
ホームページ >テクノロジー周辺機器 >AI >DeepMind は大規模モデルの幻想を終わらせますか?事実のラベル付けは人間よりも信頼性が高く、20 分の 1 のコストがかかり、完全にオープンソースです
DeepMind は大規模モデルの幻想を終わらせますか?事実のラベル付けは人間よりも信頼性が高く、20 分の 1 のコストがかかり、完全にオープンソースです

- PHPz転載
- 2024-03-30 18:01:32719ブラウズ
ビッグモデルの幻想はついに終わりを迎えますか?
今日、ソーシャルメディアプラットフォームReddit上の投稿がネチズンの間で激しい議論を巻き起こしました。この投稿は、昨日 Google DeepMind によって提出された論文「大規模言語モデルにおける長形式の事実性」について論じています。この記事で提案されている方法と結果により、人々は大規模言語モデルの幻想はもはや問題ではないと結論付けることになります。

大規模な言語モデルでは、事実を探求する自由形式の質問に答えるときに、事実誤認を含むステートメントが生成されることが多いことがわかっています。 DeepMind は、この現象についていくつかの探索的研究を実施しました。
オープン ドメインにおけるモデルの長い形式の事実性のベンチマークを行うために、研究者らは GPT-4 を使用して、38 のトピックと数千の質問を含むプロンプトである LongFact を生成しました。次に彼らは、SAFE (Search Augmented Fact Evaluator) を使用して、LLM エージェントを長文の事実性の自動評価装置として使用することを提案しました。 SAFE の目的は、事実の信頼性評価者の精度を向上させることです。
