
ホームページ >テクノロジー周辺機器 >AI >大規模な言語モデルで一般的に使用される回転位置エンコーディング RoPE の詳細な説明: なぜ絶対位置エンコーディングや相対位置エンコーディングよりも優れているのですか?
大規模な言語モデルで一般的に使用される回転位置エンコーディング RoPE の詳細な説明: なぜ絶対位置エンコーディングや相対位置エンコーディングよりも優れているのですか?

- 王林転載
- 2024-04-01 20:19:01781ブラウズ
2017 年に発表された「attention is all you need」論文以来、Transformer アーキテクチャは自然言語処理 (NLP) 分野の基礎となってきました。その設計は長年にわたってほとんど変わっておらず、2022 年にはロータリー ポジション エンコーディング (RoPE) の導入によりこの分野で大きな発展が見られました。
回転位置埋め込みは、最も高度な NLP 位置埋め込みテクノロジです。 Llama、Llama2、PaLM、CodeGen などの最も一般的な大規模言語モデルはすでにこれを使用しています。この記事では、回転位置エンコーディングとは何か、また、回転位置エンコーディングが絶対位置エンコーディングと相対位置エンコーディングの利点をどのようにうまく融合させるのかについて詳しく説明します。
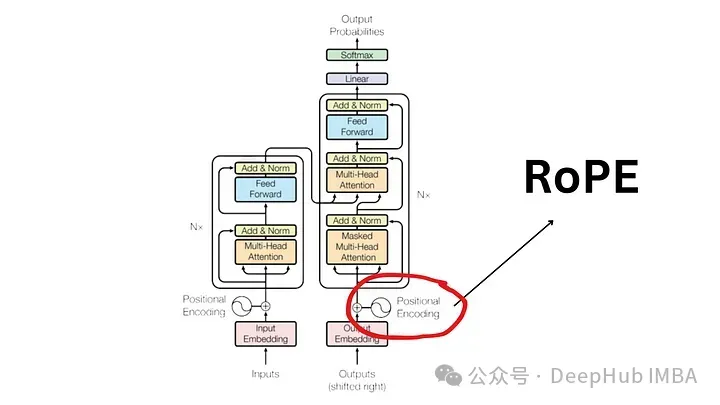
RoPE の重要性を理解するために、まず確認しましょう。位置エンコーディングが重要な理由 エンコーディングが重要です。 Transformer モデルは、その固有の設計により、入力トークンの順序を考慮しません。
たとえば、「犬が豚を追いかける」や「豚が犬を追いかける」などのフレーズは、意味は異なりますが、順序のないトークンのセットとして扱われるため、区別がつかないと見なされます。 シーケンス情報とその意味を維持するには、位置情報をモデルに統合するための表現が必要です。
絶対位置エンコード
文内の位置をエンコードするには、同じ次元のベクトルを使用する別のツールが必要です。各 A ベクトルは文内の位置を表します。たとえば、文内の 2 番目の単語に特定のベクトルを指定します。したがって、各文の位置には固有のベクトルがあります。次に、単語の埋め込みとそれらの対応する位置の埋め込みを組み合わせることによって、Transformer 層への入力が形成されます。
これらの埋め込みを生成するには、主に 2 つの方法があります:
- データから学習する:
- ここ 、位置ベクトルは、他のモデル パラメーターと同様に、トレーニング中に学習されます。位置ごとに一意のベクトルを学習します (例: 1 から 512)。これにより、シーケンスの最大長が制限されるという制限が生じます。モデルが位置 512 のみを学習する場合、その位置より長いシーケンスを表すことはできません。 サイン関数:
- この方法では、サイン関数を使用して各位置に一意の埋め込みを構築します。この構築の詳細は複雑ですが、基本的には配列内の各位置に一意の位置埋め込みが提供されます。実証研究により、データから正弦関数を学習して使用すると、現実世界のモデルで同等のパフォーマンスが得られることが示されています。 #絶対位置エンコーディングの制限
広く使用されていますが、絶対位置埋め込みには欠点がないわけではありません:
制限されたシーケンス長:
- 前述したように、モデルが特定の点の位置ベクトルを学習した場合、本質的にその制限を超える位置を表すことはできません。
- 位置埋め込みの独立性: 各位置埋め込みは、他の位置埋め込みから独立しています。これは、モデルの観点からは、位置 1 と 2 の差が位置 2 と 500 の差と同じであることを意味します。しかし実際には、位置 1 と位置 2 は、かなり離れている位置 500 よりも密接に関連しているはずです。この相対的な位置の欠如により、言語構造のニュアンスを理解するモデルの能力が妨げられる可能性があります。
- 相対位置エンコーディング
相対位置は、文内のメモの絶対位置ではなく、メモの位置に焦点を当てます。ノートペア間の関係、距離。この方法では、位置ベクトルを単語ベクトルに直接追加しません。代わりに、相対位置情報を組み込むようにアテンション メカニズムが変更されます。
T5 (Text-to-Text Transfer Transformer) は、相対位置埋め込みを利用するよく知られたモデルです。 T5 は、位置情報を処理する微妙な方法を導入しています:
位置オフセットのバイアス:
- T5 は、バイアス (浮動小数点数) を使用して、可能な各位置オフセットを表します。 。たとえば、バイアス B1 は、文内の絶対位置に関係なく、1 位置離れた 2 つのトークン間の相対距離を表す場合があります。
- セルフアテンション層での統合: この相対位置バイアス行列は、セルフアテンション層のクエリ行列とキー行列の積に追加されます。注目層。これにより、シーケンス内の位置に関係なく、同じ相対距離にあるマーカーが常に同じバイアスで表されることが保証されます。
- スケーラビリティ: このアプローチの大きな利点は、そのスケーラビリティです。これは任意の長さのシーケンスに拡張でき、絶対位置の埋め込みに比べて明らかな利点があります。
- 相対位置エンコーディングの制限
尽管它们在理论上很有吸引力,但相对位置编码得问题很严重
- 计算效率低下:必须创建成对的位置编码矩阵,然后执行大量张量操作以获得每个时间步的相对位置编码。特别是对于较长的序列。这主要是由于自注意力层中的额外计算步骤,其中位置矩阵被添加到查询键矩阵中。
- 键值缓存使用的复杂性:由于每个附加令牌都会改变每个其他令牌的嵌入,这使得 Transformer 中键值缓存的有效使用变得复杂。使用 KV 缓存的一项要求是已经生成的单词的位置编码, 在生成新单词时不改变(绝对位置编码提供)因此相对位置编码不适合推理,因为每个标记的嵌入会随着每个新时间步的变化而变化。
由于这些工程复杂性,位置编码未得到广泛采用,特别是在较大的语言模型中。
旋转位置编码 (RoPE)?
