
ホームページ >テクノロジー周辺機器 >AI >CUDA の汎用行列乗算: 入門から習熟まで!
CUDA の汎用行列乗算: 入門から習熟まで!

- 王林転載
- 2024-03-25 12:30:271307ブラウズ
General Matrix Multiplication (GEMM) は、多くのアプリケーションやアルゴリズムの重要な部分であり、コンピューター ハードウェアのパフォーマンスを評価するための重要な指標の 1 つでもあります。 GEMM の実装に関する徹底的な調査と最適化は、ハイ パフォーマンス コンピューティングとソフトウェア システムとハードウェア システムの関係をより深く理解するのに役立ちます。コンピューター サイエンスでは、GEMM を効果的に最適化すると、計算速度が向上し、リソースが節約されます。これは、コンピューター システムの全体的なパフォーマンスを向上させるために非常に重要です。 GEMM の動作原理と最適化方法を深く理解することは、最新のコンピューティング ハードウェアの可能性をより有効に活用し、さまざまな複雑なコンピューティング タスクに対してより効率的なソリューションを提供するのに役立ちます。 GEMM のパフォーマンスを最適化および改善することで、
##1. GEMM の基本特性
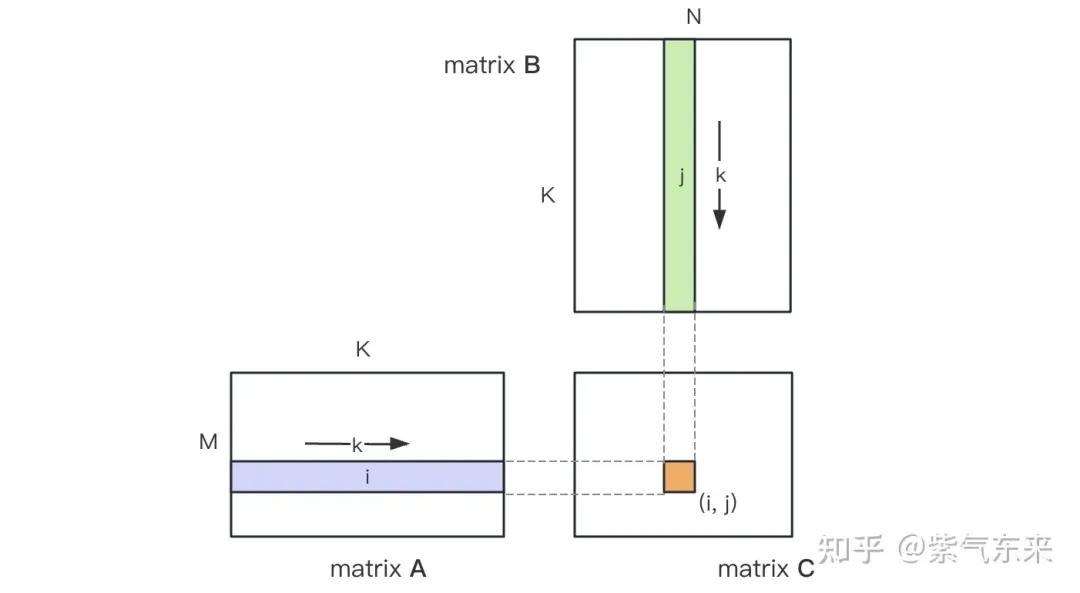
#1.1 GEMM の計算プロセスと複雑さ#GEMM は次のように定義されます:
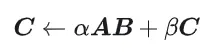

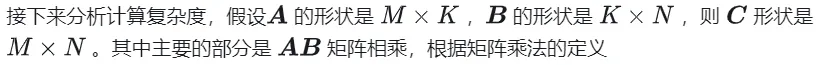
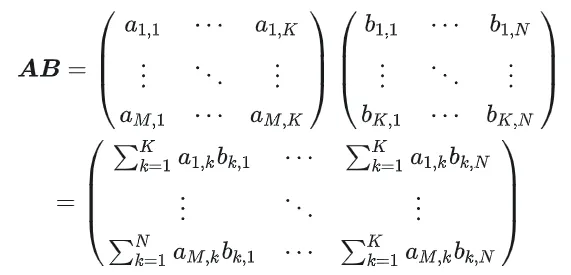


 ##1.2 簡単な実装とプロセス分析
##1.2 簡単な実装とプロセス分析
#以下は元の定義に従って CPU に実装されたコードです。これは後で精度の比較として使用されます###define OFFSET(row, col, ld) ((row) * (ld) + (col))void cpuSgemm(float *a, float *b, float *c, const int M, const int N, const int K) {for (int m = 0; m
以下では CUDA を使用して最も単純なカーナル マトリックスを実装します乗算、合計 M * N スレッドを使用して、行列乗算全体を完了します。各スレッドは行列 C の要素の計算を担当し、K 回の乗算と累算を完了する必要があります。行列 A、B、および C はすべてグローバル メモリに保存されます (修飾子 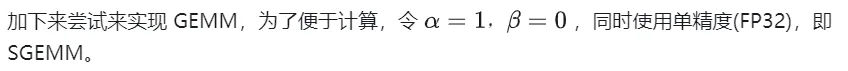
__global__
__global__ void naiveSgemm(float * __restrict__ a, float * __restrict__ b, float * __restrict__ c,const int M, const int N, const int K) {int n = blockIdx.x * blockDim.x + threadIdx.x;int m = blockIdx.y * blockDim.y + threadIdx.y;if (m コンパイルが完了し、Tesla V100-PCIE-32GB で実行した結果は次のとおりです V100 ホワイトペーパーによると、FP32 のピーク演算能力は 15.7 TFLOPS です。したがって、この方法の計算能力使用率はわずか 11.5% です。 うわー
以下では、上記の計算プロセスのワークフローを詳細に分析するために、例として M=512、K=512、N=512 を取り上げます。
- グローバル メモリでは、これらは行列 A、それぞれ B、C に記憶領域を割り当てます。
- 行列 C の各要素の計算は互いに独立しているため、並列マッピングでは、各スレッドは行列 C の 1 つの要素の計算に対応します。
- 実行 実行構成の GridSize と blockSize はどちらも、x (列方向) と y (行方向) の 2 つの次元を持ちます。


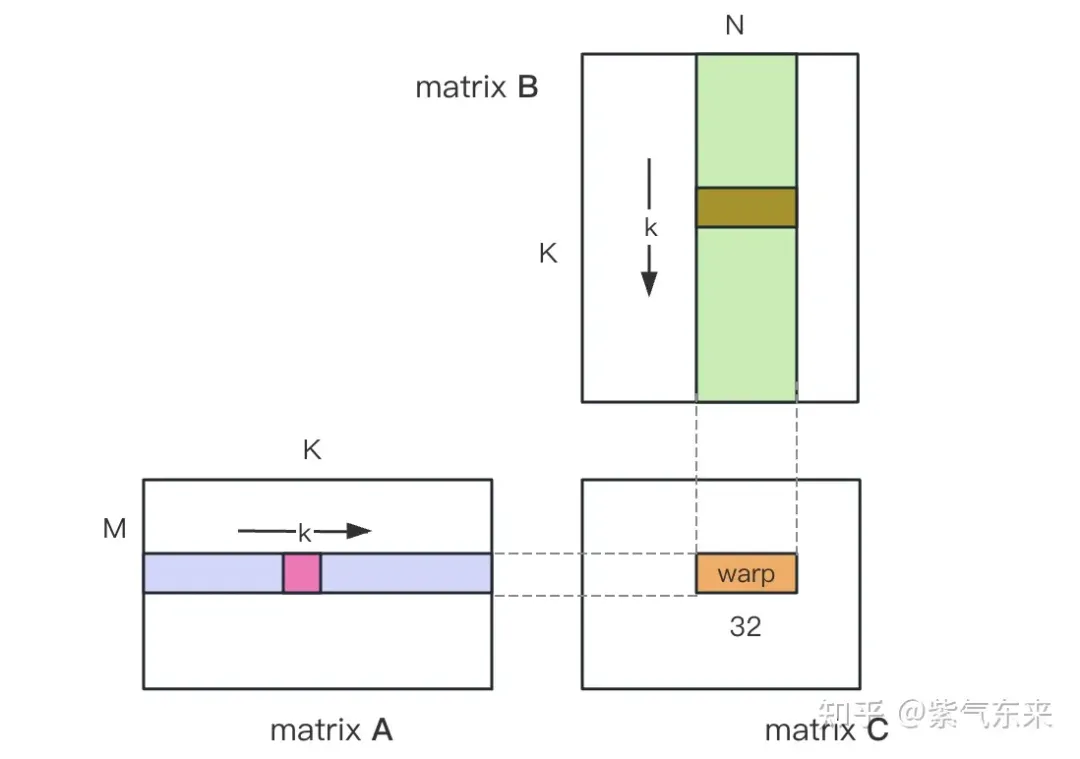


