



マルチモーダル文書理解能力 新しい SOTA!
Alibaba mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl 1.5 をリリースしました。これは、高解像度画像テキスト認識、一般的な文書構造の理解、および指示遵守、外部知識導入の一連のソリューション。
早速、まず効果を見てみましょう。
ワンクリックで複雑な構造のチャートを認識し、マークダウン形式に変換:

さまざまなスタイルのチャートが利用可能:

より詳細なテキストの認識と位置決めも簡単に実行できます:

文書を理解するための詳細な説明も提供できます:

「文書の理解」は現在、大規模な言語モデルの実装にとって重要なシナリオであることを知っておく必要があります。市場には文書の読み取りを支援する多くの製品があり、主に OCR システムを使用して文書を読み取る製品もあります。テキスト認識機能を備え、LLM と連携してテキスト認識を行うことで、優れた文書理解能力を実現します。
しかし、ドキュメント画像、リッチテキスト、複雑なレイアウトのカテゴリは多様であるため、グラフ、インフォグラフィック、Web ページなどの複雑な構造を持つ画像を普遍的に理解することは困難です。
現在人気のあるマルチモーダル大規模モデル QwenVL-Max、Gemini、Claude3、GPT4V はいずれも強力な文書画像理解機能を備えていますが、オープンソース モデルはこの方向での進歩が遅れています。
Alibaba の新しい調査では、mPLUG-DocOwl 1.5 が 10 の文書理解ベンチマークで SOTA を獲得し、5 つのデータセットで 10 ポイント以上向上し、一部のデータセットで Wisdom の 173 億 CogAgent を上回りました。 。

DocOwl 1.5-Chat は、ベースラインでの単純な質問に答える機能に加えて、少量の「詳細な質問」を使用してデータを微調整する機能も備えています。 「説明」 (推論) マルチモーダル文書の分野で詳細に説明できる能力は、大きな応用可能性を秘めています。
アリババの mPLUG チームは、2023 年 7 月にマルチモーダル文書理解の研究への投資を開始し、mPLUG-DocOwl、UReader、mPLUG-PaperOwl、mPLUG-DocOwl 1.5 を連続リリースし、一連の大規模文書をオープンソース化しました。モデルとトレーニング データを理解する。
この記事は、最新作 mPLUG-DocOwl 1.5 から始まり、「マルチモーダル文書理解」の分野における主要な課題と効果的な解決策を分析します。
課題 1: 高解像度の画像テキスト認識
文書画像は通常の画像とは異なり、A4 サイズの文書画像や短い表や幅広の表など、形状やサイズが多様であることが特徴です。写真、携帯電話のウェブページの細長いスクリーンショット、何気なく撮影した風景写真など、解像度の分布は非常に広いです。
主流のマルチモーダル大規模モデルが画像をエンコードする場合、画像サイズを直接スケーリングすることがよくあります。たとえば、mPLUG-Owl2 と QwenVL は 448x448 にスケーリングし、LLaVA 1.5 は 336x336 にスケーリングします。
文書画像を単純に拡大縮小すると、画像内のテキストがぼやけて変形し、読めなくなります。
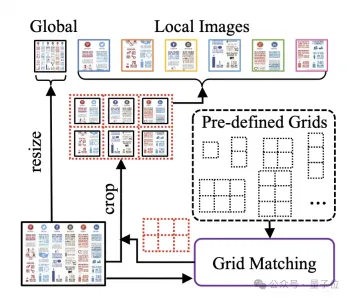
文書画像を処理するために、mPLUG-DocOwl 1.5 は前処理 UReader の cutting メソッドを続行します。モデル構造は図 1 に示されています:

