
ホームページ >テクノロジー周辺機器 >AI >Sora はオープンソースではありません。Microsoft がオープンソース化します。 12 秒でリアルで爆発的なエフェクトを備えた、世界で最も近いソラ ビデオ モデルが誕生
Sora はオープンソースではありません。Microsoft がオープンソース化します。 12 秒でリアルで爆発的なエフェクトを備えた、世界で最も近いソラ ビデオ モデルが誕生

- PHPz転載
- 2024-03-22 23:10:32770ブラウズ
Microsoft バージョンの Sora が誕生しました!
Sora は人気がありますが、クローズド ソースであるため、学術コミュニティに大きな課題をもたらしています。学者は、リバース エンジニアリングを使用して Sora を再現または拡張することしか試みることができません。
Diffusion Transformer と空間パッチ戦略が提案されていますが、コンピューティング能力とデータセットの不足は言うまでもなく、Sora のパフォーマンスを達成することは依然として困難です。
しかし、ソラを再現するために研究者によって開始された新たな突撃の波が来ています!
たった今、リーハイ大学は Microsoft チームと協力して、新しいマルチ AI エージェント フレームワークである Mora を開発しました。

論文アドレス: https://arxiv.org/abs/2403.13248
はい、リーハイ大学とマイクロソフトのアイデアは、AI エージェントに依存することです。
Mora は、Sora のジェネラリストビデオ世代に近いです。複数のSOTAビジュアルAIエージェントを統合することで、Soraが実証したユニバーサルビデオ生成機能を再現できます。

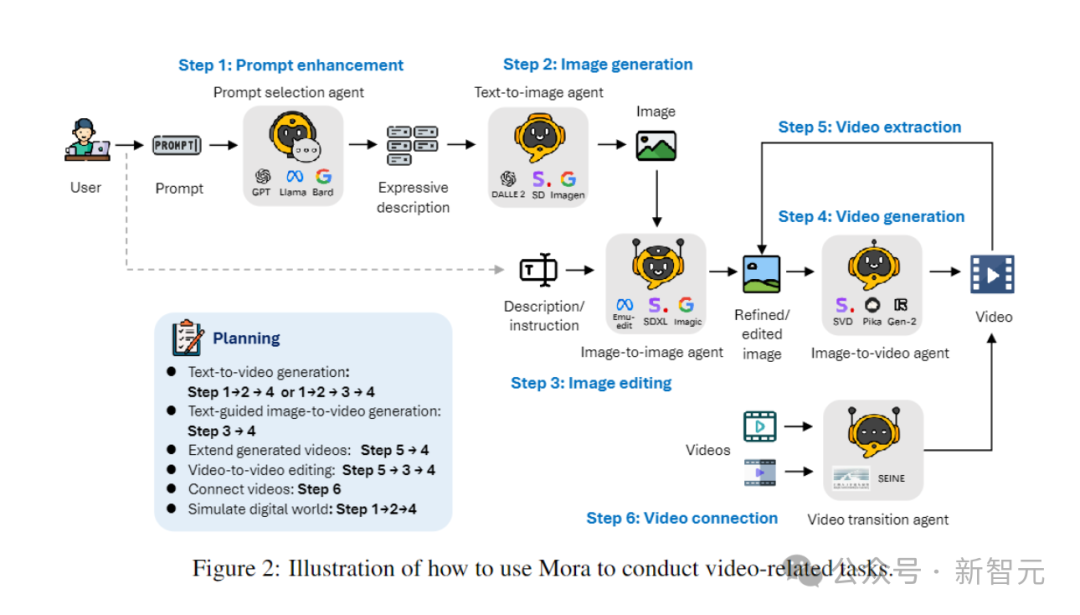
具体的には、Mora は複数のビジュアル エージェントを利用して、次のようなさまざまなタスクで Sora のビデオ生成機能を適切にシミュレートできます。
#- テキストからビデオへの生成
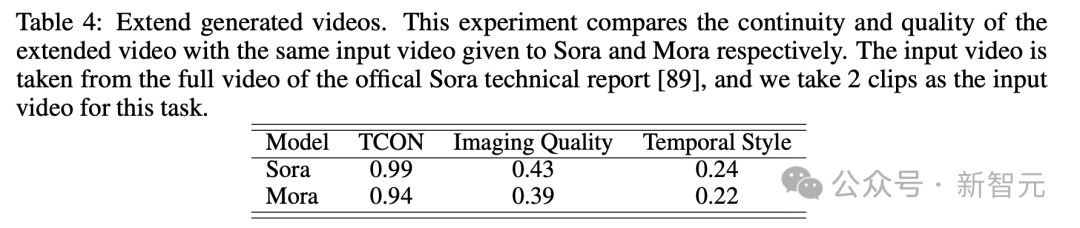
##- テキスト条件に基づいた画像からビデオへの生成##- 生成されたビデオを拡張する
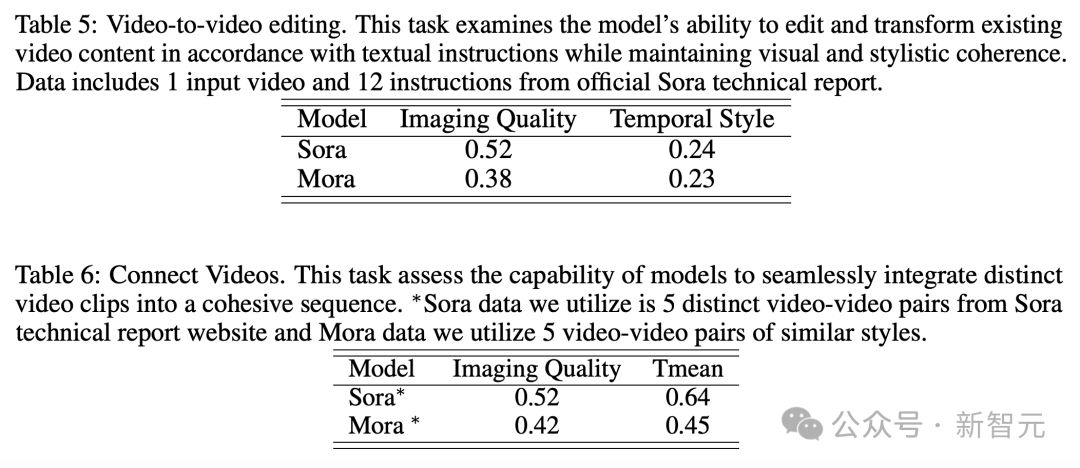
#- ビデオからビデオの編集
- ビデオをステッチ
#- シミュレーション デジタル ワールド
