
ホームページ >テクノロジー周辺機器 >AI >マンバの超進化形態がトランスフォーマーを一挙に打ち破る! 140K コンテキストを実行する単一の A100
マンバの超進化形態がトランスフォーマーを一挙に打ち破る! 140K コンテキストを実行する単一の A100

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-29 15:11:18887ブラウズ
以前 AI サークルを爆発させた Mamba アーキテクチャが、本日スーパーバリアントをリリースしました。
人工知能のユニコーン AI21 Labs は、世界初の実稼働レベルの Mamba 大型モデルである Jamba をオープンソース化しました。

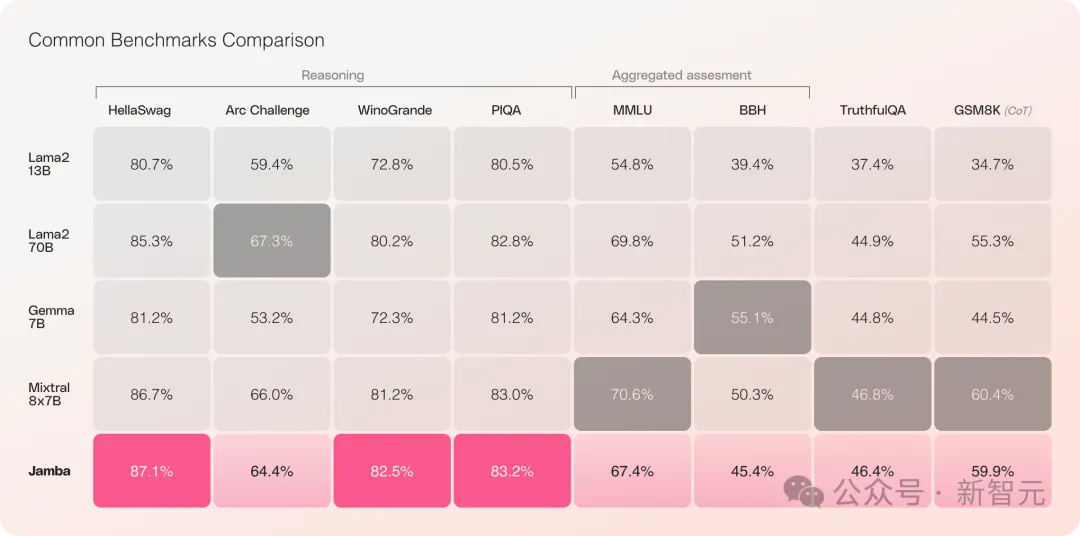
Jamba は複数のベンチマーク テストで良好なパフォーマンスを示し、現在最も強力なオープンソース Transformers の一部と同等の性能を示しています。
特に、最高のパフォーマンスを持ち、MoE アーキテクチャでもある Mixtral 8x7B を比較する場合、勝者と敗者も存在します。
具体的には、——
- は、新しい SSM-Transformer ハイブリッド アーキテクチャに基づく最初の製品グレードの Mamba モデルです
- Mixtral 8x7B と比較して長いテキスト処理のスループットが 3 倍増加
- 256K の超長いコンテキスト ウィンドウを達成
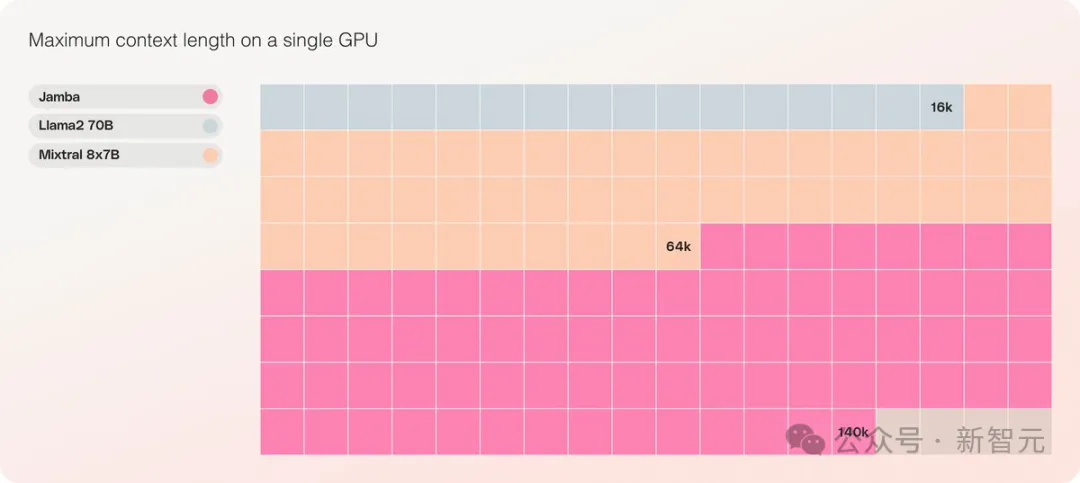
- これは、単一の GPU で 140K のコンテキストを処理できる同じ規模の唯一のモデルです
- Apache 2.0 オープン ソース ライセンスに基づいてリリースされ、大きなオープン権が付与されています
#従来のマンバはさまざまな制約により3Bしかできず、トランスフォーマーを引き継ぐことができるかどうかも疑問視されていました。一方、同じく線形 RNN ファミリである RWKV、Griffin などは 14B までしか拡張されていません。
——今回、Jamba は直接 52B に移行し、Mamba アーキテクチャが製品レベルの Transformer と初めて正面から競合できるようになりました。

オリジナルの Mamba アーキテクチャに基づいて、Jamba は状態空間の欠点を補うために Transformer の利点を組み込んでいます。モデル (SSM) 固有の制限。
これは実際には新しいアーキテクチャであると考えることができます。最も重要なことは、Transformer と Mamba を組み合わせたものです。素晴らしいのは、1 台の A100 で実行できることです。
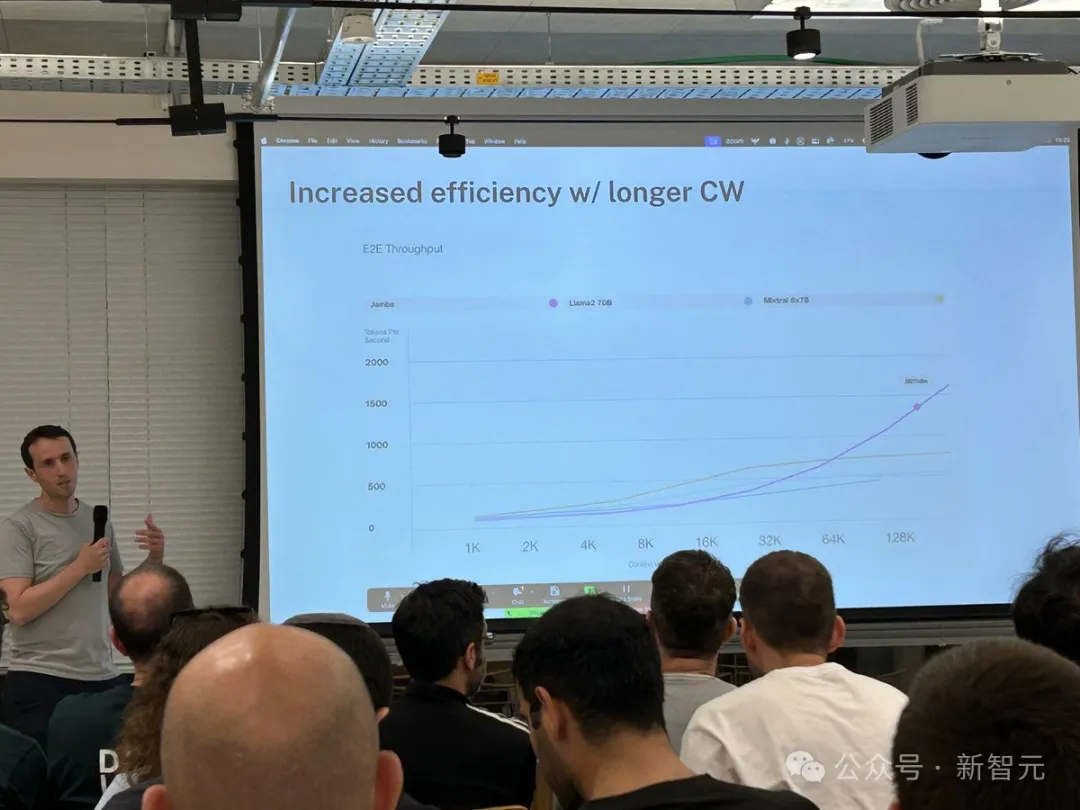
最大 256K の超長いコンテキスト ウィンドウを提供し、単一の GPU で 140K のコンテキストを実行でき、スループットは Transformer の 3 倍です。
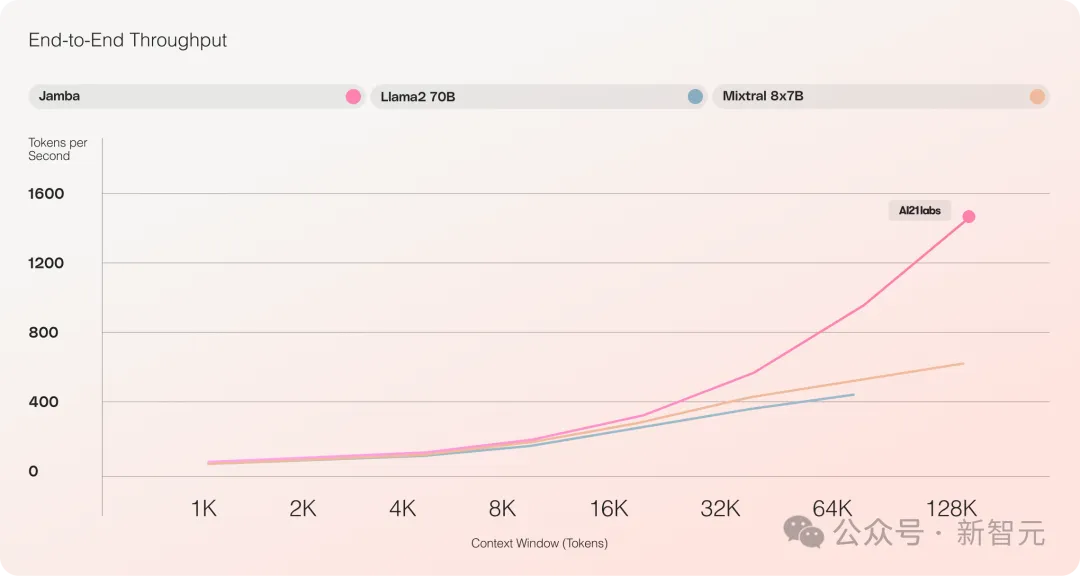
Transformer と比較すると、Jamba が巨大なコンテキスト長にどのように対応するかを見るのは非常に衝撃的です。
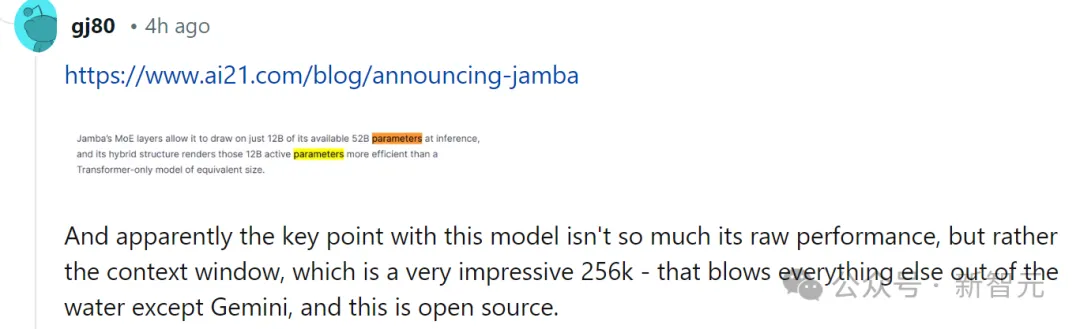