△図 1: DocOwl 1.5 モデル構造図
UReader は既存のマルチモーダル大規模モデルに基づいて最初に提案され、パラメータなしで形状切断モジュールを適応させました(形状適応型)トリミング モジュール) 一連のサブピクチャを取得し、各サブピクチャは低解像度エンコーダを通じてエンコードされ、最後にサブピクチャの直接のセマンティクスが言語モデルを通じて関連付けられます。
このグラフカッティング戦略は、既存の汎用ビジュアルエンコーダ (CLIP ViT-14/L など) の能力を最大限に活用して文書を理解することができ、 コストを大幅に削減します。高解像度レート ビジュアル エンコーダのコスト を再トレーニングする必要があります。形状に適応した切断モジュールを図 2 に示します。
△図 2: 形状適応型切断モジュール。
課題 2: 一般的な文書構造の理解
OCR システムに依存しない文書理解には、テキスト認識が基本的な能力であり、文書の意味的理解と構造的理解を達成することが非常に重要です。表の内容を理解するには、表のヘッダーと行と列の対応を理解する必要があり、グラフを理解するには、折れ線グラフ、棒グラフ、円グラフなどの多様な構造を理解する必要があります。契約書では、日付署名などのさまざまなキーと値のペアを理解する必要があります。
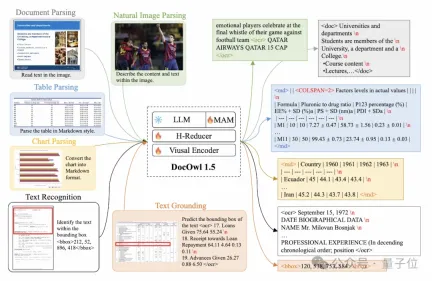
mPLUG-DocOwl 1.5 は、一般文書およびその他の構造理解機能の解決に重点を置いており、モデル構造の最適化とトレーニング タスクの強化を通じて、大幅に強化された一般文書理解機能を実現しました。
構造的には、図 1 に示すように、mPLUG-DocOwl 1.5 は、mPLUG-Owl/mPLUG-Owl2 の Abstractor のビジュアル言語接続モジュールを放棄し、 は「畳み込み全結合層」に基づく H を採用しています。 " -Reducer は、特徴の集約と特徴の位置合わせを実行します。
学習可能なクエリに基づく Abstractor と比較して、H-Reducer は視覚的特徴間の相対的な位置関係を保持し、文書構造情報を言語モデルに適切に転送します。
視覚シーケンスの長さを保持する MLP と比較して、H-Reducer は畳み込みを通じて視覚特徴の数を大幅に削減し、LLM が高解像度のドキュメント画像をより効率的に理解できるようにします。
ほとんどのドキュメント画像のテキストは最初に水平方向に配置され、水平方向のテキストのセマンティクスが一貫していることを考慮して、H-Reducer では畳み込み形状と 1x4 のステップ サイズが使用されます。論文では、著者は構造理解においてH-Reducerの優位性と、1x4がより一般的な骨材形状であることを十分な比較実験により証明しました。
トレーニング タスクに関しては、mPLUG-DocOwl 1.5 は、図 3 に示すように、あらゆるタイプの画像に対して統一構造学習 (統一構造学習) タスクを設計します。
△図 3: 統合構造学習
統合構造学習には、グローバルな画像テキスト分析だけでなく、多粒度のテキスト認識と位置決めも含まれています。
グローバル画像テキスト解析タスクでは、ドキュメント画像と Web ページ画像の場合、スペースと改行を使用してテキストの構造を表すことが最も一般的です。表の場合、著者は、以下に基づいて複数行の表現を導入します。マークダウン構文。複数の列の特殊文字は、テーブル表現の単純さと汎用性を考慮しています。グラフの場合、グラフが表形式のデータを視覚的に表現したものであることを考慮して、著者はグラフの分析対象としてマークダウン形式のテーブルも使用します。自然図、意味記述、シーンテキストも同様に重要であるため、シーンテキストをつなぎ合わせた画像記述の形式が分析対象として使用されます。
「テキストの認識と配置」タスクでは、文書画像の理解をより適切に行うために、作成者は、単語、語句、行、ブロックの 4 つの粒度でテキストの認識と配置を設計しました。離散化された整数を使用します。数値表現、範囲は 0 ~ 999 です。
統一構造学習をサポートするために、著者は文書/Web ページ、表、グラフ、自然画像などのさまざまな種類の画像をカバーする包括的なトレーニング セット DocStruct4M を構築しました。
統合構造学習の後、DocOwl 1.5 は、複数のフィールドの文書画像を構造的に分析し、テキストを配置する機能を備えています。

