
ホームページ >テクノロジー周辺機器 >AI >LLM のパフォーマンスが最大 60% 向上しました。 Google ICLR 2024 の傑作: 大規模言語モデルに「グラフの言語」を学習させよう
LLM のパフォーマンスが最大 60% 向上しました。 Google ICLR 2024 の傑作: 大規模言語モデルに「グラフの言語」を学習させよう

- 王林転載
- 2024-03-27 20:46:33772ブラウズ
コンピュータ サイエンスの分野では、グラフ構造はノード (エンティティを表す) とエッジ (エンティティ間の関係を表す) で構成されます。
写真はいたるところにあります。
インターネットは巨大なネットワークとみなすことができ、検索エンジンはグラフィカルな方法を使用して情報を整理し、表示します。
LLM は主に通常のテキストでトレーニングされるため、グラフの構造がテキストとは根本的に異なるため、グラフを LLM が理解できるテキストに変換するのは困難な作業です。
ICLR 2024 で、Google のチームは、グラフ データを LLM が理解できる適切な形式に変換する方法を検討しました。

#論文アドレス: https://openreview.net/pdf?id=IuXR1CCrSi
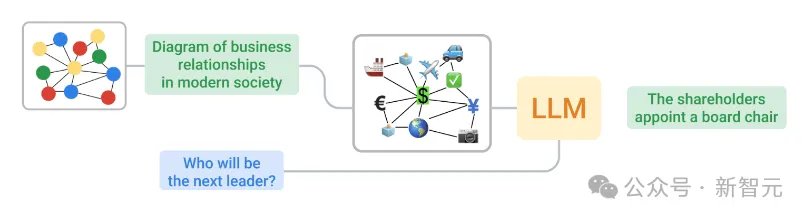
##2 つの異なる方法を使用してグラフをテキストにエンコードし、テキストと質問を LLM にフィードバックするプロセス
##また、GraphQA と呼ばれるツールも開発しました。さまざまなグラフ推論問題を解決するためのアプローチを示し、LLM によるグラフ関連の問題の解決に役立つ方法でこれらの問題を定式化する方法を示します。正しい方法を使用すると、LLM はグラフィックス タスクのパフォーマンスを最大 60% 向上させることができます。
GraphOA: LLM のための「試験」
まず、Google チームは GraphQA ベンチマークを設計しました。これは、設計された試験として見ることができます。特定のグラフィックス問題に対処する LLM の能力を評価します。GraphOA は、複数の種類のグラフを使用して、グラフ処理時に LLM の潜在的なバイアスを検出し、プロセス全体を、次のような場合に発生する可能性のある LLM の状況に近づけることで、接続の幅と数の多様性を確保します。実用的なアプリケーション。
 #GraphIQA を使用した LLM の推論フレームワーク
#GraphIQA を使用した LLM の推論フレームワーク