Jamba は MoE ソリューションを採用しています。52B のうち 12B がアクティブなパラメータです。現在のモデルは Apache 2.0 でオープン ウェイトを持ち、huggingface でダウンロードできます。

LLM の新しいマイルストーン
Jamba のリリースは、LLM にとって 2 つの重要なマイルストーンを示します:まず、Mamba と Transformer の統合が成功しました。 2 つ目は、新しい形式のモデル (SSM-Transformer) を実稼働レベルのスケールと品質にアップグレードすることに成功することです。
最強のパフォーマンスを備えた現在の大規模モデルはすべて Transformer に基づいていますが、Transformer アーキテクチャの 2 つの主な欠点も誰もが認識しています。
大きなメモリ フットプリント: Transformer のメモリ フットプリントは、コンテキストの長さに応じて拡大します。長いコンテキスト ウィンドウや大規模な並列バッチ処理を実行するには、大量のハードウェア リソースが必要となるため、大規模な実験や展開が制限されます。数年前、カーネギーメロン大学とプリンストン大学の 2 人の偉人が Mamba を提案し、人々の希望にすぐに火をつけました。コンテキストが大きくなるにつれて、推論速度は遅くなります。Transformer のアテンション メカニズムにより、推論時間はシーケンスの長さに比例して増加し、スループットはますます遅くなります。各トークンはその前のシーケンス全体に依存するため、非常に長いコンテキストを実現するのは非常に困難になります。
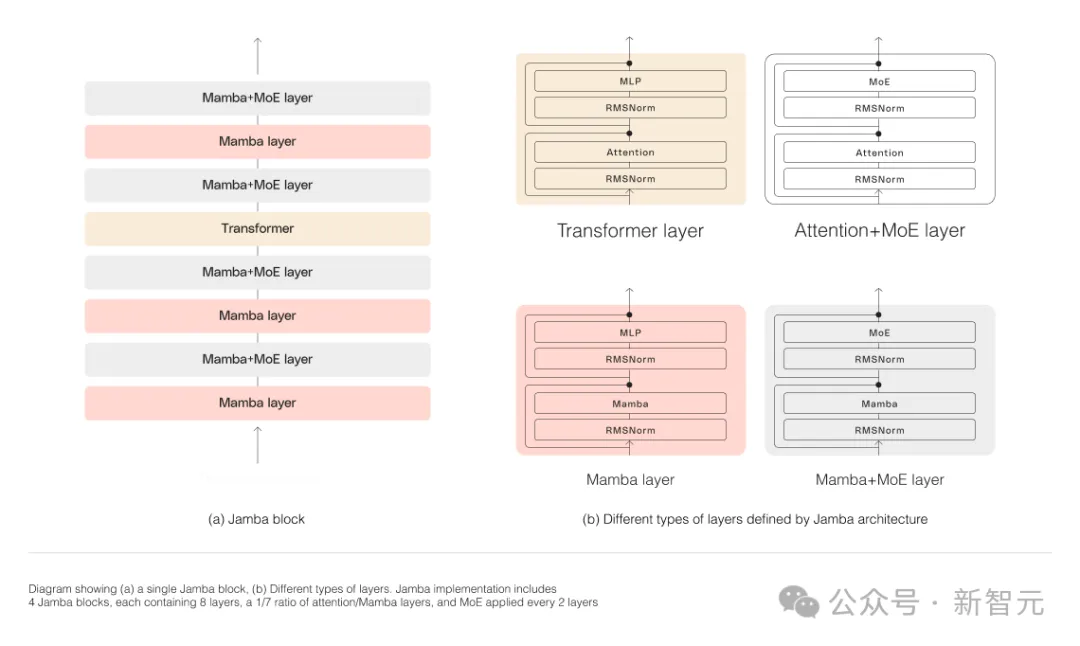
Mamba is based on SSM, adds the ability to selectively extract information, and efficient algorithms on hardware, solving the problems of Transformer in one fell swoop. This new field immediately attracted a large number of researchers. A large number of applications and improvements about Mamba emerged on arXiv, such as Vision Mamba, which uses Mamba for vision. I have to say that the current scientific research field is really complicated. It took three years to introduce Transformer into Vision (ViT), but Mamba arrived Vision Mamba only lasted a month. However, the context length of the original Mamba is shorter, and the model itself has not been enlarged, so it is difficult to beat the SOTA Transformer model, especially in tasks related to recall. Jamba then went a step further and integrated the