
ホームページ >テクノロジー周辺機器 >AI >必要なのは注意力だけではありません! Mamba ハイブリッド大規模モデルのオープンソース: Transformer スループットが 3 倍
必要なのは注意力だけではありません! Mamba ハイブリッド大規模モデルのオープンソース: Transformer スループットが 3 倍

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-30 09:41:16946ブラウズ
Mamba Time has come?
The transformer architecture has dominated the field of generative artificial intelligence since the publication of the groundbreaking research paper "Attention is All You Need" in 2017.
However, the transformer architecture actually has two significant disadvantages:
The memory footprint of the Transformer changes with the length of the context. This makes it challenging to run long context windows or massive parallel processing without significant hardware resources, thus limiting widespread experimentation and deployment. The memory footprint of Transformer models scales with context length, making it difficult to run long context windows or heavily parallel processing without significant hardware resources, thus limiting widespread experimentation and deployment.
The attention mechanism in the Transformer model will adjust the speed according to the increase in the context length. This mechanism will randomly expand the sequence length and reduce the amount of calculation because each token depends on it. the entire sequence before, thereby applying context beyond the scope of efficient production.
Transformers are not the only way forward for productive artificial intelligence. Recently, AI21 Labs launched and open sourced a new method called "Jamba" that surpasses the transformer on multiple benchmarks.

Hugging Face Address: https://huggingface.co/ai21labs/Jamba-v0.1
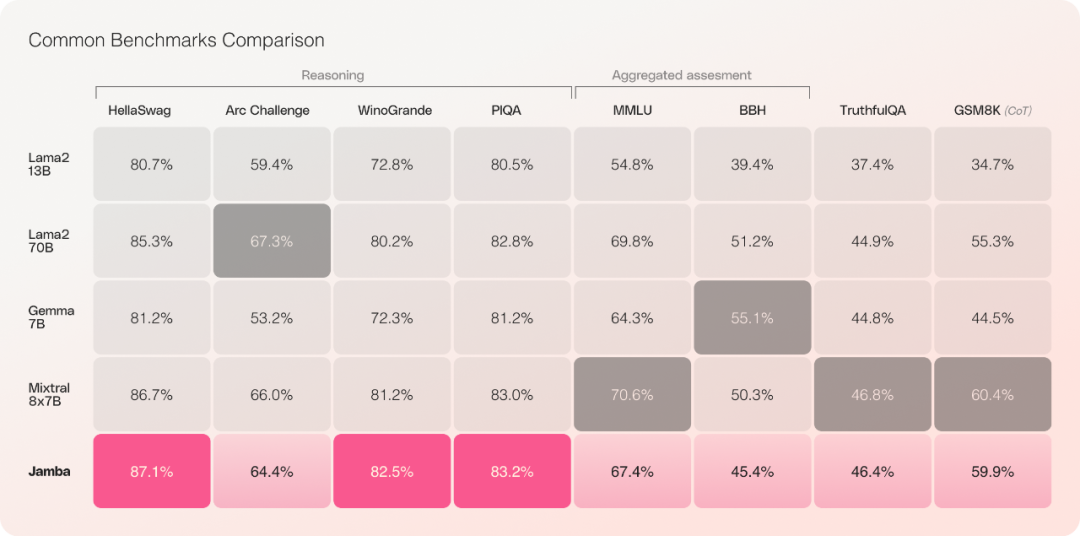
Mamba The SSM architecture can well solve the memory resource and context issues of the transformer. However, the Mamba approach struggles to provide the same level of output as the transformer model.
Jamba combines the Mamba model based on the Structured State Space Model (SSM) with the transformer architecture, aiming to combine the best properties of SSM and transformer.

Jamba is also accessible from the NVIDIA API catalog as an NVIDIA NIM inference microservice that enterprise application developers can deploy using the NVIDIA AI Enterprise software platform.