実験結果は、Mora がこれらのタスクで Sora に近いパフォーマンスを達成することを示しています。 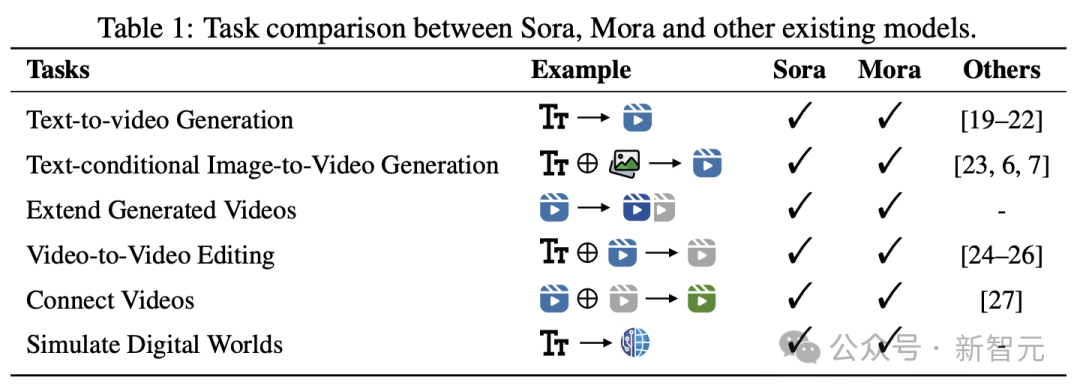
テキストからビデオへの生成タスクにおけるパフォーマンスが既存のオープンソース モデルを上回り、全モデルの中で Sora に次いで 2 位にランクされていることは注目に値します。
しかし、総合的なパフォーマンスという点では、ソラとはまだ明らかな差があります。
Mora は、テキスト プロンプトに基づいて、解像度 1024 × 576、持続時間 12 秒の高解像度の時間一貫性のあるビデオを生成できます。 、合計 75 フレーム。 
ソラの能力をすべて回復する
モラは基本的にソラの能力をすべて回復します。テキストからビデオへの生成
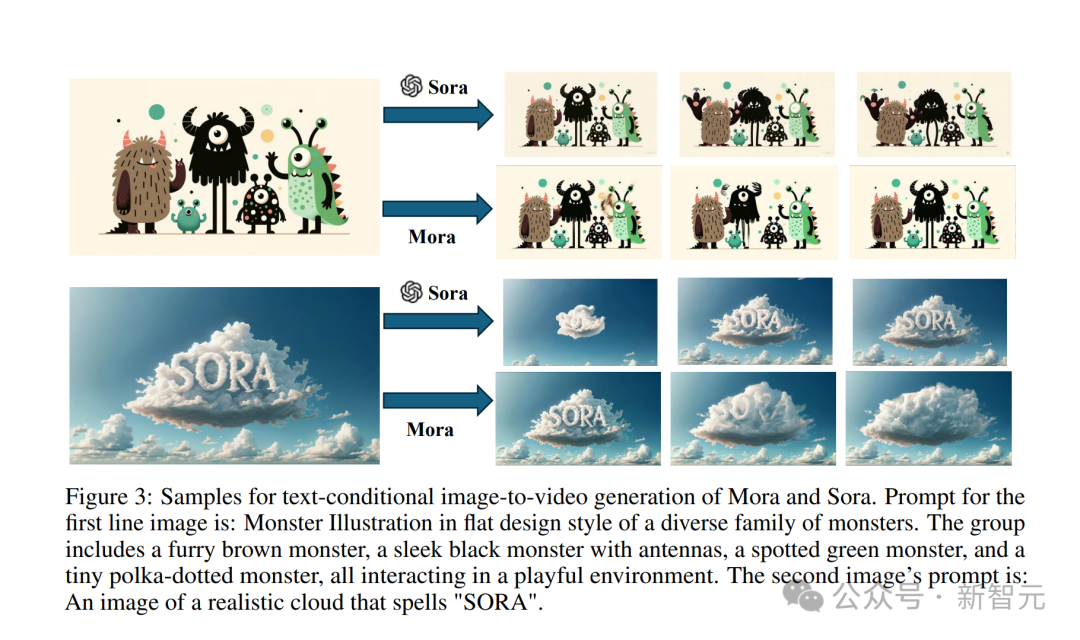
ヒント: 透き通った青い海の下、生命があふれる活気に満ちたサンゴ礁。サンゴの間を泳ぐ色とりどりの魚、水面から差し込む太陽の光、そして穏やかな流れが海の植物を動かします。 ヒント: 雪に覆われた雄大な山脈、その頂上は雲に接し、透き通った湖があります。 ## ヒント: 広大な砂漠の真ん中、黄金色の砂漠都市は地平線上に現れ、その建築は古代エジプトと未来の要素が融合したものです。都市は放射エネルギー障壁に囲まれ、空中では # に基づいています。テキスト条件付き画像からビデオの生成 この古典的な「SORA という単語が付いた現実的な雲の画像」を入力します。 ヒント: 「SORA」と綴るリアルな雲のイメージ。 Sora モデルの生成効果はこんな感じです。 Mora によって生成されたビデオはまったく悪くありません。 小さなモンスターの写真も入力してください。 ヒント: モンスターの多様なファミリーをフラット デザイン スタイルで表現したモンスターのイラスト。このグループには、毛皮で覆われた茶色のモンスター、アンテナを持つ滑らかな黒いモンスターが含まれます。 、まだら模様の緑色のモンスター、そして小さな水玉模様のモンスターが、遊び心のある環境で相互作用しています。 Sora は、これらの小さなモンスターを生き生きとさせるために、それをビデオ効果に変換しました。 モーラは小さなモンスターも動かしますが、明らかに少し不安定で、絵の中の漫画のキャラクターは一貫して見えません。 #生成されたビデオを展開します 最初にビデオを提供します #Sora は、一貫したスタイルで安定した AI ビデオを生成できます。 #しかし、Mora によって生成されたビデオでは、前の自転車に乗っていた人が自転車を失い、人が変形したため、効果はありませんでした。