advantages of Transformer, Mamba, and Mix of Experts (MoE) through the Joint Attention and Mamba architecture, while optimizing memory, throughput and performance. Jamba is the first hybrid architecture to reach production scale (52B parameters). As shown in the figure below, AI21’s Jamba architecture adopts a blocks-and-layers approach, allowing Jamba to successfully integrate the two architectures. Each Jamba block consists of an attention layer or a Mamba layer, followed by a multilayer perceptron (MLP). The second feature of Jamba is to use MoE to increase the total number of model parameters and simplify the parameters used in inference. number of active parameters, thereby increasing model capacity without increasing computational requirements. To maximize model quality and throughput on a single 80GB GPU, the researchers optimized the number of MoE layers and experts used, leaving room for common inference workloads enough memory. Compared with Transformer-based models of similar size such as Mixtral 8x7B, Jamba achieves 3 times acceleration in long contexts . Jamba will be added to the NVIDIA API directory soon. Recently, major companies are rolling out long context. Models with smaller context windows tend to forget the content of recent conversations, while models with larger context avoid this pitfall and can better grasp what they receive data flow. However, models with long context windows tend to be computationally intensive. Generative models from startup AI21 Labs prove that this is not the case. Jamba can handle up to 140,000 when running on a single GPU (such as the A100) with at least 80GB of video memory token. This equates to approximately 105,000 words, or 210 pages, which is the length of a medium-length novel. In contrast, Meta Llama 2’s context window has only 32,000 tokens and requires 12GB of GPU memory. By today's standards, this context window is obviously small. Regarding this, some netizens immediately said that performance is not important. The key is that Jamba has a 256K context. Except for Gemini, no one else is that long. — —And Jamba is open source. On the surface, Jamba seems unremarkable. Whether it is DBRX, which was in the limelight yesterday, or Llama 2, there are now a large number of free and downloadable generative AI models. The uniqueness of Jamba is hidden under the model: it combines two model architectures at the same time-Transformer and state space model SSM. On the one hand, Transformer is the preferred architecture for complex reasoning tasks. Its core defining feature is the “attention mechanism”. For each piece of input data, the Transformer weighs the relevance of all other inputs and extracts from them to generate the output. On the other hand, SSM combines many advantages of earlier AI models, such as recurrent neural networks and convolutional neural networks, so it can process long sequence data with high computational efficiency. higher. Although SSM has its own limitations. But some early representatives, such as Mamba proposed by Princeton