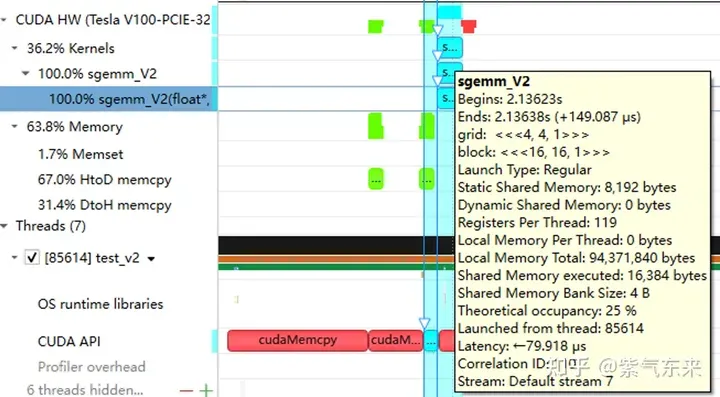
nsys によって記録されたナイーブ バージョンのプロファイリング
2. GEMM 最適化の探索
前回の記事では GEMM を機能的に実装しただけで、そのパフォーマンスは期待とは程遠いものでしたが、このセクションでは主に GEMM のパフォーマンスの最適化について検討します。
2.1 共有メモリを使用した行列分割
上記の計算では、乗算と累積演算を完了するために 2 つのグローバル メモリのロードが必要です。計算メモリのアクセス率は非常に低く、効率的なデータの再利用。したがって、共有メモリを使用すると、メモリ読み取りの繰り返しを減らすことができます。
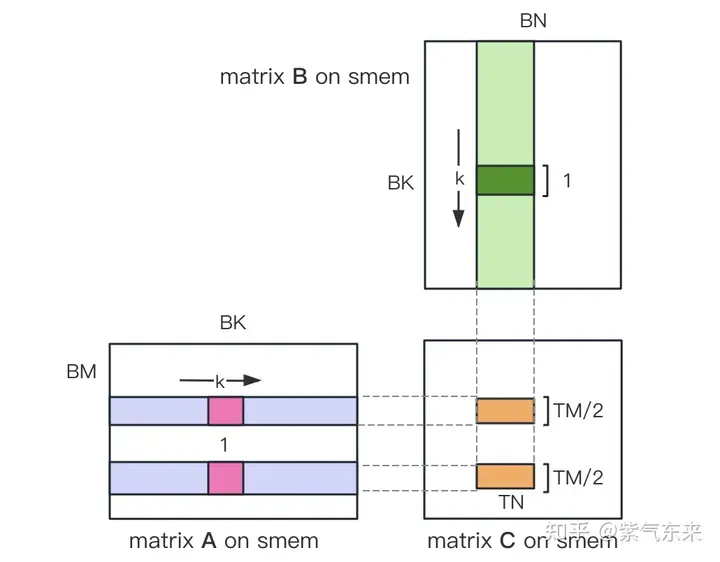
まず行列 C を BMxBN サイズの等しいブロックに分割します。各ブロックはブロックによって計算され、各スレッドは行列 C 内の TMxTN 要素の計算を担当します。その後、計算に必要なすべてのデータが smem から読み取られるため、A 行列と B 行列の繰り返しメモリ読み取りの一部が省略されます。共有メモリの容量が限られていることを考慮すると、BK サイズのブロックは毎回 K 次元で読み込むことができ、このようなループでは行列乗算演算全体を完了するまでに合計 K / BK 回が必要となり、ブロックの結果が得られます。このプロセスを以下の図に示します。
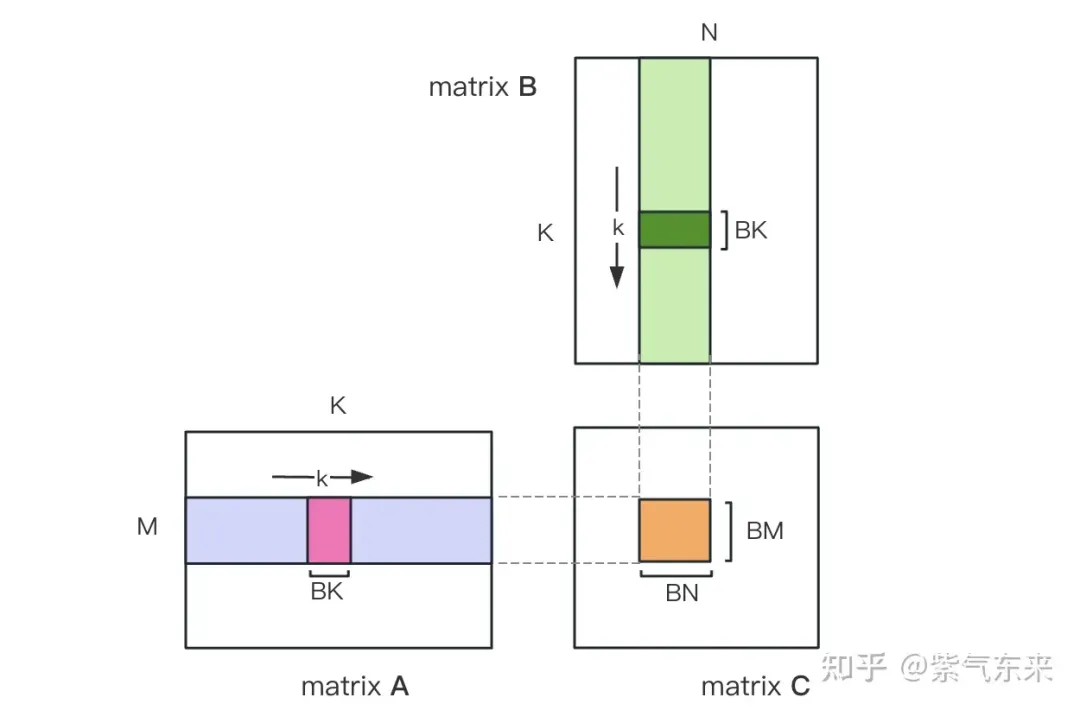
共有メモリを使用した最適化後、ブロックごとに次の結果が得られます。
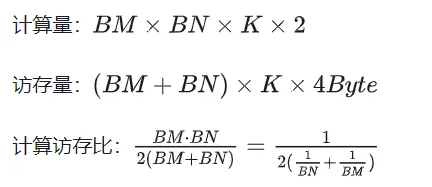
上式より、BMとBNが大きいほど計算メモリのアクセス率が高くなり、性能が良くなることがわかります。ただし、共有メモリ容量の制限 (V100 1 SM は 96KB のみ) のため、ブロックは BK * (BM BN) * 4 バイトを占有する必要があります。
TM と TN の値も 2 つの側面によって制限されます。一方で、スレッド数の制限があります。ブロック内には BM / TM * BN / TN スレッドが存在します。この数は、 1024 を超えることはできず、SM への影響を防ぐために大きすぎることはできません 内部ブロック間の並列性; 一方、レジスタ数には制限があります スレッドは行列の部分和を格納するために少なくとも TM * TN レジスタを必要としますC と他のいくつかのレジスタ。すべてのレジスタの数は 256 を超えることはできず、同時に SM の並列スレッドの数に影響を及ぼさないようにするには、多すぎることはできません。
最後に BM = BN = 128、BK = 8、TM = TN = 8 を選択すると、計算されたメモリ アクセス率は 32 になります。 V100 の理論上の計算能力 15.7TFLOPS によれば、15.7TFLOPS/32 = 490GB/s が得られます。測定された HBM 帯域幅によると 763GB/s であり、帯域幅がこの時点での計算パフォーマンスを制限しないことがわかります。時間。
上記の分析に基づくと、カーネル関数の実装プロセスは次のとおりです。完全なコードについては、sgemm_v1.cu を参照してください。主な手順は次のとおりです。
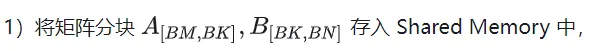

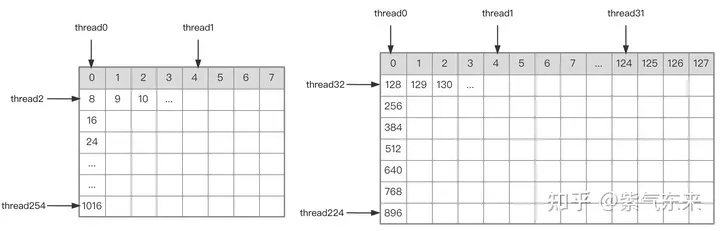
単一ブロックの実行プロセスを決定した後、グローバルメモリ内のマルチブロックで処理される異なるブロック間の対応関係を決定する必要がありますが、説明のための例として引き続き A が使用されます。ブロックは行方向に沿って移動するため、最初に行番号を決定する必要があります。グリッドの 2 次元グローバル線形インデックス関係に従って、by * BM は次のように表されます。ブロックの開始行 同時に、load_a_smem_m がブロック内の行番号であることがわかっているため、グローバル行番号は load_a_gmem_m = by * BMload_a_smem_m となります。 。ブロックが行方向に沿って移動するため、列が変更され、ループ内で計算する必要があります。開始列番号も最初に計算されます bk * BK ブロックの内部列を加速しますブロック No.load_a_smem_k Get load_a_gmem_k = bk * BKload_a_smem_k 、そこからブロックの位置を決定できます。元のデータ内の OFFSET(load_a_gmem_m,load_a_gmem_k,K) の位置。同様に、マトリックス分割状況を分析することができますが、繰り返す必要はありません。