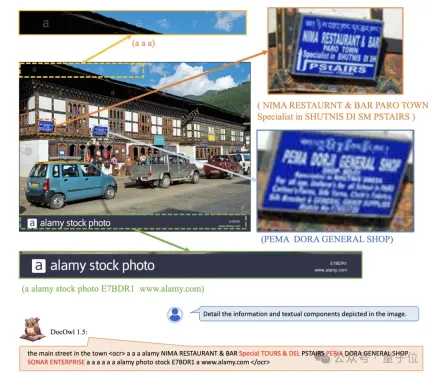
(指示に従う) モデルが基本的な文書理解機能に基づいており、情報抽出、質問と回答、画像の説明など、ユーザーの指示に従ってさまざまなタスクを実行する必要があります。
mPLUG-DocOwl の実践を継続し、DocOwl 1.5 は複数の下流タスクをコマンドの質問と回答の形式に統合し、統合構造学習後、マルチタスク共同トレーニングを通じて文書を取得しますドメインジェネラルモデル(ジェネラリスト)。
さらに、モデルに詳細を説明できるようにするために、mPLUG-DocOwl は共同トレーニング用のデータを微調整するためのプレーン テキスト命令を導入しようとしましたが、これには一定の効果がありますが、理想的ではありません。 。 DocOwl 1.5 では、作者は下流タスク(DocReason25K) の問題に基づいて、GPT3.5 および GPT4V を通じて少量の詳細な説明データを構築しました。
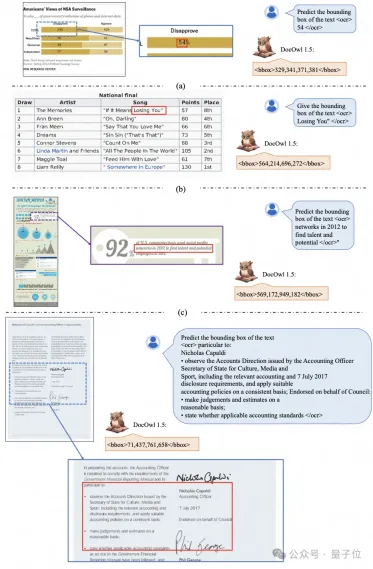
ドキュメントのダウンストリーム タスクとトレーニング用の DocReason25K を組み合わせることで、DocOwl 1.5-Chat はベンチマークでより良い結果を達成できます。
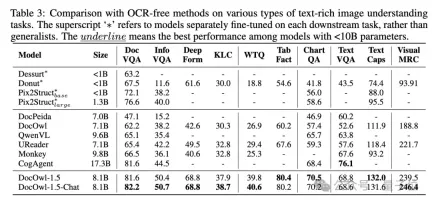
△図 6: ドキュメント理解ベンチマーク 評価
で詳細な説明を行うこともできます。