RoPE 代表了一种编码位置信息的新方法。传统方法中无论是绝对方法还是相对方法,都有其局限性。绝对位置编码为每个位置分配一个唯一的向量,虽然简单但不能很好地扩展并且无法有效捕获相对位置;相对位置编码关注标记之间的距离,增强模型对标记关系的理解,但使模型架构复杂化。
RoPE巧妙地结合了两者的优点。允许模型理解标记的绝对位置及其相对距离的方式对位置信息进行编码。这是通过旋转机制实现的,其中序列中的每个位置都由嵌入空间中的旋转表示。RoPE 的优雅之处在于其简单性和高效性,这使得模型能够更好地掌握语言语法和语义的细微差别。
旋转矩阵源自我们在高中学到的正弦和余弦的三角性质,使用二维矩阵应该足以获得旋转矩阵的理论,如下所示!
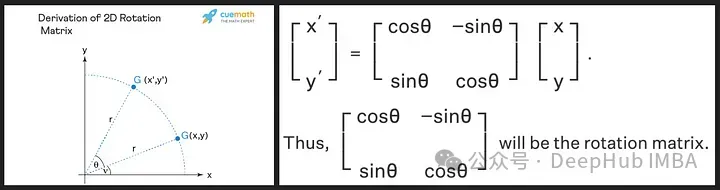
我们看到旋转矩阵保留了原始向量的大小(或长度),如上图中的“r”所示,唯一改变的是与x轴的角度。
RoPE 引入了一个新颖的概念。它不是添加位置向量,而是对词向量应用旋转。旋转角度 (θ) 与单词在句子中的位置成正比。第一个位置的向量旋转 θ,第二个位置的向量旋转 2θ,依此类推。这种方法有几个好处:
- 向量的稳定性:在句子末尾添加标记不会影响开头单词的向量,有利于高效缓存。
- 相对位置的保留:如果两个单词在不同的上下文中保持相同的相对距离,则它们的向量将旋转相同的量。这确保了角度以及这些向量之间的点积保持恒定
RoPE 的矩阵公式
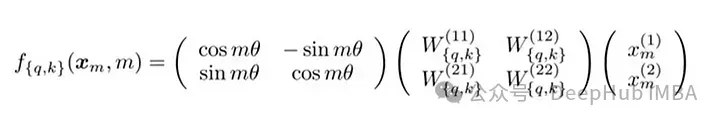
RoPE的技术实现涉及到旋转矩阵。在 2D 情况下,论文中的方程包含一个旋转矩阵,该旋转矩阵将向量旋转 Mθ 角度,其中 M 是句子中的绝对位置。这种旋转应用于 Transformer 自注意力机制中的查询向量和键向量。
对于更高维度,向量被分成 2D 块,并且每对独立旋转。这可以被想象成一个在空间中旋转的 n 维。听着这个方法好好像实现是复杂,其实不然,这在 PyTorch 等库中只需要大约十行代码就可以高效的实现。
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x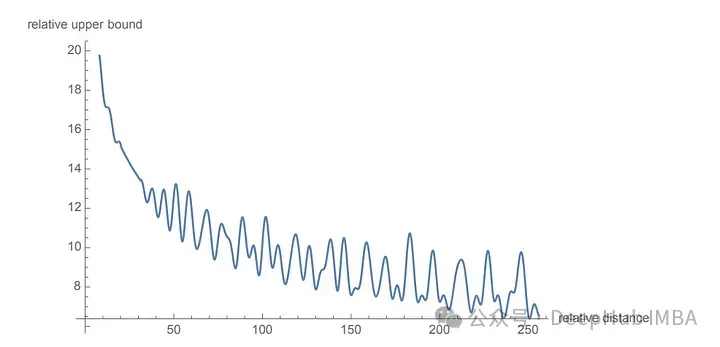
为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
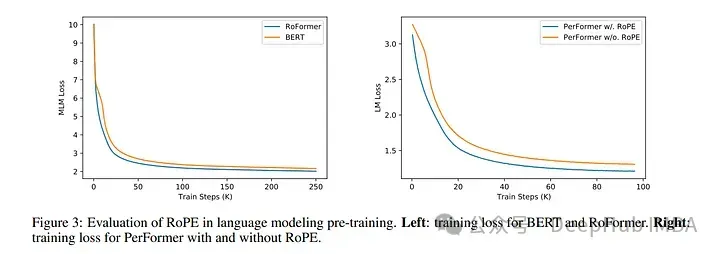
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
总结
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
以上が大規模な言語モデルで一般的に使用される回転位置エンコーディング RoPE の詳細な説明: なぜ絶対位置エンコーディングや相対位置エンコーディングよりも優れているのですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。