and CMU, can handle larger outputs than the Transformer model and are better at language generation tasks. In this regard, AI21 Labs product manager Dagan said - Although there are some preliminary examples of SSM models, Jamba is the first production-scale commercial grade model. In his view, in addition to being innovative and interesting for the community to further study, Jamba also provides huge efficiency and throughput possibilities. Currently, Jamba is released under the Apache 2.0 license, with fewer usage restrictions but not for commercial use. Subsequent fine-tuned versions are expected to be launched within a few weeks. Even though it is still in the early stages of research, Dagan asserts that Jamba undoubtedly shows the great promise of the SSM architecture. "The added value of this model - both due to size and architectural innovation - is that it can be easily installed on a single GPU." 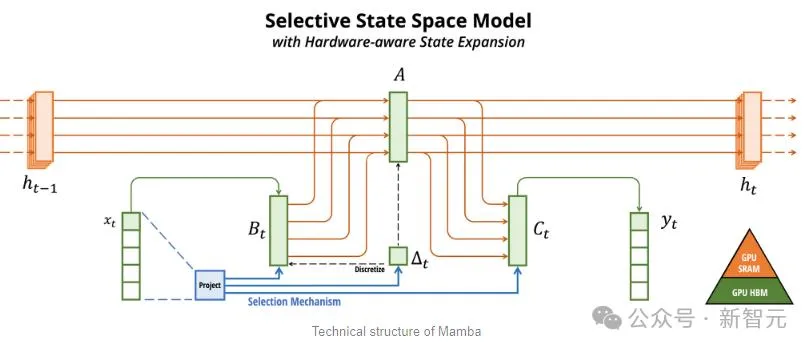

Long context has a new player

What makes Jamba truly unique
以上がマンバの超進化形態がトランスフォーマーを一挙に打ち破る! 140K コンテキストを実行する単一の A100の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- Javaソフトウェアシステムの機能設計実習ビデオチュートリアル
- Haimo スーパーコンピューティング センターの公式発表: 1,000 億のパラメーターを持つ大規模モデル、100 万クリップのデータ規模、トレーニング コストの 200 倍の削減
- 今年の英語大学入学試験では、CMU が再構築事前トレーニングを使用して GPT3 を大幅に上回る 134 点の高得点を達成しました
- バック・トゥ・ザ・フューチャー! AI をトレーニングするために子供時代の日記を使用したこのプログラマーは、GPT-3 を使用して「過去の自分」との対話を実現しました
- 視覚を利用してプロンプトを表示してください。 Shen Xiangyang 氏は、トレーニングや微調整を必要とせず、すぐに使用できる IDEA Research Institute の新しいモデルを披露しました。