とても良い。 ビデオ ビデオ エディター プロンプトを表示して「シーン 1920 年代のビンテージ カーに切り替えて、ビデオを入力します。 #Sora のスタイルを置き換えた後、全体的な外観は非常に滑らかになりました。 #モーラ 旧式の車の世代は、あまりにもみすぼらしいので、少し現実的ではありません。 #ビデオの結合
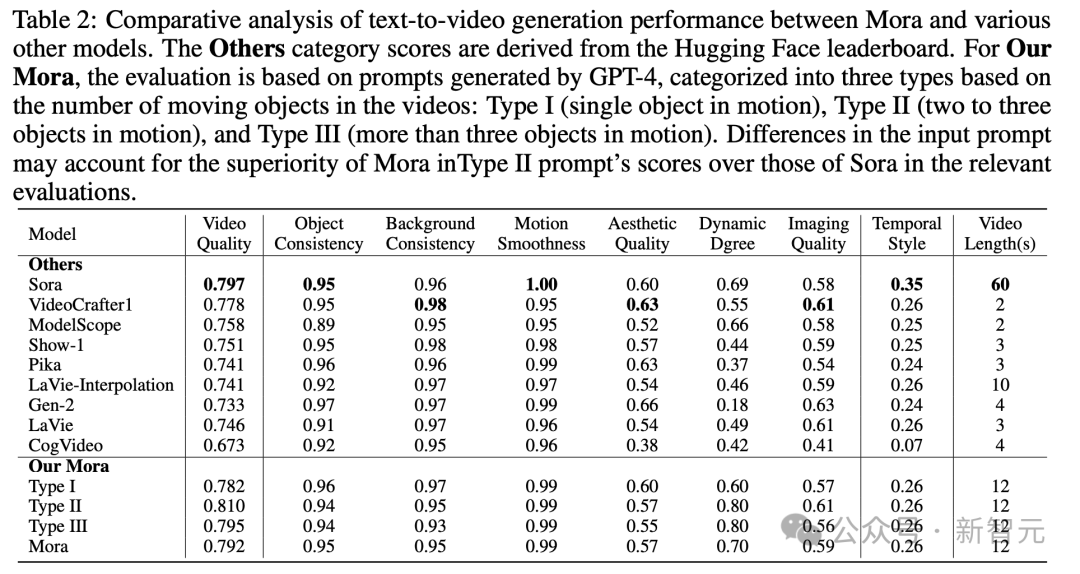
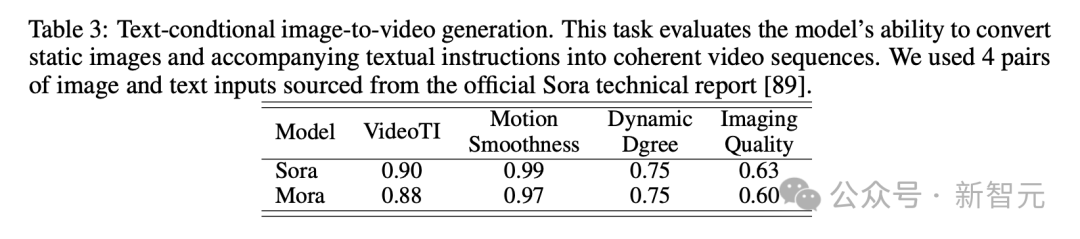
Analog Digital World 数多くのデモを経て、誰もが Mora のビデオ生成機能をある程度理解できるようになりました。 OpenAI Sora と比較すると、6 つのタスクにおける Mora のパフォーマンスは非常に近いですが、大きな欠点もあります。 テキストからビデオへの生成 具体的には、Mora のビデオ品質スコア 0.792 は、最初の Sora のビデオ品質スコアに次ぐ 2 番目でした。 0.797 であり、現在最高のオープン ソース モデル (VideoCrafter1 など) を上回っています。 オブジェクトの一貫性に関しては、Mora のスコアは 0.95 で、Sora と同じで、ビデオ全体にわたって優れた一貫性を示しています。 下の画像では、Mora のテキストからビデオへの生成の視覚的な忠実度が非常に際立っており、高解像度の画像と次の点への注意が反映されています。細部までこだわり、現場を生き生きと描写。 テキスト条件に基づく画像生成タスクでは、画像とテキスト命令を一貫したものに変換する能力の点で、Sora は間違いなく最高のモデルです。ビデオ、完璧です。 しかし、Mora の結果は Sora の結果とは大きく異なります。 #拡張機能で生成されたビデオ 拡張世代のビデオテストを見ると、継続性と品質の点でも、Moraは比較的Soraに近い結果になっています。 Sora のリードにもかかわらず、Mora の能力、特に時系列スタイルに従い、品質を大幅に損なうことなく既存のビデオを拡張する能力は、次の分野でその有効性を証明しました。ビデオの拡張子。 ビデオ to ビデオ編集ビデオ スティッチング ビデオ to ビデオ編集の場合、Mora はビジュアルとビデオを維持します。文体の一貫性という点ではソラに近い。ビデオの結合タスクでは、Mora はさまざまなビデオをシームレスに結合することもできます。 