作業はチェックなど簡単ですが、エッジが存在するかどうか、ノードやエッジの数を数えるなどですが、これらのタスクでは LLM がノードとエッジの間の関係を理解する必要があり、これはより複雑なグラフ推論にとって重要です。
同時に、チームは、次の 2 つの重要な問題を解決するなど、グラフを LLM が処理できるテキストに変換する方法も検討しました。
ノードのエンコーディング: 単一ノードをどのように表現するか?ノードには、単純な整数、一般名 (人物、キャラクター)、および文字を含めることができます。エッジ コーディング: ノード間の関係をどのように記述するか?メソッドには、括弧、フレーズ (「友達です」など)、および記号表現 (矢印など) を含めることができます。
最終的に、研究者らはさまざまなノードとエッジのエンコーディング手法を系統的に組み合わせて、以下の図に示すような関数を生成しました。
#グラフィカル エンコーディング関数の例

#研究チームは、GraphOA に関して 3 つの重要な実験を実施しました:
グラフィックス タスクを処理する LLM の能力のテスト
LLM のサイズがパフォーマンスに与える影響をテストする
- さまざまなグラフ形状がパフォーマンスに与える影響をテストする
- #In Chapter ある実験では、LLM のパフォーマンスは平凡で、ほとんどの基本的なタスクでは、LLM のパフォーマンスはランダムな推測と同じでした。
- ただし、エンコード方法は結果に大きく影響します。次の図に示すように、ほとんどの場合、「インシデント」エンコードはほとんどのタスクで適切に実行されます。適切なエンコード関数を選択すると、タスクの精度が大幅に向上します。
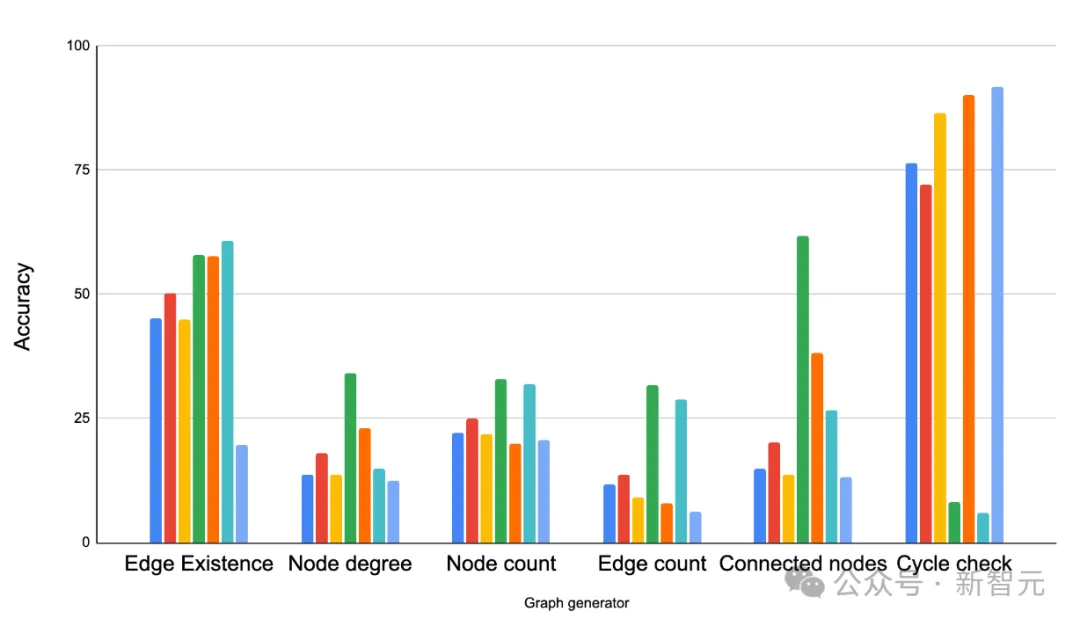
異なるタスク精度に基づくさまざまなグラフ エンコーダ関数の比較 2 番目のテストでは、研究者は異なるサイズのモデルのグラフィックス タスクで同様のテストを行いました。 結論としては、グラフィカル推論タスクでは、大きなモデルの方がパフォーマンスが高くなります。 ただし、興味深いことに、「エッジの存在」では、タスク (グラフ内の 2 つのノードが接続されているかどうかを判断する) では、スケールは他のタスクほど重要ではありません。 最大規模の LLM であっても、サイクル チェック問題 (グラフ内にサイクルが存在するかどうかを判断する) では、常に単純なベースライン ソリューションに勝てるとは限りません。これは、LLM には特定のグラフ タスクに関してまだ改善の余地があることを示しています。 