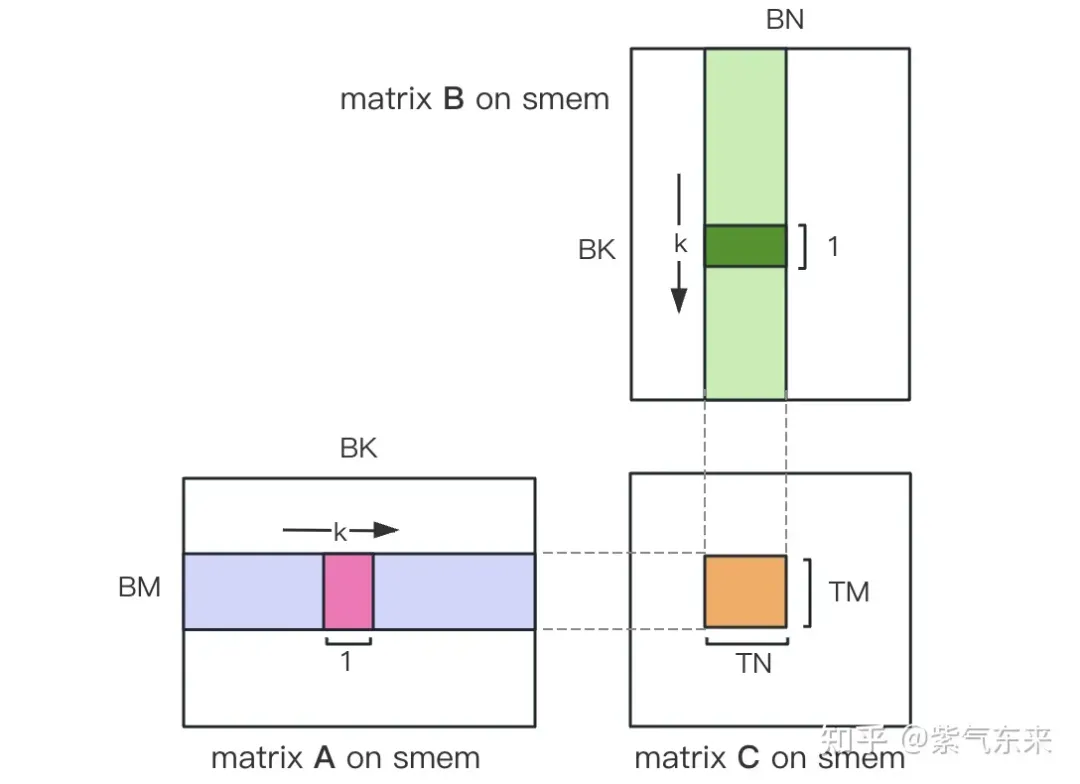
計算が完了したら、グローバル メモリに保存する必要があります。そのためには、グローバル メモリ内の対応関係を計算する必要があります。小さなチャンクが存在するため、行と列は両方とも 3 つの部分で構成されます。グローバル行番号 store_c_gmem_m は、大きなチャンクの開始行番号 by と等しくなります。 * BM 小ブロック ty の開始行番号 * TM 小ブロック i 内の相対行番号。列についても同様です。
M N K =128128 1024, Time = 0.00010083 0.00010260 0.00010874 s, AVG Performance = 304.5951 GflopsM N K =192192 1024, Time = 0.00010173 0.00010198 0.00010253 s, AVG Performance = 689.4680 GflopsM N K =256256 1024, Time = 0.00010266 0.00010318 0.00010384 s, AVG Performance =1211.4281 GflopsM N K =384384 1024, Time = 0.00019475 0.00019535 0.00019594 s, AVG Performance =1439.7206 GflopsM N K =512512 1024, Time = 0.00037693 0.00037794 0.00037850 s, AVG Performance =1322.9753 GflopsM N K =768768 1024, Time = 0.00075238 0.00075558 0.00075776 s, AVG Performance =1488.9271 GflopsM N K = 1024 1024 1024, Time = 0.00121562 0.00121669 0.00121789 s, AVG Performance =1643.8068 GflopsM N K = 1536 1536 1024, Time = 0.00273072 0.00275611 0.00280208 s, AVG Performance =1632.7386 GflopsM N K = 2048 2048 1024, Time = 0.00487622 0.00488028 0.00488614 s, AVG Performance =1639.2518 GflopsM N K = 3072 3072 1024, Time = 0.01001603 0.01071136 0.01099990 s, AVG Performance =1680.4589 GflopsM N K = 4096 4096 1024, Time = 0.01771046 0.01792170 0.01803462 s, AVG Performance =1785.5450 GflopsM N K = 6144 6144 1024, Time = 0.03988969 0.03993405 0.04000595 s, AVG Performance =1802.9724 GflopsM N K = 8192 8192 1024, Time = 0.07119219 0.07139694 0.07160816 s, AVG Performance =1792.7940 GflopsM N K =1228812288 1024, Time = 0.15978026 0.15993242 0.16043369 s, AVG Performance =1800.7606 GflopsM N K =1638416384 1024, Time = 0.28559187 0.28567238 0.28573316 s, AVG Performance =1792.2629 Gflops