この例では、ソラとモーラの両方が、車の赤色を維持しながら設定を 1920 年代スタイルに変更するように指示されました。 アナログデジタルワールド デジタル世界をシミュレートするという最後のタスクもあり、Mora には Sora のような仮想環境の世界を作成する機能もあります。ただし、品質に関してはソラよりも劣ります。 Mora はマルチエージェント フレームワークです、現在のビデオ生成モデルの制限を解決するにはどうすればよいでしょうか? ユーザーの多様なニーズに応えるために、動画生成プロセスを複数のサブタスクに分解し、それぞれのタスクに専任のエージェントを配置することで、一連の動画生成タスクを柔軟に完了することがポイントです。 推論プロセス中に、Mora は中間画像またはビデオを生成することで、テキストから画像へのモデルに見られる視覚的な多様性、スタイル、品質を維持し、編集機能を強化します。 テキストから画像、画像から画像、画像からビデオ、ビデオからビデオへの変換タスクの処理を効率的に調整することによるインテリジェンス全体として、Mora はさまざまな複雑なビデオ生成タスクを処理でき、優れた編集の柔軟性と視覚的なリアリズムを提供します。 要約すると、チームの主な貢献は次のとおりです: #- 革新的なマルチエージェント フレームワークと直感的なインターフェイスにより、ユーザーはさまざまなコンポーネントを構成し、タスク プロセスを調整することが容易になります。 #- Mora は 6 つのビデオ関連タスクで優れたパフォーマンスを実証し、既存のオープンソース モデルを上回りました。これは、Mora の効率性を証明するだけでなく、多目的フレームワークとしての可能性も示しています。 エージェントの定義 この目的のために、著者は 5 つの基本タイプのエージェントを定義します: プロンプトの選択と生成、テキストから画像への生成、画像から画像への生成、画像からビデオへの生成、ビデオ間の生成。
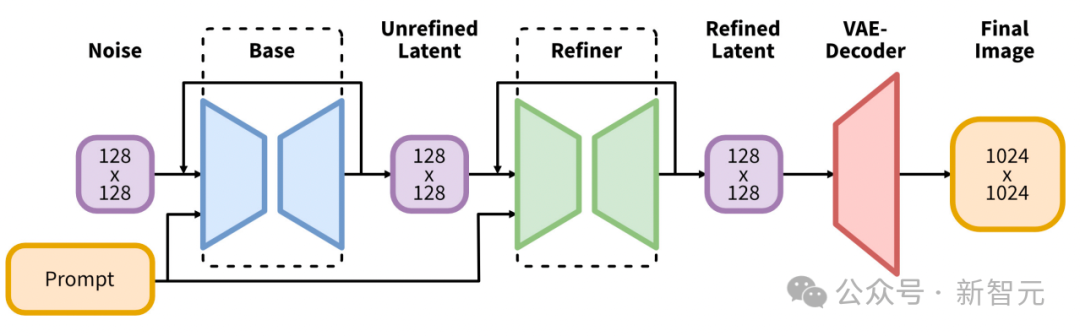
初期イメージの生成を開始する前のテキスト プロンプト一連の厳密な処理と最適化のステップを経ます。このエージェントは、大規模な言語モデル (GPT-4 など) を活用してテキストを正確に分析し、重要な情報とアクションを抽出し、生成される画像の関連性と品質を大幅に向上させることができます。 - テキストから画像への生成エージェント: このエージェントは、リッチ テキストの説明を高品質の画像に変換する役割を果たします。