SAFE に関しては、LLM を使用すると、各インスタンスの精度をより正確に説明できます。この複数段階の推論プロセスには、検索クエリを Google 検索に送信し、検索結果が特定のインスタンスをサポートしているかどうかを判断することが含まれます。

論文アドレス: https://arxiv.org/pdf/2403.18802.pdf
GitHubアドレス: https://github.com/google-deepmind/long-form-factuality
さらに、研究者は、F1 スコア (F1@K) を長いスコアに拡張することを提案しました。 - 実用的な集計インジケーターを形成します。これらは、応答でサポートされているファクトの割合 (精度) と、ユーザーの優先応答の長さを表すハイパーパラメータに対して提供されたファクトの割合 (再現率) のバランスをとります。
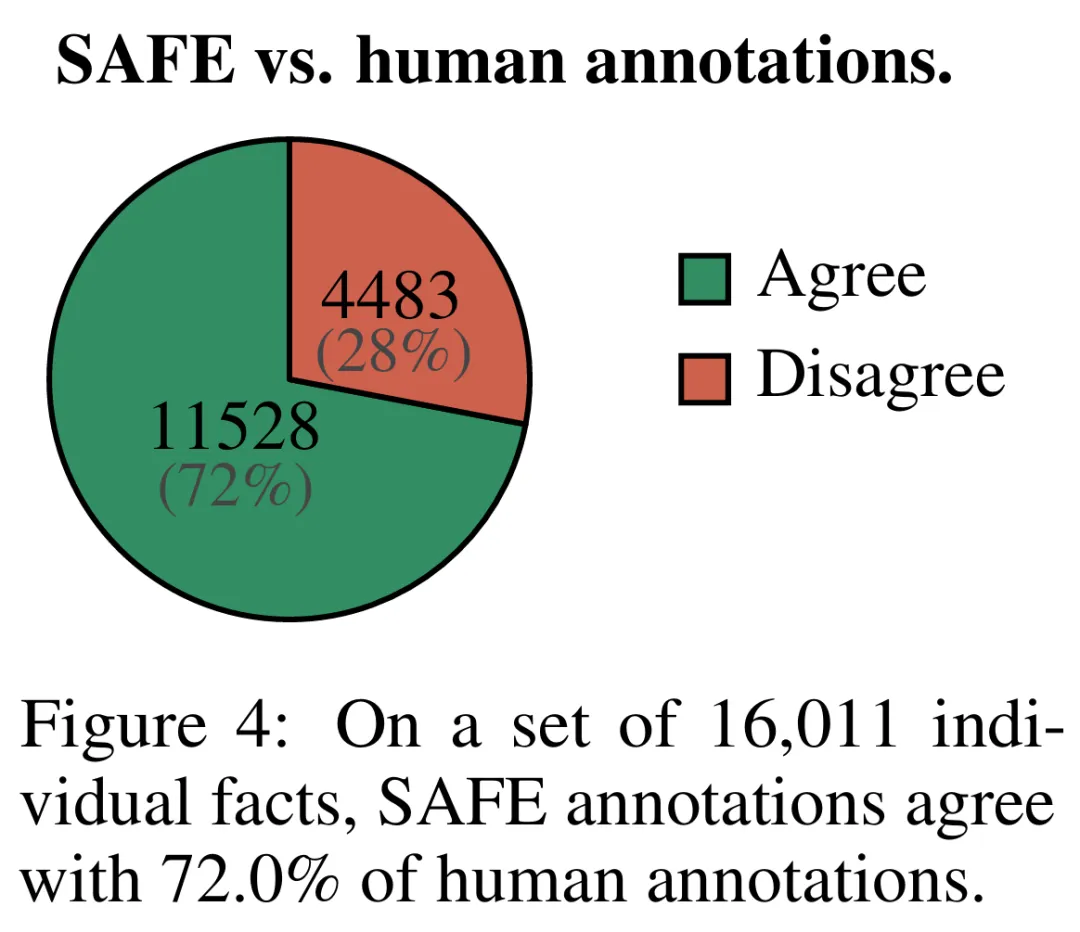
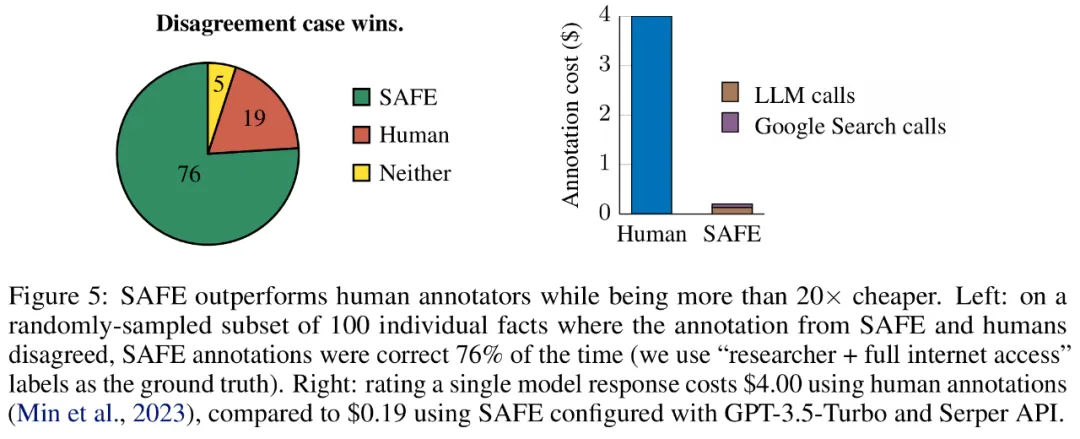
実験結果は、LLM エージェントが人間を超える評価パフォーマンスを達成できることを示しています。約 16,000 個の個別の事実のセットについては、SAFE は 72% の確率でヒューマン アノテーターと一致し、100 件の不一致ケースのランダムなサブセットについては、SAFE が 76% の確率で勝利します。同時に、SAFE はヒューマン アノテーターよりも 20 倍以上安価です。