計算結果は次のとおりで、パフォーマンスは理論上のピーク パフォーマンスの 51.7% に達します。
以下では、引き続き M=512、K=512、N=512 を例として結果を分析します。まず、プロファイリングを通じて、共有メモリが 8192 バイトを占有していることがわかります。これは理論 (128 128) X8X4 と完全に一致しています。
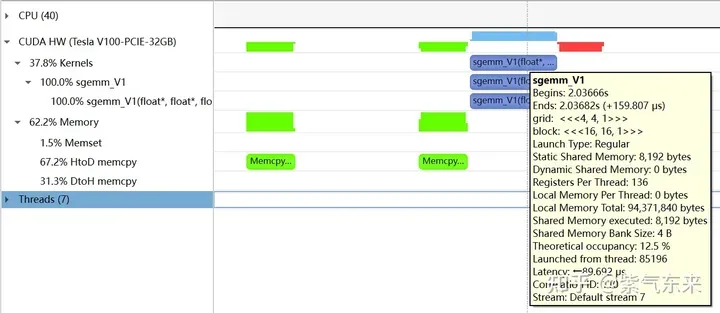 nsys
nsys
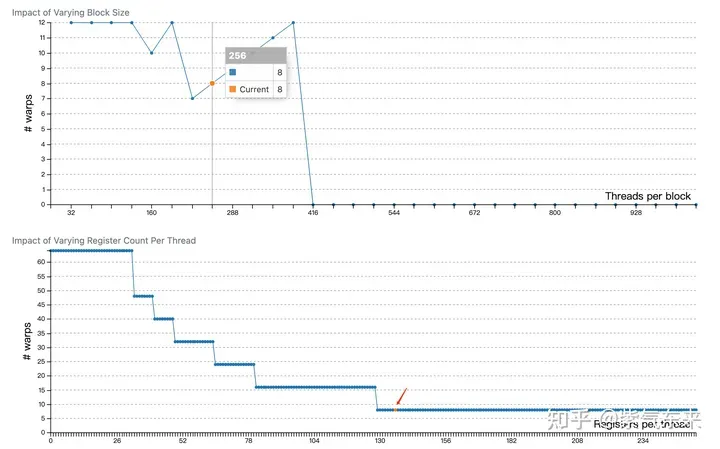
profiling によって記録された V1 バージョンのプロファイリングは、占有率が 12.5% であることを示しており、これは cuda-calculator によって確認できます。この例では、ブロックごとのスレッド = 256、スレッドごとのレジスタ = 136、各 SM のアクティブなワープは 8 であると計算できます。V100 の場合、各 SM のワープの合計数は 64 であるため、占有率は 8/64 = 12.5% となります。
2.2 バンク競合問題の解決
前のセクションでは、共有メモリを使用することでメモリ アクセス効率が大幅に向上し、パフォーマンスが向上しました。このセクションでは、共有メモリの使用をさらに最適化します。
共有メモリは 32 個のバンクに分割されており、各バンクの幅は 4 バイトであるため、同じバンクの複数のデータにアクセスする必要がある場合、バンク競合が発生します。たとえば、ワープに 32 のスレッドがあり、アクセスされたアドレスが 0、4、8、...、124 の場合、バンク競合は発生せず、共有メモリの 1 ビートだけが占有されます。は 0、8、16、...、248 であるため、アドレス 0 とアドレス 128 に対応するデータは同じバンクに配置され、アドレス 4 とアドレス 132 に対応するデータは同じバンクに配置されます。 、その後、読み出すのに共有メモリ時間が 2 ビートかかります。
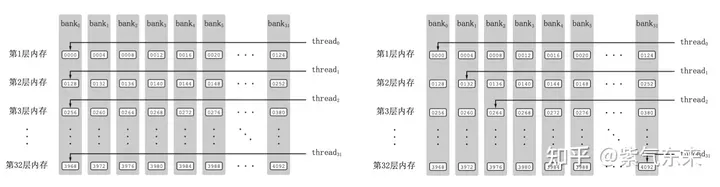
バンク競合あり VS バンク競合なし
V1 バージョンの計算部分の 3 層ループを見てみましょう。行列 A の は共有メモリから取得されます。 は TM のベクトルであり、行列 B の長さ TN のベクトルです。これら 2 つのベクトルは外積を実行し、部分和に累積されます。1 つの外積は TM * TN 回の合計です乗算と累算の合計 BK 回のカウントと外積をループする必要があります。
次に、共有メモリのロード処理中に存在するバンク競合を分析します。
i) 行列 A を取得するには、列ベクトルを取得する必要があります。行列 A は行ごとに格納されます。 ;
ii) TM = TN = 8 の場合、行列 A または行列 B に関係なく、共有メモリから数値をフェッチするときは、8 つの連続する数値をフェッチする必要があります。 LDS.128 命令を使用して 1 つの命令でフェッチする 4 つの数値も 2 つの命令が必要 1 つのスレッド内の 2 つのロード命令のアドレスは連続しているため、同じ Warp の異なるスレッドにおける同じロード命令のメモリ アクセス アドレスは分離されます。そして銀行紛争が発生しています。
共有メモリのバンク競合の上記 2 点を解決するために、2 つの最適化点が採用されます。
i) 行列 A に共有メモリを割り当てるとき、形状は [BK として割り当てられます。 ][BM]、つまり、行列 A を共有メモリに列ごとに格納します
ii) 各スレッドが計算する TM * TN 行列 C を下図のように 2 つの TM/2 * TN 行列 C に分割します TM/2=4 なので 1 命令で完了しますロード操作では、2 つのロードを同時に実行できます。
#カーネル関数のコア部分は次のように実装されています。完全なコードについては、sgemm_v2.cu を参照してください。