In general, the Jamba model has the following characteristics:
The first production-level model based on Mamba, using a novel SSM-Transformer hybrid architecture;
3x improved throughput on long contexts compared to Mixtral 8x7B;
Provides access to 256K context windows;
Exposed model weights;
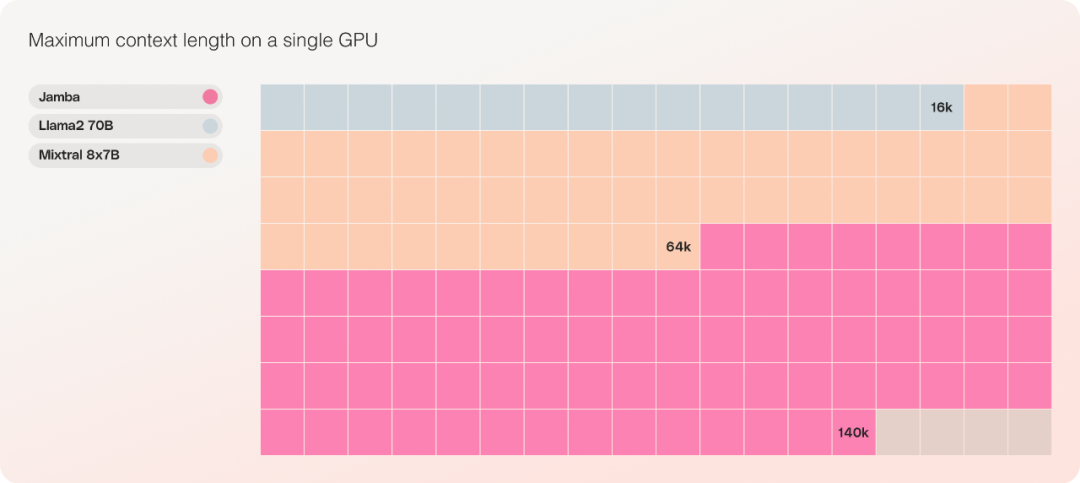
The only model of the same parameter scale that can accommodate up to 140K contexts on a single GPU.
Model Architecture
As shown in the figure below, Jamba's architecture adopts a blocks-and-layers approach to enable Jamba to integrate Two architectures. Each Jamba block consists of an attention layer or a Mamba layer, followed by a multilayer perceptron (MLP), forming a transformer layer.
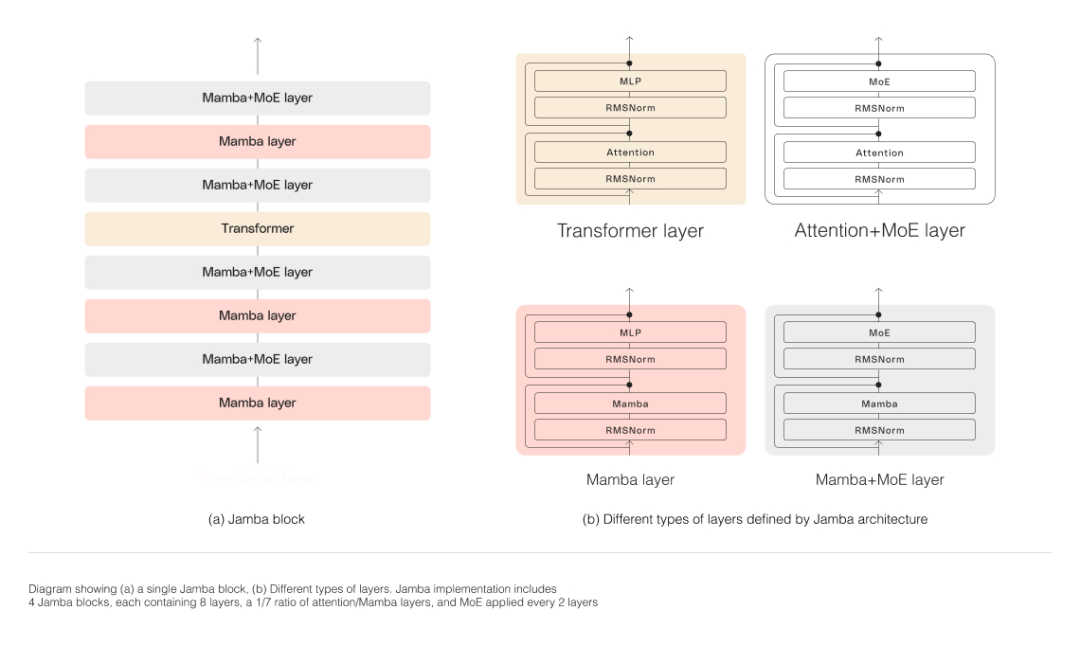
Jamba leverages MoE to increase the total number of model parameters while simplifying the number of active parameters used in inference, resulting in higher performance without a corresponding increase in computational requirements. Model capacity. To maximize model quality and throughput on a single 80GB GPU, the research team optimized the number of MoE layers and experts used, leaving enough memory for common inference workloads.