△図 7: 文書理解の詳細な説明
課題 4: 外部知識の導入
文書画像には情報が豊富に含まれているため、理解するには専門用語や特殊な分野でのその意味など、追加の知識が必要になることがよくあります。
mPLUG チームは、文書をよりよく理解するために外部の知識を導入する方法を研究するために、紙の分野から始めて、447,000 枚が関与する高品質の紙チャート分析データセット M-Paper を構築する mPLUG-PaperOwl を提案しました。高精細紙、チャート。
このデータは、外部の知識源として論文内のチャートのコンテキストを提供し、モデルがよりよく理解できるようにチャート分析の制御信号として「キーポイント」 (概要) を設計します。ユーザーの意図。
UReader に基づいて、著者は M-Paper 上で mPLUG-PaperOwl を微調整し、図 8 に示すように予備的な紙チャート分析機能を実証しました。
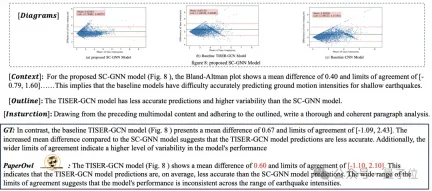
△図 8: ペーパー チャート分析
mPLUG-PaperOwl は、現時点では文書理解に外部知識を導入する最初の試みにすぎず、依然としてドメインの制限に直面しています。 , 単一の知識源などの問題はさらに解決する必要があります。
一般に、この記事は、最近リリースされた 7B の最も強力なマルチモーダル文書理解の大規模モデル mPLUG-DocOwl 1.5 から始まり、OCR に依存せずにマルチモーダル文書を理解するための 4 つの重要なポイントをまとめています。 (「高解像度画像テキスト認識」、「ユニバーサル文書構造理解」、「指示追従」、「外部知識導入」) および Alibaba mPLUG チームが提供するソリューション。
mPLUG-DocOwl 1.5 は、オープン ソース モデルの文書理解パフォーマンスを大幅に向上させましたが、テキスト認識、数学的計算の点で、クローズド ソースの大規模モデルと実際のニーズとの間には依然として大きなギャップがあります。 、自然シーンでの汎用など、まだまだ改善の余地があります。
mPLUG チームは、DocOwl のパフォーマンスをさらに最適化し、オープンソース化していきますので、引き続きご注目いただき、フレンドリーに議論していただければ幸いです。
GitHub リンク: https://github.com/X-PLUG/mPLUG-DocOwl
紙のリンク: https://arxiv.org/abs/2403.12895
以上がAlibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AM
Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AMオンデバイスAIの力を活用:個人的なチャットボットCLIの構築 最近では、個人的なAIアシスタントの概念はサイエンスフィクションのように見えました。 ハイテク愛好家のアレックスを想像して、賢くて地元のAI仲間を夢見ています。
 メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AM
メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AMAI4MHの最初の発売は2025年4月15日に開催され、有名な精神科医および神経科学者であるLuminary Dr. Tom Insel博士がキックオフスピーカーを務めました。 Insel博士は、メンタルヘルス研究とテクノでの彼の傑出した仕事で有名です
 2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM
2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM「私たちは、WNBAが、すべての人、プレイヤー、ファン、企業パートナーが安全であり、大切になり、力を与えられたスペースであることを保証したいと考えています」とエンゲルバートは述べ、女性のスポーツの最も有害な課題の1つになったものに取り組んでいます。 アノ
 Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM
Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM導入 Pythonは、特にデータサイエンスと生成AIにおいて、プログラミング言語として優れています。 大規模なデータセットを処理する場合、効率的なデータ操作(ストレージ、管理、アクセス)が重要です。 以前に数字とstをカバーしてきました
 Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM
Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM潜る前に、重要な注意事項:AIパフォーマンスは非決定論的であり、非常にユースケース固有です。簡単に言えば、走行距離は異なる場合があります。この(または他の)記事を最終的な単語として撮影しないでください。これらのモデルを独自のシナリオでテストしないでください
 AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM
AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM傑出したAI/MLポートフォリオの構築:初心者と専門家向けガイド 説得力のあるポートフォリオを作成することは、人工知能(AI)と機械学習(ML)で役割を確保するために重要です。 このガイドは、ポートフォリオを構築するためのアドバイスを提供します
 エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM
エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM結果?燃え尽き症候群、非効率性、および検出とアクションの間の隙間が拡大します。これは、サイバーセキュリティで働く人にとってはショックとしてはありません。 しかし、エージェントAIの約束は潜在的なターニングポイントとして浮上しています。この新しいクラス
 Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM
Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM即時の影響と長期パートナーシップ? 2週間前、Openaiは強力な短期オファーで前進し、2025年5月末までに米国およびカナダの大学生にChatGpt Plusに無料でアクセスできます。このツールにはGPT ‑ 4o、Aが含まれます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