__global__ void sgemm_V1(float * __restrict__ a, float * __restrict__ b, float * __restrict__ c,const int M, const int N, const int K) {const int BM = 128;const int BN = 128;const int BK = 8;const int TM = 8;const int TN = 8;const int bx = blockIdx.x;const int by = blockIdx.y;const int tx = threadIdx.x;const int ty = threadIdx.y;const int tid = ty * blockDim.x + tx;__shared__ float s_a[BM][BK];__shared__ float s_b[BK][BN];float r_c[TM][TN] = {0.0};int load_a_smem_m = tid >> 1;// tid/2, row of s_aint load_a_smem_k = (tid & 1) > 5; // tid/32, row of s_bint load_b_smem_n = (tid & 31) 結果は以下の通りで、未解決の Bank Conflict バージョン (V1) と比較して、パフォーマンスが 14.4% 向上し、理論上のピークの 74.3% に達しました。
M N K =128128 1024, Time = 0.00031578 0.00031727 0.00032288 s, AVG Performance =98.4974 GflopsM N K =192192 1024, Time = 0.00031638 0.00031720 0.00031754 s, AVG Performance = 221.6661 GflopsM N K =256256 1024, Time = 0.00031488 0.00031532 0.00031606 s, AVG Performance = 396.4287 GflopsM N K =384384 1024, Time = 0.00031686 0.00031814 0.00032080 s, AVG Performance = 884.0425 GflopsM N K =512512 1024, Time = 0.00031814 0.00032007 0.00032493 s, AVG Performance =1562.1563 GflopsM N K =768768 1024, Time = 0.00032397 0.00034419 0.00034848 s, AVG Performance =3268.5245 GflopsM N K = 1024 1024 1024, Time = 0.00034570 0.00034792 0.00035331 s, AVG Performance =5748.3952 GflopsM N K = 1536 1536 1024, Time = 0.00068797 0.00068983 0.00069094 s, AVG Performance =6523.3424 GflopsM N K = 2048 2048 1024, Time = 0.00136173 0.00136552 0.00136899 s, AVG Performance =5858.5604 GflopsM N K = 3072 3072 1024, Time = 0.00271910 0.00273115 0.00274006 s, AVG Performance =6590.6331 GflopsM N K = 4096 4096 1024, Time = 0.00443805 0.00445964 0.00446883 s, AVG Performance =7175.4698 GflopsM N K = 6144 6144 1024, Time = 0.00917891 0.00950608 0.00996963 s, AVG Performance =7574.0999 GflopsM N K = 8192 8192 1024, Time = 0.01628838 0.01645271 0.01660790 s, AVG Performance =7779.8733 GflopsM N K =1228812288 1024, Time = 0.03592557 0.03597434 0.03614323 s, AVG Performance =8005.7066 GflopsM N K =1638416384 1024, Time = 0.06304122 0.06306373 0.06309302 s, AVG Performance =8118.7715 Gflops