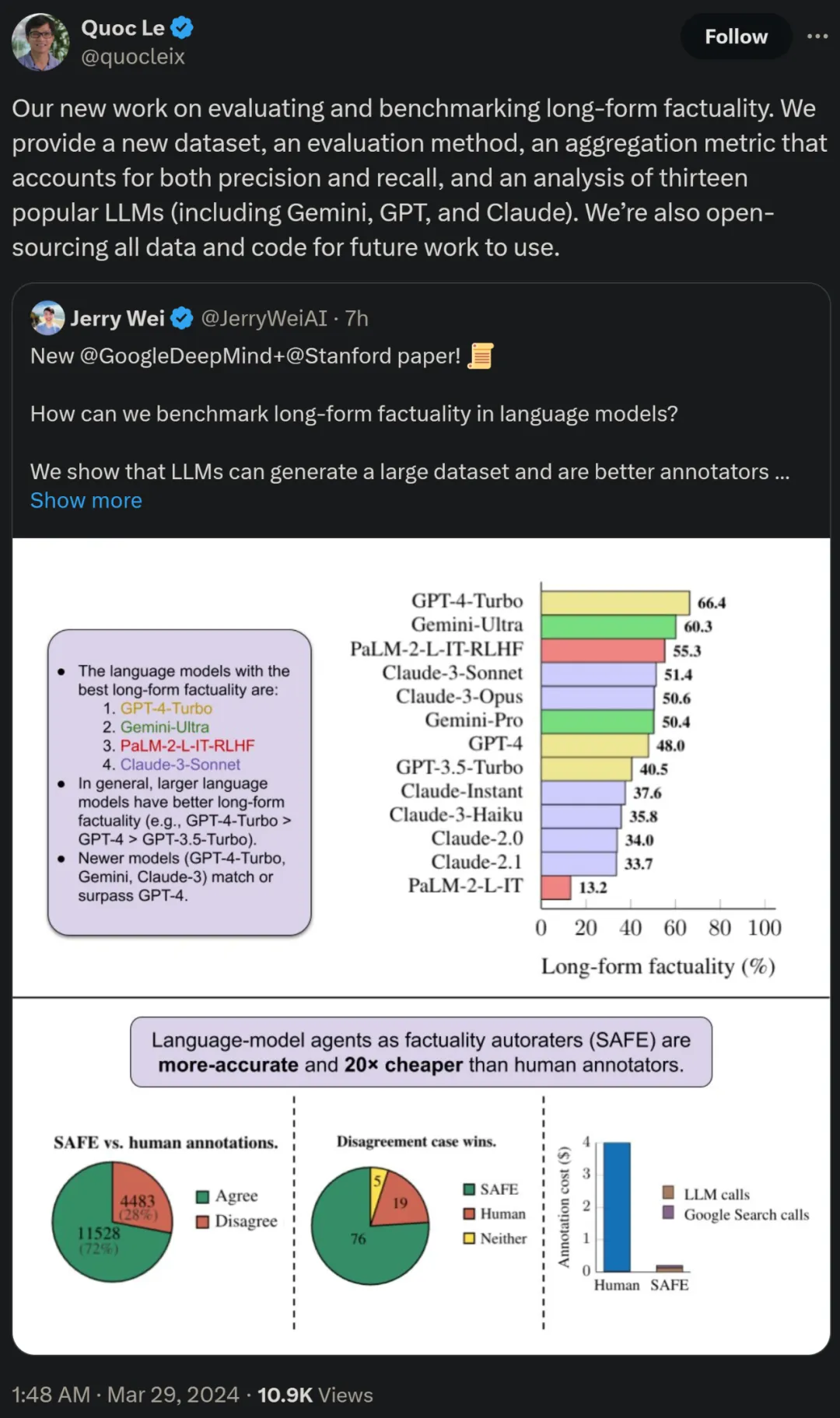
研究者らはまた、LongFact を使用して、4 つの大規模なモデル シリーズ (Gemini、GPT、Claude、PaLM-2) の 13 の人気のある言語モデルのベンチマークを行ったところ、言語モデルが大きいほど、長い言語モデルのパフォーマンスが向上することが多いことがわかりました。 -形式的な事実。
この論文の著者の一人であり、Google の研究科学者でもある Quoc V. Le 氏は、長文の事実性の評価とベンチマークに関するこの新しい研究は、新しいデータセットを提案していると述べました。新しい評価方法と、精度と再現率の両方を考慮した集計指標。同時に、すべてのデータとコードは将来の作業のためにオープンソースになります。
メソッドの概要
LONGFACT: 事実に基づく長文の複数トピックのベンチマークの生成LLM を使用する
まず、GPT-4 を使用して生成された LongFact プロンプト セットを見てみましょう。これには、手動で選択した 38 のトピックにわたる長い形式の応答を必要とする 2,280 の事実探索プロンプトが含まれています。研究者らは、LongFact はさまざまな分野における長文の事実性を評価するための最初のプロンプト セットであると述べています。
LongFact は、LongFact-Concepts と LongFact-Objects という 2 つのタスクで構成されており、質問が概念とオブジェクトのどちらについて尋ねているかによって区別されます。研究者らは被験者ごとに 30 個の固有の手がかりを生成し、その結果、各タスクに対して 1,140 個の手がかりが得られました。