Jamba’s MoE layer allows it to utilize only 12B of the available 52B parameters at inference time, and its hybrid architecture makes these 12B active parameters more efficient than a pure transformer model of equivalent size.
Previously, no one extended Mamba beyond 3B parameters. Jamba is the first hybrid architecture of its kind to reach production scale.
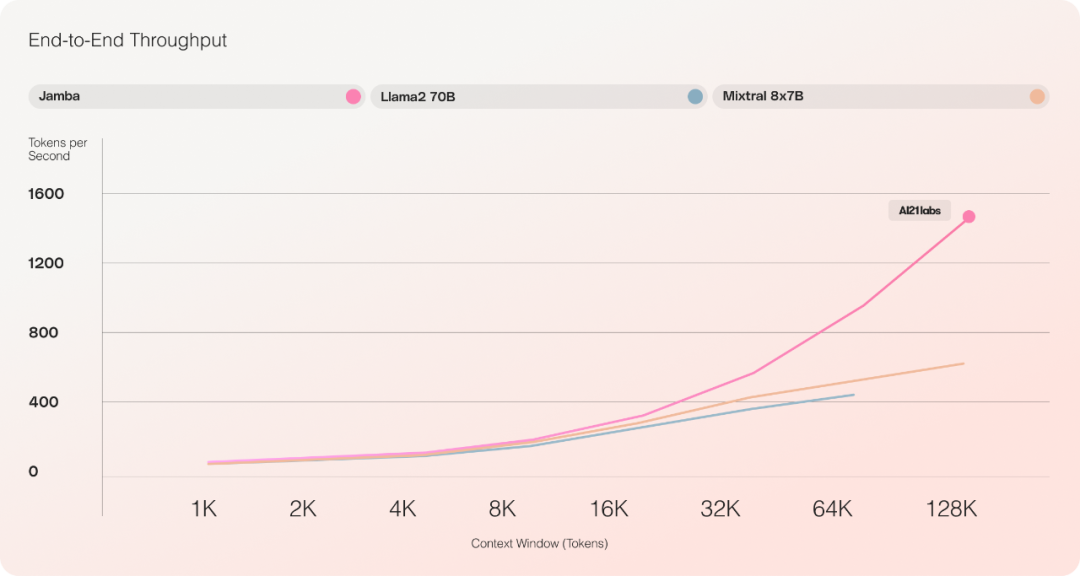
Throughput and Efficiency
Initial evaluation experiments show that Jamba performs well on key metrics such as throughput and efficiency.
In terms of efficiency, Jamba achieves 3x the throughput of Mixtral 8x7B on long contexts. Jamba is more efficient than similarly sized Transformer-based models such as Mixtral 8x7B.
In terms of cost, Jamba can accommodate 140K contexts on a single GPU. Jamba offers more deployment and experimentation opportunities than other current open source models of similar size.
Jamba が現在の Transformer ベースの大規模言語モデル (LLM) を置き換える可能性は現時点では低いことに注意してください。ただし、一部の領域では補完となる可能性があります。
#参考リンク:
#https://www.ai21.com/blog/owned-jamba
##https://venturebeat.com/ai/ai21-labs-juices-up-gen-ai-transformers-with-jamba/以上が必要なのは注意力だけではありません! Mamba ハイブリッド大規模モデルのオープンソース: Transformer スループットが 3 倍の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。