その中心的な機能は、複雑なテキスト入力を深く理解して視覚化し、提供されたテキストの説明に基づいて詳細で正確な視覚イメージを作成できるようにすることです。 #- イメージからイメージへの生成エージェント: 特定のテキスト命令に基づいて既存のソース イメージを変更します。テキストの合図を正確に解釈し、微妙な変更から完全な変換まで、それに応じてソース画像を調整します。事前トレーニングされたモデルを使用することで、テキストの説明と視覚的表現を効果的につなぎ合わせることができ、新しい要素の統合、視覚スタイルの調整、または画像構成の変更が可能になります。 #- 画像からビデオへの生成エージェント: 最初の画像生成の後、このエージェントは、静的な画像を動的なビデオに変換する役割を果たします。最初の画像の内容とスタイルを分析して後続のフレームを生成し、ビデオの一貫性と視覚的な一貫性を確保します。これにより、最初の画像を理解し、複製し、シーンの論理展開を予測して実装するモデルの能力が実証されます。 -ビデオ スプライシング エージェント: このエージェントは、2 つのビデオのキー フレームを選択的に使用することにより、それらの間の滑らかさと視覚的に一貫したトランジションを保証します。 2 つのビデオに共通する要素とスタイルを正確に識別し、一貫性と視覚的に魅力的なビデオを作成します。 テキストから画像への生成 研究者は事前トレーニング A を使用します高品質で代表的な最初の画像を生成するための大きなテキストから画像へのモデル。 最初の実装では、Stable Diffusion XL を使用します。 テキストから画像への合成のための潜在拡散モデルのアーキテクチャと手法に大きな進化が導入され、この分野で新たなベンチマークが設定されます。 。 そのアーキテクチャの中核となるのは、Stable Diffusion 2 の以前のバージョンで使用されていたバックボーンよりも 3 倍大きい、拡張された UNet バックボーン ネットワークです。 この拡張は主に、アテンション ブロックの数とより広範囲のクロスアテンション コンテキストを増やし、バイテキスト エンコーダを統合することによって実現されます。促進するシステム。 最初のエンコーダーは OpenCLIP ViT-bigG に基づいており、2 番目のエンコーダーは CLIP ViT-L を利用しており、これらのエンコーダーの出力を結合することでテキスト入力を変更できます。よりニュアンスのある説明。 このアーキテクチャ上の革新は、外部の監視を必要としないさまざまな新しい調整スキームの導入によって補完され、モデルの柔軟性が向上します。