安全: 事実に基づく自動評価者としての LLM エージェント
研究者らは、検索拡張ファクト評価 (SAFE) を提案しました。これは次のように動作します:
a) 長い応答を個別の独立したファクトに分割します;
b) 個々の事実がコンテキスト内のプロンプトに答えるのに関連しているかどうかを判断します;
c) 関連する事実ごとに、複数ステップのプロセスで Google 検索クエリを繰り返し発行し、検索結果がその事実を裏付けるかどうかを推論します。
彼らは、SAFE の主要な革新は、言語モデルをエージェントとして使用して、複数ステップの Google 検索クエリを生成し、検索結果が事実を裏付けるかどうかを慎重に推論することであると考えています。以下の図 3 は、推論チェーンの例を示しています。
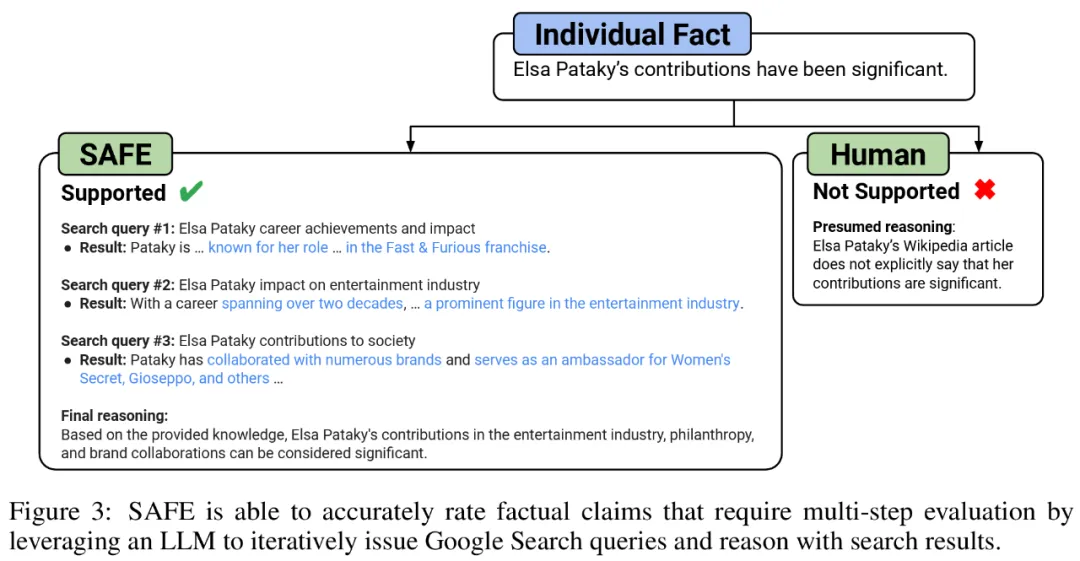
長い応答を個別の独立した事実に分割するために、研究者らはまず、言語モデルに長い応答内の各文を個々の事実に分割するよう指示しました。次に、曖昧な参照 (代名詞など) を応答コンテキスト内で参照する正しいエンティティに置き換えるようモデルに指示することで、個々のファクトを独立したものに変更します。
それぞれの独立した事実をスコアリングするために、言語モデルを使用して、その事実が応答コンテキストで回答されたプロンプトに関連しているかどうかを推論し、複数ステップの方法を使用してランク付けしました。残りの各関連事実は、「支持される」または「支持されない」として評価されます。詳細を以下の図 1 に示します。
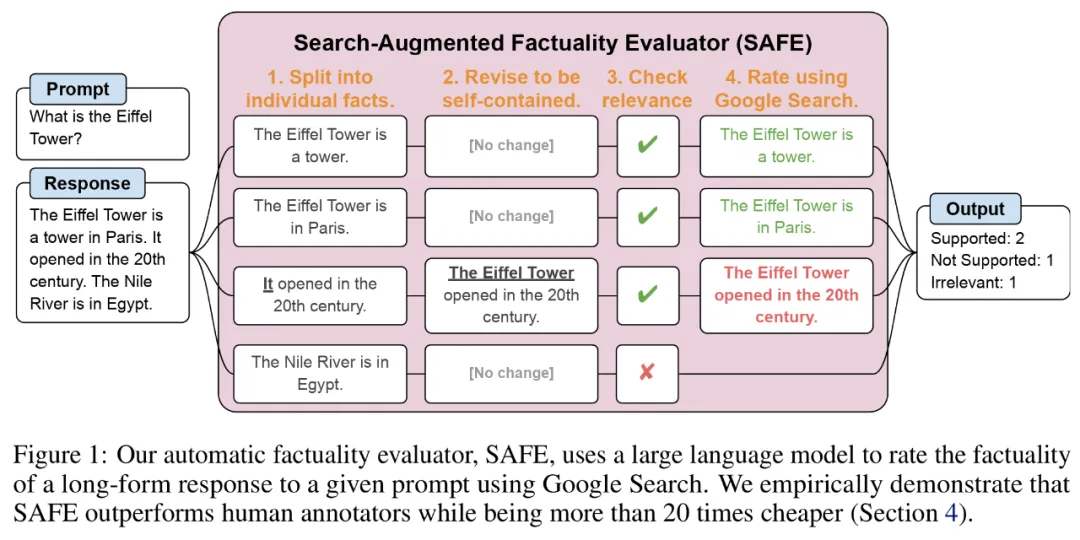