プロファイリングを分析すると、静的共有メモリが依然として 8192 バイトを使用していることがわかります。奇妙なのは、実行された共有メモリが 2 倍の 16384 バイトになっていることです (ご存知の場合は教えていただけますか)理由)。
#2.3 パイプライン並列化: ダブル バッファリング
ダブル バッファリング、つまりバッファを増やすことによって、そのためメモリアクセス計算 のシリアルモードは待ち時間を短縮し、計算効率を向上させるためにパイプライン化されており、その原理は次の図に示されています:
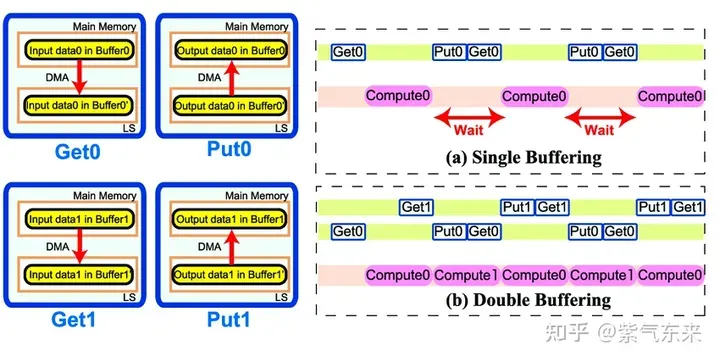
bk = 1 から始まります。最初のデータ ロードはメイン ループの前にあり、最後のデータ ロードはメイン ループの前にあります。計算はメインループの後にあります。ループの後はパイプラインの特性によって決まります;
__shared__ float s_a[BK][BM];__shared__ float s_b[BK][BN];float r_load_a[4];float r_load_b[4];float r_comp_a[TM];float r_comp_b[TN];float r_c[TM][TN] = {0.0};int load_a_smem_m = tid >> 1;int load_a_smem_k = (tid & 1) > 5;int load_b_smem_n = (tid & 31) <div></div>パフォーマンスは以下に示されており、理論上のピークの 80.6% に達しています。 <p></p>うわー<div>
<p>プロファイリングから、共有メモリの占有が 2 倍であることがわかります</p>
<p style="text-align:center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/465/014/171134103391361.jpg" class="lazy" alt="CUDA の汎用行列乗算: 入門から習熟まで!"></p>
<h3><span>3. cuBLAS 実装の調査</span></h3>
<p>このセクションでは、 CUDA の標準ライブラリである cuBLAS (Basic Linear Algebra Subprograms (BLAS) 仕様の実装コードの NVIDIA バージョン) について学びます。レベル 1 (ベクトルとベクトル演算)、レベル 2 (ベクトルと行列演算)、およびレベル 3 (行列と行列演算) の標準行列演算をサポートします。 </p>
<p style="text-align:center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/465/014/171134103377810.jpg" class="lazy" alt="CUDA の汎用行列乗算: 入門から習熟まで!"></p>
<p style="text-align: center;">cuBLAS/CUTLASS GEMM の基本プロセス</p>
<p>上図に示すように、計算プロセスは <strong>スレッド ブロック タイルに分解されます</strong>(スレッド ブロック タイル)、<strong>スレッド バンドル ピース</strong>(ワープ タイル)、<strong>スレッド ピース</strong>(スレッド タイル)の階層構造を作成し、AMP の戦略をこの階層構造に適用して、GPU ベースのティアダウンを効率的に完了します。 . タイルに分割されたGEMM。この階層は、NVIDIA CUDA プログラミング モデルを厳密に反映しています。グローバル メモリから共有メモリへのデータ移動 (行列からスレッド ブロック タイル)、共有メモリからレジスタへのデータ移動 (スレッド ブロック タイルからワープ タイル)、レジスタから CUDA コアへの計算 (ワープ タイルからスレッド タイル) を確認できます。 </p>