PaLM 2-XXS、XS、S、L のグラフ推論タスクに対するモデル能力の影響 3 番目のテストでは、研究者らは GraphOA を使用して、グラフ構造が LMM の問題解決能力に影響を与えるかどうかを分析するために、さまざまな構造を持つグラフを生成しました。 # GraphQA のさまざまなグラフ ジェネレーターによって生成されたグラフの例。 ER、BA、SBM、SFN は、それぞれ Erdős-Rényi、Barabasi-Albert、確率的ブロック モデル、スケールフリー ネットワークです。 結果は、グラフの構造が LLM のパフォーマンスに大きな影響を与えることを示しています。 たとえば、サイクルが存在するかどうかを尋ねるタスクでは、LLM は密接に接続されたグラフ (サイクルが一般的である) ではうまく機能しますが、パス グラフ (サイクルが一般的である) では機能しません。 )。 しかし同時に、いくつかの混合サンプルを提供することは、LLM の適応に役立ちます。たとえば、サイクル検出タスクでは、研究者はサイクルを含むサンプルとサイクルを含まないサンプルを追加しました。プロンプトではサンプル学習の例が少なくなり、この方法で LLM のパフォーマンスが向上します。 さまざまなグラフ タスクでさまざまなグラフ ジェネレーターを比較します。主な観察は、グラフ構造が LLM のパフォーマンスに大きな影響を与えるということです。 ER、BA、SBM、SFN は、それぞれエルデシュ-レーニ、バラバシ-アルバート、確率的ブロック モデル、スケールフリー ネットワークを指します。 論文の中で、Google チームは最初にグラフをテキストとして最適に表現する方法を検討しました。 LLM が理解できるようにするためです。 正しいコーディング手法の助けにより、グラフ問題に対する LLM の精度が大幅に向上します (約 5% から 60% 以上の向上)。 同時に、グラフィックスをテキストに変換するエンコード方法、さまざまなグラフィックスのタスクの種類、グラフィックスの密度構造という 3 つの主な影響要因も決定されました。 これは、LLM がグラフを理解するための始まりにすぎません。新しいベンチマーク GraphQA の助けを借りて、LLM のさらなる可能性を探るためのさらなる研究を楽しみにしています。 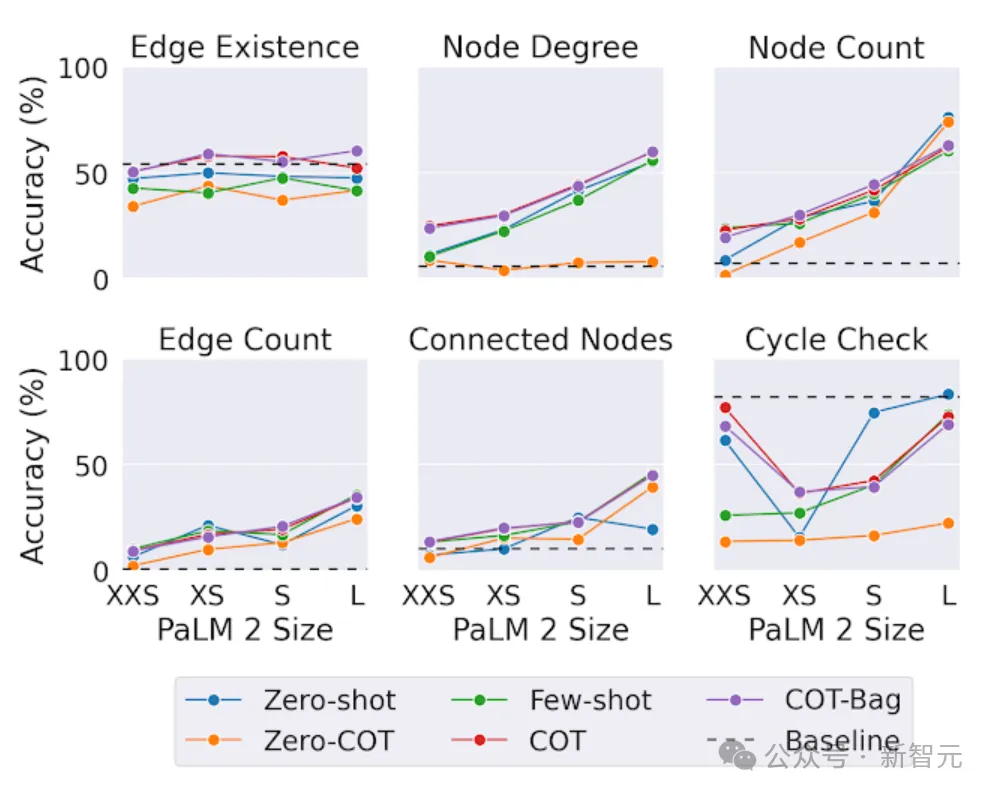

これは LLM にグラフを理解させるためのほんの始まりにすぎません
以上がLLM のパフォーマンスが最大 60% 向上しました。 Google ICLR 2024 の傑作: 大規模言語モデルに「グラフの言語」を学習させようの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。