#各ステップで、モデルはスコア付けされるファクトと以前に取得した検索結果に基づいて検索クエリを生成します。一定数のステップの後、モデルは推論を実行して、検索結果がその事実を裏付けるかどうかを判断します (上の図 3 を参照)。すべての事実が評価された後、特定のプロンプト応答ペアに対する SAFE の出力メトリックは、「裏付けとなる」事実の数、「無関係な」事実の数、および「サポートされない」事実の数になります。
#実験結果#LLM エージェントは人間よりも優れたファクト アノテーターになる
SAFE を使用して取得されたアノテーションの品質を定量的に評価するために、研究者らはクラウドソーシングによる人間によるアノテーションを使用しました。データには 496 のプロンプト応答ペアが含まれており、応答は手動で個々の事実 (合計 16,011 個の個々の事実) に分割され、個々の事実はサポートされている、無関係である、またはサポートされていないとして手動でラベル付けされました。彼らは、各ファクトについて SAFE アノテーションと人間によるアノテーションを直接比較したところ、以下の図 4 に示すように、SAFE が個々のファクトの 72.0% について人間と一致していることがわかりました。これは、SAFE がほとんどの個別の事実に対して人間レベルのパフォーマンスを達成していることを示しています。次に、SAFE の注釈が人間の評価者の注釈と一致しない、ランダムなインタビューから得られた 100 の個別の事実のサブセットが検査されました。