<p>cuBLAS は、単精度行列乗算関数 cublasSgemm を実装します。その主なパラメータは次のとおりです: </p>
<div><pre class="brush:php;toolbar:false">M N K =128128 1024, Time = 0.00029699 0.00029918 0.00030989 s, AVG Performance = 104.4530 GflopsM N K =192192 1024, Time = 0.00029776 0.00029828 0.00029882 s, AVG Performance = 235.7252 GflopsM N K =256256 1024, Time = 0.00029485 0.00029530 0.00029619 s, AVG Performance = 423.2949 GflopsM N K =384384 1024, Time = 0.00029734 0.00029848 0.00030090 s, AVG Performance = 942.2843 GflopsM N K =512512 1024, Time = 0.00029853 0.00029945 0.00030070 s, AVG Performance =1669.7479 GflopsM N K =768768 1024, Time = 0.00030458 0.00032467 0.00032790 s, AVG Performance =3465.1038 GflopsM N K = 1024 1024 1024, Time = 0.00032406 0.00032494 0.00032621 s, AVG Performance =6155.0281 GflopsM N K = 1536 1536 1024, Time = 0.00047990 0.00048224 0.00048461 s, AVG Performance =9331.3912 GflopsM N K = 2048 2048 1024, Time = 0.00094426 0.00094636 0.00094992 s, AVG Performance =8453.4569 GflopsM N K = 3072 3072 1024, Time = 0.00187866 0.00188096 0.00188538 s, AVG Performance =9569.5816 GflopsM N K = 4096 4096 1024, Time = 0.00312589 0.00319050 0.00328147 s, AVG Performance = 10029.7885 GflopsM N K = 6144 6144 1024, Time = 0.00641280 0.00658940 0.00703498 s, AVG Performance = 10926.6372 GflopsM N K = 8192 8192 1024, Time = 0.01101130 0.01116194 0.01122950 s, AVG Performance = 11467.5446 GflopsM N K =1228812288 1024, Time = 0.02464854 0.02466705 0.02469344 s, AVG Performance = 11675.4946 GflopsM N K =1638416384 1024, Time = 0.04385955 0.04387468 0.04388355 s, AVG Performance = 11669.5995 Gflops呼び出しメソッドは次のとおりです:
__shared__ float s_a[2][BK][BM];__shared__ float s_b[2][BK][BN];float r_load_a[4];float r_load_b[4];float r_comp_a[TM];float r_comp_b[TN];float r_c[TM][TN] = {0.0};int load_a_smem_m = tid >> 1;int load_a_smem_k = (tid & 1) > 5;int load_b_smem_n = (tid & 31)
パフォーマンスは以下に示されており、理論上のピークの 82.4% に達しています。
M N K =128128 1024, Time = 0.00024000 0.00024240 0.00025792 s, AVG Performance = 128.9191 GflopsM N K =192192 1024, Time = 0.00024000 0.00024048 0.00024125 s, AVG Performance = 292.3840 GflopsM N K =256256 1024, Time = 0.00024029 0.00024114 0.00024272 s, AVG Performance = 518.3728 GflopsM N K =384384 1024, Time = 0.00024070 0.00024145 0.00024198 s, AVG Performance =1164.8394 GflopsM N K =512512 1024, Time = 0.00024173 0.00024237 0.00024477 s, AVG Performance =2062.9786 GflopsM N K =768768 1024, Time = 0.00024291 0.00024540 0.00026010 s, AVG Performance =4584.3820 GflopsM N K = 1024 1024 1024, Time = 0.00024534 0.00024631 0.00024941 s, AVG Performance =8119.7302 GflopsM N K = 1536 1536 1024, Time = 0.00045712 0.00045780 0.00045872 s, AVG Performance =9829.5167 GflopsM N K = 2048 2048 1024, Time = 0.00089632 0.00089970 0.00090656 s, AVG Performance =8891.8924 GflopsM N K = 3072 3072 1024, Time = 0.00177891 0.00178289 0.00178592 s, AVG Performance = 10095.9883 GflopsM N K = 4096 4096 1024, Time = 0.00309763 0.00310057 0.00310451 s, AVG Performance = 10320.6843 GflopsM N K = 6144 6144 1024, Time = 0.00604826 0.00619887 0.00663078 s, AVG Performance = 11615.0253 GflopsM N K = 8192 8192 1024, Time = 0.01031738 0.01045051 0.01048861 s, AVG Performance = 12248.2036 GflopsM N K =1228812288 1024, Time = 0.02283978 0.02285837 0.02298272 s, AVG Performance = 12599.3212 GflopsM N K =1638416384 1024, Time = 0.04043287 0.04044823 0.04046151 s, AVG Performance = 12658.1556 Gflops
上記の方法のパフォーマンスを比較すると、次のように手動実装のパフォーマンスが公式のパフォーマンスに近いことがわかります。
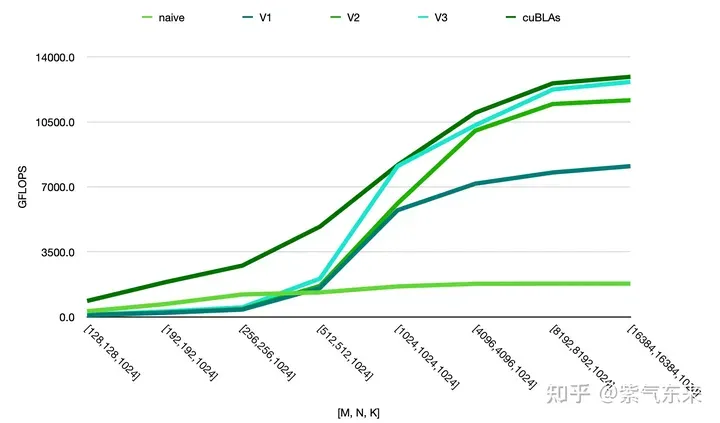
##
以上がCUDA の汎用行列乗算: 入門から習熟まで!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。