複数のアスペクト比にわたる画像を生成する機能。 さらに、SDXL は、生成された画像の視覚的な品質を向上させるために、ポストホックな画像間の変換を採用する改良モデルを備えています。 この調整プロセスでは、ノイズ除去テクノロジーを利用して、生成プロセスの効率や速度に影響を与えることなく、出力画像をさらに調整します。 画像から画像の生成 このプロセスでは、研究者は初期フレームワークを使用して InstructPix2Pix As を実装しました。画像から画像への生成エージェント。 InstructPix2Pix は、自然言語命令に基づいて効果的な画像編集ができるように慎重に設計されています。 システムのコアは、2 つの事前トレーニングされたモデルの広範な知識を統合します: GPT-3 は、テキストの説明に基づいて編集指示と編集されたタイトルを生成するために使用され、Stable Diffusion は、これらを組み合わせると、テキストベースの入力が視覚的な出力に変換されます。 この独創的なアプローチでは、まず、画像キャプションと対応する編集手順の厳選されたデータセットに基づいて GPT-3 を微調整し、その結果、賢明な編集を創造的に提案し、修正されたキャプションを生成できるモデルが得られます。 この後、プロンプトツープロンプト技術によって強化された安定拡散モデルは、GPT-3 によって生成された字幕に基づいて画像ペア (編集前と編集後) を生成します。 次に、生成されたデータセットで InstructPix2Pix コアの条件付き拡散モデルをトレーニングします。 InstructPix2Pix は、テキスト命令と入力画像を直接利用して、単一の前方パスで編集を実行します。 この効率は、画像と命令条件に分類子を使用しないガイダンスを採用することでさらに向上し、モデルが生の画像の忠実性と編集命令への準拠のバランスを取ることが可能になります。 #画像からビデオへの生成 #テキストからビデオへの生成エージェントでは、ビデオ生成エージェントは、ビデオの品質と一貫性が重要な役割を果たすことを保証します。 研究者による最初の実装は、現在の SOTA ビデオ生成モデルである Stable Video Diffusion を使用してビデオを生成することです。 SVD アーキテクチャは、もともと画像合成用に開発された LDM である Stable Diffusion v2.1 の強みを活用し、固有の時間を処理するためにその機能を拡張しています。したがって、高解像度ビデオを生成するための高度な方法が導入されます。 