ここで注目すべきは 2 つのアノテーション プランの価格です。人間の注釈を使用して単一のモデル応答を評価するコストは 4 ドルですが、GPT-3.5-Turbo と Serper API を使用した SAFE はわずか 0.19 ドルです。
##最後に研究者らは、以下の表 1 の 4 つのモデル シリーズ (Gemini、GPT、Claude、PaLM-2) の 13 個の大規模言語モデルに対して、LongFact に関する広範なベンチマーク テストを実施しました。
具体的には、LongFact-Objects の 250 プロンプトの同じランダムなサブセットを使用して各モデルを評価し、次に SAFE を使用して各モデルの応答の生の評価メトリクスを取得しました。集計用の F1@K インジケーター。
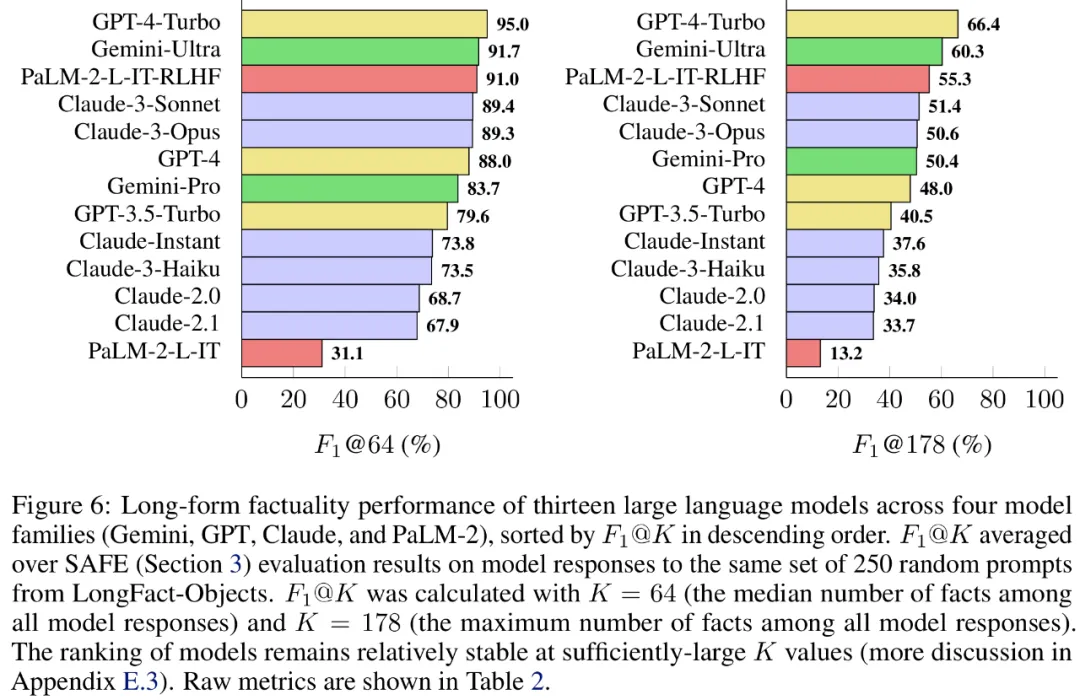
一般に、言語モデルが大きいほど、長い形式の事実性が向上することがわかりました。以下の図 6 と表 2 に示すように、GPT-4-Turbo は GPT-4 よりも優れており、GPT-4 は GPT-3.5-Turbo よりも優れており、Gemini-Ultra は Gemini-Pro よりも優れており、PaLM-2-L よりも優れています。 -IT-RLHF PaLM-2-L-IT よりも優れています。
#技術的な詳細と実験結果については、元の論文を参照してください。
以上がDeepMind は大規模モデルの幻想を終わらせますか?事実のラベル付けは人間よりも信頼性が高く、20 分の 1 のコストがかかり、完全にオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。