s h d -> b h s d") value = rearrange(value, "b s h d -> b h s d")次に、「グループ化」の概念をクエリ マトリックスに導入する必要があります。
from einops import rearrange query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups) print(query.shape) # torch.Size([1, 4, 2, 256, 64])上記のコードを使用して、2D を 2D に再形成します。定義したテンソルの場合、元の次元 8 (クエリ内のヘッドの数) は現在、 (キーと値のヘッドの数を一致させるため) 2 つのグループに分割し、各グループのサイズは 4 です。
最後で最も難しい部分は、注意スコアの計算です。しかし実際には、insum 演算を通じて 1 行で実行できます。
from einops import einsum, rearrange # g stands for the number of groups # h stands for the hidden dim # n and s are equal and stands for sequence length scores = einsum(query, key, "b g h n d, b h s d -> b h n s") print(scores.shape) # torch.Size([1, 2, 256, 256])スコア テンソルは、上記の値テンソルと同じ形状をしています。仕組みを見てみましょう
einsum は次の 2 つのことを行います:
1. クエリとキーの行列乗算。私たちの場合、これらのテンソルの形状は (1,4,2,256,64) と (1,2,256,64) であるため、最後の 2 次元に沿った行列の乗算は (1,4,2,256,256) になります。
2. 2 番目の次元 (次元 g) の要素を合計します - 指定された出力形状で次元が省略されている場合、einsum はこの作業を自動的に完了します。ヘッダー内のキーと値の数を一致させます。
最後に、分数と値の標準的な乗算に注目してください:
import torch.nn.functional as F scale = query.size(-1) ** 0.5 attention = F.softmax(similarity / scale, dim=-1) # here we do just a standard matrix multiplication out = einsum(attention, value, "b h n s, b h s d -> b h n d") # finally, just reshape back to the (batch_size, seq_len, num_kv_heads, hidden_dim) out = rearrange(out, "b h n d -> b n h d") print(out.shape) # torch.Size([1, 256, 2, 64])
最も単純な GQA 実装が完了しました。必要な Python コードは 16 行未満です。
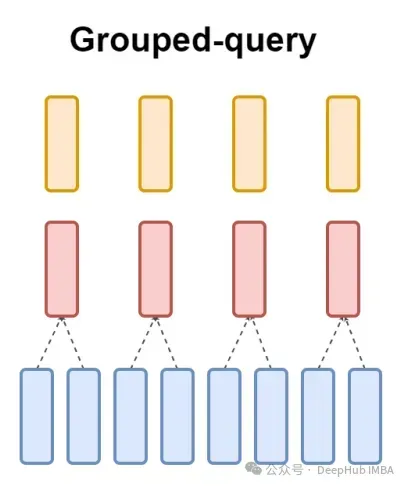
最後に、簡単に説明します。 MQA について一言: マルチプル クエリ アテンション (MQA) は、MHA を簡素化するもう 1 つの一般的な方法です。すべてのクエリは同じキーと値を共有します。概略図は次のとおりです。
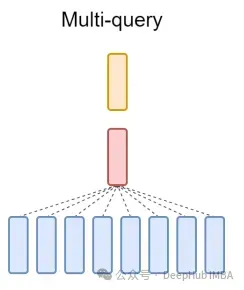
ご覧のとおり、MQA と MHA は両方とも GQA から派生できます。単一のキーと値を持つ GQA は MQA と同等ですが、ヘッダーの数と同じグループを持つ GQA は MHA と同等です。
GQA の利点は何ですか?
GQA は、最高のパフォーマンス (MQA) と最高のモデル品質 (MHA) の中間の 1 つです。良いトレードオフ。
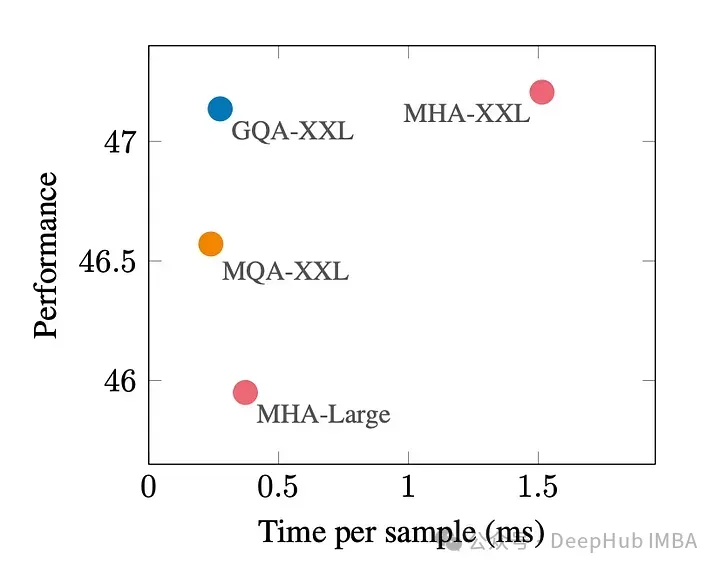
次の図は、GQA を使用すると、MHA とほぼ同じモデル品質が得られ、処理時間が 3 倍になり、MQA のパフォーマンスに達することがわかります。これは高負荷システムには不可欠である可能性があります。
pytorch には GQA の正式な実装はありません。そこで、より良い非公式の実装を見つけました。興味があれば、試してみてください:
https://www.php.cn/link/5b52e27a9d5bf294f5b593c4c071500e
GQA ペーパー:
以上がGQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。