SVD モデルの中核は、テキストと画像の関連付けから始まる 3 段階のトレーニング システムに従い、モデルはさまざまな画像のセットから堅牢な視覚表現を学習します。この基盤により、モデルは複雑な視覚的パターンとテクスチャを理解して生成できるようになります。 第 2 段階のビデオ事前トレーニングでは、モデルが大量のビデオ データにさらされ、時間的畳み込みレイヤーとアテンション レイヤーを空間的に対応するレイヤーと組み合わせることで時間的に学習できるようになります。そしてスポーツモード。 トレーニングはシステム管理のデータセットで実行され、モデルが高品質で関連性の高いビデオ コンテンツから学習するようにします。 最終段階は高品質ビデオの微調整です。これは、小さいながらも高品質のデータセットを使用して、より高い解像度と忠実度のビデオを生成するモデルの能力を向上させることに重点を置いています。 この階層化されたトレーニング戦略と、新しいデータ管理プロセスによって補完されることにより、SVD は最先端のテキストからビデオへの合成、および画像からビデオへの合成の生成において優れた能力を発揮できるようになります。時間の経過とともに、並外れた詳細、信頼性、一貫性を備えています。 ビデオの結合 このタスクでは、研究者は SEINE を使用してビデオを結合しました。 SEINE は、事前トレーニングされた T2V モデル LaVie エージェントに基づいて構築されています。 SEINE は、テキストの説明に基づいてトランジションを生成する、確率論的なマスクされたビデオ拡散モデルを中心としています。 さまざまなシーンの画像をテキストベースのコントロールと統合することで、SEINE は一貫性と視覚的な品質を維持したトランジション ビデオを生成できます。 さらに、このモデルは、画像からビデオへのアニメーションや白回帰ビデオ予測などのタスクに拡張できます。 - イノベーション フレームワークと柔軟性: テキストをビデオに変換するプロセスを簡素化するだけでなく、デジタル世界をシミュレートし、前例のない柔軟性と効率性を示します。 - オープンソースへの貢献: Mora のオープンソースの性質は、AI コミュニティを促進するための強固な基盤を提供することで、AI コミュニティへの重要な貢献です。さらなる開発と改善は、将来の研究の基礎となります。 これにより、高度なビデオ生成技術の普及が促進されるだけでなく、この分野での協力と革新も促進されます。 制限事項 人間の動きを捉えたい 微妙な違い高解像度で滑らかなビデオ シーケンスが必要です。これにより、バランス、姿勢、環境との相互作用など、ダイナミクスのあらゆる側面を詳細に表示できます。 しかし、高品質のビデオ データ セットのほとんどは、映画、テレビ番組、独自のゲーム映像などの専門的なソースから得られます。多くの場合、法的に収集または使用するのが難しい著作権で保護された素材が含まれています。 これらのデータセットが不足しているため、Mora のようなビデオ生成モデルが、歩いたり自転車に乗ったりするなど、現実世界の環境での人間の行動をシミュレートすることが困難になります。 - 質量と長さのギャップ: モーラはソラと同様のタスクを完了できますが、多数の人の動きを伴うシーンでは、結果として得られるビデオの品質は著しく低くなり、ビデオの長さが長くなると、特に 12 秒を超えると品質が低下します。 - 指示に従う能力: Mora はプロンプトで指定されたすべてのオブジェクトをビデオに含めることができますが、正確に説明し、説明することは困難です。移動速度など、ヒントで説明されている移動ダイナミクスをデモンストレーションします。 また、Mora はオブジェクトを左右に動かすなど、オブジェクトの移動方向を制御することはできません。 これらの制限は主に、Mora のビデオ生成がテキスト プロンプトから直接指示を取得するのではなく、画像からビデオへの方法に基づいているという事実によるものです。 - 人間の好みの調整: ビデオ分野では人間による注釈情報が不足しているため、実験結果が人間の好みに必ずしも一致するとは限りません。視覚的な好み。 たとえば、上記のビデオ結合タスクの 1 つは、男性が徐々に女性に変化するトランジション ビデオを生成する必要がありますが、これは非常に非論理的です。 

















全体的には近いですが、それほど良くはありませんSora







ビデオ生成のさまざまなタスクでは、通常、異なる専門知識を持つ複数のエージェントが連携して作業する必要があります。各エージェントが出力を提供します。その専門分野で。
 - エージェントの選択と生成のプロンプト:
- エージェントの選択と生成のプロンプト: エージェントの実現



利点
- ビデオ データは非常に重要です:
以上がSora はオープンソースではありません。Microsoft がオープンソース化します。 12 秒でリアルで爆発的なエフェクトを備えた、世界で最も近いソラ ビデオ モデルが誕生の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。